가비지 컬렉션(Garbage Collection)
가비지 컬렉션 과정
stop-the-world
- GC를 실행하기 위해 JVM 애플리케이션 실행을 멈추는 것을 의미
- GC를 실행하는 쓰레드를 제외한 나머지 쓰레드는 모두 작업을 멈춤
- GC작업이 완료된 후에 중단한 작업을 다시 시작, 이는 어떤 알고리즘을 사용하더라도 발생
- stop-the-world의 시간을 줄이는 것이 GC 튜닝의 목적
System.gc()
- Java는 메모리를 명시적으로 지정하여 해제하지는 않음
- 단, 해당 객체를 null로 지정하거나
System.gc()메서드를 호출하여 처리할 순 있음 System.gc()메서드 호출 시에는 시스템 성능에 매우 큰영향을 끼쳐 사용하지 않는 것이 좋음
Garbage Collector
- 두가지 가설을 기준으로 만들어짐
- 대부분의 객체는 금방 접근 불가능(unreachable)
- 오래된 객체에서는 젊은 객체로의 참조는 아주 적게 존재
- 이를
weak generation hypothesis라 함 - 해당 가설의 장점을 활용하기 위해 HotSpot VM에서는 크게 2개로 물리적 공간을 나눔
- Young 영역(Young Generation 영역): 새롭게 생성한 객체가 위치, 대부분의 객체가 금방 접근 불가능 해지기 때문에 많은 객체가 Young영역에 생성되었다 사라짐, 이를 Minor GC가 발생한다고 지칭
- Old 영역(Old Generation 영역): 접근 불가능 상태로 되지 않고 Young 영역에서 살아남은 객체를 복사. Young영역 보다 크며, GC는 적게 발생. 이를 Major GC(혹은 Full GC)가 발생한다고 지칭
- 데이터 흐름
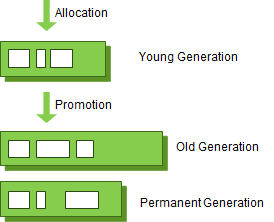 GC 영역 및 데이터 흐름
GC 영역 및 데이터 흐름
- Permanent Generation 영역(Perm 영역)은 Method Area라고도 하며, 객체나 억류된 문자열을 저장하며, 이 영역에서도 GC 발생하고 이는 Major GC에 포함
- Old 영역에서 Young 영역을 참조하는 방식
- Old 영역에 카드 테이블(card table)이 존재 Old 영역에 있는 객체가 Young 영역의 객체를 참조할 때마다 정보가 표시
- Young 영역의 GC 실행시 Old역역에 있는 모든 객체가 아닌 카드 테이블을 이용해 GC 대상인지 식별
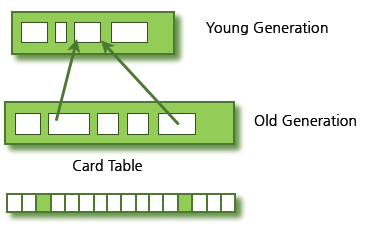 카드 테이블 구조
카드 테이블 구조
Young 영역의 구성
- 영역의 구성
- Eden 영역
- Survivor 영역(2개)
- 영역의 처리 절차
- 새로 생성한 대부분의 객체가 Eden 역역에 위치
- Eden 영역에서 GC가 한번 발생한 후 살아남은 객체를 Survivor 영역중 하나로 이동
- Eden 영역에서 GC가 발생하면 이미 남은 객체가 존재하는 Survivor 영역에 계속 쌓임
- 하나의 Survivor 영역이 가득 차면 그중 살아남은 객체를 다른 Survivor로 이동하며 이전 Survivor 영역은 비워짐
- 이 과정을 반복하여 살아남은 객체가 Old 영역으로 이동
- 해당 절차에 의하면 Survivor영역 중 하나는 반드시 비어야 함, 만약 두 Survivor에 데이터가 모두 존재하거나 모두 0이면 정상이 아닌 것으로 판단 가능
- Minor GC를 통해 Old영역 까지의 데이터 이동
 GC 전후 비교
GC 전후 비교
- 정리하면, Eden 영역에는 최초로 객체가 만들어지고, Survivor 영역을 통해 Old 영역으로 오래살아남은 객체가 이동
Old 영역에 대한 GC
- Old 영역은 기본적으로 데이터가 가득 차면 Gc 실행
- GC 방식에 따라 처리 절차가 다르며 JDK 7 기준으로 5가지 방식 존재
- Serial GC
- Parallel GC
- Parallel Old GC
