
1. 패키지 다운
데이터를 분석하는 것 보다 데이터를 정리하는 작업이 더 오래걸린다고 한다. 전체시간의 80%를 데이터를 정리하는데 사용한다고도 한다. 데이터를 분석하기 위해서 데이터를 이쁘게 정리하는 것이다. 데이터를 정리하기 위해선 몇 가지 packages를 통해 효율적으로 할 수 있는데 그 중에서 우리는 tidyr 과 dplyr 를 사용할 것이다.
만약 이 두가지가 설치되어 있지 않다면
install.packages("tidyr")
install.packages("dplyr")를 하여서 먼저 packages를 다운받아준다.
2. tidyr
다운로드가 끝났으면 이제 활용해보자 우선 member 라는 데이터 프레임을 만들어준다.
library("tidyr")
library("dplyr")
member = data.frame(family=c(1,2,3),name_f=c("a","b","c"),age_f=c(30,40,23),name_m=c("d","e","f"),age_m=c(33,46,26))
member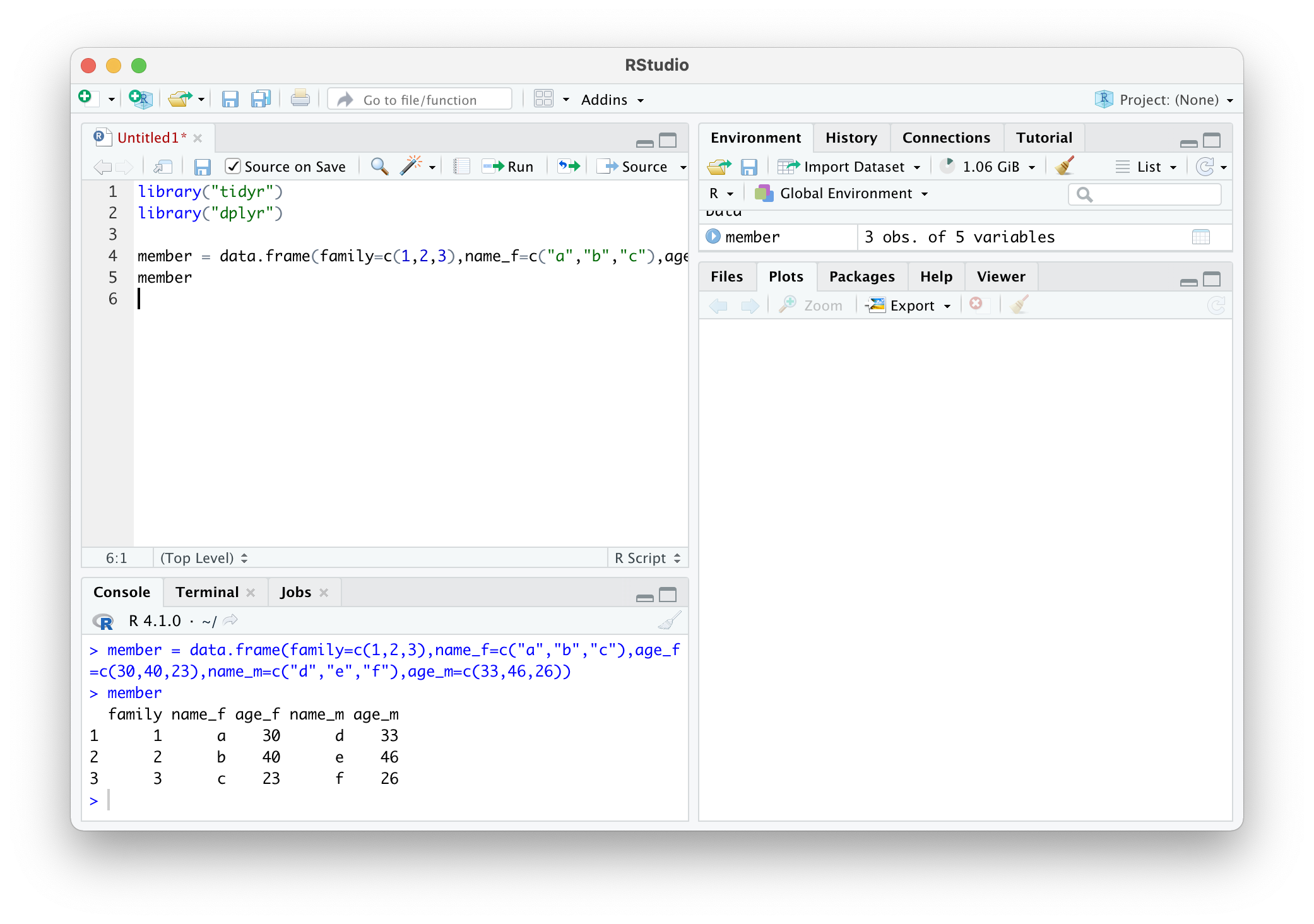
이 데이터 프레임을 설명하자면 3개의 가족이 있고 첫번째 가족의 여성의 이름(name_f)는 'a'이고 30세(age_f), 남성의 이름(name_m)은 'd'이고 33세(age_m)이다.
