📌Arrays - 배열을 다루기 편리한 메서드(static) 제공
toString(), deepToString()
: 배열의 출력. 다양한 타입의 배열을 문자열 형태로 출력
int[] arr = {0,1,2,3,4};
int[][] arr2D = {{11,12,13}, {21,22,23}};
System.out.println("arr = "+Arrays.toString(arr));
System.out.println("arr2D = "+Arrays.deepToString(arr2D));arr = [0, 1, 2, 3, 4]
arr2D = [[11, 12, 13], [21, 22, 23]]
- deepToString() : 다차원 배열을 출력할 때 사용
copyOf(), copOfRange()
: 배열의 복사. 새로운 배열을 생성해서 반환
int[] arr2 = Arrays.copyOf(arr, arr.length);
int[] arr3 = Arrays.copyOf(arr, 3);
int[] arr4 = Arrays.copyOf(arr, 7);
int[] arr5 = Arrays.copyOfRange(arr, 2, 4);
int[] arr6 = Arrays.copyOfRange(arr, 0, 7);
System.out.println("arr2 = " + Arrays.toString(arr2));
System.out.println("arr3 = " + Arrays.toString(arr3));
System.out.println("arr4 = " + Arrays.toString(arr4));
System.out.println("arr5 = " + Arrays.toString(arr5));
System.out.println("arr6 = " + Arrays.toString(arr6));arr2 = [0, 1, 2, 3, 4]
arr3 = [0, 1, 2]
arr4 = [0, 1, 2, 3, 4, 0, 0]
arr5 = [2, 3]
arr6 = [0, 1, 2, 3, 4, 0, 0]
Arrays.copyOfRange(arr, 0, 7);: 뒤에 남는 나머지 공간은 0으로 채운다.
fill(), setAll()
: 배열 채우기
int[] arr7 = new int[5];
Arrays.fill(arr7, 9);
System.out.println("arr7 = " + Arrays.toString(arr7));
Arrays.setAll(arr7, i -> (int) (Math.random() * 6) + 1);
System.out.println("arr7 = " + Arrays.toString(arr7));arr7 = [9, 9, 9, 9, 9]
arr7 = [5, 3, 6, 2, 5]
Arrays.fill(arr7, 9);: arr7 배열을 9로 채운다.i -> (int) (Math.random() * 6) + 1: 람다식. 1~6까지의 난수로 채운다.
sort(), binarySearch()
: 배열의 정렬과 탐색. binarySearch() - 이진 탐색
char[] chArr = {'C', 'A', 'D', 'B', 'E'};
System.out.println("chArr = " + Arrays.toString(chArr));
System.out.println("index of B = " + Arrays.binarySearch(chArr, 'B'));
System.out.println("= After sorting = ");
Arrays.sort(chArr);
System.out.println("chArr = " + Arrays.toString(chArr));
System.out.println("index of B = " + Arrays.binarySearch(chArr, 'B'));chArr = [C, A, D, B, E]
index of B = -1
= After sorting =
chArr = [A, B, C, D, E]
index of B = 1
Arrays.binarySearch(chArr, 'B');: 결과는 -1.binarySearch()는 정렬된 배열에서만 사용 가능하다.Arrays.sort(chArr);로 정렬 후Arrays.binarySearch(chArr, 'B');하니까 제대로 된 결과인 1이 나온다.
순차 탐색과 이진 탐색
순차 탐색 : 정렬하지 않고 처음부터 순서대로 탐색하는 방법
- 10개의 요소 중 평균 5.5회 만에 탐색한다.
이진 탐색 : 정렬 후에 반복적으로 반으로 나눠서 탐색하는 방법
- 반으로 나눈 후 가운데 요소와 찾는 요소와 비교해서 계속 범위를 줄여나간다.
- 10개의 요소 중 평균 3~4번 만에 탐색한다.
- 탐색을 하기 전 정렬을 해야만 한다는 단점이 있다.
deepEquals()
: 다차원 배열의 비교
String[][] str2D = new String[][]{{"aaa", "bbb"}, {"AAA", "BBB"}};
String[][] str2D2 = new String[][]{{"aaa", "bbb"}, {"AAA", "BBB"}};
System.out.println(Arrays.equals(str2D, str2D2));
System.out.println(Arrays.deepEquals(str2D, str2D2)); false
true
- 다차원 배열을 비교할 땐
equals()대신deepEquals()사용
asList(Object... a)
: 배열을 List로 변환. (Object... a) - 갯수가 정해져 있지 않은 가변 매개변수
List list = Arrays.asList(1,2,3,4,5);
list.add(6); // UnsupportedOperationException 예외 발생
List list = new ArrayList(Arrays.asList(1,2,3,4,5));
list.add(6); // 가능-
List list = Arrays.asList(1,2,3,4,5);: 읽기만 가능하다.add()메서드 사용 불가 -
new ArrayList(Arrays.asList(1,2,3,4,5));: List의 내용을 복사해서 List를 생성자로 하는 new ArrayList를 새로 만들면 변경이 가능하다.
📌Comparator와 Comparable
객체 정렬에 필요한 메서드(정렬 기준 제공)를 정의한 인터페이스
- Comparable : 기본 정렬 기준을 구현하는데 사용
- Comparator : 기본 정렬 기준 외에 다른 기준으로 정렬할 때 사용
public interface Comparable {
int compareTo(Object o);
}
public interface Comparator {
int compare(Object o1, Object o2);
}int compareTo(Object o);: 주어진 객체(o)를 자신과 비교int compare(Object o1, Object o2);: o1, o2 두 객체를 비교- 반환 타입이 int인 이유
- 0이면 두 객체가 같다.
