계층구조와 DOM Tree
*계층이란?
컴퓨터 과학에서 계층화는 메시지 전송을 별도의 구성 요소와 활동으로 구분하는 것을 의미한다. 계층화는 어떤 순차적, 계층적 방식으로 상호작용하는 별개의 기능적 요소들로 프로그래밍의 조직이다. 쉽게 해석한다면 별개의 기능을 가진 요소들로 분활하는 기준점이 계층이라고 생각한다.
네이버에서 이야기하는 계층의 사전적 의미는 재산·교육·직업 등의 여러 차원에서 사회적 지위가 거의 비슷한 사람들의 집단 이라고 한다. 이 뜻은 서로 비슷한 공통의 무언가(접점)을 통해 만들어지는 모든 것이 바로 계층 아닐까?
컴퓨터 과학에서 말하는 계층은 어느 하나의 계층이 우위에 있는 것이 아닌 서로 동등한 위치에서 상호작용하는 것을 의미한다. 즉 계층은 개체, 이름, 값, 범주와 같은 항목들의 나열을 뜻하며 여기에서 항목들은 "위", "아래", "다른 항목과 같은 수준"으로 표현된다.
간단한 예시를 들어보겠다.
우리가 63빌딩을 계단을타고 올라가고 있다.
우리는 지금 32층에있다.
이 때 우리는 63층의 모든 계단을 고려할 필요가 없다.
그저 33층과 31층만 고려하면 된다.
컴퓨터 과학에서도 똑같다.
우리는 지금 컴퓨터를 사용할 때 이 시스템이 내부에서 어떻게 돌아가고 있는지 전혀 알 필요 없다. 우리는 마우스 한 번의 클릭으로 프로그램을 작성할 수 있고, 키보드 한 번의 입력으로 원하는 글자를 입력할 수 있다. 이것이 바로 컴퓨터의 계층구조 덕분이다.
만약 계층구조가 없다면 어떨까? 아무리 똑똑한 사람이라도, 컴퓨터를 혼자서는 만들 수 없다. 계층구조가 없다면 모든 컴퓨터의 시스템을 정확히 파악하고 조작을 해야할 것이다. 그나마 컴퓨터가 계층구조로 이루어져 있기에, 우리는 컴퓨터 프로그램을 개발할 때 인접하지 않은 부분은 신경쓰지 않아도 된다.
내가 지금 공부하고있는 웹에서 또한 대표적인 계층구조가 있다.
바로 DOM이다. DOM은 웹페이지에 대한 인터페이스이다. 쉽게 이야기하면 HTML문서를 객체 기반으로 표현한 방식이다. 일단 DOM에 대해서 이야기하기 전에 웹페이지가 만들어지는 과정을 먼저 설명하려고 한다. 웹페이지에서는 HTML문서를 읽어들인 후, 스타일을 입히고(CSS) 대화형 페이지로 만들어 뷰포트(우리가 보이는 화면)에 보이기까지의 일련의 과정을 거친다.
이 과정을 크게 두가지로 나눌 수 있는데 첫 번째 단계에서 브라우저는 읽어들인 문서를 파싱(가공)한다. 두 번째 단계에서는 어떤 내용을 렌더링 ( html로 입력받아 해석해서 표준 출력 장치로 출력)을 수행한다.
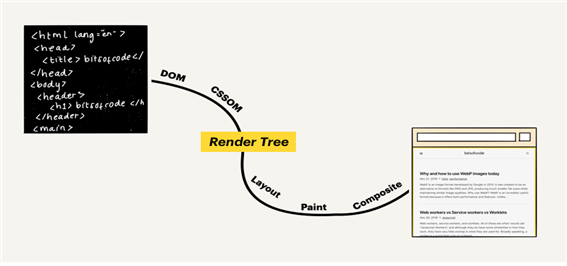
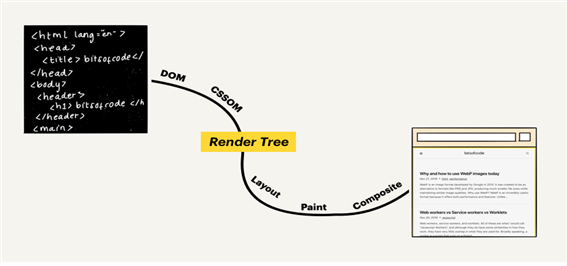
첫 번째 단계에서는 렌더트리가 생성된다.
렌더트리는 웹페이지에서 표시 될 HTML 요소들과 이와 관련된 스타일 요소(CSS)들로 구성된다. 이 때 브라우저에서 렌더트리가 생성될 때 그림에서와 같이 DOM과 CSSOM이라는 두 모델이 필요하다.
DOM은 내용과 구조를 객체 모델로 변환되어 다양한 프로그램에서 사용할 수 있다.
즉 웹 브라우저가 HTML 페이지를 인식하는 방식이다.
이 때 우리는 DOM의 개체 구조는 “노드 트리”로 표현된다.
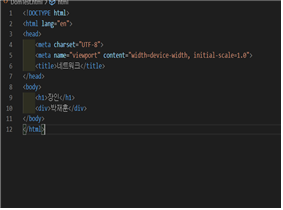
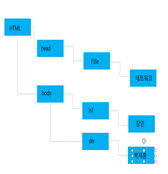
단 이렇게 표현된다고 해서 DOM과 HTML이 완전히 매핑하는 것은 아니다.
비록 DOM이 HTML문서로부터 생성된다고 해서 원본 HTML과 소스가 다를 수 있다.
DOM은 HTML문서의 객체 기반 표현 방식이다. 즉 서로 비슷하면서도 다른 개념인 것이다.