2-1. gather
그런데 우리는 이 데이터 프레임을 가족 1의 여자의 이름은 무엇이고 나이는 몇 살인지, 가족2의 남자의 이름은 무엇이고 이런식으로 데이터를 나누고 싶다. 여기서 tidyr 를 package 를 사용한다. 그중에서 gather 를 사용한다.
library("tidyr")
library("dplyr")
member = data.frame(family=c(1,2,3),name_f=c("a","b","c"),age_f=c(30,40,23),name_m=c("d","e","f"),age_m=c(33,46,26))
gather(member, key,value,name_f:age_m)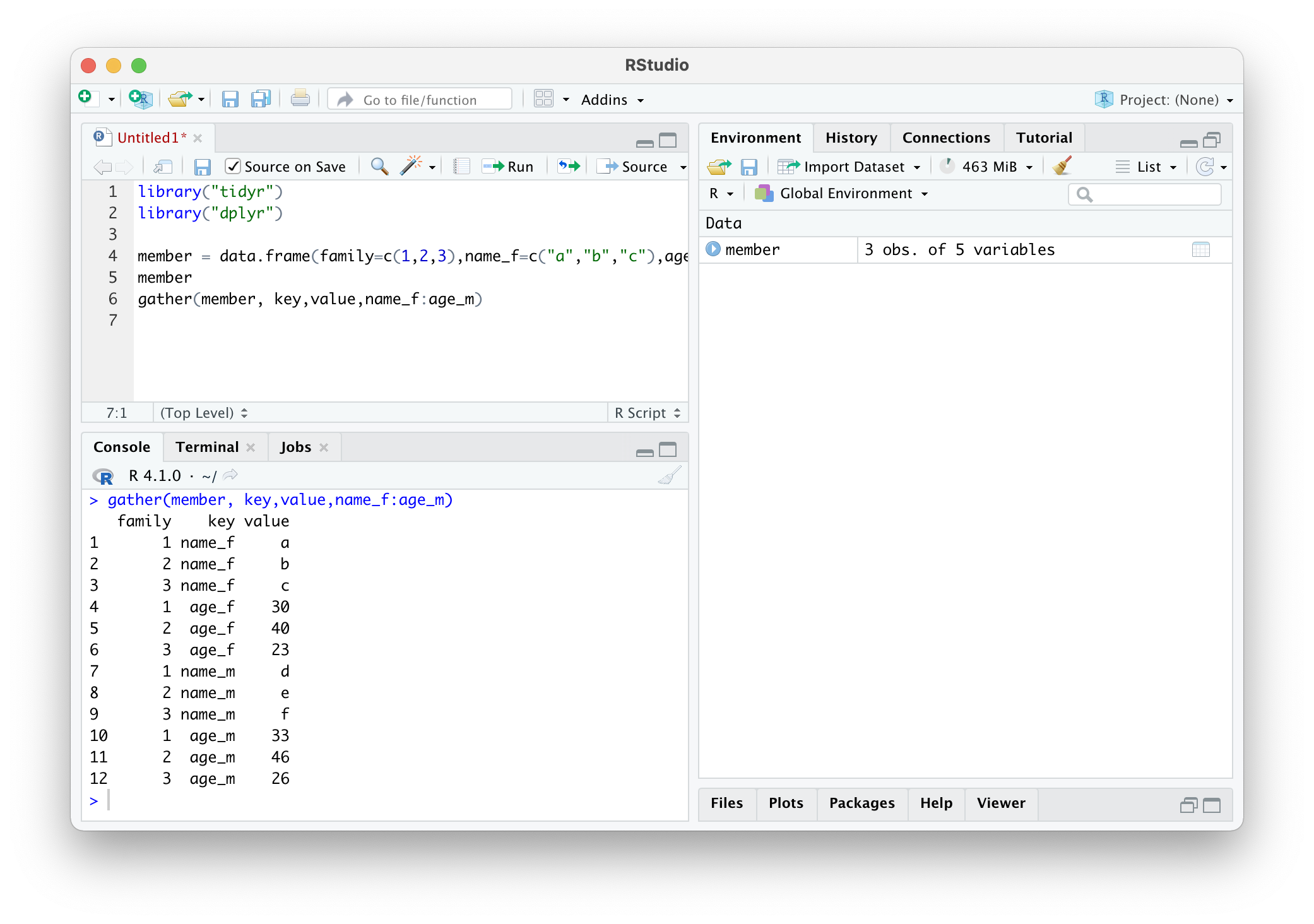
gather 는 tidyr 패키지 안에 있는 함수 중 하나로 간단히 말해서 열로 긴 데이터를 행으로 전환한다.
