기본기
1.리스트 관련 함수

insert(n, c) n 위치에 c를 삽입 pop(n) n번째 위치의 원소를 반환하고 제거 인자를 주지 않고 pop()과 같이 사용하면 마지막 원소를 반환하고 제거 remove(c) c를 찾아 제거 c가 여러개일 경우 가장 앞의 c를 제거 reverse() li
2.lambda, map 등
lambda lambda는 위와같이 표현된다. 그래서 함수를 한 줄로 줄여서 쓸 수 있다는 것. 람다는 sort에서 유용하게 사용된다. 1번의 경우엔 list의 각 원소의 길이에 따라 정렬이 가능하며, 2번의 경우 list의 각 원소의 첫번째 원소에 따라 정렬이
3.프로그래머스 level 0 정리
range(2,n+1,2)로 짝수만 구할 수 있다.range는 iterable한 객체를 반환하므로 sum에 바로 넣을 수 있다.list.reverse()하면 반환 값 없이 list를 뒤집는다.list\[::-1]와 같이 슬라이싱에서 증가량을 이용한 방법이 있다.stri
4.MySQL 정리
수정중에 있습니다. 참고 바랍니다 ORDER 내림차순 위와같이 컬럼명 뒤 DESC를 붙여 내림차순으로 정렬이 가능하다. IN IN 두 개 이상의 값에 해당하는 데이터만 조회하고싶다면 IN을 사용할 수 있다. 와 같이 사용한다면 MCDP_CD값이 CS이거나
5.MYSQL) RANK 함수
RANK 함수는 말 그대로 순위를 매기는 함수이다. RANK() OVER(\[PARTITION BY COLUMN_1] ORDER BY COLUMN_2 \[DESC])위와 같이 사용되는데, 여기서 파티션은 그룹별로 그룹 내에서 랭킹을 매길 때 사용한다.나같은 경우는 해당
6.MYSQL) Recursive 문법
sql에서 재귀를 쓰는 방법이다!나는 해당 문제를 풀 때, 하드코딩(?)을 사용했는데 다른 사람들이 푼 걸 보니 재귀를 사용하길래 찾아봤다.기본 구조는 위와 같다.UNION ALL 윗 부분이 비재귀 부분이며 초기값을 설정한다.UNION ALL을 통해서 위와 아래 쿼리를
7.[MySQL] group by에서 select 절의 alias를 사용할 수 있나? 인덱스는?
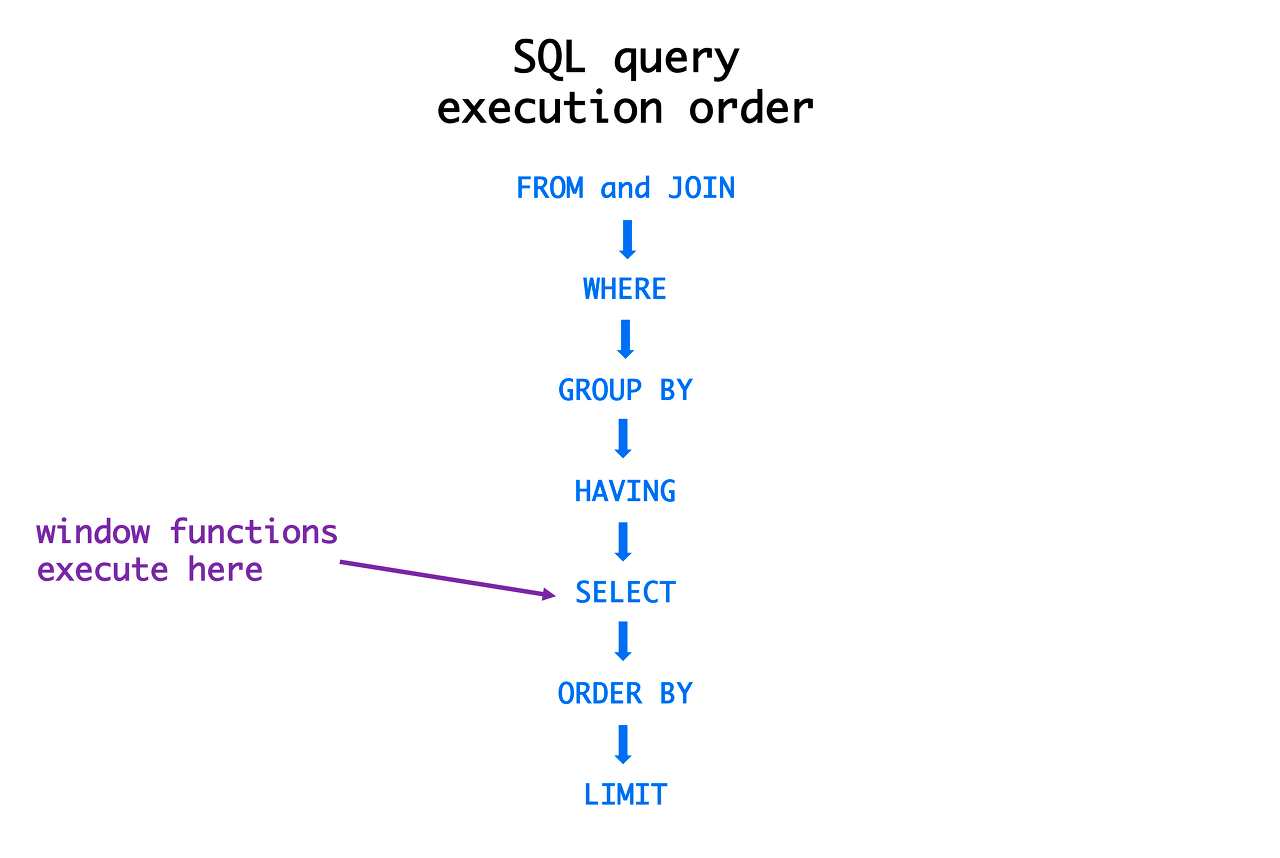
코테 연습을 하다가 갑작스레 궁금해졌다.group by절은 select보다 먼저 실행되는데 어떻게 alias를 사용해도 되지?대답은,, mysql에서 가능한 것이라고 한다. 즉 DBMS가 알아서 처리해준다는 말씀사실 내가 궁금했던건 따로 있는데, 바로 group by
8.프로그래머스 level 1,2 정리
증가폭이 0이면 안된다.range에서 3번째 인자인 증가폭(step)이 0일 경우 오류 남! 유의해서 코드 작성하기reversed문자열을 뒤집어주는 함수. 참고: 리스트는 ::-1과 같이 쓸 수 있음deldel arr\[1]과 같이 사용함poparr.pop(1)과 같이