Learning Rate Scheduler (Pytorch, HF)
학습 중 학습률을 변경해 최적의 학습을 하자. [처음에는 학습률을 크게 설정하다가 점점 줄이는 방향으로]
학습률 규제(Learning Decay)
-
Step Decay: 특정 epoch를 기준으로 일정한 비율로
learning rate을 감소시키는 것.- 이를 위한 hyperparameter가 필요.
-
Cosine Decay: 코사인 함수의 값을 따라가도록
learning rate감소 시키는 것.- 추가적인 hyperparameter가 따로 필요 없음.
HuggingFace Scheduler
-
transformers.get_linear_schedule_with_warmup:
learning rate를 linear하게 감소시킴.- learning rate는 0~1 사이의 값을 가지며 선형적으로 떨어지게 됨.
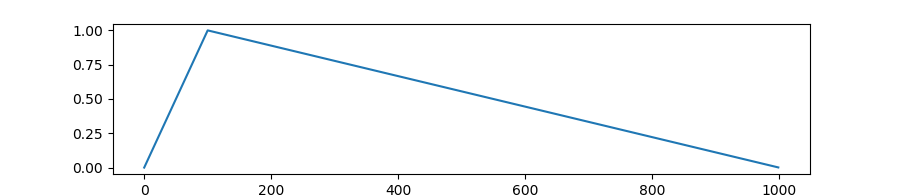
def get_linear_schedule_with_warmup(optimizer, num_warmup_steps, num_training_steps, last_epoch=-1): def lr_lambda(current_step: int): if current_step < num_warmup_steps: return float(current_step) / float(max(1, num_warmup_steps)) return max( 0.0, float(num_training_steps - current_step) / float(max(1, num_training_steps - num_warmup_steps)) ) return LambdaLR(optimizer, lr_lambda, last_epoch)- 위에서 LambdaLR을 반환하는 것을 볼 수 있는데
LambdaLR이 무엇일까?
LambdaLR(Pytorch)
-
Pytorch에서 제공하는 클래스
-
lambda함수를 이용해learning rate조절 -
url: https://github.com/pytorch/pytorch/blob/v1.1.0/torch/optim/lr_scheduler.py#L56
-
code example
def func(epoch): if epoch < 40: return 0.5 elif epoch < 70: return 0.5 ** 2 elif epoch < 90: return 0.5 ** 3 else: return 0.5 ** 4 scheduler = LambdaLR(optimizer, lr_lambda = func)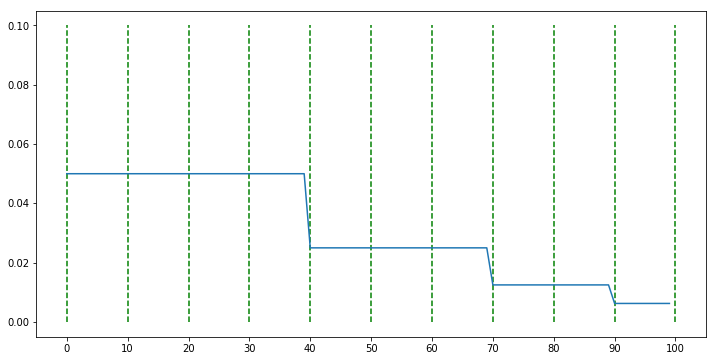
learning rate scheduler 사용
- optimizer와 scheduler를 정의
- 학습할 때 batch마다 optimizer.step()
- epoch or step(batch)마다 scheduler.step()
for _ in trange(epochs, desc="Epoch"):
entity_property_model.train()
epoch_step += 1
# entity_property train
entity_property_total_loss = 0
for step, batch in enumerate(entity_property_train_dataloader):
batch = tuple(t.to(device) for t in batch)
b_input_ids, b_input_mask, b_labels = batch
entity_property_model.zero_grad()
loss, _ = entity_property_model(b_input_ids, b_input_mask, b_labels)
loss.backward()
entity_property_total_loss += loss.item()
# print('batch_loss: ', loss.item())
torch.nn.utils.clip_grad_norm_(parameters=entity_property_model.parameters(), max_norm=max_grad_norm)
entity_property_optimizer.step()
entity_property_scheduler.step()