gather(member, key,value,name_f:age_m)이 함수만 자세히 살펴보면 먼저 'member' 라는 데이터 프레임에서 어떤 key값이 어떤 value값을 가지고 있느냐 물어보는 것이고 그 범위를 'name_f' 부터 'age_m' 까지 나타내라는 것이다.
앞서 'member' 데이터 프레임에는 family부터 age_m 까지 있었으니까 family를 뺀 모든 열을 행 방향으로 바꾸라는 것이다.
library("tidyr")
library("dplyr")
member = data.frame(family=c(1,2,3),name_f=c("a","b","c"),age_f=c(30,40,23),name_m=c("d","e","f"),age_m=c(33,46,26))
member
gather(member, key,value,name_m:age_m)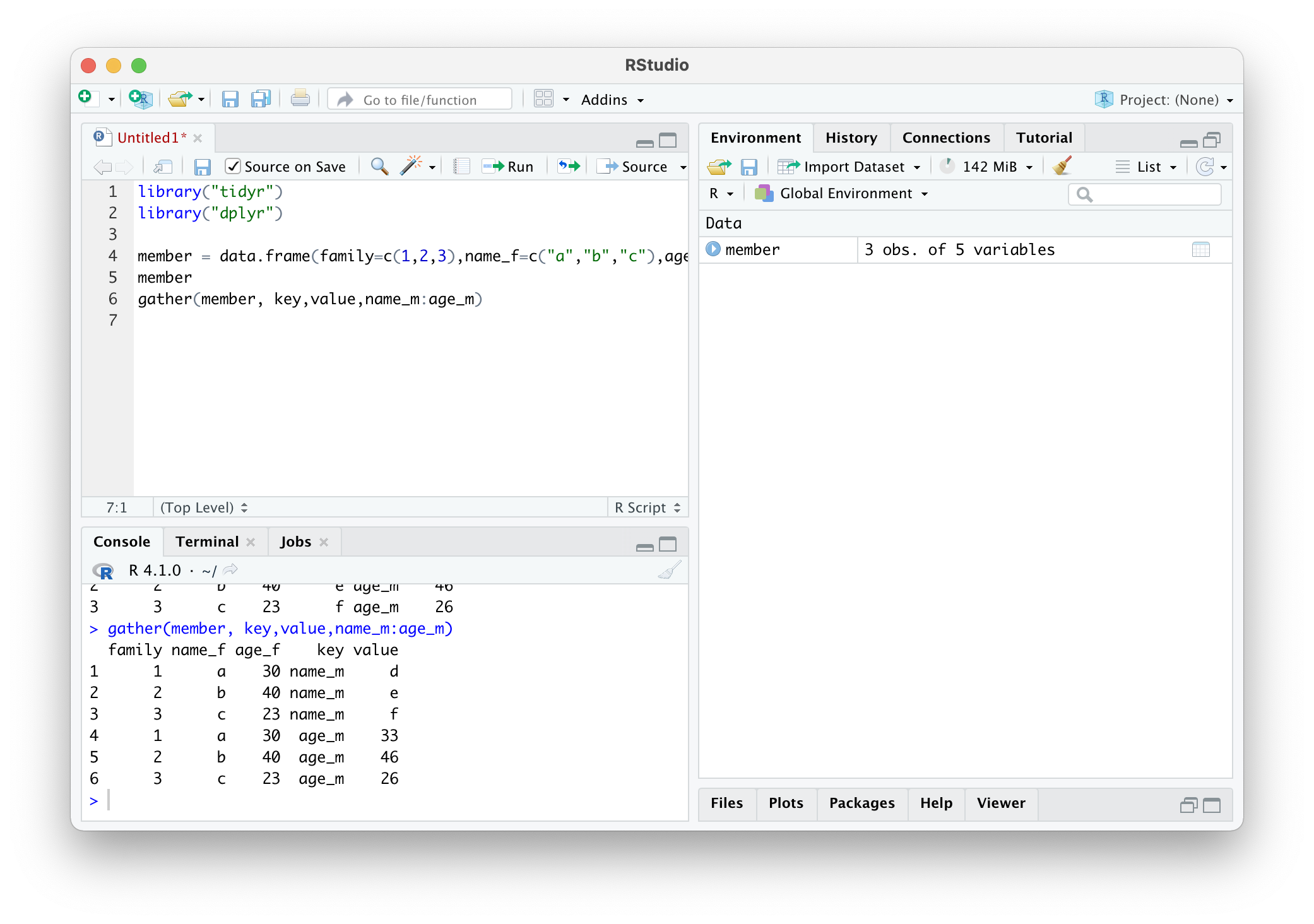
