Amazon MSK 는 Apache Kafaka서비스를 더욱더 실시간으로 스트리밍 데이터를 손쉽고 수집하고 처리할수있고, 또한 모니터링 하는부분도 손쉽게처리할수있게 설정을 할 수 있습니다.
먼저 MSK 서비스를 들어갑니다. 저희는 사용자 지정 생성 선택하여 클러스터를 생성할 예정입니다.
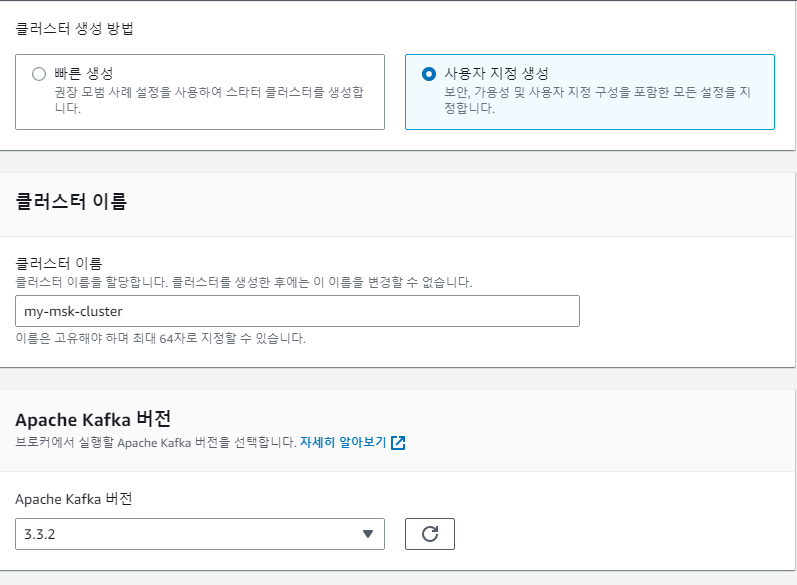
위와 같이 cluster 이름을 선정한 후 , kafka버전은 3.3.2로 맞추었습니다. 3.3.2와 호환되는 Spring Boot버전도 있기에, 추후 Spring Boot setting할때 버전을 맞는거에 맞춰야한다.
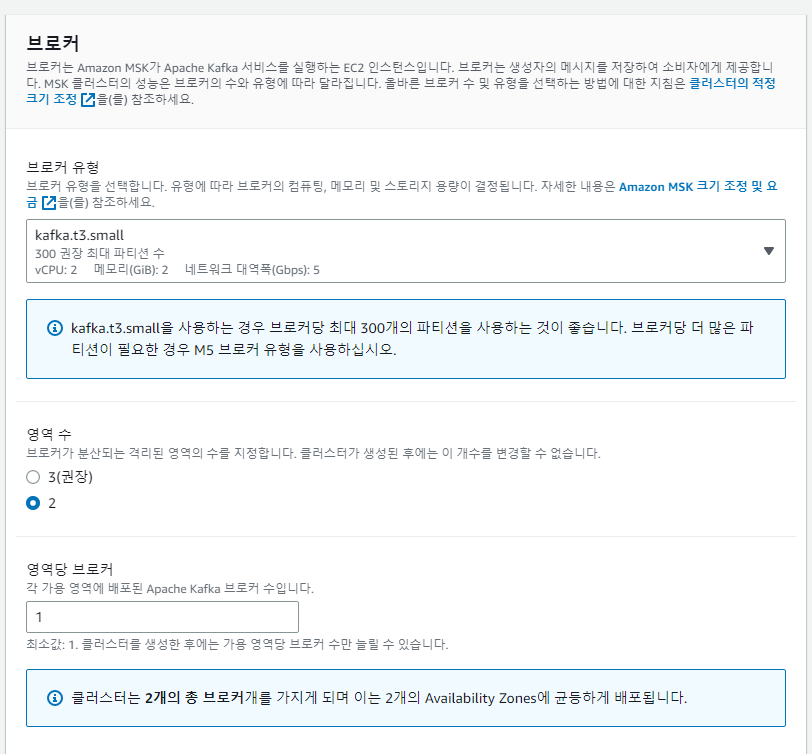
브로커의 유형은 제일 낮은사양 t3.small을 선택하였고, 영역수는 2개를 지정하였다 이부분은 앞서 설명했던 서브넷을 두개를 만드는이유이다. 여기서 우리는 2개의 서브넷을 지정했기에, 2개를 선택하였고, 영역당 브로커는 1로지정하였다.
