
jpabegin 영속성 연결!
persist() db에 저장!
find() db에서 조회!
close() 마지막에 닫아줘야함(entityManager->EntityManagerFactory)
간단한 설정으로 클래스와 테이블간 매핑 처리!!
EntityManager(persist(),find()...)를 이용해서 DB 연동처리!!
객체 변경만으로 DB 테이블 업데이트!
쿼리 작성할 필요 없음ㅎ
02. JPA 코드 구조 & 영속 컨텍스트
-
영속 단위로 초기화
: EntityManagerFactory는 영속 단위 기준으로 초기화된다.
: persistence.xml 파일에 정의한 영속 단위 기준으로 초기화된다. -
EntityManagerFactory
: DB 연결에 필요한 자원들을 생성!
: 어플리케이션 구동될 때 한번만 실행
: 종료할 때 close로 닫기
EntityManager로 DB 연동
: EntityManagerFactory로 EntityManager 생성
: transaction이 필요하면, EntityTransaction으로 생성 가능
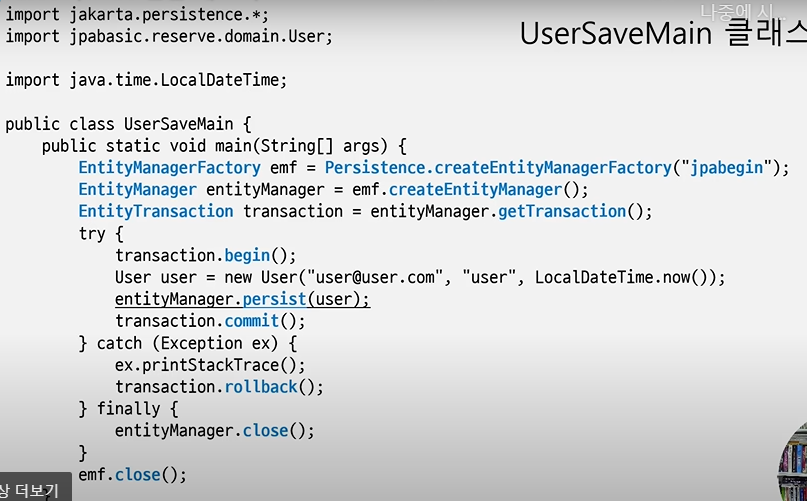
// EntityManager 생성
EntityManager entityManager = emf.createEntityManager();
// EntityTransaction
EntityTransaction transaction = entityManager.getTransaction();
try{
// 트랜잭션 시작
transaction.begin();
....
// 트랜잭션 커밋
transaction.commit();
} catch(Exception ex){
// 트랜잭션 롤백
transaction.rollback();
} finally{
// entityManager 닫기
entityManager.close();
}저장과 쿼리 실행 시점
transaction.begin();
User user = new User("user@user.com","user",LocalDateTime.now());
entityManager.persist(user);
logger.info("EntityManager.persist 호출함");
transaction.commit();
logger.info("EntityTransaction.commit 호출함");
persist()에 바로 저장되는 것이 아니다!
commit 시점에 이루어 짐!

수정과 쿼리 실행 시점
수정도 저장과 마찬가지고 commit 시점에 이루어진다
이는 바로 영속 컨텍스트 속성때문!!!!
영속 컨텍스트
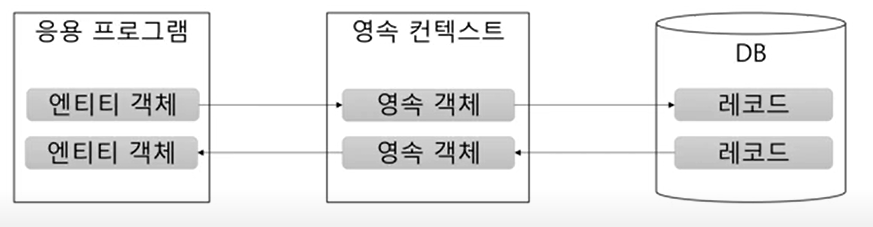
: 일종의 메모리 저장 공간(Entity를 보관)
: DB 에서 읽어온 객체나 DB에 저장할 데이터를 저장하는 공간
: EntityManager 단위로 영속 컨텍스트 관리
: 해당 영속 객체에 변경이 발생하면, 변경을 감지해서 커밋 시점에 영속 컨텍스트의 변경 내역을 DB에 반영(변경 쿼리 실행)
: 다시 말해, persist()등은 영속 컨텍스트에 해당 변경 내용을 저장시키는 것!
=> 위의 사항은 spring 에서 자동으로 해 줌!
=> 매핑 설정 중심으로 작업하면 됨
03. 엔티티 단위 CRUD 처리
EntityManager가 제공하는 메서드
1) persist(Object entity)
: 저장 시 사용
2) find(Class entityCalss, Object primaryKey)
: 조회 시 사용
: 없는 경우 null 출력
: 파라미터의 entity 타이브 ID 타입이 맞아야 함!
3) remove(Object entity)
: 삭제 시 사용
: find()로 조회해온 정보를 파라미터로 전달해야 삭제됨! 아니면 오류 발생
4) merge()
5) 수정
: 트랜잭션 범위 내에서 변경된 값을 자동으로 반영
public class ChangeNameService{
public void changeName(String email, String newName){
EntityManager em = EMF.createEntityManager();
EntityTransaction tx = em.getTransaction();
try{
tx.begin();
User user = em.find(User.class, email);
if(user == null){
throw new NoUserException();
}
user.changeName(newName);
tx.commit();
} catch(Exception ex){
tx.rollback();
throw ex;
} finally{
em.close();
}
}
}04. 엔티티 매핑
매우 간단하다~
기본 annotation
- @Entity : entity 클래스에 설정, 필수
- @Table : 매핑할 테이블 지정
- @Id : 식별자 속성에 설정, 필수
- @Column : 매핑할 칼럼명 지정
(지정하지 않으면 필드명/프로퍼티명 사용) - @Enumerated : enum 타입 매핑할 때 설정
- @Temporal: java.util.Date, java.util.Calendar 매핑
(자바8 시간/날짜 타입 등장 이후로 거의 안 씀) - @Basic : 기본 지원 타입 매핑이기에 거의 안 씀
@Table annotation
: 생략하면, 클래스 이름과 동일한 이름에 매핑
- 속성
- name : 테이블 이름
- catalog : 카탈로그 이름 (ex, MySQL DB 이름)
- schema : 스키마 이름 (ex, 오라클 스키마 이름)
- 예시
- @Table
- @Table(name="hotel_info")
- @Table(catalog = "point", name = "point_history")
- @Table(schema = "crm" , name = "cust_stat")
@Enumerated annotation
설정 값
- EnumType.STRING
: enum 타입 값 이름을 저장
: 문자열 타입 칼럼에 매핑 - EnumType.ORDINAL (기본값)
: enum 타입의 값의 순서를 저장
: 숫자 타입 칼럼에 매핑