만약 범위를 name_m부터 age_m까지로 하면 다음과 같이 나타나는 것을 볼 수 있다.
2-2. separate
우리가 원하는 것은 이제 key값에서 남자인 데이터와 여자인 데이터를 분리시키는 것이다. 그러면 이제 separate 를 사용해야 한다.
자 이제 다시 name_f부터 age_m까지로 범위를 바꾼 다음에 이제 key값을 기준으로 분리시켜보자
library("tidyr")
library("dplyr")
member = data.frame(family=c(1,2,3),name_f=c("a","b","c"),age_f=c(30,40,23),name_m=c("d","e","f"),age_m=c(33,46,26))
member
a = gather(member, key, value, name_f:age_m)
separate(a,key,c("variable","gender"),-1)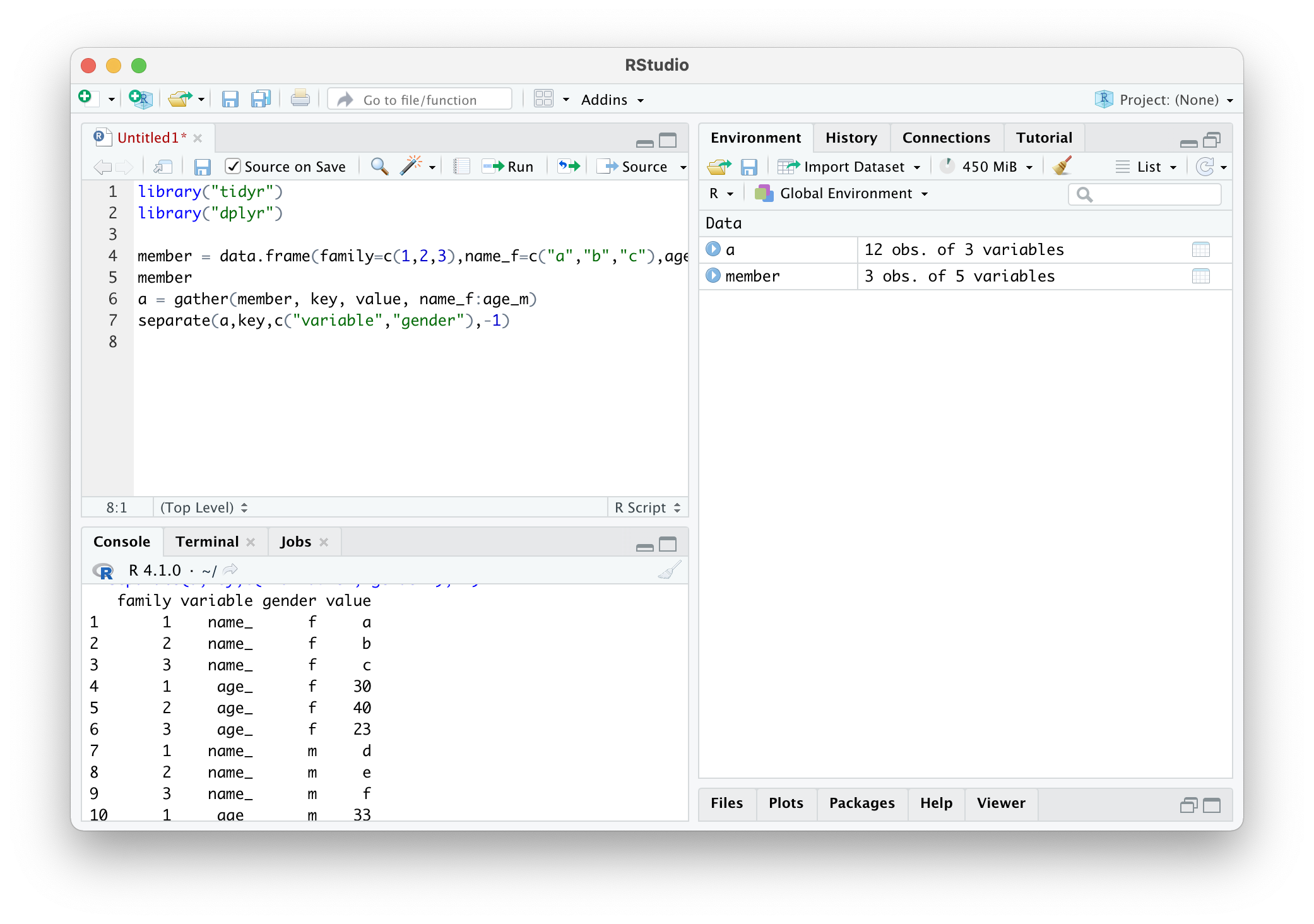
이렇게 성별을 따로 분리시킨 것을 볼 수 있다.
separate(a,key,c("variable","gender"),-1)이 함수만 자세히 살펴보자. 먼저 'a' 라는 gather를 통해 분리된 데이터 프레임을 넘겨주고, key를 기준으로 분리시킨다는 것이다. 그리고 분리시킬 이름을 'variable', 과 'gender'로 나눈다. 그리고 어떤 값을 분리시킬지 정하는데 '-1'를 넣어서 key의 마지막 한 글자( f or m ) 을 분리시킨다고 말하는 것이다.
더 자세한 설명은 https://blog.naver.com/juhy9212/220843749610 여기서 확인할 수 있다.
2-3. spread
거의 다 왔다. 이제 우리는 varialbe에서 name과 age를 다시 열로 바꾸면 된다. 그러면 우리는 앞서 사용했던 gather 의 반대인 spread 함수를 사용하면 된다.
