
텍스트 파일을 읽어 데이터를 저장하는 방법입니다. 일반적인 Bulk Insert 보다 훨씬 효과적인 방법입니다.
전체적인 Statement
LOAD DATA
[LOW_PRIORITY | CONCURRENT] [LOCAL] -- (1)
INFILE '파일경로' -- (2)
[REPLACE | IGNORE] -- (3)
INTO TABLE 테이블_명
[PARTITION (partition_name [, partition_name] ...)] -- (4)
[CHARACTER SET charset_name] -- (5)
[{FIELDS | COLUMNS} -- (6)
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES -- (7)
[STARTING BY 'string']
[TERMINATED BY 'string']
]
[IGNORE number {LINES | ROWS}] -- (8)
[(col_name_or_user_var -- (9)
[, col_name_or_user_var] ...)]
[SET 테이블_컬럼1={expr | DEFAULT}
[, 테이블_컬럼2={expr | DEFAULT}] ...](1) LOCAL
데이터 파일이 MySQL 서버가 아닌 다른 컴퓨터에 있을 경우 LOCAL 옵션을 사용하면 됩다.
이때 파일 경로는 URL이 됩니다.
LOAD DATA
LOCAL
INFILE 'http://another-server-url/custmoer.csv'
INTO TABLE customer
CHARACTER SET 'utf-8';(2) 파일 경로
읽어올 텍스트 파일 경로를 입력하면 됩니다.
당연히 MySQL이 설치된 환경에서 접근할 수 있는 경로여야 되겠죠?
(3) 중복키 처리 여부
텍스트 파일을 읽다 중복되는 키를 처리해야 하는 상황이 올 수 있겠죠?
id,name,age
1,kim,26
2,park,29
2,hong,19키를 id로 설정했다면 중복되는 상황이 발생하게 됩니다. MySQL에서는 크게 두가지 처리 방안을 제시하고 있습니다.
- REPLACE : 새로운 row가 기존 row를 덮어씌움 (
2,hong,19가 저장) - IGNORE : 새로운 row를 무시함 (
2,park,29가 저장)
만약 이 키워드 중 아무것도 설정하지 않은 경우에는 오류가 발생하게 됩니다.
만약 최신 로그인 정보만 담고싶다면 REPLACE와 같은 키워드를 둠으로써 처리를 할 수 있을 것이고
만약 각각의 유일성이 반드시 보장되어야 한다면 키워드를 입력하지 않아 오류를 내도록 만들어 두는 것이 좋을 것 같습니다.
(4) 파티셔닝
텍스트 파일을 특정한 규칙을 사용해 나누고 싶은 케이스가 있을 수 있습니다. 이런 경우에 PARTITION을 사용합니다.
기존에 사용하는 파티션 규칙을 따르기 때문에 추가적인 설명은 넘어가도록 하겠습니다.
만약 파티션에 데이터를 입력할 수 없는 경우에는 오류가 발생하게 됩니다.
(5) 인코딩
파일을 읽을 때 문자가 깨질 수가 있습니다. 이를 대비해 CHARACTER SET 을 설정할 수 있습니다.
예를 들어 다음과 같은 텍스트 파일이 있다고 해봅시다.
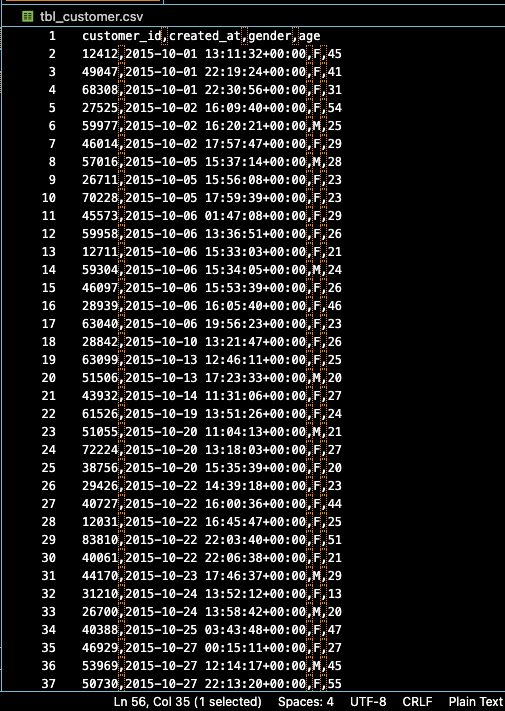
다음과 같은 경우라면 UTF-8이 되겠군요!
LOAD DATA
INFILE '/samples/customer.csv'
INTO TABLE customer
CHARACTER SET 'utf-8';(6), (7) 필드 & 라인 파싱
텍스트 파일 데이터를 어떻게 파싱할 지 결정하는 키워드입니다. 다음과 같은 예시가 있다고 해보죠
id,name,age
data1,kim,26
data2,park,29
이건,읽지,마세요STARTING_BY
STARTING_BY는 각 유효한 데이터의 prefix를 정하는 키워드입니다.