// 매핑 대상 엔티디
@Entity
// hotel_info 테이블에 매핑
@Table(name="hotel_info")
public class Hotel{
// 식별자로 매핑
@Id
// hoitel_id 칼럼에 매핑
@Column(name="hotel_id")
private String id;
// nm 칼럼에 매핑
@Column(name="nm")
private String name;
// year 칼럼에 자동으로 매핑
@private int year;
// 열거 타입 이름을 값으로 저장
@Enumerated(EnumType.STRING)
// grade 칼럼에 매핑
private Grade grade;
// created 칼럼에 매핑
private LocalDateTime created;
// modified 칼럼에 매핑
@Column(name="modified")
private LocalDataTime lastModified;
... 생략
}Entity 클래스 제약 조건(스펙 기준)
-
@Entity 적용해야 함
-
@Id 적용해야 함
-
인자 없는 기본 생성자 필요
protected Hotel(){ } -
기본 생성자는 public이나 protected여야 함
-
최상위 클래스여야 함
-
final이면 안 됨
접근 타입
1) 필드 접근 : 필드 값을 사용해서 매핑
2) 프로퍼티 접근 : getter/setter 매서드를 사용해서 매핑
- 설정 방법
: @Id annotation을 필드에 붙이면 필드 접근
: @Id annotation을 getter 메서드에 붙이면 프로퍼티 접근
: @Access annotation을 사용해서 명시적으로 지정
- 클래스 / 개별 필드에 적용 가능
- @Access(AccessType.PROPERTY) / @Access(AccessType.FIELD)
cf) 필드 접근법을 사용하게 되면, 불필요한 setter 매서드를 만들 필요 없음!
05. 엔티티 식별자 생성
1) 직접 할당 생성 방식
: @Id 설정 대상에 직접 값 설정
ex, 이메일과 주문번호와 같이 사용자가 입력한 값, 규칙에 따라 생성한 값 등
: 저장하기 전에 생성자 할당, 보통 생성 시점에 전달
2) 식별 칼럼 방식
: DB의 식별 칼럼에 매핑(ex, MySql autoincrement와 같은 자동 증가 칼럼) - DB가 식별자를 생성하므로 객체 생성시에 식별값을 설정하지 않음
: 설정 방식
@GeneratedValue(strategy=GenerationType.IDENTITY)설정
: INSERT 쿼리를 실행해야 식별자를 알 수 있음
- EntityManager#persist() 호출 시점에 INSERT 쿼리 실행
- persist() 실행할 때, 객체에 식별자 값 할당함
- 저장 시점에 INSERT 쿼리 실행
@Entity
public class Review{
@Id
@Column(name="review_id")
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Long id;
@Column(name="hotel_id")
private String hotelId;
...
public Review(int mark, String hotelId, String writerName, String comment){
this.mark = mark;
...
}
public Long getId(){
return id;
}
}// 생성 시점에 식별자 지정하지 않음
Review review = new Review(5,"H-01",...);
// 저장 시점에 INSERT 쿼리 바로 실행
entityManager.persist(review);
// persist() 이후 "식별자 사용 가능"
Long genId = review.getId();3) 시퀀스 사용 방식
: 시퀀스를 사용해서 식별자 생성
-JPA가 식별자 생성 처리 -> 객체 생성시에 식별값을 설정하지 않음
: 설정 방식
@SequenceGenerator로 시퀀스 생성기 설정@GeneratedValue의 generator로 시퀀스 생성기 지정
: EntityManager#persist() 호출 시점에 시퀀스 사용
persist()실행할 때 객체에 식별자 값 할당됨- INSERT 쿼리는 실행하지 않음
: 저장 시점에 시퀀스 사용해서 식별자 생성
@Entity
@Table(schema = "crm", name = "activity_log")
public class ActivityLog{
@Id
@SequenceGenerator(
name = "log_seq_gen",
sequenceName = "activity_seq",
schema = "crm",
// 1로 주어야 함!!
allocationSize = 1
)
// 위 @SequenceGenerator의 name과 일치
@GeneratedValue(generator = "log_seq_gen")
private Long id;
@Column(name = "user_id")
private String userId;
,,,
public ActivityLog(String userId, String activityType){
this.userId = userId;
this.activityType = activityType;
this.create = LocalDateTime.now();
}
} // 생성 시점에 식별자 지정하지 않음
ActivityLog log = new ActivityLog("U01", "VISIT");
// persist() 시점에 시퀀스로 식별자 구함
em.persist(log);
// 커밋 시점에 INSERT 쿼리 실행
tx.commit();4) 테이블 사용 방식
: 테이블을 시퀀스처럼 사용
- 테이블에 엔티티를 위한 키를 보관
- 해당 테이블을 이용해서 다음 식별자 생성
: 설정 방식
@TableGenerator로 테이블 생성기 설정@GeneratedValue의 generator로 테이블 생성기 지정
: EntityManager#persist() 호출 시점에 테이블 사용
persist()할 때 테이블을 이용해서 식별자 구하고, 이를 엔티티에 할당- INSERT 쿼리는 실행하지 않음
: 식별자를 생성할 때 / 사용할 때 테이블 구조
- 엔티티 이름 칼럼 & 식별자 보관 컬럼
: 저장 시점에 테이블 사용해서 식별자 생성
create table id_seq(
entity varchar(100) not null primary key,
nextval bigint
) engine innodb charactre set utf8mb4; @Entity
@Table(name = "access_log")
public class AccessLog{
@Id
@TableGenerator(
name = "accessIdGen",
table = "id_seq",
pkColumnName = "entity",
pkColumnValue = "accesslog",
valueColumnName = "nextval",
initialValue = 0,
allocationSize = 1
)
@GeneratedValue(generator = "accessIdGen")
private Long id;
}06. Embeddable
- 엔티티가 아닌 타입을 한 개 이상의 필드와 매핑할 때 사용
- 엔티티의 한 속성으로 @Embeddable 적용 타입 사용
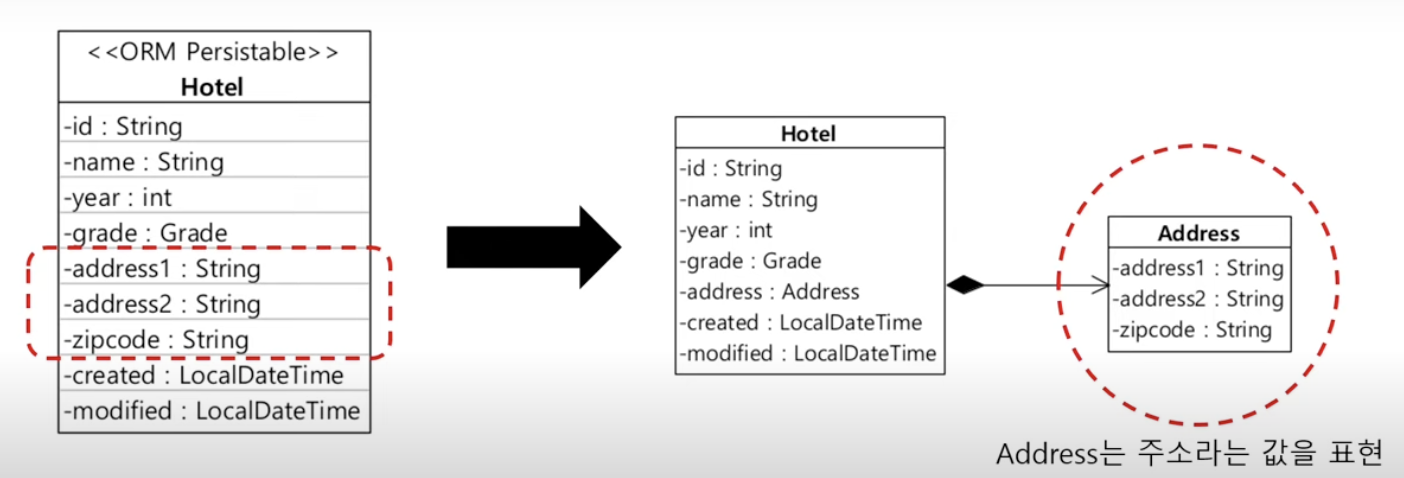
@Embeddable
public class Address{
@Column(name="addr1")
private String address1;
@Column(name="addr2")
private String address2;
@Column(name="zipcode")
private String zipcode;
protected Address(){
}
...
}@Entity
@Table(name="hotel_info")
public class Hotel{
@Id
@Column(name="hotel_id")
private String id;
...
@Embedded
private Address Address;
}같은 @Embeddable 타입 필드가 두 개면?
: 에러가 발생
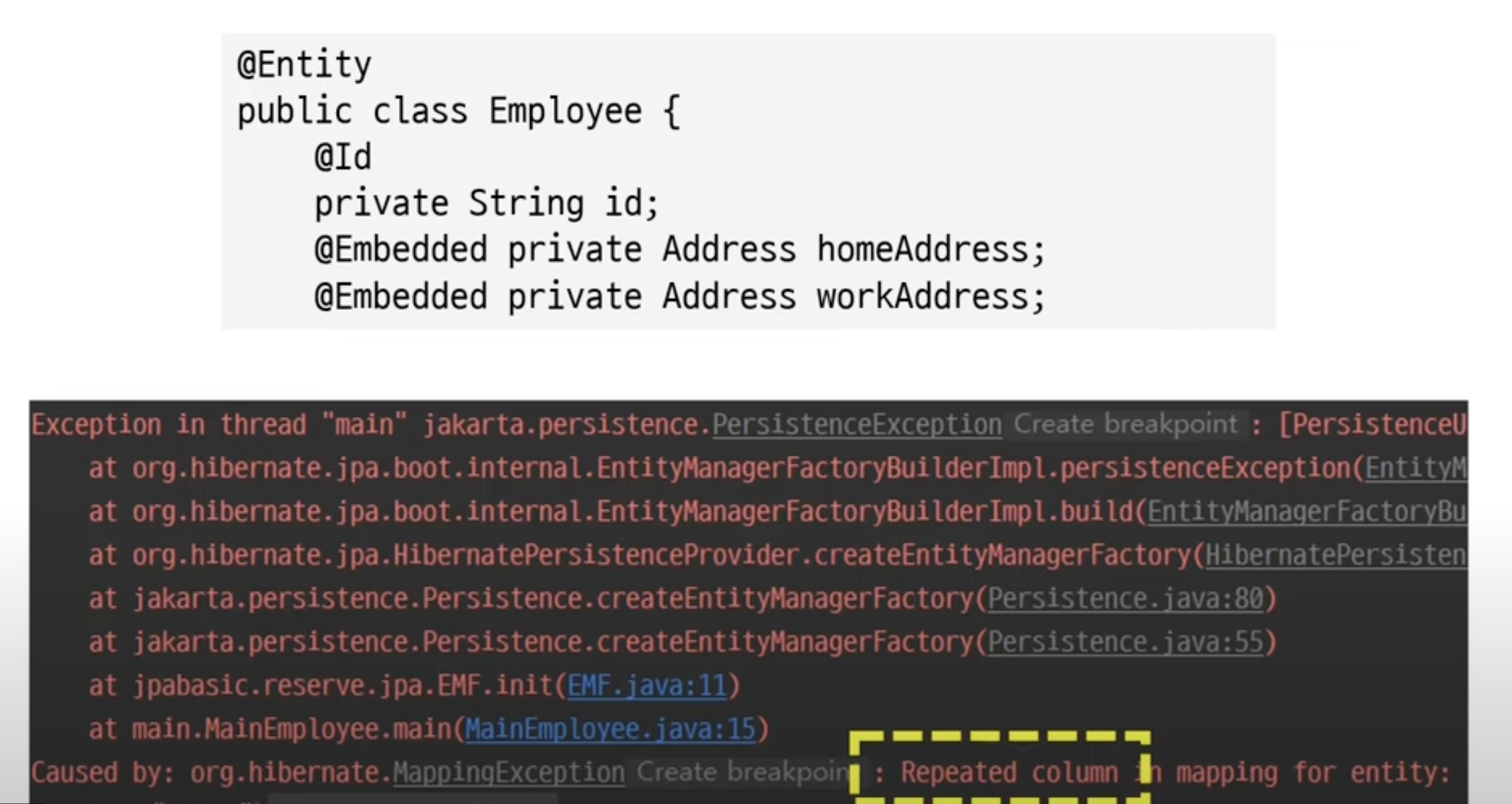
=> @AttributeOverride으로 설정 재정의하면 됨!
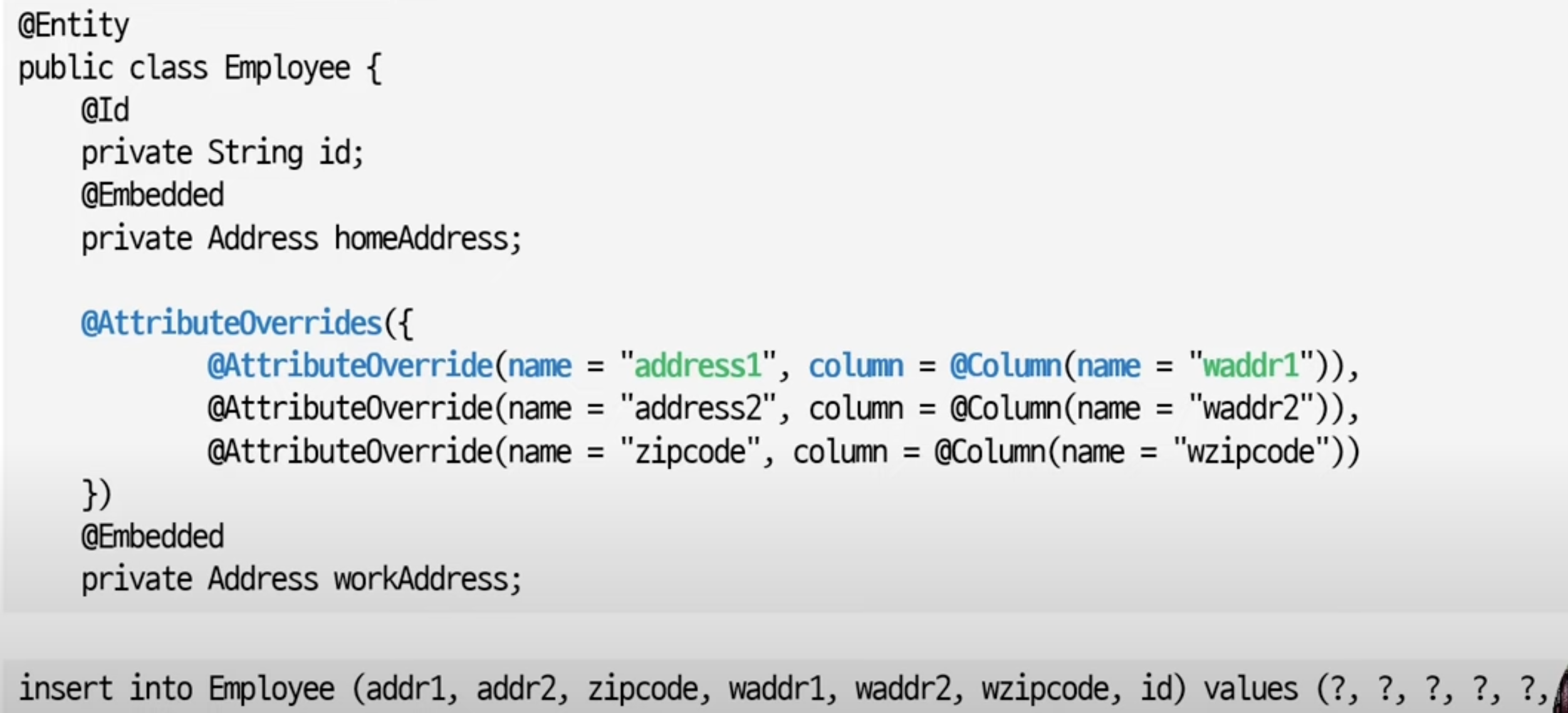
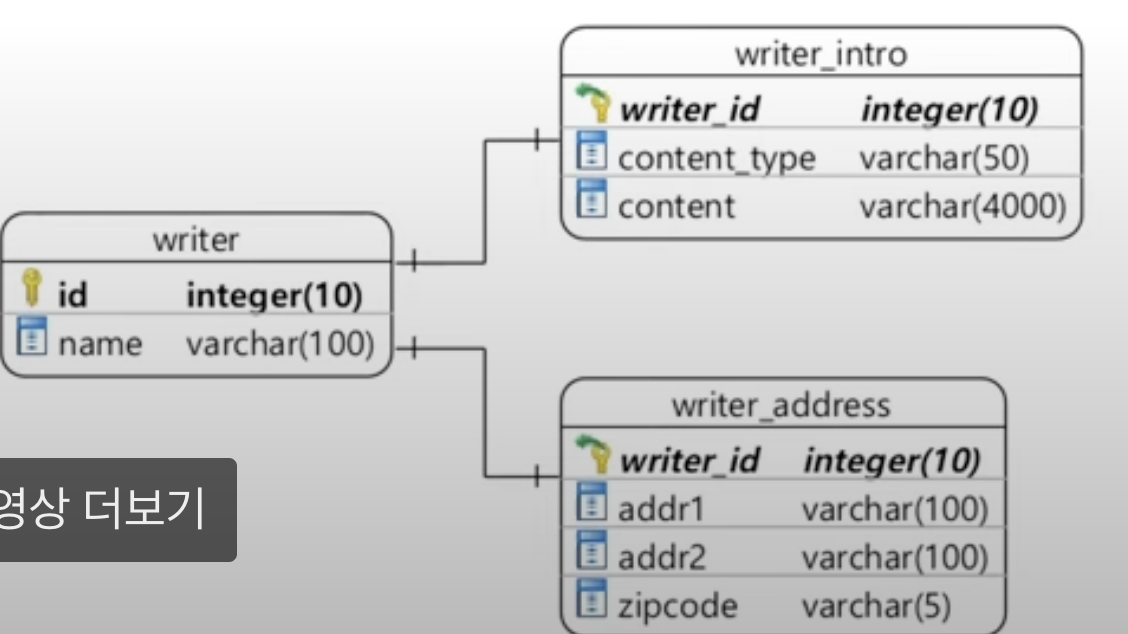
다른 테이블에 값을 저장해야 할 때
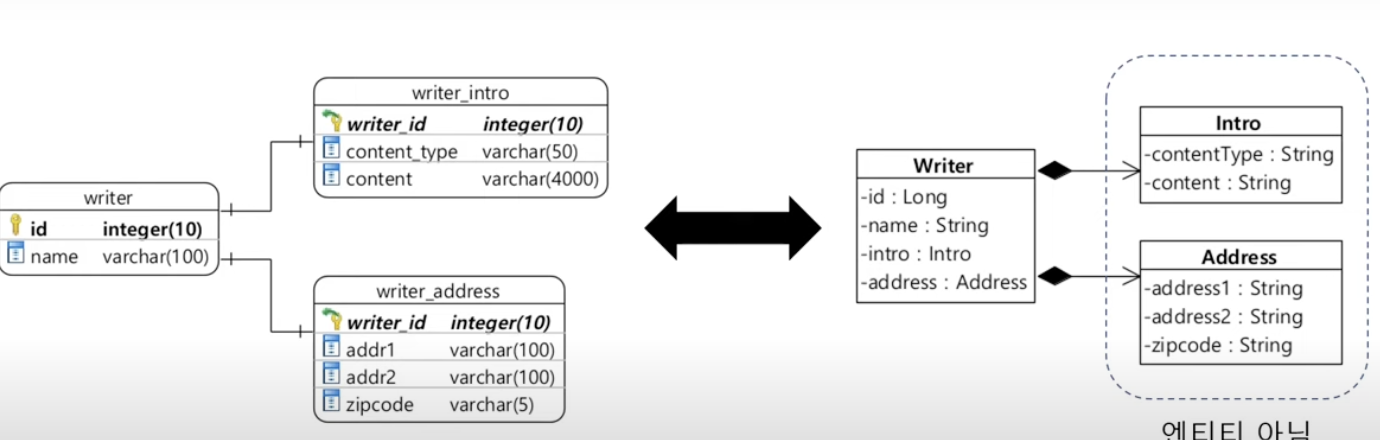
- 방법
1) @SecondaryTable + 테이블명
@Embeddable
public class Intro{
@Column(table="writer_intro", name="content_type")
private String contentType;
@Column(table="writer_intro")
private String content;
...
}@Entity
@SecondaryTable(
name="writer_intro",
// writer_intro 테이블에서 지금 현재 테이블(writer)을 참조할 때 사용할 컬럼이 이거야!
pkJoinColumns = @PrimaryKeyJoinColumn(
name = "writer_id", // writer_intro 테이블 칼럼
referencedColumnName = "id" // writer 테이블 칼럼
)
)
public class Writer{
...
@Embedded
private Intro intro;
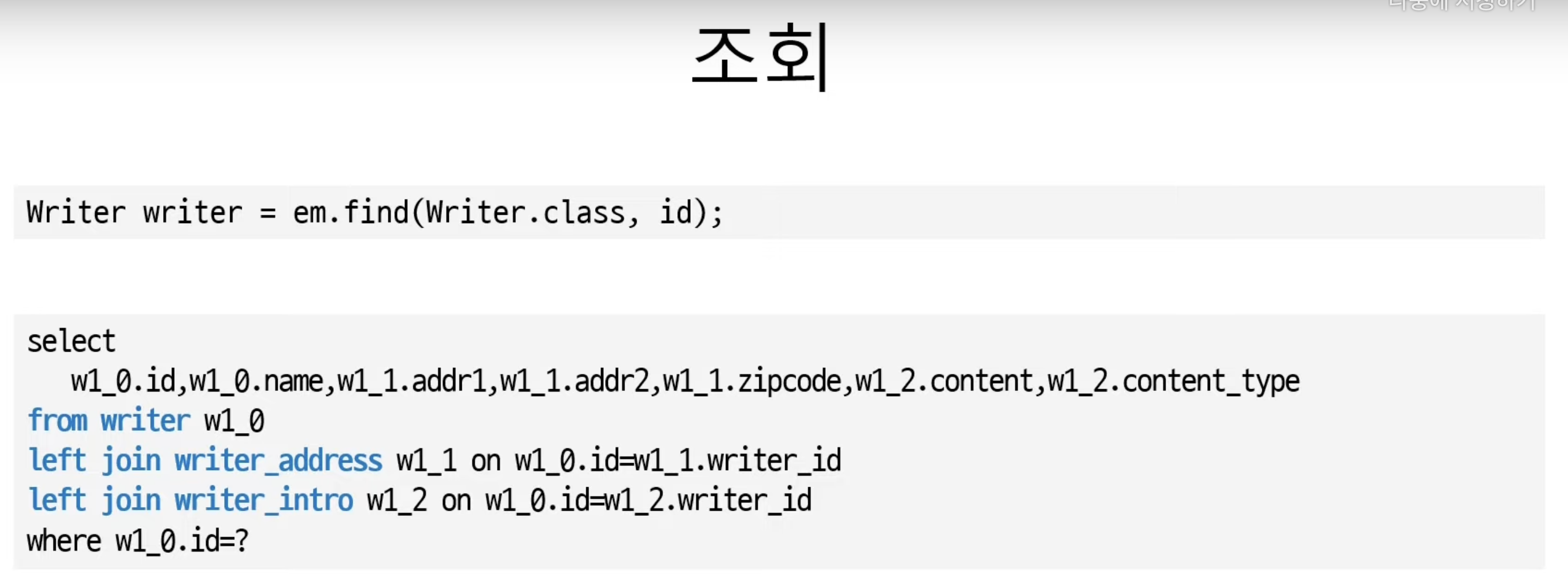
} 
2) SecondaryTable+@AttributeOverrride
@Embeddable
public class Address{
@Column(name="addr1")
private String address1;
@Column(name="addr2")
private String address2;
@Column(name="addr3")
private String address3;
}@Entity
@SecondaryTables({
@SecondaryTable(name="writer_address",pkJoinColumns = @PrimaryKeyJoinColumn(name="writer_id",referencedColumnName="id"))
})
public class writer{
...
@Embedded
@AttributeOverrides({
@AttributeOverride(name="address1",column=@Column(table="writer_address",name="addr1")),
@AttributeOverride(name="address2",column=@Column(table="writer_address",name="addr2")),
@AttributeOverride(name="address3",column=@Column(table="writer_address",name="addr3")),
})
} 