library("tidyr")
library("dplyr")
member = data.frame(family=c(1,2,3),name_f=c("a","b","c"),age_f=c(30,40,23),name_m=c("d","e","f"),age_m=c(33,46,26))
member
a = gather(member, key, value, name_f:age_m)
b = separate(a,key,c("variable","gender"),-1)
spread(b, variable, value)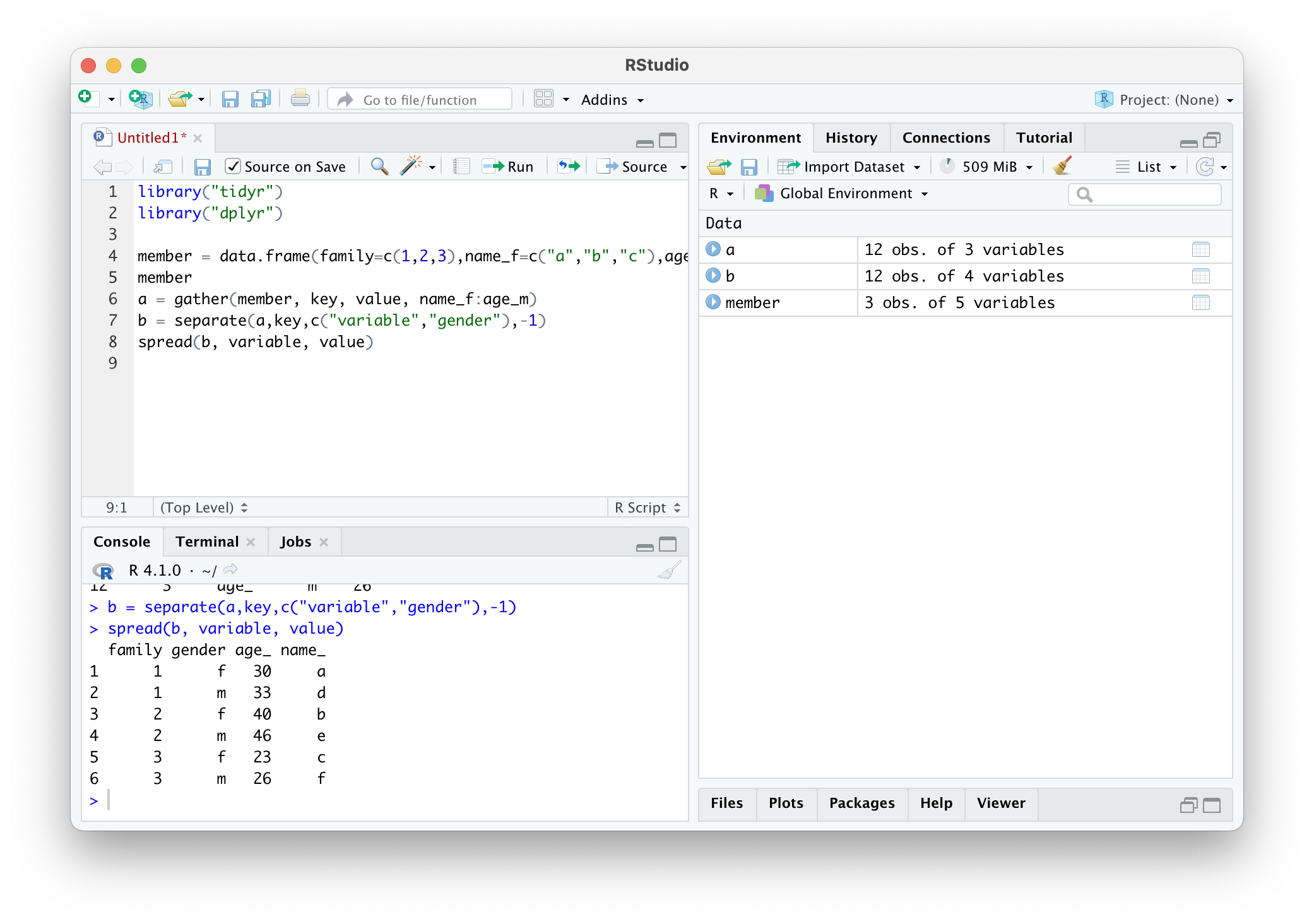
spread(b, variable, value)를 살펴보면 데이터 프레임인 **b 를 key값은 variable이고 value값**은 value인 것으로 바꾼다는 것이다.
그래서 key값으로 'age'와 'name'가 올라간 데이터 프레임이 나온다.
이렇게까지 데이터를 나누면 이제 활용하기가 매우 편해진다.