- 양수면 왼쪽이 크다.
- 음수면 오른쪽이 크다.
정렬은 1. 두 객체를 비교 2. 자리 바꿈 이 2가지를 반복하는 것이다.
실습 예제
class Ex11_7 {
public static void main(String[] args) {
String[] strArr = {"cat", "Dog", "lion", "tiger"};
Arrays.sort(strArr); // String의 Comparable 구현에 의한 정렬
System.out.println("strArr=" + Arrays.toString(strArr));
Arrays.sort(strArr, String.CASE_INSENSITIVE_ORDER); // 대소문자 구분안함
System.out.println("strArr=" + Arrays.toString(strArr));
Arrays.sort(strArr, new Descending()); // 역순 정렬
System.out.println("strArr=" + Arrays.toString(strArr));
}
}
class Descending implements Comparator {
public int compare(Object o1, Object o2){
if( o1 instanceof Comparable && o2 instanceof Comparable) {
Comparable c1 = (Comparable)o1;
Comparable c2 = (Comparable)o2;
return c1.compareTo(c2) * -1 ;
}
return -1;
}
}strArr=[Dog, cat, lion, tiger]
strArr=[cat, Dog, lion, tiger]
strArr=[tiger, lion, cat, Dog]
-
Arrays.sort(strArr);: 정렬 기준은 String의 Comparable 구현에 의한 정렬이다. 객체 배열에 저장된 객체(strArr)가 정렬 기준을 구현하고 있어야지만 정렬 기준을 생략할 수 있다. -
strArr=[Dog, cat, lion, tiger]: Comparable 인터페이스는 기본 정렬 기준을 제공한다. 문자열의 기본 정렬 기준을 사전순서이다. 따라서 대문자가 먼저 오고 그 다음 알파벳 순서대로 정렬이 된다. -
Arrays.sort(strArr, String.CASE_INSENSITIVE_ORDER);: 정렬 기준은String.CASE_INSENSITIVE_ORDER- 대소문자 구분안하는 정렬 기준
class Descending implements Comparator {
public int compare(Object o1, Object o2){
if( o1 instanceof Comparable && o2 instanceof Comparable) {
Comparable c1 = (Comparable)o1;
Comparable c2 = (Comparable)o2;
return c1.compareTo(c2) * -1; // c2.compareTo(c1); 도 가능
}
return -1;
}
}-
Comparator 인터페이스의
compare(Object o1, Object o2)메서드를 오버라이딩해서 구현해준다. -
c1.compareTo(c2) * -1;: 기본 정렬 기준에 * -1을 해줌으로써 오름차순이었던 정렬 기준을 내림차순으로 바꿔준다. -
c2.compareTo(c1);으로 해도 정렬 기준이 내림차순으로 바뀐다.
Integer와 Comparable
public final class Integer extends Number implements Comparable<Integer> {
...
public int compareTo(Integer anotherInteger) {
return compare(this.value, anotherInteger.value);
}
public static int compare(int x, int y) {
return (x < y) ? -1 : ((x == y) ? 0 : 1);
}
...
}-
return (x < y) ? -1 : ((x == y) ? 0 : 1);: 비교하는 값이 같으면 0, 오른쪽(y)이 크면 -1, 왼쪽(x)이 크면 1 반환 -
Integer, String, Double 등의 클래스들은 기본 정렬 기준을 제공하는 Comparable 인터페이스를 구현하고 있다. 정렬 기준이 없을 때 기본 정렬 기준을 제공한다.
-
정렬 방법은 이미 코드가 잘 짜여져 있다.(불변) 따라서, 정렬 기준(가변)만 우리가 제공해주면 된다.
📌HashSet - 순서X, 중복X
: Set 인터페이스를 구현한 대표적인 컬렉션 클래스
- 순서를 유지하려면 LinkedHashSet 클래스를 사용
TreeSet
- 범위 검색과 정렬에 유리한 컬렉션 클래스
- HashSet 보다 데이터 추가, 삭제에 시간이 더 걸린다.
HashSet의 메서드
생성자
-
HashSet() : 기본 생성자
-
HashSet(Collection c) : 컬렉션끼리 변환할 때 사용하는 생성자
-
HashSet(int initialCapacity) : 초기 용량 정해주는 생성자
-
HashSet(int initialCapacity, float loadFactor) : loadFactor 만큼 용량이 차면 용량을 x2 해준다.(loadFactor = 0.8 -> 80% 찼을 때)
주요 메서드
-
boolean add(Object o) : 추가
-
boolean addAll(Collection c) : 합집합
-
boolean remove(Object o) : 삭제
-
boolean removeAll(Collection c) : 차집합
-
boolean retainAll(Collection c) : 교집합
-
void clear() : 전체 삭제
-
boolean contains(Object o) : 객체(o)를 포함하고 있는지
-
boolean containsAll(Collection c) : 컬렉션(c)에 담긴 객체들이 모두 포함하고 있는지
-
Iterator iterator() : 컬렉션의 요소들을 읽어오는 메서드
-
boolean isEmpty() : 비어있으면 true
-
int size() : 저장된 객체의 개수 반환
-
Object[] toArray() : Set에 저장되어 있는 객체를 객체 배열로 반환
-
Object[] toArray(Object[] a) : Set에 저장되어 있는 객체를 객체 배열로 반환
실습 예제
Object[] objArr = {"1", new Integer(1), "2", "3", "3", "4", "4"};
Set set = new HashSet();
for (int i = 0; i < objArr.length; i++) {
set.add(objArr[i]);
}
System.out.println(set);[1, 1, 2, 3, 4]
-
중복은 전부 제거되었다.