@SecondaryTable
: 다른 테이블에 저장된 데이터를 @Embeddable로 매핑 가능
: 다른 테이블에 저장된 데이터가 개념적으로 entity가 아니라 value(값)일 때 사용!
=> 1:1 관계인 두 테이블을 매핑할 때 종종 사용
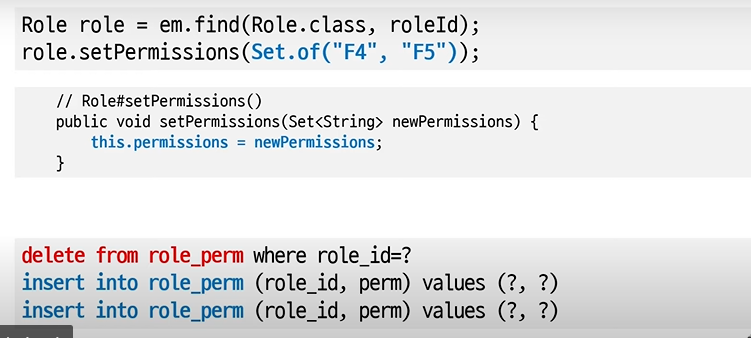
08. 값 콜렉션 Set
: 단순 값을 Set으로 보관하는 모델
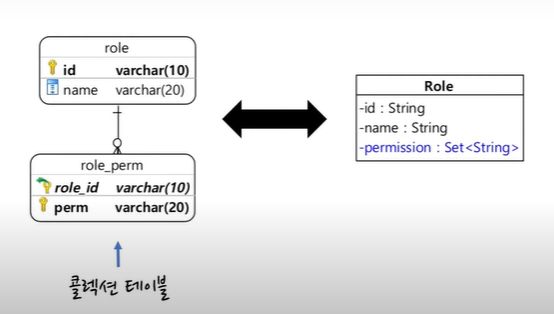
콜렉션 테이블
집합 형태의 데이터를 가지고 있는 테이블
@Entity
@Table(name="role")
public class Role{
@Id
private String id;
private String name;
@ElementCollection
// 콜렉션 테이블의 이름과 조인된 컬럼
@CollectionTable(
name = "role_perm",
joinColumns = @JoinColumn(name = "role_id")
// 콜렉션 테이블에서 사용할 값 column 이름
@Column(name = "perm")
private Set<String> permissions = new HashSet<>();
)
}Set 저장
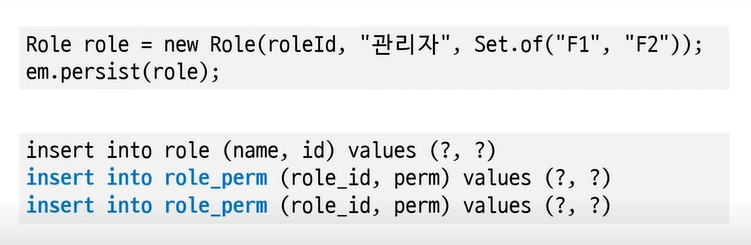
Set 조회 (lazy방식 = 기본 값)
lazy방식
: (collection 테이블) 연관된 테이블을 나중에 가져온다
: 해당 데이터가 필요한 시점에 읽어온다
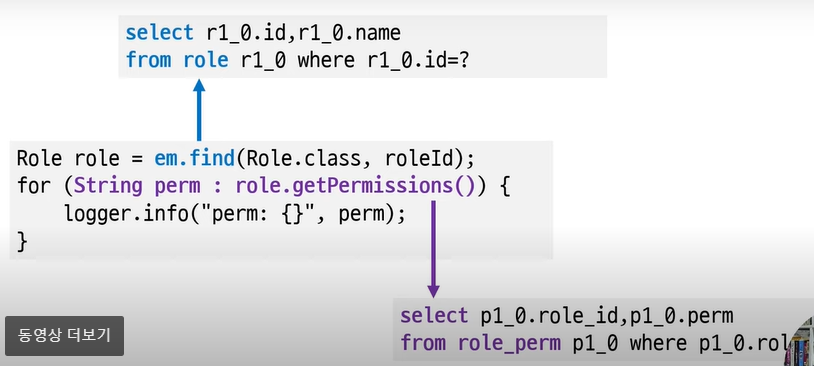
Set 조회 (eager방식)
: 즉시 해당 데이터를 가져온다.
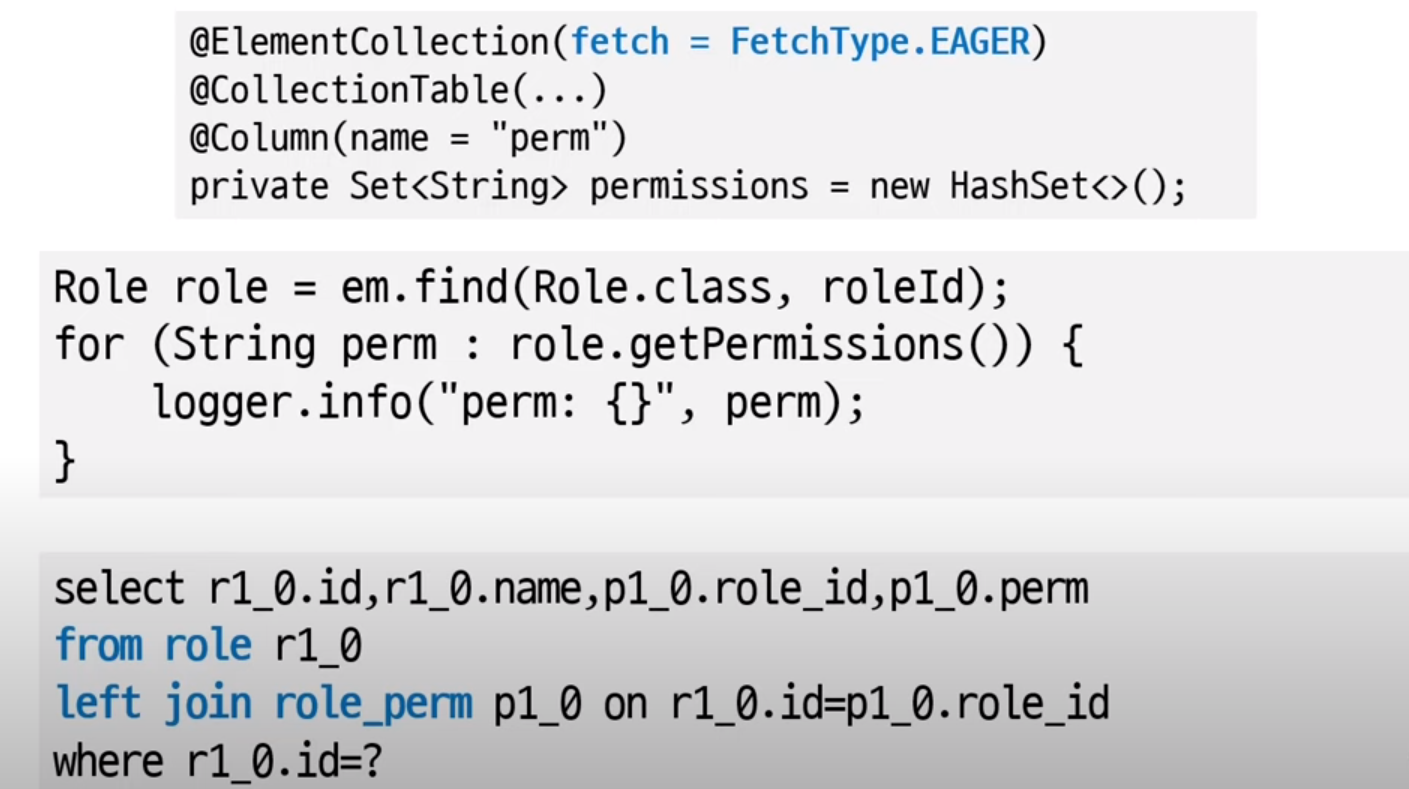
Set 수정: add(), remove()

