CPU 스케줄링(scheduling)은 다중 프로그램 운영체제의 기본입니다. 운영체제는 CPU를 프로세스 간에 교환함으로써, 컴퓨터를 보다 생산적으로 만듭니다.
여기서는 프로세스 스케줄링과 스레드 스케줄링에 대해서 알아볼 것입니다.
1. 기본 개념
다중 프로그래밍의 목적은 CPU 이용률을 최대화하기 위해 항상 실행 중인 프로세스를 가지게 하는데 있습니다.
Blocking작업을 수행하는 프로세스는 해당 CPU의 점유를 다른 프로세스에게 반환해줘야 계속해서 CPU를 사용할 수 있습니다.
이를 위해 CPU 스케줄링이 요구됩니다.
1.1 CPU-I/O 버스트 사이클
CPU 스케줄링의 성공은 프로세스들의 다음과 같은 관찰될 성질에 의해 좌우됩니다.
프로세스의 실행은 다음과 같은 두 가지 사이클로 구성됩니다.
- CPU 실행(CPU Burst)
- I/O 대기(I/O Burst)
1.2 CPU 스케줄러
CPU가 유후 상태가 될 때, 운영체제는 준비 큐에 있는 프로세스 중에서 하나를 선택해서 실행합니다.
선택 절차는 CPU 스케줄러에 의해 수행되고, 방식으로는 FIFO, 우선순위 큐, 트리 또는 연결 리스트로 구현할 수 있습니다.
큐에 있는 레코드들은 일반적으로 프로세스들의 프로세스 제어 블록(PCB)들 입니다.
CPU와 준비큐에 대해서 정리하자면 다음과 같습니다.
CPU와 준비큐
- CPU 스케줄링은 준비 큐에 있는 프로세스들 중 하나 선택 <- 알고리즘에 의해 선택
- 멀티 스레딩 환경에서는 개별 스레드들이 CPU 스케줄링 대상이 될 수 있다.
- 준비큐에는 실행 대기 중인 프로세스(또는 스레드)의 정보가 저장됩니다.
- 프로세스 상태, PC, 레지스터 집합 상태, 메모리 관리 정보 등등
- 준비 큐에 저장되는 것은 PCB의 실제 데이터가 아닌 PCB의 주소
1.3 선점 및 비선점 스케줄링
CPU 스케줄링 결정은 다음의 네 가지 상황에서 발생할 수 있습니다.
- 한 프로세스가 실행 상태에서 대기 상태로 전환될 때
- 프로세스가 실행 상태에서 준비 완료 상태로 전환될 때
- 프로세스가 대기 상태에서 준비 완료 상태로 전환될 때
- 프로세스가 종료될 때
여기서는 두 가지의 스케줄링 방법에 대해서 설명하고 있습니다.
- 선점형 방식: CPU가 제어권을 가지고 있는 것
- 비선점형 방식: CPU가 제어권을 가지고 있지 않은 것
선점 스케줄링은 데이터가 다수의 프로세스에 의해 공유될 때 Race Condition을 초래합니다.
선점은 또한 운영체제 커널 설계에 영향을 줍니다. 시스템 콜을 처리할 동안, 커널은 한 프로세스를 위한 활동으로 바쁠 수 있습니다.
만약, 중요한 커널 작업을 하고 있는 동안에 다른 프로세스가 선점되어, 커널이 동일한 구조를 읽거나 변경하려고 한다면 어떻게 될 것인가에 대한 문제가 생깁니다.
비선점형 커널은 문맥 교환을 하기 전에 시스템 콜이 완료되거나 입출력 완료를 기다리며 프로세스가 봉쇄되기를 기다립니다. 이것은 커널 구조를 단순하게 만들지만 CPU의 이용률 측면에서 좋지 않기에 실시간 컴퓨팅을 지원하기에는 좋은 모델이 아닙니다.
위에서 언급했던 선점 방식의 문제를 해결하기 위해서 mutex와 같은 동기화 기법이 요구됩니다.
1.4 디스패처
CPU 스케줄링 기능에 포함된 또 하나의 요소는 디스패처(dispatcher)입니다.
디스패처는 CPU 코어의 제어를 CPU 스케줄러가 선택한 프로세스에 주는 모듈입니다.
다음과 같은 작업을 포함합니다.
- 한 프로세스에서 다른 프로세스로 문맥을 교환하는 일
- 사용자 모드로 전환하는 일
- 프로그램을 다시 시작하기 위해 사용자 프로그램의 적절한 위치로 이동(jump)하는 일
디스패처가 하나의 프로세스를 정지하고 다른 프로세스의 수행을 시작하는데까지 소요되는 시간을 디스패치 지연(dispatch latency)라고 합니다.
문맥 교환은 자발적 문맥 교환과 비자발적 문맥 교환으로 구분됩니다.