-
1이 2개 있는 이유는 하나는 문자열 "1" 이고 나머지 하나는 new Integer(1) 이기 때문이다.
로또 번호 6자리 출력하는 예제
Set set = new HashSet();
for (int i = 0; i < set.size() < 6; i++) {
int num = (int)(Math.random() * 45) + 1;
set.add(num);
}
List list = new LinkedList(set); // LinkedList(Collection c)
Collections.sort(list); // Collections.sort(List list)
System.out.println(list);[5, 12, 18 ,22, 33, 44]
-
for 문은
Math.random()을 이용해서 6개의 난수 번호를 set에 저장한다. -
Collections.sort(List list)은 정렬해주는 메서드인데 매개변수로 List 인터페이스만 올 수 있다. 따라서, Set 은 정렬을 할 수 없기 때문에LinkedList(Collection c)생성자를 이용해서 Set을 List로 변환해주고Collections.sort(List list)로 정렬해준다.
HashSet은 객체를 저장하기 전에 기존에 같은 객체가 있는지 확인한다. 같은 객체가 없으면 저장하고, 있으면 저장하지 않는다.
boolean add(Object o)는 저장할 객체의 equals()와 hashCode()를 호출한다. 따라서 equals()와 hashCode()가 오버라이딩 되어 있어야 한다.
class Ex11_11 {
public static void main(String[] args) {
HashSet<Person> set = new HashSet<>();
set.add(new Person("David",10));
set.add(new Person("David",10));
System.out.println(set);
}
}
class Person {
String name;
int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
public String toString() {
return name +":"+ age;
}
}[David:10, David:10]
- Person 클래스에서 equals()와 hashCode()를 오버라이딩 해주지 않아서 HashSet에 중복으로 저장이 된다.
equals()와 hashCode() 오버라이딩하는 방법
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public boolean equals(Object obj) {
if (!(obj instanceof Person)) return false;
Person p = (Person) obj;
return this.name.equals(p.name) && this.age == p.age;
}[David:10]
- equals()와 hashCode() 오버라이딩하니까 중복이 제거되었다.
집합 예제
class Ex11_12 {
public static void main(String args[]) {
HashSet setA = new HashSet();
HashSet setB = new HashSet();
HashSet setHab = new HashSet();
HashSet setKyo = new HashSet();
HashSet setCha = new HashSet();
setA.add("1"); setA.add("2"); setA.add("3");
setA.add("4"); setA.add("5");
System.out.println("A = "+setA);
setB.add("4"); setB.add("5"); setB.add("6");
setB.add("7"); setB.add("8");
System.out.println("B = "+setB);
Iterator it = setB.iterator();
// 교집합
while(it.hasNext()) {
Object tmp = it.next();
if(setA.contains(tmp))
setKyo.add(tmp);
}
// 차집합
it = setA.iterator();
while(it.hasNext()) {
Object tmp = it.next();
if(!setB.contains(tmp))
setCha.add(tmp);
}
// 합집합
it = setA.iterator();
while(it.hasNext())
setHab.add(it.next());
it = setB.iterator();
while(it.hasNext())
setHab.add(it.next());
System.out.println("A ⋂ B = " + setKyo);
System.out.println("A U B = " + setHab);
System.out.println("A - B = " + setCha);
}
}A = [1, 2, 3, 4, 5]
B = [4, 5, 6, 7, 8]
A ⋂ B = [4, 5]
A U B = [1, 2, 3, 4, 5, 6, 7, 8]
A - B = [1, 2, 3]
교집합, 차집합, 합집합 더 쉽게 구하는 방법
setA.retainAll(setB); // 교집합
setA.addAll(setB); // 합집합
setA.removeAll(setB); // 차집합-
setA.retainAll(setB);: 교집합. 공통된 요소만 남기고 삭제 -
setA.addAll(setB);: 합집합. setB의 모든 요소를 추가(중복 제외) -
setA.removeAll(setB);: 차집합. setB와 공통 요소를 제거
📌TreeSet - 범위 탐색, 정렬
이진 탐색 트리(binary search tree)로 구현. 범위 탐색과 정렬에 유리
이진 트리는 모든 노드가 최대 2개(0~2개)의 하위 노드를 갖는다.
- 각 요소(node)가 나무(tree)형태로 연결되어있다.(LinkedList의 변형)
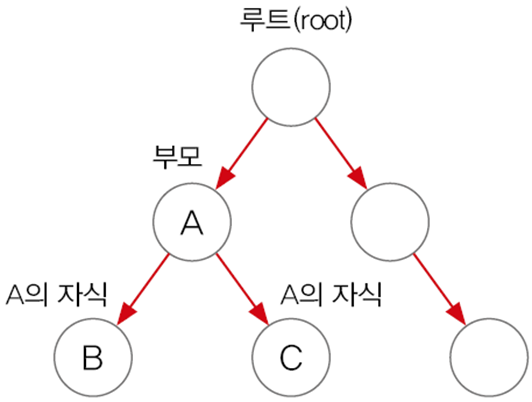
class TreeNode {
TreeNode left; // 왼쪽 자식노드
Object element; // 저장할 객체
TreeNode right; // 오른쪽 자식노드
}- 노드 하나를 트리노드라고 부르고 총 3개의 변수가 저장되어 있다.
이진 탐색 트리(Binary search tree)
부모보다 작은 값은 왼쪽. 큰 값은 오른쪽에 저장한다.