: 삭제 먼저 한 후에, 값 추가
Set 새로 할당
: 삭제 후 값 추가
Set clear()

: 데이터를 select(조회)한 후, 삭제
Embeddable 타입 Set
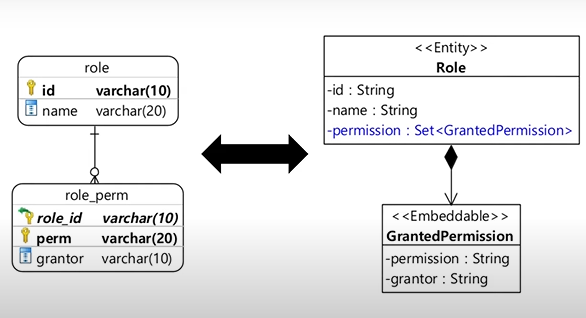
매핑 설정
@Entity
@Table(name="role")
public class Role2 {
@Id
private String id;
private String name;
@ElementCollection
@CollectionTable(
name = "role_perm",
joinColumns = @JoinColumn(name = "role_id")
)
private Set<GrantedPermission> permissions = new HashSet<>();
} @Embeddable
public class GrantedPermission {
@Column(name="perm")
private String permission;
private String grantor;
}콜렉션 테이블을 이용한 값 Set 매핑
:@ElementCollection과@CollectionTable이면 끝!!
09. 값 콜렉션 List
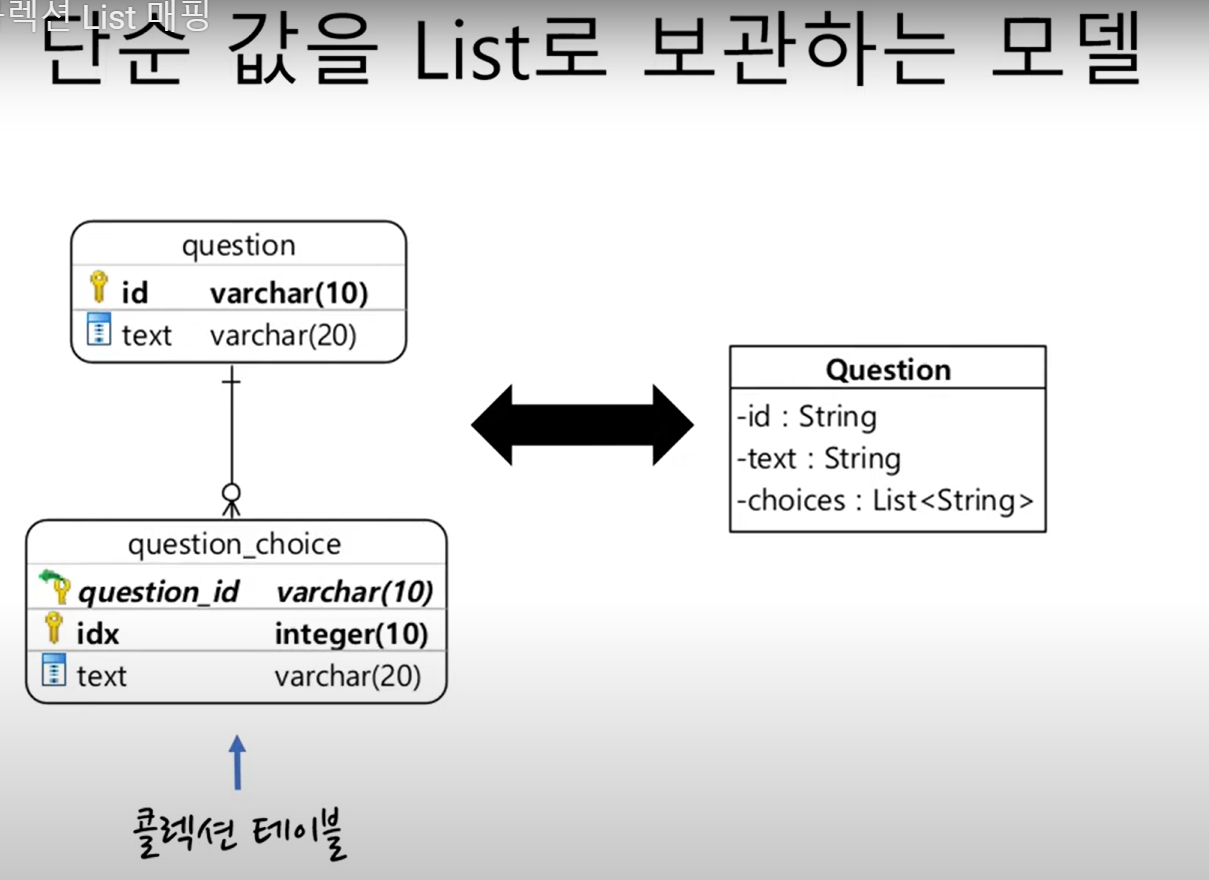
@Entity
@Table(name="question")
public class Question{
@Id
private String id;
private String text;
@ElementCollction
@CollectionTable(
name = "question_choic",
joinColumns = @JoinColumn(name = "question_id")
)
@OrderColumn(name = "idx")
@Column(name = "text")
private List<String> choices;
}set과의 차이는 단 하나!
@OrderColumn을 사용한다는 것
리스트의 인덱스값을 저장할 컬럼을 지정해준다.
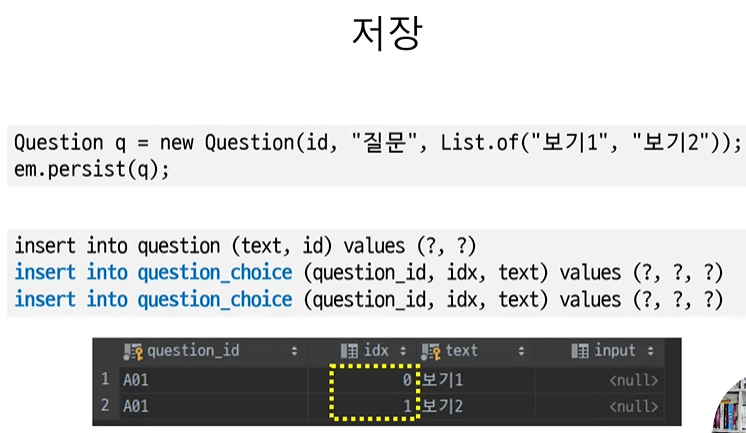



: 콜렉션 테이블의 데이터도 삭제가 됨!
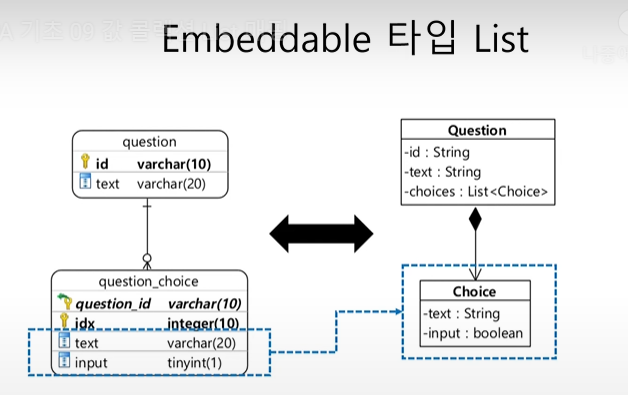
매핑 설정
@Entity
@Table(name="question")
public class Question2{
@Id
private String id;
priavet String text;
@ElementCollection
@CollectionTable(
name="question_choice",
joinColumns = @JoinColumn(name="question_id")
)
@OrderColumn(name="idx")
private List<Choice> choices;
}@Embeddable
public class Choice{
private String text;
private boolean input;
}콜렉션 테이블을 이용한 값 List 매핑
:@ElementCollection,@CollectionTable,@OrderColumn이면 끝!
--
10. 값 콜렉션 Map
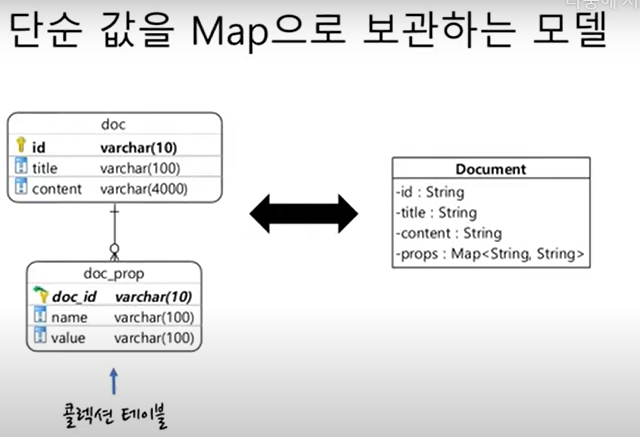
@Entity
@Table(name="doc")
public class Document{
@Id
private String id;
private String title;
private String content;
@ElementCollection
@CollectionTable(
name="doc_prop",
joinColumns=@JoinColumn(name="doc_id")
)
@MapKeyColumn(name="name")
@Column(name="value")
private Map<String, String> props = new HashMap<>();
}@MapKeyColumn을 이용하여 key에 매핑할 컬럼명을 설정해준다.
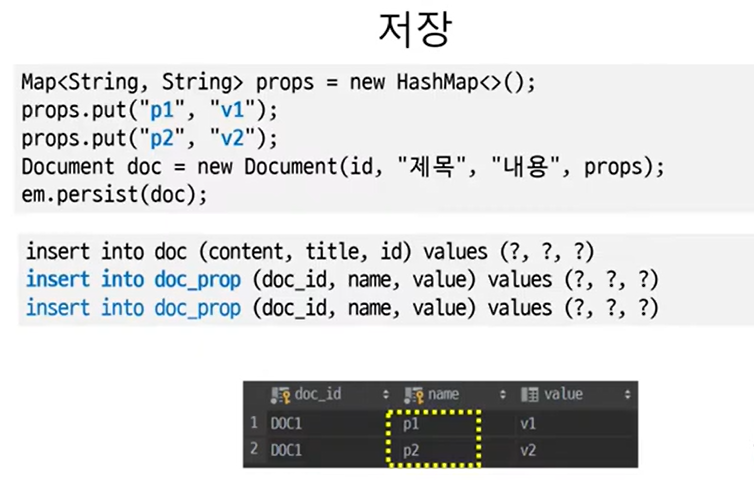
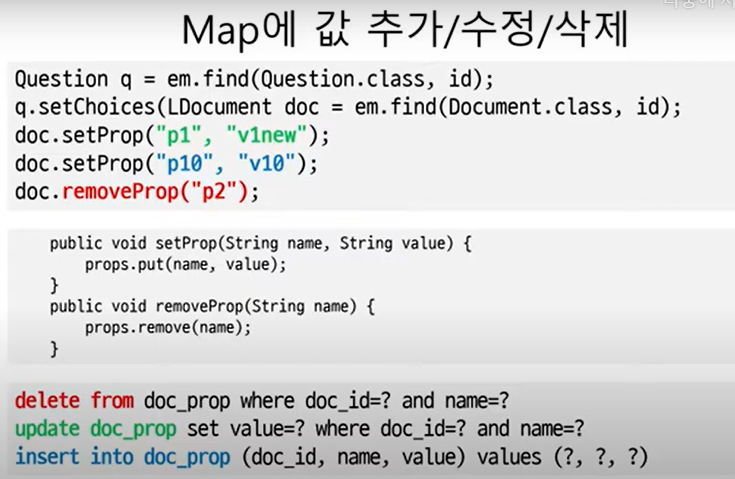
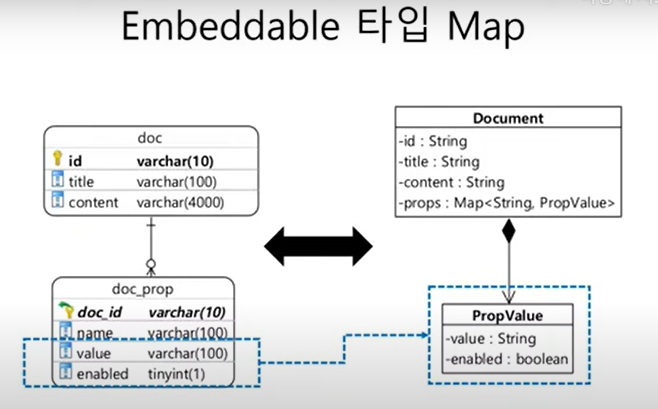
매핑 설정
@Entity
@Table(name="doc")
public class Document{
@Id
private String id;
private String title;
private String content;
@ElementCollection
@CollectionTable(
name="doc_prop",
joinColumns=@JoinColumn(name="doc_id")
)
@MapKeyColumn(name="name")
private Map<String, PropValue> props = new HashMap<>();
}
콜렉션 테이블을 이용한 값 Map 매핑
:@ElementCollection,@CollectionTable,@MapKeyColumne이면 끝
11. 값 콜렉션 주의 사항