- 자발적 문맥 교환: 현재 사용 불가능한 자원을 요청했기 때문에 프로세스가 CPU 제어를 포기
- 비자발적 문맥 교환: 타임 슬라이스가 만료되었거나 우선순위가 더 높은 프로세스에 의해 선점된 경우
2. 스케줄링 기준
CPU 스케줄링 알고리즘을 비교하기 위해서 여러 기준이 존재합니다.
- CPU 이용률(utilization)
- 처리량(throughput): 단위 시간당 완료된 프로세스의 개수
- 총처리 시간(turnaround time): 프로세스를 실행하는 데 소요된 시간, 프로세스의 제출 시간과 완료 시간의 간격
- 대기 시간(waiting time): 준비 큐에서 대기하면서 보낸 시간의 합
- 응답 시간(response time): 하나의 요구를 제출한 후 첫 번쨰 응답이 나올 때까지의 시간
CPU 이용률과 처리량은 최대화하고 총처리 시간, 대기 시간, 응답 시간을 최소화하는 것이 바람직합니다.
조금 더 정리를 해보자면, 무엇이 중요하는지는 요구 사항에 맞게 정해야 합니다.
예를 들어, 대화식 시스템에서는 평균 응답 시간을 최소화하는 것보다 응답 시간의 편차(variance)를 최소화하는 것이 중요할 것입니다.
3. 스케줄링 알고리즘
여기서는 소개되는 스케줄링 알고리즘은 처리 코어가 하나뿐이라고 가정하고 설명합니다. 즉, 한 개의 처리 코어를 가진 CPU가 한 개의 시스템이므로 한번에 하나의 프로세스만 실행할 수 있는 것입니다.
3.1 선입 선처리 스케줄링
가장 간단한 CPU 스케줄링 알고리즘은 선입 선처리(FIFO) 스케줄링 알고리즘입니다.
구현은 간단한데 프로세스가 준비 큐에 진입하면, 이 프로세스의 프로세스 제어 블록(PCB)을 큐의 끝에 연결하면 됩니다.
CPU가 가용 상태가 되면, 준비 큐에 앞부분에 있는 프로세스에 할당합니다.
해당 방식은 코드 작성이 쉽고 이해하기 쉽습니다.
단점은 평균대기 시간이 종종 대단히 길어질 수 있다는 점입니다.
예를 들어보자면,
| 프로세스 | 버스트 시간 |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
이와 같이 되어있다고 해봅시다. 만약, P1 -> P2 -> P3 순으로 도착했다면 평균대기 시간은 입니다.
P2 -> P3 -> P1 순으로 도착했다면 평균대기 시간은 입니다.
이 방식은 CPU-bound 프로세스와 많은 수의 I/O-bound 프로세스를 사용하는 상황에서도 문제가 발생할 수 있습니다.
우선 CPU-bound 프로세스들은 CPU 스케줄링에 의해 CPU를 선점하여 작업을 수행할 것입니다. 해당 시간동안 I/O 장치들을 쉬고 있습니다.
그러다가 자신의 CPU 버스트를 끝내고 I/O 장치로 이동하게 됩니다.
모든 I/O-bound 프로세스들은 매우 짧은 CPU 버스트를 갖고 있기 때문에, CPU 작업을 신속하게 끝내고 다시 I/O 큐로 이동하게 됩니다. 이 시점에서 CPU는 쉬고 있게 됩니다.
그러면 CPU 중심 프로세스는 다시 준비 큐로 이동해 CPU를 할당받게 됩니다.
이러한 악순환이 반복될 수 있습니다.
모든 다른 프로세스들이 하나의 긴 프로세스가 CPU를 양도하기를 기다리는 것을 호위 효과(convoy effect)라고 합니다.
해당 알고리즘은 특히 대화형 시스템에서 문제가 되는데, 그 이유는 대화형 시스템에서는 각 프로세스가 규칙적인 간격으로 CPU의 몫을 얻는 것이 매우 중요하기 때문입니다.
FIFO는 비선점형입니다.
3.2 최단 작업 우선 스케줄링
CPU 스케줄링의 다른 접근 방법은 최단 작업 우선(shortest-job-fist, SJF) 알고리즘입니다.
이 알고리즘은 각 프로세스에 다음 CPU 버스트 길이를 연관시킵니다.
CPU가 이용 가능해지면, 가장 작은 다음 CPU 버스트를 가진 프로세스를 할당합니다.
동일한 길이의 다음 CPU 버스트를 가지면, 순위를 정하기 위해 FIFO를 적용합니다.
이 알고리즘은 최단 다음 CPU 버스트(shortest-next-CPU-burst)라는 용어가 더 적합합니다.
예를 들어서 보자면,
| 프로세스 | 버스트 시간 |
|---|---|
| P1 | 6 |
| P2 | 8 |
| P3 | 7 |
| P4 | 3 |
이와 같이 프로세스가 있다고 하고, SJF 스케줄링 방식대로 동작한다면 P4 -> P1 -> P3 -> P2 순으로 동작합니다.
따라서, 평균대기 시간은 입니다.