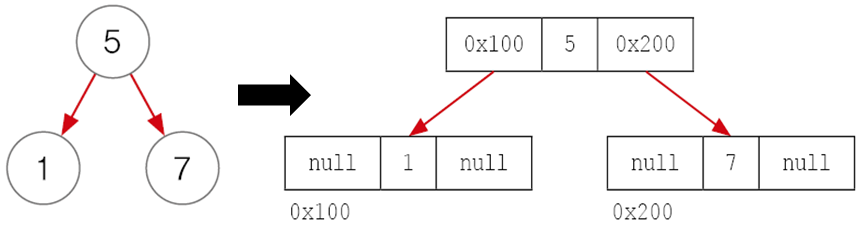
단점 : 데이터가 많아질수록 비교 횟수 증가에 따라 추가, 삭제에 시간이 더 걸린다.
TreeSet 데이터 저장 과정
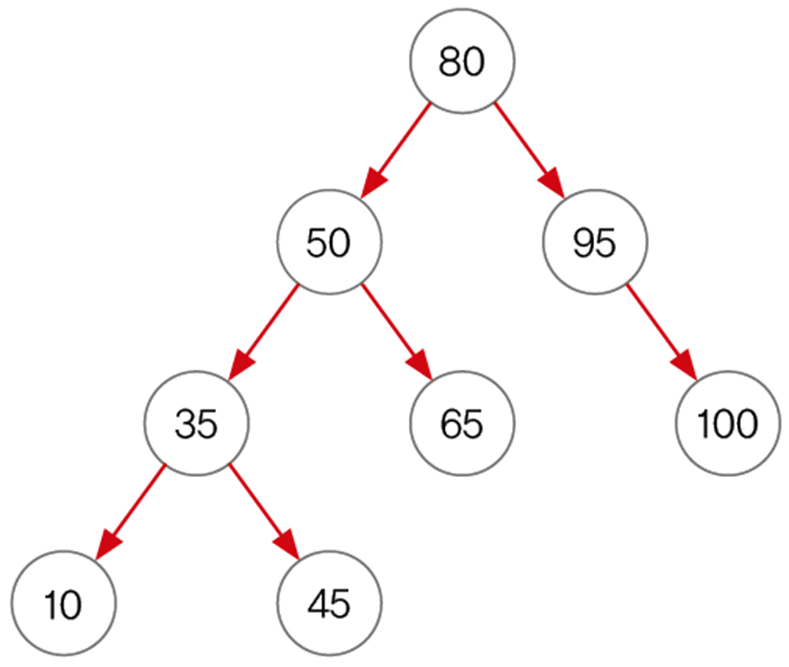
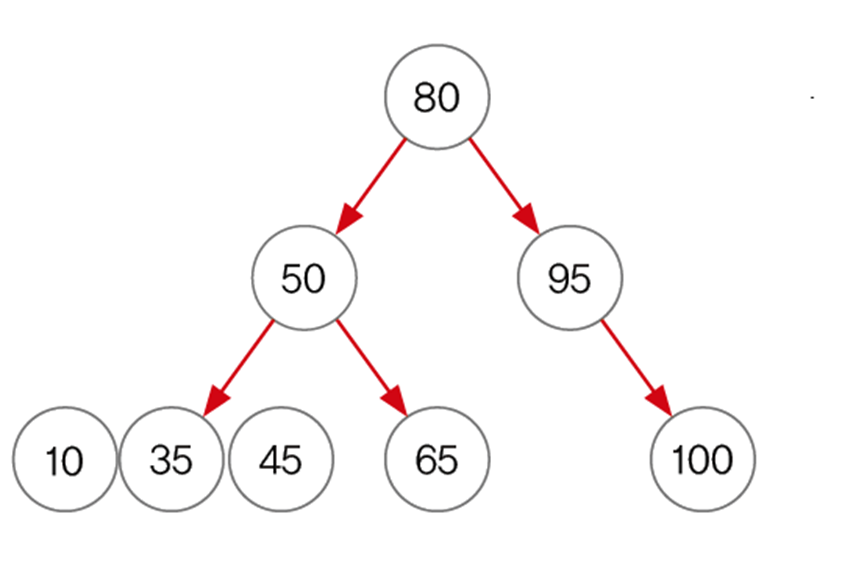
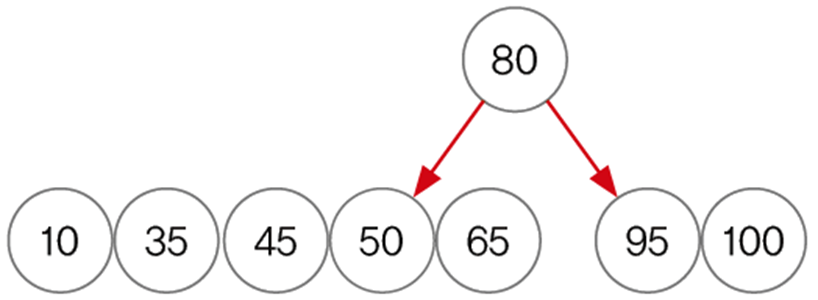
TreeSet에 7, 4, 9, 1, 5의 순서로 데이터를 저장하면 아래의 과정을 거친다.