성능문제를 고민해야 함!

CQRS
: 변경 기능을 위한 모델과 조회 기능을 위한 모델을 분리
- 변경 기능 : JPA 활용
- 조회 기능 : MyBatis/JdbcTemplate/JPA 중 알맞은 기술 사용
: 모든 기능을 JPA로 구현할 필요 없음
- 특히 목록, 상세와 같은 조회 기능
- JPA로 다 할 수는 있겠지만, 고통만 커질 수 있다. 특히 콜렉션/연관을 다룰 때!
- JPA로 다 하겠다는 생각 버리기
: 명령 모델(상태 변경)과 조회 모델을 구분하면 좋음
12. 영속 컨텍스트 & 라이프 사이클
영속 객체와 영속 컨텍스트
- 영속(persistent) 엔티티 / 객체
: DB 데이터에 매핑되는 메모리상의 객체
: 영속 컨텍스트에 보관된 객체여야만 함 - 영속 컨텍스트
: 일종의 메모리 저장소
: EntityManager가 관리(=변경을 추적)할 엔티티 객체 보관
: (엔티티 타입, 식별자) => 엔티티 객체 형태로 저장 - EntityManager.close()
: 영속 컨텍스트 제거 - 배치 처리 X
영속 컨텍스트와 캐시

: 한번 조회한 경우 영속컨텍스트 내에 저장이 되어있기 때문에, 동일한 식별자를 통해서 조회를 한다면 쿼리가 중복으로 실행되는 것이 아니라 영속 컨텍스트 내에 저장되어 있는 값을 조회하는 것이다!
영속 객체 라이프사이클
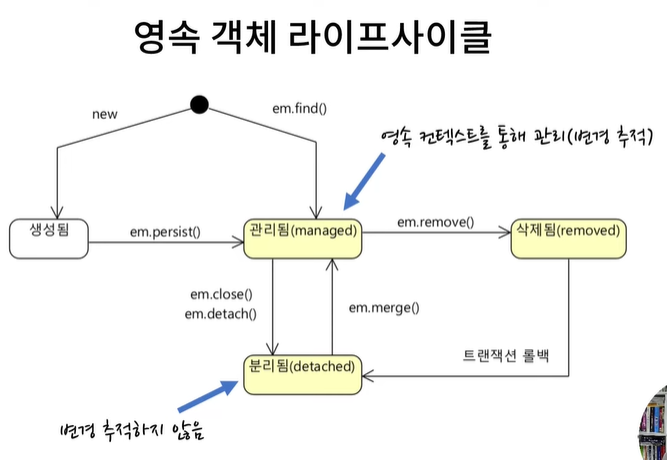
영속 컨텍스트와 변경 추적

분리된 상태는 변경 추적 대상이 아님!!

: changeName()은 실행되지 않는다!
: merge()를 통해 다시 관리된 상태로 변경시킬수도 있다
- JPA는 영속 엔티티(객체)를 영속 컨텍스트에 담아 변경 추적
: 트랜잭션 커밋 시점에 변경 반영- 대량 변경은 굳이 JPA로 할 필요 없음
: 직접 쿼리 실행하는 게 나음- 분리됨 상태는 변경을 추적하지 않는다
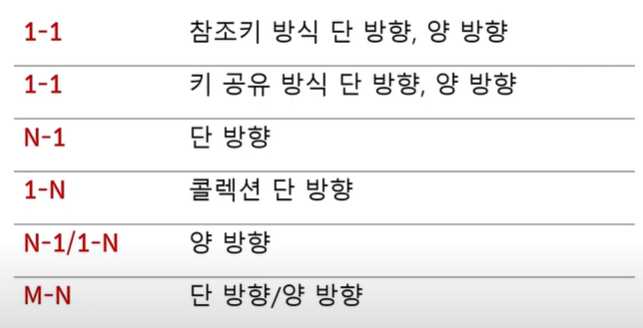
13. 엔티티 연관
연관
: 엔티티와 엔티티 간 연결
: 엔티티가 다른 엔티티를 필드/프로퍼티로 참조
: 거의 사용하지 않음! (특히 양방향, N:M은 없음)
why? value(embeddable 타입)로 매핑 / 조회는 쿼리 직접 사용할 때 많음
연관의 종류
14. 1:1 단방향 연관
주의!
- 연관 매핑은 진짜 필요할 때만 사용할 것
: 연관된 객체 탐색이 쉽다는 이유로 사용하지 말 것
: 조회 기능은 별도 모델을 만들어 구현(CQRS)- Embeddable 매핑이 가능하다면 Embeddable 매핑 사용할 것
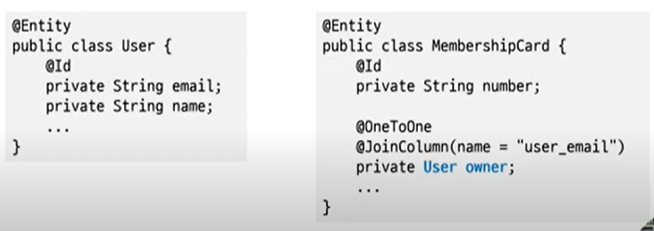
참조키를 이용한 1:1 연관 매핑
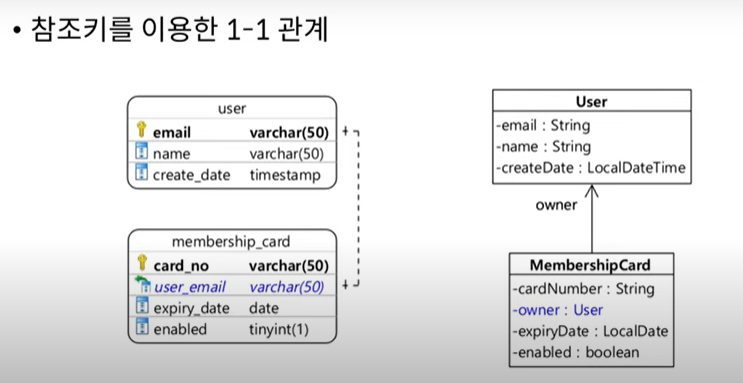
: @OneToOne, @JoinColumn 사용
@Entity
public class MemberShipCard {
@Id
private String number;
@OneToOne
@JoinColumn(name="user_email")
private User owner;
...
}저장

