
Aggregation Function
대표적인 집계함수 종류
- Count(): 정해진 집합 레벨에서 데이터 건수를 계산
- Sum(컬럼): 정해진 집합 레벨에서 지정된 컬럼값의 총합을 계산
- Min(컬럼): 정해진 집합 레벨에서 지정된 컬럼값의 최솟값을 계산
- Max(컬럼): 정해진 집합 레벨에서 지정된 컬럼값의 최댓값을 계산
- Avg(컬럼): 정해진 집합 레벨에서 지정된 컬럼값의 평균값을 계산
- 집계 함수는 NULL을 계산하지 않는다.
- Min, Max 함수의 경우에는 문자열, 날짜, 시간에 적용이 가능하다.
Group by count(distinct) 케이스
다음의 테이블이 있다.
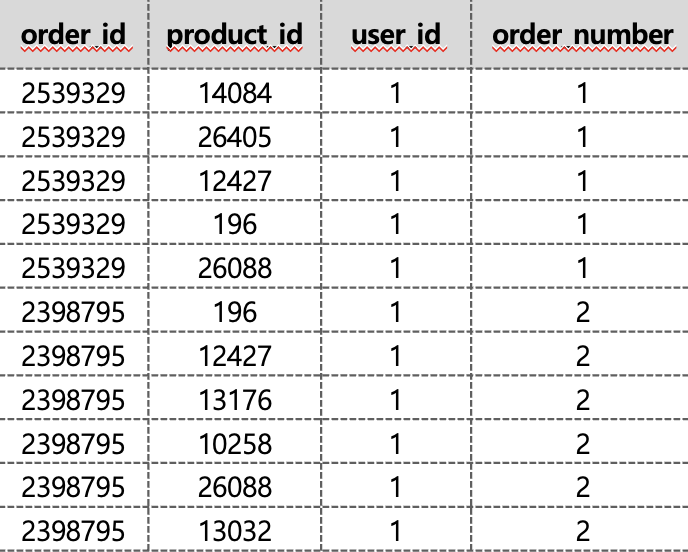
다음은 user_id로 group by된 테이블의 개수를 세는 코드이다.
select user_id, count(*) as cnt from orders group by user_id
--결과: user_id: 1, cnt: 11여기에서 distinct product_id를 추가하자. 중복을 제거한 unique한 product_id의 개수를 세는 것이다.
select user_id, count(distinct product_id) as cnt from orders group by user_id
--결과: user_id: 1, cnt: 8Count 함수에서 distinct를 사용하면 컬럼에서 중복된 값을 제외한 행의 개수를 세는 함수이다.
emp_test 테이블
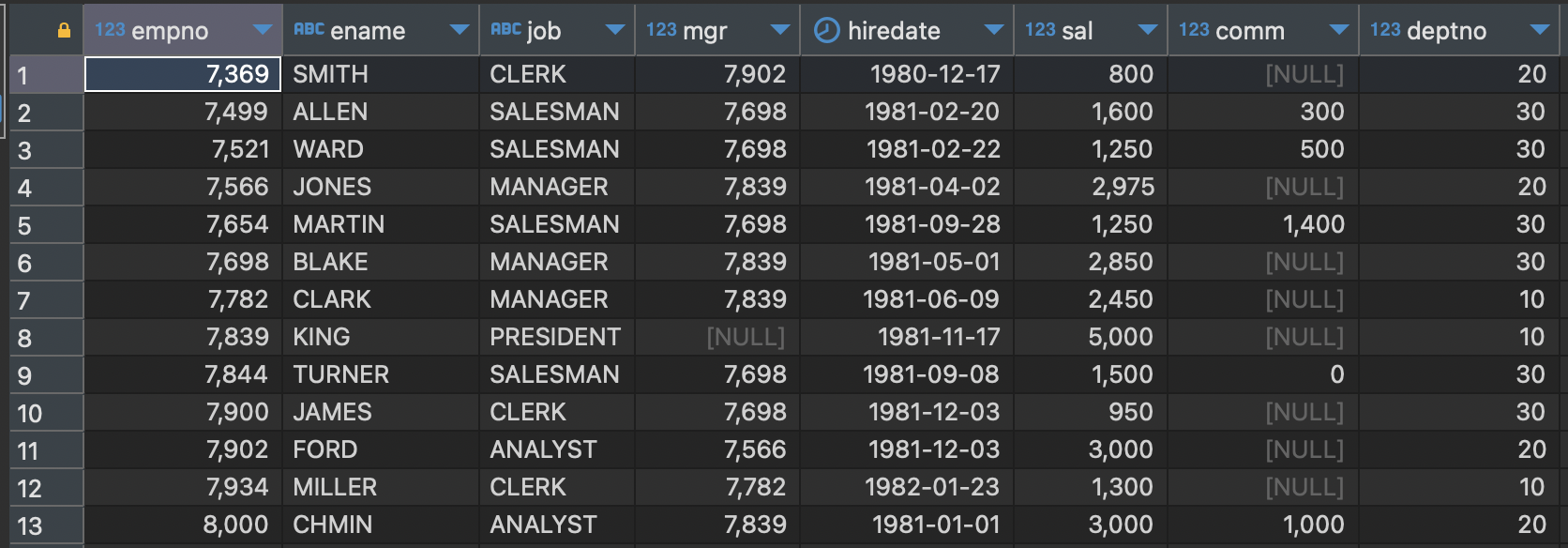
현재 해당 테이블에는 deptno가 10이면 comm은 전부 null값이다. 20에는 comm값이 하나, 30에는 4개가 할당이 되어있다.
다음은 deptno별 comm의 최솟값, 최댓값, 평균, count를 구하는 코드이다.
select deptno, count(*) as cnt, sum(comm), min(comm), avg(comm)
from emp_test
group by deptno 
다음과 같이 deptno가 10인 행은 3개, 30은 6개, 20은 4개이다. 또한 deptno가 10인 경우에는 comm의 값이 전부 null값이므로, sum, min, avg는 다음과 같이 나온다
distinct를 사용하여 unique한 개수 계산
전체 행 개수 출력
select count(1) from hr.emp_test;
--출력: 13job 컬럼에 unique한 개수 계산
select count(distinct job) from hr.emp_test;
--출력: 5
노력하는 개발자