파싱을 원하는 데이터들 앞에는 반드시 입력한 키워드가 존재해야 합니다.
위의 예시에서는 prefix로 data가 있는 row들만 읽고 싶습니다. 이런 경우에는 다음과 같이 작성할 수 있습니다.
LOAD DATA
INFILE '/samples/customer.csv'
INTO TABLE customer
LINES STARTING BY 'data'
TERMINATED BY '\n';TERMINATED_BY
각각의 데이터들은 (,)로, row들은 줄건너띄기 (\n)으로 이루어져 있습니다. 이런 경우에는 TERMINATED BY ',', TERMINATED BY '\n'을 사용하게 됩니다.
LOAD DATA
INFILE '/samples/customer.csv'
INTO TABLE customer
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';(8) 데이터 건너뛰기
CSV의 제목부분은 굳이 데이터로 읽지 않아도 됩니다. 이런 경우에 IGNORE number {LINES | ROWS} 를 사용해 건너뛰기가 가능합니다.
id,name,age
data1,kim,26
data2,park,29
이건,읽지,마세요위의 데이터는 제목 부분을 건너뛰기를 해야 하기 때문에 다음과 같은 SQL로 작성이 가능합니다.
LOAD DATA
INFILE '/samples/customer'
INTO TABLE customer
IGNORE 1 LINES -- 한줄 건너뛰기(9) 데이터를 테이블로 파싱
기본적으로 Table의 Columns를 텍스트 파일의 순서에 맞게 매칭을 시키면 됩니다. 아래의 예시라면 다음과 같이 표현이 가능합니다.
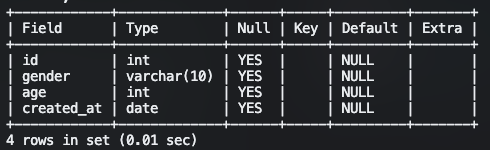
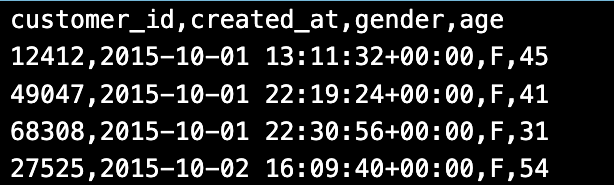
LOAD DATA
INFILE '/samples/customer.csv'
INTO TABLE customer
...
(id, created_at, gender, age) -- Table Columns들을 순서에 맞게 매칭PLUS. 데이터 파일의 값의 개수 != 테이블의 칼럼 수
위의 케이스는 데이터 파일 값의 개수와 테이블 컬럼의 개수가 일치하는 경우였습니다. 만약 다르다면 어떻게 처리를 해줘야할까요?
1. 데이터 파일의 값의 개수 < 테이블의 칼럼 수
만약 테이블의 칼럼 수가 더 많다면 나머지 칼럼에 대해서는 SET 절을 이용해 초기 값을 명시해야 합니다.
(해당 칼럼이 NULL 값이 허용된다면 굳이 명시하지 않아도 됩니다.)
id,birth_date
1,2021-01-01
2,2019-01-01
3,2011-01-01
4,2000-01-01
5,2022-01-01
+------------+------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| birth_date | date | YES | | NULL | |
| age | int | YES | | NULL | |
+------------+------+------+-----+---------+-------+위의 데이터를 아래의 테이블로 입력한다면 다음과 같은 sql문을 작성해야 합니다.
LOAD DATA
INFILE '/var/lib/mysql-files/test.csv'
INTO TABLE test
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
IGNORE 1 LINES (id, birth_date)
SET age = year(now()) - year(birth_date)2. 데이터 파일의 값의 개수 > 테이블의 칼럼 수
일단 데이터 파일의 값을 사용자 변수로 읽은 후에 버리면 됩니다.
id,name,gender,birth_date,age
1,kim,M,2000-01-01,23
2,park,F,2001-01-01,22
3,hong,F,2002-01-01,21
4,koo,M,2003-01-01,20
5,lee,F,2004-01-01,19
+------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+--------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
| gender | varchar(10) | YES | | NULL | |
| age | int | YES | | NULL | |
+------------+--------------+------+-----+---------+-------+위의 경우에는 age가 제공되기 때문에 birth_date 를 사용해 굳이 나이 계산을 안해도 됩니다. 이런 경우 사용자 변수를 사용해 더미 데이터로 변환하면 됩니다.
LOAD DATA
INFILE '/var/lib/mysql-files/test.csv'
INTO TABLE test
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
IGNORE 1 LINES (id, name, gender, @birth_date, age) 