조회

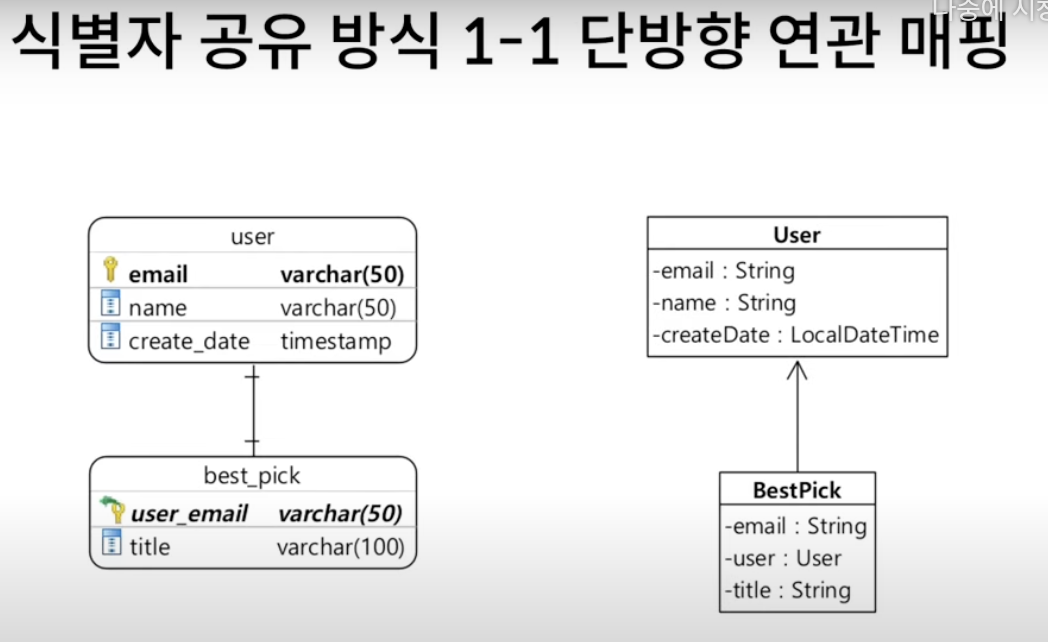
@Entity
@Table(name="best_pick")
public class BestPick{
@Id @Column("user_email")
private String email;
@OneToOne
@PrimaryKeyJoinColumn(name="user_email")
private User user;
private String Title;
protected BestPick(){}
public BestPick(User user, String title){
this.email = user.getEmail();
this.user = user;
this.title = title;
}
} 
15. N:1 단방향 연관
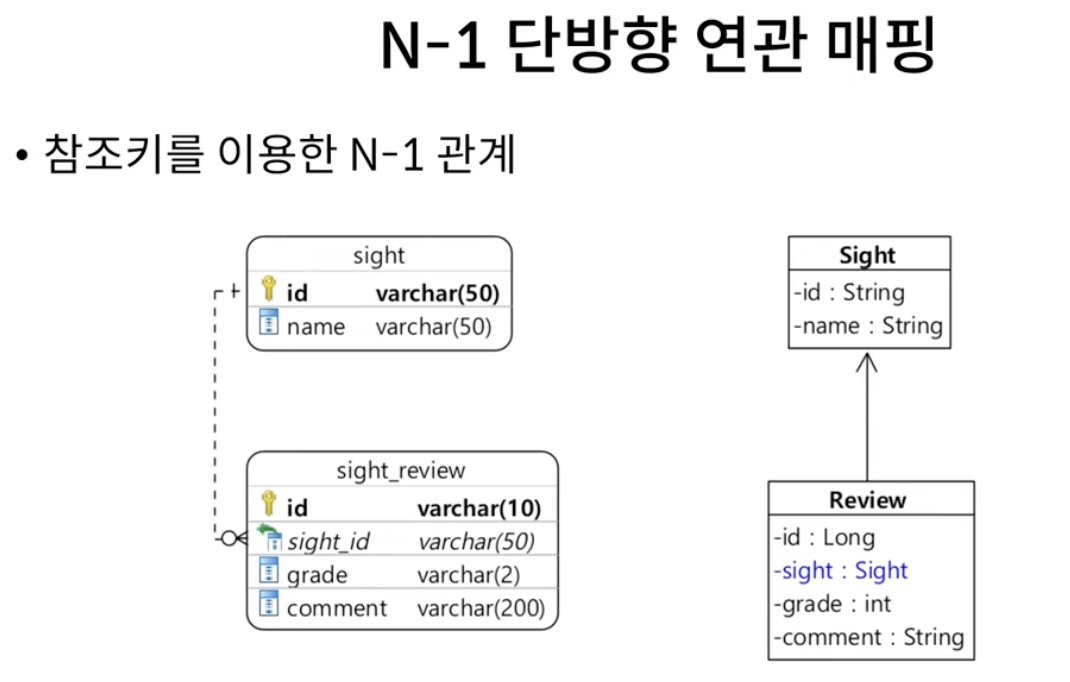
@Entity
@Table(name = "sight_review")
public class Review{
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Long id;
@ManyToOne
@JoinColumn(name="sight_id")
private Sight sight;
private int grade;
private String comment;
proteced Review(){
}
public Review(Sight sight, int grade, String comment){
this.sight = sight;
this.grade = grade;
this.comment = commnet;
}
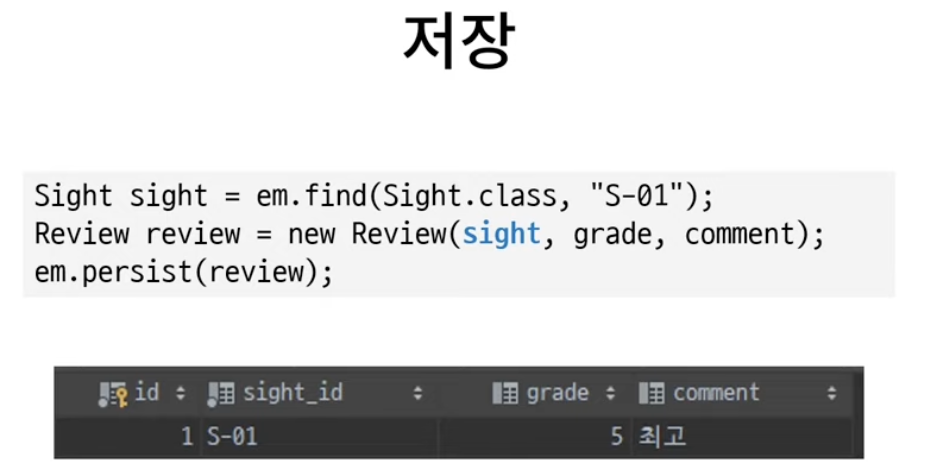
}


16. 1:N 단방향 연관
콜렉션을 사용한 매핑
1. Set
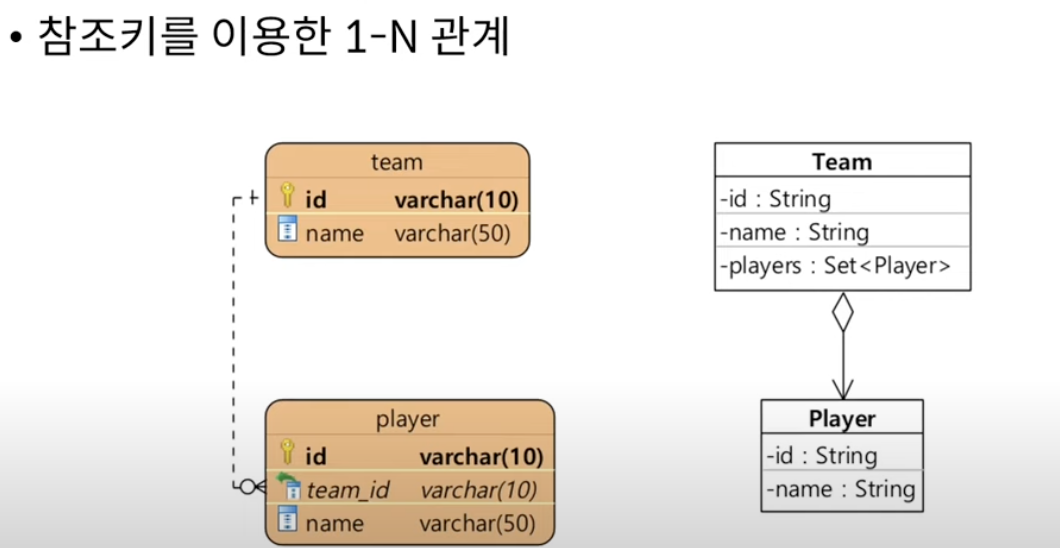
@Entity
@Table(name="team")
public class Team{
@Id
private String id;
private String name;
@OneToMany
@JoinColumn(name="team_id")
private Set<Player> players = new HashSet<>();
...
}@Entity
@Table(name="player")
public class Player{
@Id
private String id;
private String name;
} 

2. List
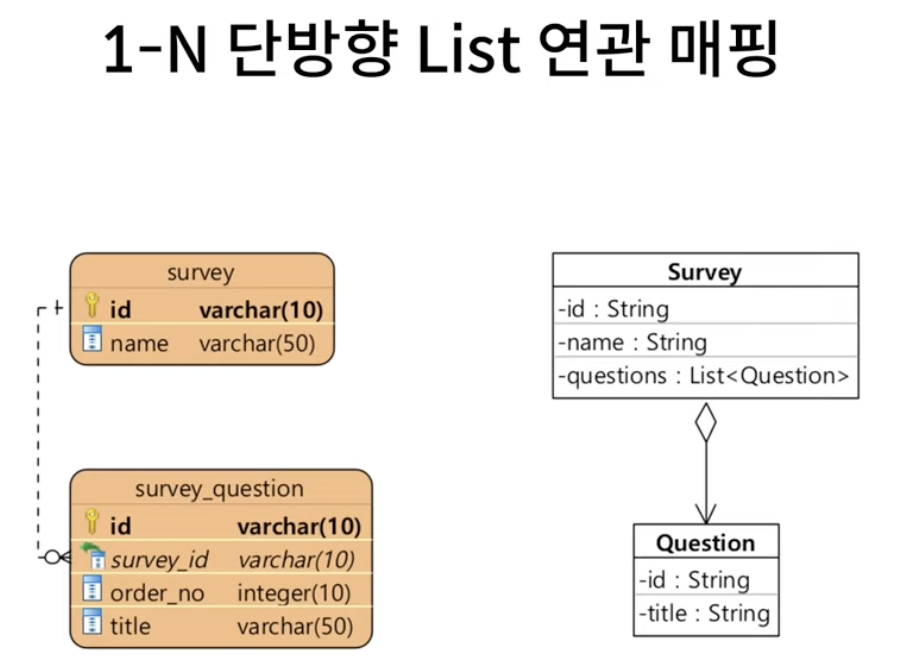
@Entity
@Table(name = "survey")
public class Survey
@Id
private String id;
private String name;
@OneToMany
@JoinColumn(name="survey_id")
@OrderColumn(name="order_no")
private List<Question> question = new ArrayList<>();@Entity
@Table(name="survey_question")
public class Question{
@Id
private String id;
private String title;
}
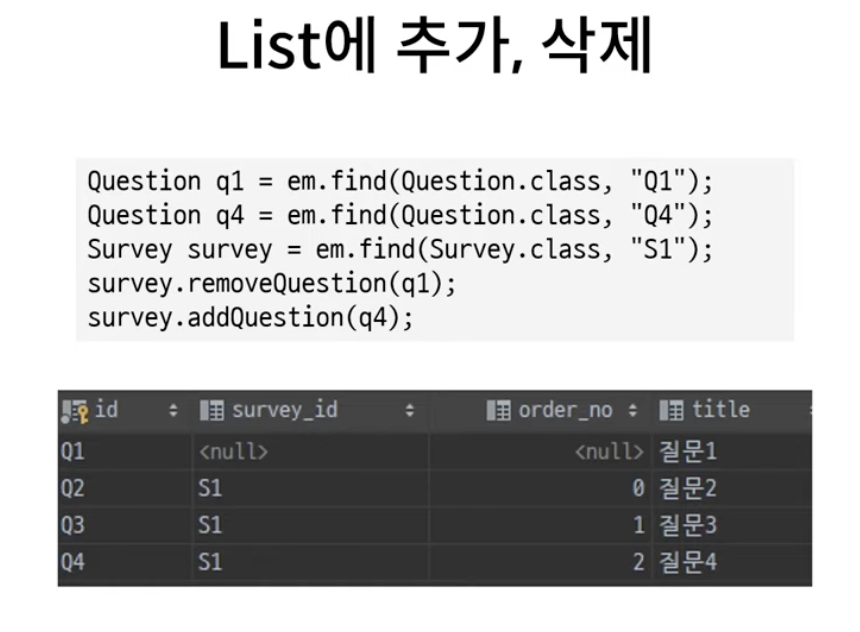
3. Map
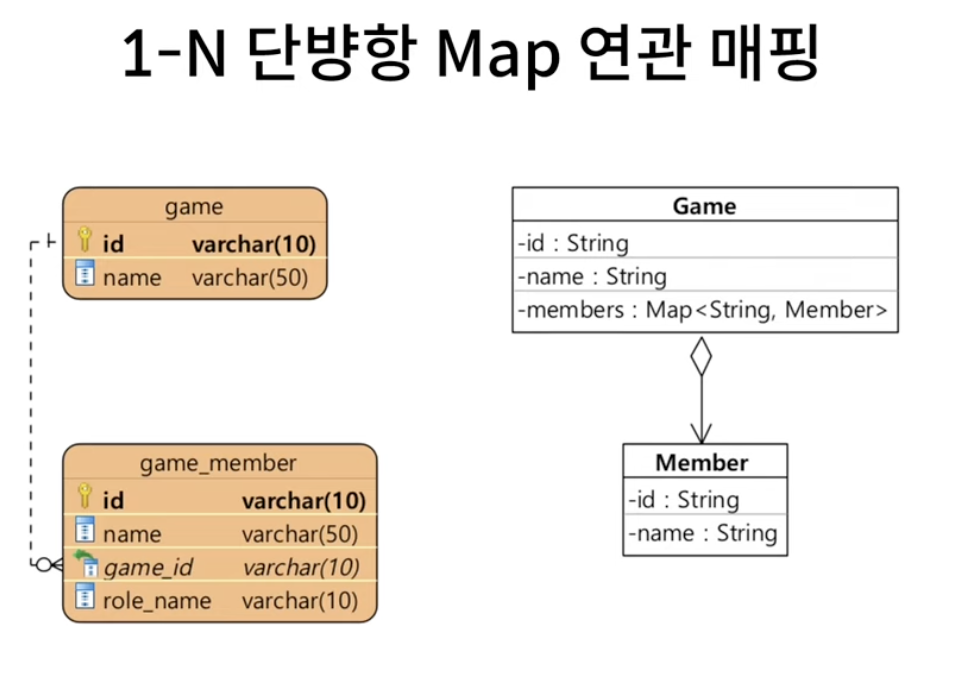
@Entity
@Table(name="game")
public class Game{
@Id
private String id;
private String name;
@OneToMany
@JoinColumn(name="game_id")
@MapKeyColumn(name="role_name")
private Map<String, Member> members = new HashMap<>();
}