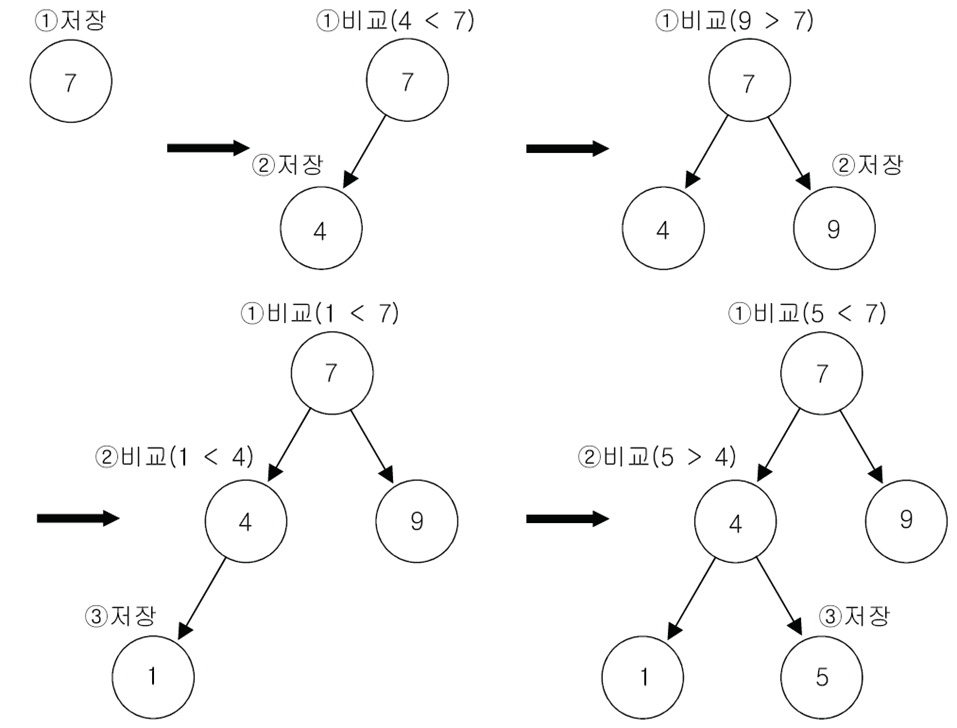
- 요소를 저장해감에 따라 비교 횟수가 점점 늘어나면서 저장하는 시간이 많이 걸린다.
TreeSet의 메서드
add(), remove(), size(), iterator()와 같은 기본적인 메서드들은 적지 않았다.
생성자
-
TreeSet() : 기본 생성자. 정렬 기준이 없으면 저장하는 객체의 기본 정렬 기준인 Comparable 사용
-
TreeSet(Collection c) : 컬렉션(c)를 TreeSet으로 변환하는 생성자
-
TreeSet(Comparator comp) : 주어진 정렬 기준으로 정렬하는 생성자
주요 메서드
-
Object first() : 정렬된 순서에서 첫 번째 객체를 반환한다.(오름차순일 때 제일 작은 값)
-
Object last() : 정렬된 순서에서 마지막 객체를 반환한다.(오름차순일 때 제일 큰 값)
-
Object ceiling(Object o) : 객체(o)와 같은 객체를 반환. 없으면 객체보다 큰 값 중 가장 가까운 값의 객체를 반환. 없으면 null
-
Object floor(Object o) : 객체(o)와 같은 객체를 반환. 없으면 객체보다 작은 값 중 가장 가까운 값의 객체를 반환. 없으면 null
-
Object higher(Object o) : 객체(o)보다 큰 값 중 가장 가까운 값의 객체를 반환. 없으면 null
-
Object lower(Object o) : 객체(o)보다 작은 값 중 가장 가까운 값의 객체를 반환. 없으면 null
-
SortedSet subSet(Object from, Object to) : from~to 사이의 값을 반환한다.(to 포함x)
-
SortedSet headSet(Object to) : to보다 작은 값의 객체들을 반환한다.
-
SortedSet tailSet(Object from) : from보다 큰 값의 객체들을 반환한다.
실습 예제
Set set = new TreeSet();
for (int i = 0; set.size() < 6 ; i++) {
int num = (int)(Math.random()*45) + 1;
set.add(num); // set.add(new Integer(num));
}
System.out.println(set);[11, 15, 20, 33, 36, 40]
- TreeSet은 따로 정렬을 하지 않아도 자동으로 정렬이 된다.
- Integer 클래스가 Comparable 구현의 의한 기본 정렬 기준을 가지고 있다.
class Ex11_13 {
public static void main(String[] args) {
Set set = new TreeSet();
set.add(new Test());
System.out.println(set);
}
}
class Test {}Exception in thread "main" java.lang.ClassCastException
에러가 난다.
- 에러가 나는 이유는 비교 기준이 없기 때문이다.
비교 기준을 만들어준다.
class Ex11_13 {
public static void main(String[] args) {
Set set = new TreeSet(new TestComp()); // 정렬 기준 넣어준다.
//Set set = new TreeSet();
set.add(new Test());
System.out.println(set);
}
}
class Test implements Comparable {
public int compareTo(Object o) {
return 0;
}
}
class TestComp implements Comparator {
public int compare(Object o1, Object o2) {
return 0;
}
}-
Set set = new TreeSet(new TestComp());: Comparator 인터페이스를 구현한 정렬 기준을TreeSet(Comparator comp)생성자를 통해 정의해준다. -
Set set = new TreeSet();: Test 클래스가 Comparable 인터페이스를 구현한다면 정렬 기준을 적지 않아도 기본 정렬 기준으로 정렬된다. -
TreeSet 클래스는 정렬 기준이 필요하기 때문에 1. 저장할 객체가 Comparable구현에 의한 정렬 기준을 가지고 있던가 2. TreeSet이 생성자를 통해 정렬 기준을 가지고 있던가 둘 중 하나는 해야 한다.