- Concurrent Mark & Sweep GC(CMS)
- G1(Garbage First) GC
- 이중 Serial GC는 단일 코어용이며, 애플리케이션 성능이 매우 떨어짐
Serial GC(-XX:+UseSerialGC)
- Young 영역은 앞서의 방식을 그대로 사용
- Old 영역은 mark-sweep-compact 라는 알고리즘 사용
- Old 영역에 살아남은 객체를 식별(Mark)
- 힙(Heap)의 앞 부분 부터 확인하여 살아있는 것만 남김(Sweep)
- 마지막으로 각 객체들이 연속되게 쌓이도록 힙의 가장 앞부분 부터 객체가 존재하는 부분과 없는 부분으로 나눔(Compaction)
- 적은 메모리와 CPU 코어 개수가 적을 때 적합
Parallel GC(-XX:+UseParllelGC)
- 기본적인 알고리즘은 Serial GC와 유사 하지만, 스레드가 여러 개가 여러개
- 이를 통해 빠르게 객체 처리가 가능
- 메모리가 충분하며 코어가 많을 때 유리
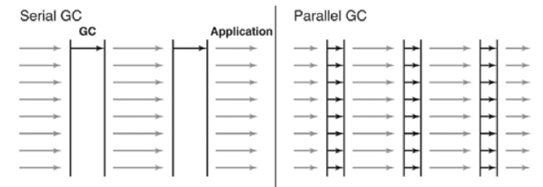 Serial GC와 Parallel GC의 차이 (이미지 출처: "Java Performance", p. 86)
Serial GC와 Parallel GC의 차이 (이미지 출처: "Java Performance", p. 86)
Parallel Old GC(-XX:+UseParallelOldGC)
- JDK 5 부터 제공한 방식이며 Parallel GC와 비교해 Old 영역의 GC 알고리즘만 다름
- Mark-Summary-Compaction 단계를 거치며, Summary 단계는 앞서 GC를 수행한 영역에 대해서도 별도로 살아있는 객체를 식별이는 Sweep과 다름
CMS GC(-XX:+UseConcMarkSweepGC)
 Serial GC와 CMS GC
Serial GC와 CMS GC
- 초기 Initial Mark 단계에서 클래스 로더에 가장 가까운 객체 중 살아있는 객체만 찾는 것으로 마무리되며 시간이 짧음
- Concurrent Mark 단계에서 방금 살아난 객체에 참조하고 있는 객체들을 따라가며 확인
- 이 단계의 특징은 다른 스레드가 실행 중인 상태에서 동시에 진행
- Remark 단계에서는 Concurrent Mark단계에서 새로 추가되거나 참조가 끊긴 객체 확인
- Concurrent Sweep 단계에서는 쓰레기를 정리하는 작업 실행, 이 작업 역시 다른 스레드가 실행된 상태에서 진행
- 이러한 단계로 진행이되어 stop-the-world의 시간이 매우 짧음
- 응답속도가 중요한 경우 CMS GC를 사용하며, Low Latency GC라 부름
- 단점
- 다른 GC 방식보다 메모리와 CPU를 더 많이 사용
- Compaction 단계가 기본적으로 제공되지 않음 -> 이로인해 조각난 메모리가 많아 Compation 실행시 stop-the-world 가 길어질 수 있음
G1 GC
- 기존의 방식과는 다른 방식
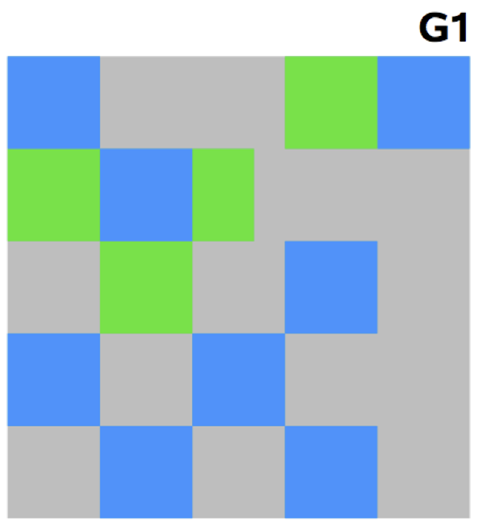 G1 GC의 레이아웃(이미지 출처: "The Garbage-First Garbage Collector" (TS-5419), JavaOne 2008, p. 19)
G1 GC의 레이아웃(이미지 출처: "The Garbage-First Garbage Collector" (TS-5419), JavaOne 2008, p. 19)
- G1 GC는 바둑판의 각 영역에 객체를 할당하고 GC를 실행
- 해당영역이 가득차면 다른영역에서 객체를 할당하고 GC를 실행 즉, Old 영역으로 이동하는 단계가 사라진 방식
- G1 GC는 CMS GC를 대체하기 위해 만들어짐
- 성능이 지금까지의 어떤 방식보다 빠름
- JDK 7에서 부터 정식으로 포함하여 제공
참조
Garbage Collector:https://d2.naver.com/helloworld/1329

차근차근 기록하고 배우는 개발자