17. 영속성 전파 & 연관 매핑 고려사항

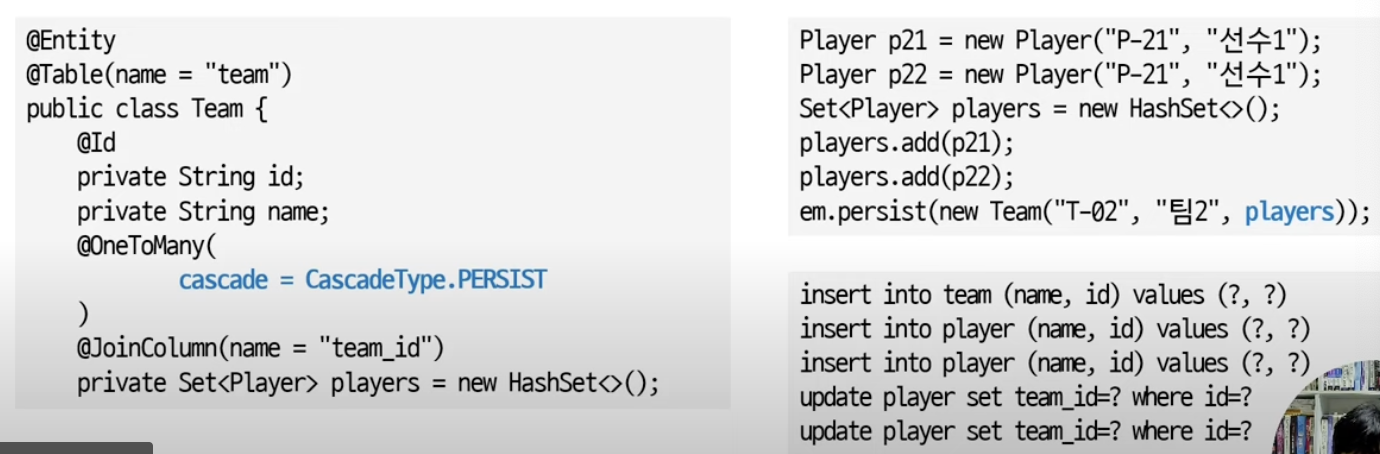
오른쪽은 조회하고 저장하는 것이 아니라, 생성하면서 저장 => 오류가 발생함!
WHY??
DB에 player 정보가 없기 때문에, Team 입장에서는 연관하는 정보가 없다고 인지하기 때문에 에러가 발생!
=> 영속성 전파를 통해 해결 가능!!
영속성 전파
: 연관된 엔티티에 영속 상태를 전파하는 것!
: 예를 들면, 저장할 때, 연관된 엔티티(DB에 없는 데이터)도 함께 저장하는 것!!

엔티티 매니저가 제공하는 매서드 이름!!
주의
특별한 이유가 없다면, 사용하지 말자!!!!!!!
연관 고려 사항
- 연관 대신에 ID 값으로 참조 고려
- 객체 탐색이 쉽다고 연관 쓰기 없기
- 조회는 전용 쿼리나 구현 사용 고려(CQRS)
- 엔티티가 아닌 벨류인지 확인
- 1:1 , 1:N 관계는 특히!!!
- 1:N 보다는 N:1(어쩔 수 없이 써야한다면)
- 양방햔은 절대! 사용하지 말자
JPQL
: JPA Query Language
: SQL 쿼리와 유사
: 테이블 대신 엔티티 이름, 속성 사용

JPQL 기본 구조
- select 별칭 from 엔티티명 별칭
- 예
: select r from Review r
: select r from Review as r
쿼리 생성
- TypedQueryEntityManager#createQuery(String ql, ClassresultClass)
TypedQuery<Review> query = em.createQuery(
"select r from Review r", //쿼리
Review.class); // 결과 타입
)
List<Review> reviews = query.getResultList();검색 조건 지정
where + and , or, 괄호 등
select r from Review r where r.hotelId = :hotelId // 이름을 지정
select r from Review r where r.hoteld = ? // 위치기반으로 지정
select r from Review r where r.hoteld = :hotelId and r.mark > :minMark
select p from Player p where p.position = :pos or p.team.id = :teamId 파라미터
- 이름을 사용한 경우: query.setParameter("hotelId","H-001")
- 인덱스 기반: query.setParameter(0,"H-001")
TypedQuery<Review> query = em.createQuery(
"select r from Review r where r.hotelId = :hotelId order by r.id desc",
Review.class
);
query.setParameter("hotelId","H-001");정렬순서 order by
select r from Review r order by r.id
select r from Review r order by r.id asc
select r from Review r order by r.id desc
select p from Player p order by p.position,p.name
select p from player p order by p.team.id,p.name비교연산자

페이징 처리

외

19. CRITERIA
코드로 쿼리를 구성하는 API
: JPQL 대신 자바 코드 사용

기본 사용법

검색 조건 지정
: CQ#where 메서드에 검색 조건 전달
: 검색 조건은 CB를 이용해서 생성
ex) 같음 조건은 CB#equal()로 생성
: 검색 조건에 사용할 엔티티 속성은 Root#get() 메서드로 구함
Root<Review> root = cq.from(Review.class);
// 생성조건 : Review의 hotelId가 'H-001' 과 같음
Predicate predicate = cb.equal(root.get("hotelId"),"H-001");
cq.where(predicate);
정렬 순서
: CQ#orderBy로 정렬 지정
: CB#asc(), CB#desc()로 정렬 정보(Order) 생성
- 정렬 대상 속성은 Root#get()로 구함
Order orderId = cb.asc(root.get("id")); cq.orderBy(orderId); - 한개 이상 정렬 지정 가능
cq.orderBy( cb.asc(root.get("hotelId")), cb.desc(root.get("id")) );

Root#get()과 제네릭 타입
: Pathget(String attributeName)
: in() 조건 생성할 때 타입 파라미터 지정하면 유용

Criteria 사용 이점
- 동적인 검색 조건 지정 가능


20. 기타 특징
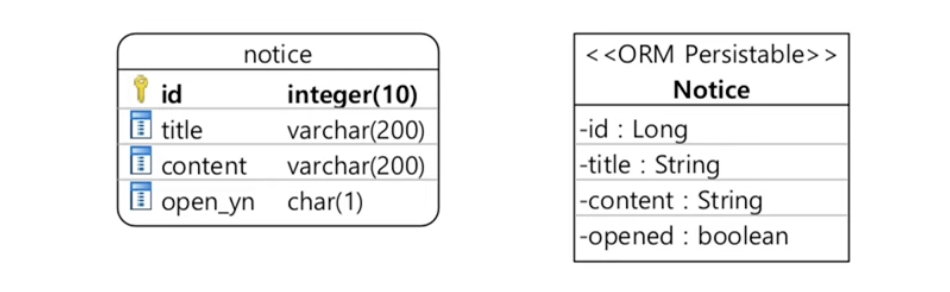
@AttributeConverter
: 매핑을 지원하지 않는 자바 타입과 DB 타입 간 변환 처리
ex) boolean 타입과 char(1) 타입 간 변환
public class BooleanYesNoConverter implements AttributeConverter<Boolean,String>{
@Override
// entity를 db column으로 변환 매핑
public String convertToDatabaseColumn(Boolean attribute){
return Objects.equals(Boolean.TRUE, attribute) ? "Y" : "N";
}
@Override
// db column을 entity로 변환 매핑
public Boolean convertToEntityAttribute(String dbData){
return "Y".equals(dbData) ? true : false;
}
}@Entity
@Table(name="notice")
public class Notice{
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
@Column(name="notice_id")
private Long id;
private String title;
private String content;
@Column(name="open_yn")
@Convert(converter=BooleanYesNoConverter.class)
private boolean opened;
...
}@Formula
-
SQL을 이용한 속성 매핑
: 조회에서만 매핑 처리(INSERT, UPDATE 매핑 대상 아님)
: 하이버네이트 제공 기능(org.hibernate.annotaions.Formula)
: 주로 DB 함수 호출, 서브 쿼리 결과를 매핑@Entity public class Notice{ @Id @GeneratedValue(strategy=GenerationType.IDENTITy) @Column(name="notice_id") private Long id; .... @Column(name="cat") private String categoryCode; @Formula("(select c.name from category c where c.cat_id = cat)") // sql의 결과를 categoryName과 매핑 private String categoryName; }
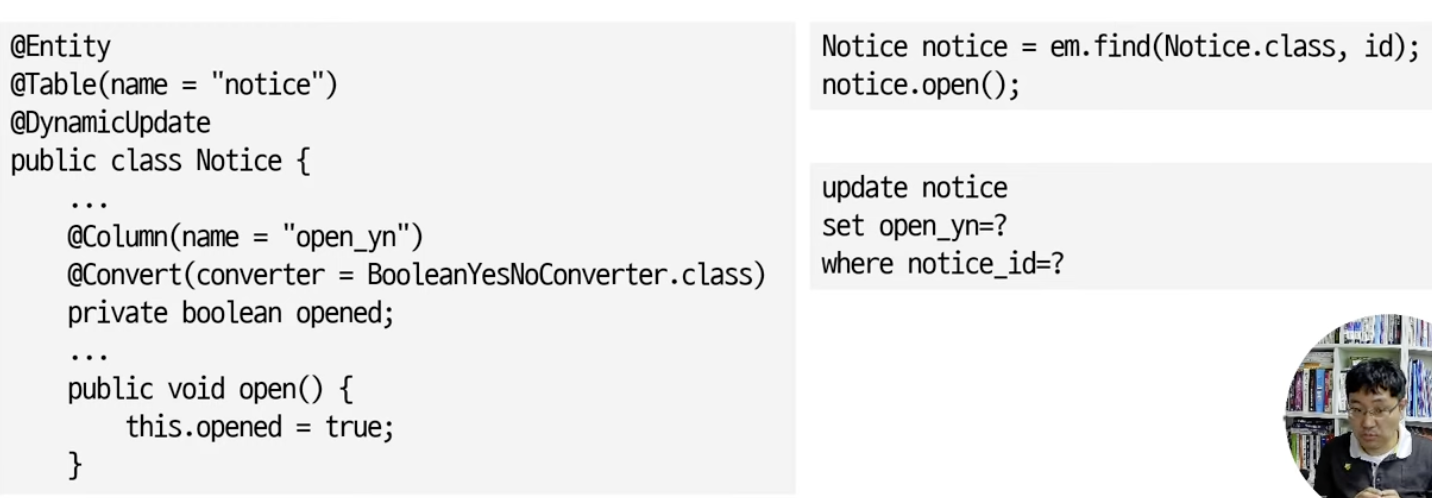
@DynamicUpdate / @DynamicInsert
@DynamicUpdate: 변경된 칼럼만 UPDATE 쿼리에 포함@DynamicInsert: null이 아닌 칼럼만 INSERT 쿼리에 포함- 주의: 기본값을 사용할 수 있음(null을 지정해야 할 경우 사용 X)
- 수정 쿼리의 칼럼
: 수정 쿼리는 기본적으로 모든 칼럼 포함@Entity @Table(name="notice") public class Notice{ ... @Column(name="open_yn") @Convert(converter=BooleanYesNoConverter.class) private boolean opened; ... public void open(){ this.opened = true; } }Notice notice = em.find(Notice.class, id); // open 매서드를 통해 수정을 실행하면 notice.open();// 모든 속성에 업데이트가 일어난다 update notice set cat=?, content=?, open_yn=?, title=? where notice_id=?@DynamicUpdate를 붙여주면 실제 변경된 것만 쿼리에 포함시킬 수 있다!
@Immutable
변경 추척 대상에서 제외 처리
: 변경 추적 위한 메모리 사용 감소
: 주로 조회 목적으로만 사용되는 엔티티 매핑에 사용
: @Immutable이 적용된 엔티티도 저장은 됨
: 코드 수준에서 persist()하지 않도록 주의!
@Entity
@Table(name="notice")
@Immutable
public class NoticeReadonly{
@Id
@Column(name="notice_id")
private Long id;
private String title;
}@Subselect
select 결과를 엔티티로 매핑
: 수정 대상이 아니므로 @Immutable과 함께 사용