class Ex11_15 {
public static void main(String[] args) {
TreeSet set = new TreeSet();
int[] score = {80, 95, 50, 35, 45, 65, 10, 100};
for(int i=0; i < score.length; i++)
set.add(new Integer(score[i]));
System.out.println("50보다 작은 값 :" + set.headSet(new Integer(50)));
System.out.println("50보다 큰 값 :" + set.tailSet(new Integer(50)));
System.out.println("40~80사이의 값 :" + set.subSet(40, 80));
}
}50보다 작은 값 :[10, 35, 45]
50보다 큰 값 :[50, 65, 80, 95, 100]
40~80사이의 값 :[45, 50, 65]
-
set.headSet(new Integer(50));: 50보다 작은 값. 50 포함X -
set.tailSet(new Integer(50));: 50보다 큰 값. 50 포함O -
set.subSet(40, 80): 40 ~ 80 사이의 값. 80 포함X
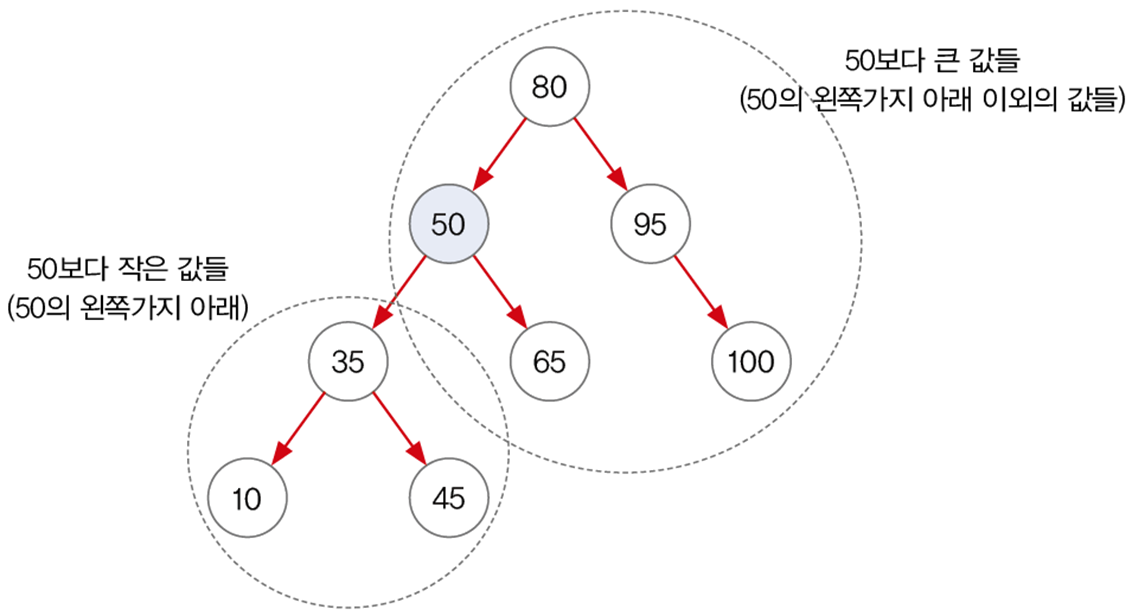
-
이런 방식으로 동작하기 때문에 범위 검색에 유리하다.
트리 순회(Tree traversal)
: 이진 트리의 모든 노드를 한번씩 읽는 것
- 전위, 중위, 후위 순회법이 있으며, 중위 순회하면 오름차순으로 정렬된다.

- 이러한 동작 방식 때문에 TreeSet은 정렬에 유리하다.
📌HashMap - 순서X, 중복(키X, 값O)
: Map 인터페이스를 구현. 데이터를 키와 값의 쌍으로 저장
- 순서를 유지하려면 LinkedHashMap 클래스를 사용
Hashtable은 동기화O, HashMap은 동기화X
TreeMap - TreeSet과 특성이 유사
- 범위 검색과 정렬에 유리한 컬랙션 클래스
- HashMap보다 데이터 추가, 삭제에 시간이 더 걸린다.
HashMap의 키(key)와 값(value)
해싱(hashing)기법으로 데이터를 저장한다. 데이터가 많아도 검색이 빠르다.
키는 중복이 안되고 값은 중복이 된다.
HashMap<String, String> hashMap = new HashMap<>();
hashMap.put("myid", "asdf");
hashMap.put("yourid", "1122");
hashMap.put("yourid", "asdf");| 키(key) | 값(value |
|---|---|
| myid | asdf |
| yourid | asdf |
hashMap.put("yourid", "asdf");: 같은 키에 다른 값을 2번 넣으면 나중에 넣은 값이 덮어쓴다.
키(key)와 값(value) 한 쌍이 Entry[] table 이라는 엔트리 배열에 저장된다.
해싱(Hashing)
: 해시 함수(hash function)로 해시 테이블에 데이터를 저장, 검색하는 기법
해시 테이블은 배열과 LinkedList가 조합된 형태이다.
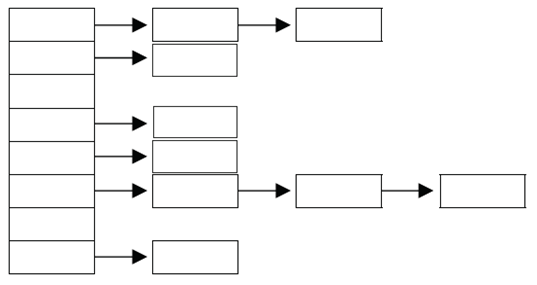
- 배열의 장점인 접근성과 LinkedList의 장점인 변경에 유리함을 조합한 것이다.