둘의 차이는 단순 텍스트로 구성된 HTML문서의 내용과 구조가 객체 모델로 변환됨에 따라 다양한 프로그램에서 사용할 수 있다.
그렇기에 DOM은 HTML문서와는 다를 수 있다.
그 대표적인 예시로는
첫번 째 작성된 HTML문서가 유효하지 않을 수 있다.
예를 들어
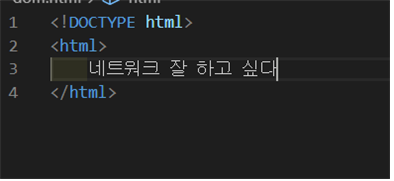
이런 코드가 있을 때 HTML에는 필수적으로 들어가야 하는 요소인와 가 빠져있다.
DOM을 생성하는 동안 유효하지 않은 HTML코드를 교정합니다.(DOM트리는 렌더트리를 생성하는 과정에서 생성된다.)
잠깐, 나는 여기서 DOM Tree와 DOM의 개념이 헷갈리지 않게 명확하게 집고가려 한다.
DOM은 문서의 각 부분을 객체로 표현한 API,
그리고 이 문서를 tree형태로 표시한 것이 DOM Tree이다.
자 그럼 이 DOM이 생성되는 과정을 DOM Tree로 만들면 어떻게 될까?
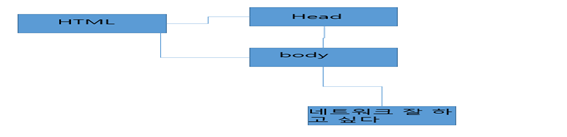
이와 같은 맥락으로 js에서
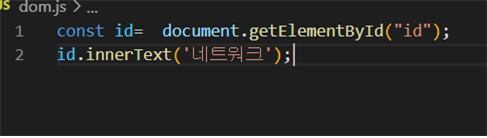
이런 식으로 동적으로 html요소를 추가할 수 있는데 이 때 HTML의 문서를 변경하는 것이 아닌 DOM을 업데이트 한다.
그렇다면 우리가 브라우저에서 보이는 것은 DOM일까?
정확히는 렌더트리, 즉 DOM과 CSSDOM의 조합이다.
나는 여기서 CSSDOM이 무엇인지 궁금해졌다.
주제와 조금은 벗어나도 이 시간이 공부를 위한 시간이라고 생각하기 때문에 한 번 찾아보았다.
CSS객체모델 즉 CSSDOM은 CSS의 조작을 가능하게 만드는 API의 집합이다.
DOM과 비슷하지만 DOM은 HTML문서를 조작하고, CSSDOM은 CSS를 조작한다.
DOM은 HTML 문서에 대한 인터페이스이다.
첫째로 뷰 포트(화면)에 무엇을 렌더링 할지 결정하기 위해 사용되며,
둘째로는 페이지의 콘텐츠 및 구조, 그리고 스타일이 자바스크립트 프로그램에 의해 수정되기 위해 사용된다.

내가 공부를 할 때 이런 식의 코드를 작성할 때가 있다. 이것은
나는 자바스크립트 프로그램으로 페이지를 조작하기 위해 위처럼 document객체를 사용할 수 있다.
결론
DOM이란 페이지의 API로 HTML문서를 객체화하여 이것을 조작할 수 있고
CSSDOM과 합쳐져 렌더 트리를 형성한다.
그리고 그 렌더트리를 사용함으로써 우리는 우리가 원하는 웹페이지를 볼 수 있다.
++공부를 하다보며 많은 것을 알게되었다. 그리고 다양한 자료를 찾으며 웹브라우저의 렌더링 과정을 코드와 연관시켜 설명한 글을 찾게되어 이야기 해보려한다.
html문서 렌더링 과정은
1. 로더 – 서버로부터 파일을 불러와 읽으며 어떤 파일인지, 데이터인지 파일을 다운로드 할 것인지 결정한다.
2. 파싱 – 웹엔진이 갖고 있는 html/xml 파서가 문서를 파싱해 domtree를 만든다.
3. 렌더링 트리 만들기 – 위에 설명이 많으므로 생략한다.
4. css결정 - css는 선택자에 따라서 적용되는 태그가 다르기 때문에 모든 CSS 스타일을 분석해 태그에 스타일 규칙이 적용되게 결정한다.
5. 레이아웃 – 객체들의 위치와 크기를 결정해주는 과정
6. 그리기 – 렌터링 트리를 탐색하며 그린다.
이 자료에서의 핵심은 아래에 있다.
우리가 html코드를 짤 때에는 자연스럽게 css는위에, script는 아래에 위치시킨다고 배워왔다.
또 어떤 경우에서는 script가 위에 있으면 오류가 나기도 한다.
지금까지는 그저 이 이유를 모르고 자연스럽게 사용해왔다.
하지만 이제는 알 수 있다.
문서를 파싱해서 DOM Tree를 만들어도 스타일 규칙이 없으면 렌더링 할 수가 없다.
즉, 최대한 빨리 스타일 규칙을 알아야 렌더링트리가 완전히 만들어지므로 스타일시트 파일을 모두 다운로드시키기 위해 태그 사이에 놓는 것이다.
반대로 script는 태그 사이에 놓게되면 굉장히 비효율적이다.
왜냐하면 js가 dom객체를 이용해서 컴포넌트를 조작하는데 상단에 위치시킨다면 html파서가 파싱을 멈추고 스크립트를 읽기 때문이다.
파싱을 멈추고 스크립트를 읽는다는 것은 즉 웹페이지의 로딩이 그만큼 느려진다.
출처:
https://d2.naver.com/helloworld/59361
https://www.html5rocks.com/en/tutorials/internals/howbrowserswork/#DOM
https://na27.tistory.com/228