Spring Data JPA 01
JPA를 쌩으로 사용하진 않음
Spring Boot에서는 따로 거의 설정 없이 JPA를 사용할 수 있다.
- 자동 설정되는 것들
: persistence.xml
: EntityManagerFactory - 자동으로 스프링 연동되는 것들
: 스프링 트랜잭션 연동
: EntityManager 연동
사용법
-
spring-boot-starter-data-jpa 의존성 주입
: 필요한 설정 자동 처리

-
스프링 부트 설정

-
엔티티 단위로 Repository 인터페이스를 상속 받은 인터페이스 생성
: 또는 그 하위 인터페이스Repository 인터페이스?
: 스프링 데이터 JPA가 제공하는 특별한 타입으로, 이 인터페이스를 상속받은 인터페이스를 이용해 빈(bean) 객체를 생성

cf) ID는 유저pk
-
지정한 규칙에 맞게 메서드 추가

-
필요한 곳에 해당 repository 인터페이스 타입을 주입해서 사용

Spring Data JPA 02. 메서드 작성 규칙
DB 연동 코드 구현 방법
: Repository 인터페이스를 상속한다.
: 정해진 규칙에 따라 매서드를 추가한다.
엔티티 조회 메서드
findById
- T findById(ID id)
- Optional findById(ID id)
public interface UserRepository extends Repository<User, String>{
Optional<User> findById(String email);
}엔티티 삭제 메서드
delete
- void delete(T entity) : 삭제할 Entity를 전달받는 경우
- void deletedById(ID id) : 삭제할 id를 전달받는 경우
: 내부적으로 findById()로 엔티티를 조회한 뒤 delete()로 삭제
삭제할 대상이 존재하지 않으면 예외 발생
public interface UserRepository extends Repository<User, String>{
Optional<User> findById(String email);
void delete(User user);
}Optional<User> userOpt = userRepository.findById("email2@email.com");
userOpt.ifPresent(user -> {
userRepository.delete(user);
})엔티티 저장 메서드
save
: 추가할 entity를 전달
- void save(T entity)
- T save(T entity)
public interface UserRepository extends Repository<User, String> {
User save(User user); // or
void save(User user);
}User savedUser = userRepository.save(new User(,,,));
User user = new User(,,,);
userRepository.save(user);save() 호출시 실행 쿼리

select가 실행된 후 insert가 실행된다
why? jpa가 제공하는 repository 구현 때문에
save() 동작 방식
public <S extends T> S save(S entity){
Assert.notNull(entity, "Entity must not be null.");
// entity가 새엔티티면
if(this.entityInformation.isNew(entity)){ // 저장
this.em.persist(entity);
return entity;
} else{
// select 실행
return this.em.merge(entity);
}
}: 새 엔티티면 EntityManager#persist() 실행
: 새 엔티티가 아니면 EntityManager#merge() 실행
: 새 엔티티인지 판단하는 기준
- Persistable(jpa가 제공하는 인터페이스)을 구현한 엔티티
: isNew()로 판단 - @Version 속성이 있는 경우(동시성 관련 처리를 할 때 사용함)
: 버전 값이 null이면 새 엔티티로 판단 - 식별자가 참조 타입이면
: 식별자가 null인 경우 새 엔티티로 판단userRepository.save(new User("a@a.com",...)) - 식별자가 숫자 타입이면
: 0이면 새 엔티티로 판단
select하는 과정을 없애고 싶다 하는 경우에는 persistable을 구현하면 된다.

조회 - 특정 조건으로 찾기
findBy프로퍼티(값): 프로퍼티가 특정 값인 대상
: ListfindByName(String name)
: ListfindByGradeAndName(Grade g,String name)- 조건 비교
: ListfindByNameLike(String keyword)
: ListfindByCreatedAtAfter(LocalDateTime time)
: ListfindByYearBetween(int from, int to)
: LessThan, IsNull, containing, in,.. 스프링 레퍼런스 문서 참고 findAll(): 모두 조회
정리
정해진 규칙에 따라 인터페이스만 작성하면 끝!
- findBy 메서드를 남용하지 말 것
- 검색 조건이 단순하지 않으면 @Query, SQL, 스펙/QueryDSL 사용하자
Spring Data JPA 03. 정렬, 페이징, @Query
정렬1
find 메서드에 OrderBy 붙임
- OrderBy 뒤에 프로퍼티명 + Asc/Desc
- 여러 프로퍼티 지정 가능
// order by u.name desc
List<User> findByNameLikeOrderByNameDesc(String keyword);
// order by u.name asc
List<User> findByNameLikeOrderByNameAsc(String keyword);
// order by u.name asc, email desc
List<User> findByNameLikeOrderByNameAscEmailDesc(String keyword);정렬2
Sort 타입 사용
List<User> findByNameLike(String keyword, Sort sort);Sort sort1 = Sort.by(Sort.Order.asc("name"));
// order by u.name asc
List<User> users1 = userRepository.findByNameLike("이름%", sort1);
// 여러 속성 정렬도 가능
Sort sort2 = Sort.by(Sort.Order.asc("name"), Sort.Order.desc("email"));
// order by u.name asc, email desc
List<User> users2 = userRepository.findByNameLike("이름%", sort2);페이징
Pageable / PageRequest 사용
: pageable 타입을 파라미터로 받으면 된다
List<User> findByNameLike(String keyword, Pageable pageable);
// page는 0부터 시작
// 한 페이지에 10개 기준으로 두번째 페이지 조회
Pageable pageable = PageRequest.ofSize(10).withPage(1); // 한페이지에 들어갈 데이터의 수 = 10, 2번째 페이지를 불러와라
List<User> users3 = userRepository.findByNameLike("이름%",pageable);Sort sort3 = Sort.by(Sort.Order.asc("name"), Sort.Order.desc("email"));
Pageable pageable = PageRequest.ofSize(10).withPage(1).withSort(sort3); // 정렬순서도 줄 수 있다
List<User> users3 = userRepository.findByNameLike("이름%",pageable);페이징 조회 결과 page로 구하기
- Page 타입: 페이징 처리에 필요한 값을 함께 제공해줌
- 전체 페이지 개수, 전체 개수 등
- Pageable을 사용하는 메서드의 리턴 타입을 Page로 지정하면 됨
Page<User> findByEmailLike(String keyword, Pageable pageable);Pageable pageable = PageRequest.ofSize(10).withPage(0).withSort(sort);
Page<User> page = userRepository.findByEmailLike("email%", pageable);
long totalElements = page.getTotalElements(); // 조건에 해당하는 전체 갯수
int totalPages = page.getTotalPages(); // 전체 페이지 개수
List<User> content = page.getContent(); // 현재 페이지 결과 목록
int size = page.getSize(); // 페이지 크기
int pageNumber = page.getNumber(); // 현재 페이지
int numberOfElements = page.getNumberOfElements(); // content의 갯수Query
매서드 명명 규칙이 아닌 JPQL을 직접 사용할 때 사용
: 매서드 이름이 간결해짐
// since 매개변수 값을 받아서 쿼리에 이용할 수 있음
@Query("select u from User u where u.createDate > :since order by u.createDate desc")
List<User> findRecentUsers(@Param("since") LocalDateTime sinc);
@Query("select u from User u where u.createDate > :since")
List<User> findRecentUsers(@Param("since") LocalDateTime since, Sort sort);
// pageable을 사용해서 Page 형태로 return 가능
@Query("select u from User u where u.createDate > :since")
Page<User> findRecentUsers(@Param("since") LocalDateTime since, Pageable pageable);정리
- 매서드 명으로 정렬지정할 수 있지만 가능하면 Sort 사용하자
- Pageable/PageRequest로 페이징 처리 가능
- findTop/findFirst,findTopN/findFirstN (상위 몇개만 찾을 수도 있다)
- @Query를 사용해서 JPQL 지정
Spring Data JPA 04. 스펙
Specification
검색 조건을 생성하는 인터페이스
public interface Specification<T> extends Serializable{
@Nullable
Predicate toPredicate(Root<T> root, CriteriaQuery<?> query, CriteriaBuilder criteriaBuilder);
}repository : Specification을 이용한 검색 조건 지정
- List
<T>findAll(Specification<T>spec)
public interface UserRepository extends Repository<User, String> {
List<User> findAll(Specification<User> spec);
}Specification 구현/사용
예시
public class UserNameSpecification implements Specification<User> {
private final String value;
public UserNameSpecification(String value){
this.value = value;
}
@Override
public Predicate toPredicate(Root<User> root, CriteriaQuery<?> query, CriteriaBuilder cb){
return cb.like(root.get("name"), "%" + value + "%");
}
}UserNameSpecification spec = new UserNameSpecification("이름");
List<User> users = userRepository.findAll(spec);람다로 간결하게 구현
Specification을 구현한 클래스를 매번 만들기 보다는 람다식을 이용해서 스펙 생성
public class UserSpecs{
public static Specification<User> nameLike(String value) {
return(root,query,cb) -> cb.like(root.get("name"),"%"+value+"%");
}
}UserNameSpecification spec = UserSpecs.nameLike("이름");
List<User> users = userRepository.findAll(spec);검색 조건 조합
Specification의 or/and 매서드로 이용해서 조합
Specification<User> nameSpec = UserSpecs.nameLike("이름1");
Specification<User> afterSpec = UserApecs.createdAfter(LocalDateTime.now().minsHours(1));
Specification<User> compositespec = nameSpec.and(afterSpec);
List<User> users2 = userRepository.findAll(compositespec);Specification<User> spec3 = UserSpecs.nameLike(keyword).and(UserSpecs.createdAfter(dateTime));
List<User> users3 = userRepository.findAll(spec3);검색 조건 조합
선택적으로 조합
Specification<User> spec = Specification.where(null);
if(keyword!=null && !keyword.trim().isEmpty()){
spec = spec.and(UserSpecs.nameLike(keyword));
}
if(dateTime != null){
spec = spec.and(UserSpecs.createdAfter(dateTime));
}
List<User> users = userRepository.findAll(spec);Specification + 페이징, 정렬 기능
List<User> findAll(Specification<T> spec, Sort s);
Page<User> findAll(Specification<T> spec, Pageable p);
List<User> findAll(Specification<T> spec, Pageable p);SpecBuilder
if절을 덜 쓰기 위한 SpecBuilder 구현
Specification<User> specs
= SpecBuilder.builder(User.class)
.ifHasText(keyword, str-> UserSpecs.nameLike(str))
.ifNotNull(dt, value->UserSpecs.createdAfter(value))
.toSpec();Specification<User> spec = Specification.where(null);
if(keyword != null && !keyword.trim().isEmpty()) {
spec = spec.and(UserSpecs.nameLike(keyword));
}
if(dateTime != null) {
spec = spec.and(UserSpecs.createdAfter(dateTime));
}참고
https://javacan.tistory.com/entry/Simple-Spec-Builder-for-Spring-Data-Specification-Composition
정리
- Specification 인터페이스를 이용한 검색 조건 생성
- 조합 가능
: and() / or()로 검색 조건 조합
Spring Data JPA 기초 05. 기타
count매서드
long Count() // 전체 갯수 조회
long countByNameLike(String keyword) // 조건으로 갯수 조회
long count(Specification<User> spec) // spec 조건을 이용해서 갯수 조회@Query 네이티브 쿼리
- @Query annotation
: JPQL 아닌 SQL 실행
(식별자를 새로 구해서 값을 id로 사용해야 하는 경우 유용)
@Query(
value = "select * from user u where u.create_date >= date_sub(now(), interval 1 day)",
nativeQuery = true
)
List<User> findRecentUsers();
@Query(
value = "select max(create_date) from user",
nativeQuery = true
)
LocalDateTime selectLastCreateDate();한 개 결과 조회
User findByName(String name)
Optional<User> findByName(String name): return type이 List가 아닌 Entity로 줌
: 존재하면 해당 값, 없으면 null 또는 빈 Optional
: 조회 결과 갯수가 두개 이상이면 예외발생!
인터페이스

인터페이스를 상속하면 편리한가?
- Repository 하위 인터페이스를 상속하면 관련 메서드 모두 포함
: 메서드를 추가해줄 필요 없음
public interface UserRepository extends JpaRepository<User, String>{
// 매서드를 정의하지 않아도 CrudRepository와 JpaRepository에 있는
// save(), findById(), findAll() 등의 매서드를 제공
} - 개인적으로는 Repository를 상속받고, 필요한 메서드만 만드는 방법을 선호