해시 테이블에 저장된 데이터를 가져오는 과정
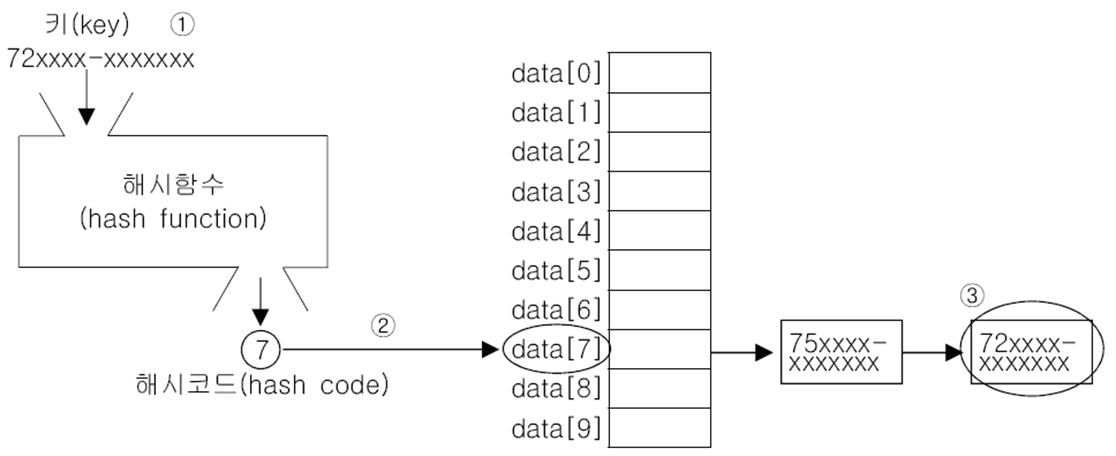
-
키(key)로 해시 함수를 호출해서 해시 코드(배열의 index)를 얻는다.
-
해시 코드(해시 함수의 반환값)에 대응하는 LinkedList를 배열에서 찾는다.
-
LinkedList에서 키(key)와 일치하는 데이터를 찾는다.
- 해시 함수는 같은 키에 대해 항상 같은 해시 코드(배열의 index)를 반환해야 한다.
- 서로 다른 키가 같은 값의 해시 코드를 반환할 수 있다.(75xxx와 72xxx의 해시 코드는 모두 7이다. = 같은 배열 data[7]에 있다.)
HashMap의 메서드
생성자
-
HashMap() : 기본 생성자
-
HashMap(int initialCapacity) : HashMap은 해시 테이블에 데이터를 저장한다. 해시 테이블은 배열 + LinkedList로 이루어져 있기 때문에 생성자를 통해 배열의 초기 용량을 정해줄 수 있다.
-
HashMap(int initialCapacity, float loadFactor) : 용량이 loadFactor만큼 차면 용량을 x2 해주는 생성자
-
HashMap(Map m) : 다른 Map을 HashMap으로 변환해주는 생성자
주요 메서드
-
Object put(Object key, Object value) : 키(key)와 값(value)을 저장
-
void putAll(Map m) : Map의 데이터들이 전부 저장된다.
-
Object remove(Object key) : 키로 저장된 값(객체)을 제거
-
Object replace(Object key, Object value) : 지정된 키의 값을 지정된 값으로 변경
-
boolean replace(Object key, Object oldValue, Object newValue) : 지정된 키(key)와 값(oldValue)을 새로운 값(newValue)으로 변경
-
Set entrySet() : 키와 값이 쌍으로 이루어진 entry를 Set 타입으로 저장해서 반환
-
Set keySet() : 저장된 모든 키를 Set 타입으로 저장해서 반환
-
Collection values() : 저장된 모든 값을 Collection 타입으로 저장해서 반환
-
Object get(Object key) : 키에 해당하는 값을 반환
-
Object getOrDefault(Object key, Object dafaultValue) : 해당하는 키가 없을 때 dafaultValue 값을 반환
-
boolean containsKey(Object key) : 지정된 키를 포함하고 있으면 true
-
boolean containsValue(Object value) : 지정된 값을 포함하고 있으면 true
-
Object clone() : 복제하는 메서드
실습 예제
로그인
class Ex11_16 {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("myId", "1234");
map.put("asdf", "1111");
map.put("asdf", "1234");
Scanner s = new Scanner(System.in); // 화면으로부터 라인단위로 입력받는다.
while(true) {
System.out.println("id와 password를 입력해주세요.");
System.out.print("id :");
String id = s.nextLine().trim();
System.out.print("password :");
String password = s.nextLine().trim();
System.out.println();
if(!map.containsKey(id)) {
System.out.println("입력하신 id는 존재하지 않습니다. 다시 입력해주세요.");
continue;
}
if(!(map.get(id)).equals(password)) {
System.out.println("비밀번호가 일치하지 않습니다. 다시 입력해주세요.");
} else {
System.out.println("id와 비밀번호가 일치합니다.");
break;
}
}
}
}if(!(map.get(id)).equals(password)):map.get(id)키가 id인 값을 반환하고 이 값을 password와 비교해서 같지 않으면 비밀번호가 틀리다는 문구 출력
entry
class Ex11_17 {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
map.put("김자바", 90);
map.put("김자바", 100); // 이 값이 덮어쓴다.