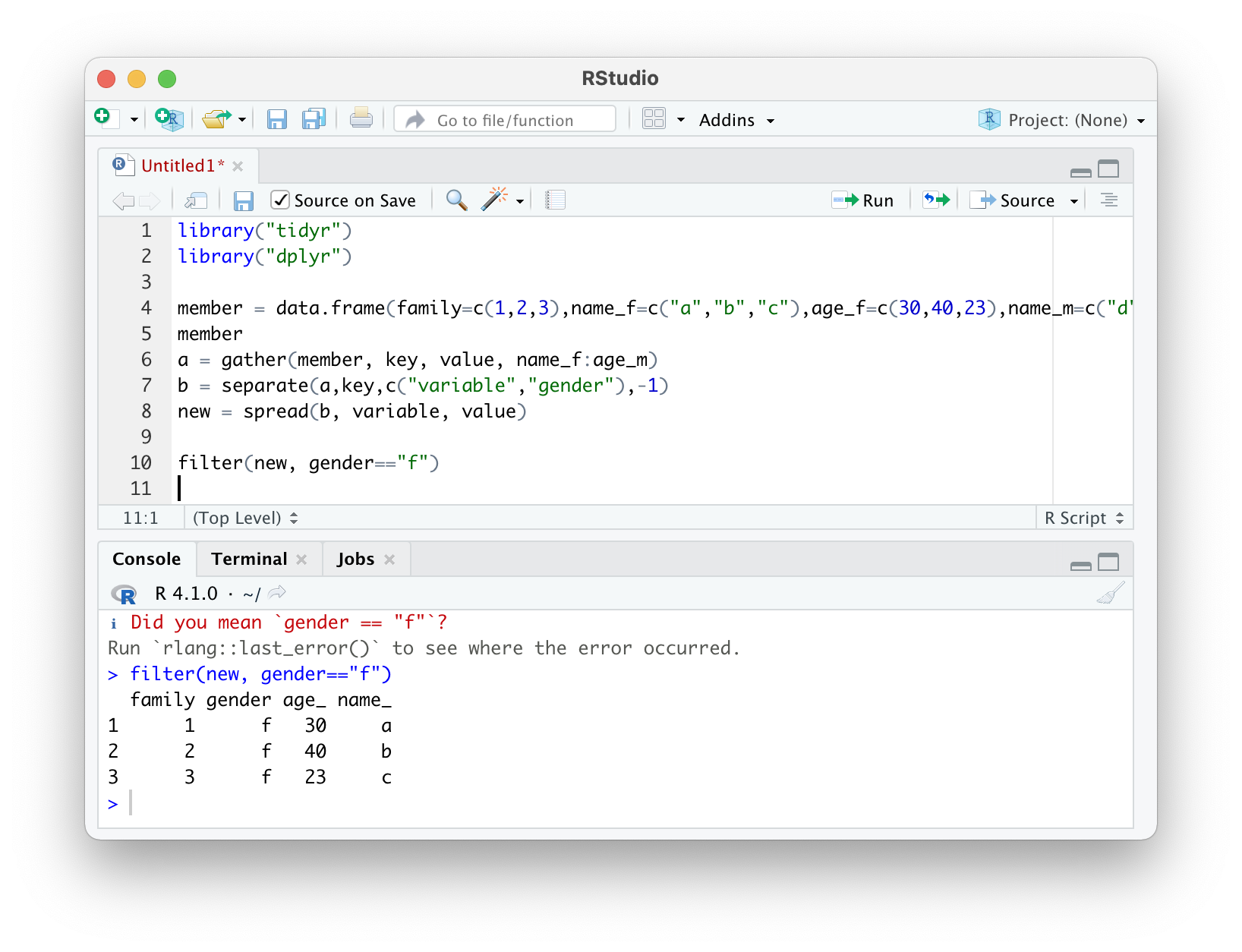
이렇게 filter 를 사용하여 여자인 데이터만 가져올 수 있고
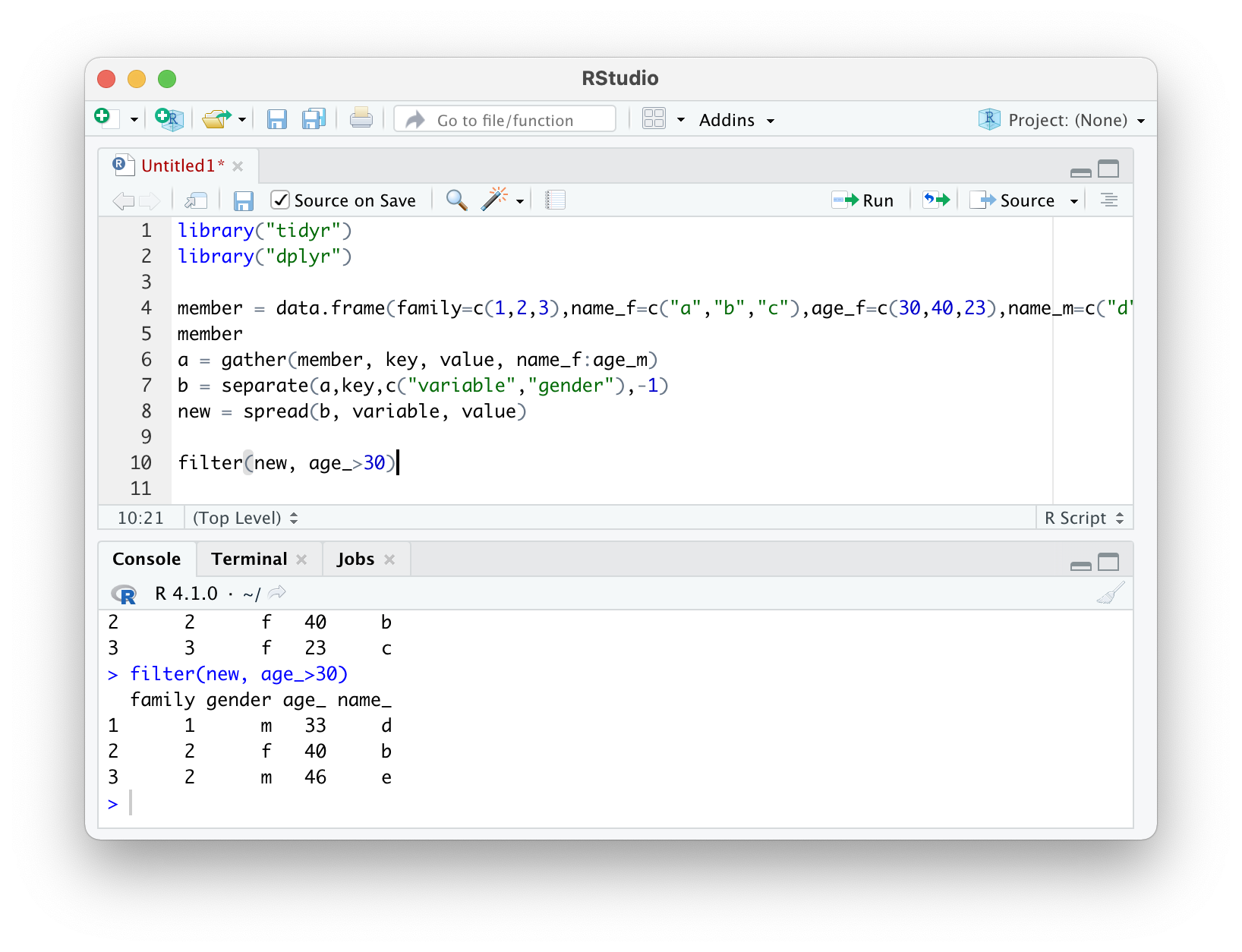
아니면 이런식으로 나이가 30살보다 많은 사람들의 데이터를 가져올 수 있다.
2. 파이프 라인
member = data.frame(family=c(1,2,3),name_f=c("a","b","c"),age_f=c(30,40,23),name_m=c("d","e","f"),age_m=c(33,46,26))
member
a = gather(member, key, value, name_f:age_m)
b = separate(a,key,c("variable","gender"),-1)
new = spread(b, variable, value)우리가 그동안 했던 것을 보면 조금 복잡해 보이는 것을 볼 수 있다.
그래서 이걸 가독성있고 깔끔하게 보이기 위해서 파이프라인(%>% ) 를 사용한다
member %>%
gather(key, value, name_f:age_m) %>%
separate(key, c("variable","gender"),-1)%>%
spread(variable,value)이런식으로 말이다. 그러면 앞에 데이터 프레임을 계속 사용하지 않아도 된다.
그러면 가독성도 좋아지고 변수를 여러번 쓰기 않아도 되어서 더 깔끔하다.