그 아래 스토리지 등등 은 설정하지 않았다
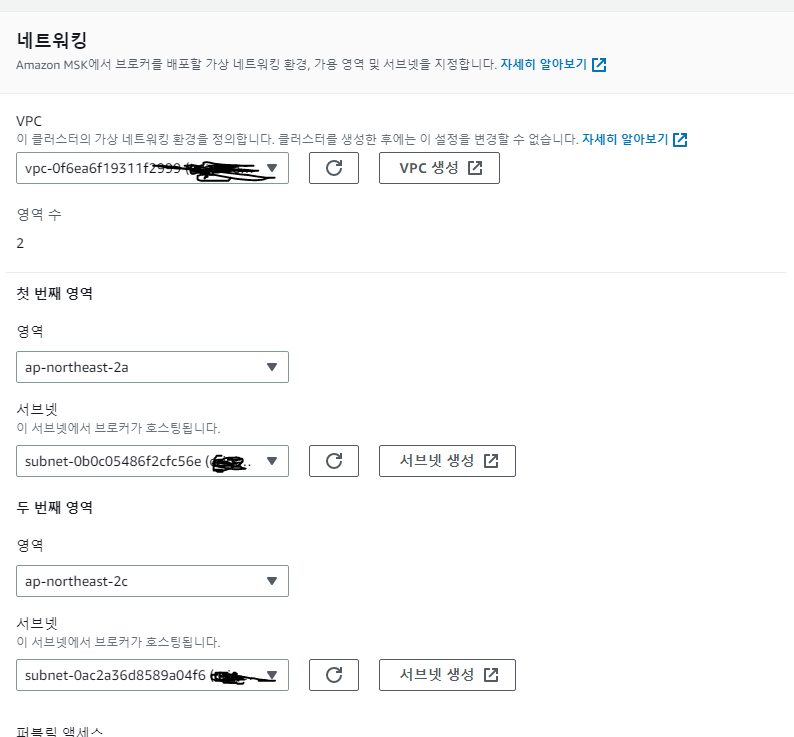
이후 다음을선택하면 네트워킹 화면이 나오는데, 우리가 지정한 VPC를 선택하여 서브넷을 지정해주었다.
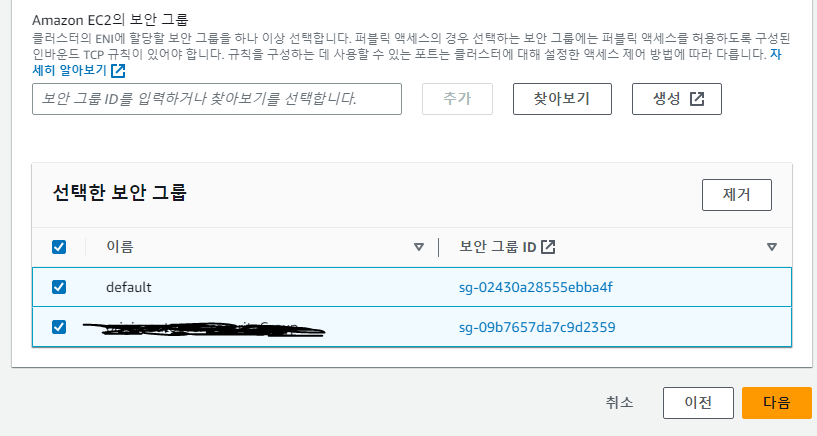
이후 보안그룹을 선택하게나오는데 맨처음에는 아마 default로 하나가 선택되어있을텐데, 이부분에서 나는 찾아보기 를 클릭하여 내가 만든 보안그룹을 선택해주고 다음 을 눌르자 !