map.put("이자바", 100);
map.put("강자바", 80);
map.put("안자바", 90);
Set<Map.Entry<String, Integer>> set = map.entrySet();
Iterator<Map.Entry<String, Integer>> it = set.iterator();
while (it.hasNext()) {
Map.Entry<String, Integer> e = it.next();
System.out.println("이름 : " + e.getKey() + ", 점수 : " + e.getValue());
}
System.out.println("참가자 명단 : " + map.keySet());
Collection<Integer> values = map.values();
Iterator<Integer> it2 = values.iterator();
int total = 0;
while (it2.hasNext()) {
int i = it2.next();
total += i;
}
System.out.println("총점 : " + total);
System.out.println("평균 : " + (float) total / set.size());
System.out.println("최고점수 : " + Collections.max(values));
System.out.println("최저점수 : " + Collections.min(values));
}
}이름 : 안자바, 점수 : 90
이름 : 김자바, 점수 : 100
이름 : 강자바, 점수 : 80
이름 : 이자바, 점수 : 100
참가자 명단 : [안자바, 김자바, 강자바, 이자바]
총점 : 370
평균 : 92.5
최고점수 : 100
최저점수 : 80
Set<Map.Entry<String, Integer>> set = map.entrySet();: Map 인터페이스의 내부 인터페이스인 Entry 인터페이스
public class Solution {
public HashMap<Character, Integer> countAllCharacter(String str) {
HashMap<Character, Integer> hashMap = new HashMap<>();
for (int i = 0; i < str.length(); i++) {
char character = str.charAt(i);
if (hashMap.containsKey(character))
hashMap.put(character, hashMap.get(character) + 1);
else
hashMap.put(character, 1);
}
return str.length() == 0 ? null : hashMap;
}
}HashMap<Character, Integer> output = countAllCharacter("banana");
System.out.println(output); // --> {b=1, a=3, n=2}
- for 문 : 문자열의 첫 번째 문자부터 hashMap에 키로 포함하고 있으면 값을 +1하고 포함하고 있지 않다면 값에 1 저장 -> 문자열에 같은 문자가 몇번 반복되는지 세는 로직
📌Collections - 컬렉션을 위한 메서드(static) 제공
fill(), copy(), sort(), binarySearch()
: 컬렉션 채우기, 복사, 정렬, 이진 검색
synchronizedXXX()
: 컬렉션의 동기화
static Collection synchronizedCollection( Collection c )
static List synchronizedList( List list )
static Set synchronizedSet( Set s )
static Map synchronizedMap( Map m )
static SortedSet synchronizedSortedSet( SortedSet s )
static SortedMap synchronizedSortedMap( SortedMap m )
/* 사용 방법 */
List synchroList = Collections.synchronizedList( new ArrayList(...) ) ; // ArrayList는 동기화 되지 않은 ListunmodifiableXXX()
: 변경 불가(read Only) 컬렉션 만들기
static Collection unmodifiableCollection( Collection c )
static List unmodifiableList( List list )
static Set unmodifiableSet( Set s )
static Map unmodifiableMap( Map m )
static SortedSet unmodifiableSortedSet( SortedSet s )
static NavigableSet unmodifiableNavigableSet( NavigableSet s )
static SortedMap unmodifiableSortedMap( SortedMap m )
static NavigableMap unmodifiableNavigableMap( NavigableMap m )singletonXXX()
: 싱글톤 컬렉션 만들기. 객체 1개만 저장 가능한 컬렉션
static List singletonList( Object o )
static Set singleton( Object o ) // Set는 그냥 singleton
static Map singletonMap( Object key, Object value )checkedXXX()
: 한 종류의 객체만 저장하는 컬렉션 만들기
static Collection checkedCollection( Collection c, Class type )
static List checkedList( List list, Class type )
static Set checkedSet( Set s, Class type )
static Map checkedMap( Map m, Class keyType, Class valueType ) // 각 각 Type 지정
static Queue checkedQueue( Queue queue, Class type )
static SortedSet checkedSortedSet( SortedSet s, Class type )
static NavigableSet checkedNavigableSet( NavigableSet s, Class type )
static SortedMap checkedSortedMap( SortedMap m, Class keyType, Class valueType )
static NavigableMap checkedNavigableMap( NavigableMap m, Class keyType, Class valueType )
/* 사용 방법 */
List list = new ArrayList() ;
List checkedList = checkedList( list, String.class ) ; //String만 저장 가능하도록
checkedList.add("abc") ; // 가능
checkedList.add(new Integer(123)) ; // 불가능(에러) : ClassCastException 발생- JDK 1.5 버전 이후에는 제네릭스로 대체되었다.
addAll([배열] , ...)
: 지정 Collection 에 '입력된 값들( 가변인자 )'을 추가
List list = new ArrayList();
addAll(list, 1,2,3,4,5);
System.out.println(list);[1, 2, 3, 4, 5]
rotate([배열] , int move)
: 오른쪽으로 move칸씩 이동
rotate(list, 2); // 오른쪽으로 두 칸씩 이동
System.out.println(list);[4, 5, 1, 2, 3]
swap([배열], int idx1, int idx2)
: "idx1 위치의 값"과 "idx2 위치의 값"과 교환
swap(list, 0, 2); // 첫 번째와 세 번째를 교환(swap)
System.out.println(list);[1, 5, 4, 2, 3]
shuffle([배열])
: 무작위 섞기
shuffle(list); // 저장된 요소의 위치를 임의로 변경
System.out.println(list);[3, 4, 2, 1, 5]
sort([배열], reverseOrder())
: 역순 정렬. reverse([배열])과 동일
sort(list, reverseOrder()); // 역순 정렬 reverse(list);와 동일
System.out.println(list);[5, 4, 3, 2, 1]
nCopies([배열].size(), Object value)
: 지정 배열과 같은 크기의 새로운 리스트를 생성하고 value로 해당 리스트 채움
List newList = nCopies(list.size(), 2);
System.out.println("newList="+newList);newList=[2, 2, 2, 2, 2]
disjoint([배열 1], [배열 2])
: 두 배열에 공통 요소가 없으면 true 반환