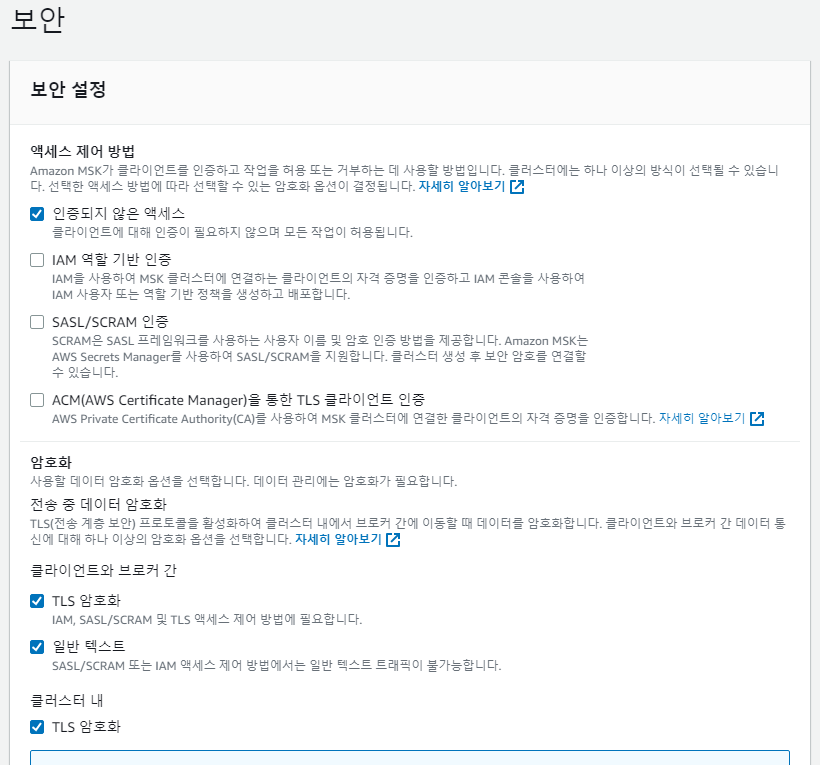
이후 보안 부분 탭이 나올텐데, 여기서 중요하다
일단 인증되지 않은 액세스를 선택해주었다. 나머지의 인증부분관련해서는 지금 현재 프로젝트를 크게 하는것이아니기때문에 필요한부분이아니라 생각하여 선택하지않았다.
이후 암호화 부분에서 일반 텍스트 를 꼭 선택해주자 실제 현업에서는 아마 이부분이 필요..한가? 아무튼 로컬에서 사용하고 사이드프로젝트 이기에 일반텍스트 만 사용하도록 하게 냅두었고, 추후 조금 더 사이드프로젝트를하다 tls도 달아야 하는 일도 있을가 해서 선택해주었습니다.
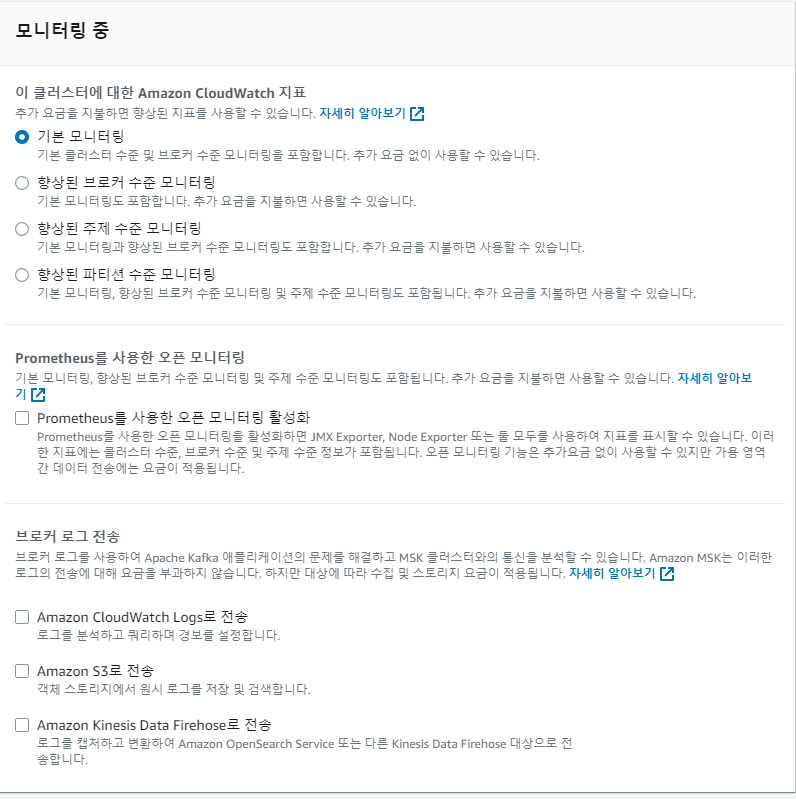
이후 모니터링 탭에서는 기본적으로 선택을 안하였다 .
하지만 기본적으로 Prometheus까지 제공을 해주는 것같아, 좋았다. 나중되면 쓰는 날이 오겠지..? 모니터링까지는 .. 아직은......... 하지만 저것도.. 하고싶네 ...
이렇게까지 하고나면 여태까지 한 선택을 했던 부분이 나오게되는데 다 확인하고 생성 버튼을 클릭하게되면 클러스터가 만들어지게된다.
필자는 기다리는과정속에서 코테를 풀었다... 진짜 좀 오래걸린다 15~20분 ? 담하피 ? ㅋㅋ
다음 챕터에서는 생성된 클러스터를 통해 데이터를 오고가는걸 producer 와 consumer에서 직접 볼 예정이다. 그러기 위해선 Apache Kafka 패키지를 다운받고 실습하는 과정이다.