비교 차원에서 FIFO 알고리즘 스케줄링을 사용한다면, 평균대기 시간은 10.25ms이 되었을 것입니다.
SJF 알고리즘이 최적이기는 하지만, 다음 CPU 버스트의 길이를 알 방법이 없기 때문에 CPU 스케줄링 수준에서는 구현할 수 없습니다.
한 가지 접근 방식은 SJF 스케줄링과 근사한 방법을 사용하는 것입니다. 즉, 예측값을 사용하는 방법입니다. 다음 CPU 버스트가 이전의 CPU 버스트와 비슷하다고 기대하고 근삿값을 계산하여, 가장 짧은 예상 CPU 버스트를 가진 프로세스를 선택할 수 있습니다.
이때 이전 하나만 가지고 계산하는 것이 아닌 최신의 정보와 과거의 역사를 가지고 지수 평균한 것으로 예측하는 것입니다.
SJF 알고리즘은 선점형이거나 또는 비선점형일 수 있습니다.
앞의 프로세스가 실행되는 동안 새로운 프로세스가 준비 큐에 도착하면 선택이 발생합니다. 새로운 프로세스가 현재 실행되고 있는 프로세스의 남은 시간보다 더 짧은 CPU 버스트를 가질 경우 다음과 같은 행동을 취할 수 있습니다.
- 현재 실행하는 프로세스를 선점 -> 선점형 SJF 알고리즘
- 현재 실행하고 있는 프로세스가 자신의 CPU 버스트를 끝내도록 허용 -> 비선점형 SJF 알고리즘
3.3 라운드 로빈 알고리즘
라운드 로빈(RR) 스케줄링 알고리즘은 FIFO와 유사하지만 시스템이 프로세스들 사이를 옮겨 다닐 수 있도록 선점이 추가됩니다.
시간 할당량(time quantum), 또는 타임슬라이스(time slice)라고 하는 작은 단위의 시간을 정의합니다.
시간 할당량은 일반적으로 10ms ~ 100ms 동안입니다. 준비 큐는 원형 큐(circular queue)로 동작합니다.
CPU 스케줄러는 준비 큐를 돌면서 한 번에 한 프로세스에 한 번의 시간 할당량 동안 CPU를 할당합니다.
CPU 스케줄러는 첫 번째 프로세스를 선택해 시간 할당량 이후에 인터럽트를 걸도록 타이머(timer)를 설정한 후, 프로세스를 디스패치(dispatch)합니다.
여기서는 두 가지 상황이 존재할 수 있는데,
- CPU 버스트 <= 시간 할당량
- CPU 버스트 > 시간 할당량
만약, 현재 실행중인 프로세스의 CPU 버스트가 한 번의 시간 할당량보다 적다면, 프로세느느 자신이 CPU를 자발적으로 방출할 것입니다.
만약 프로세스가 다음과 같은 버스트 시간을 가지고 있다면,
| 프로세스 | 버스트 시간 |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
다음과 같은 결과를 보여줄 것입니다.

평균대기 시간은 5.66ms입니다.
RR 스케줄링 알고리즘은 선점형입니다.
RR 알고리즘의 성능은 시간 할당량 크기에 매우 많은 영향을 받습니다.
극단적인 경우, 시간 할당량이 너무 크다면 그것은 FIFO 정책과 같습니다. 반대로 시간 할당량이 너무 적다면 매우 많은 Context Switching이 발생할 것입니다.
시간 할당량의 크기에 따라서 총처리 시간이 바뀔 수 있다는 점을 기억해두면 됩니다.
3.4 우선순위 스케줄링
SJF 알고리즘은 일반적인 우선순위 스케줄링 알고리즘의 특별한 경우입니다.
우선순위가 각 프로세스들에 연관되어 있으며, CPU는 가장 높은 우선순위를 가진 프로세스에 할당됩니다.
우선순위가 같다면 FIFO 순서로 스케줄 됩니다.
우선순위는 내부적 또는 외부적으로 정의될 수 있습니다. 내부적으로 정의된 우선순위는 프로세스의 우선순위를 계산하기 위해 어떤 측정 가능한 양들을 사용합니다.
내부적 요인
- 시간 제한
- 메모리 요구
- 열린 파일의 수
- 평균 I/O 버스트의 평균 CPU 버스트에 대한 비율 등
외부적 요인
- 프로세스의 중요성
- 컴퓨터 사용을 위해 지불되는 비용의 유형과 양
- 그 작업을 후원하는 부서 그리고 정치적인 요인 등
우선순위 스케줄링은 선점형이거나 비선점형이 될 수 있습니다.
여기서 주의해야될 점은 무한 봉쇄(indefinite blocking) 또는 기아 상태(starvation)입니다.
- 무한 봉쇄: 낮은 우선순위 프로세스들이 무한히 대기하는 경우가 발생
- 기아 상태: 실행 준비는 되어 있으나 CPU를 사용하지 못하는 상황
부하가 과중한 컴퓨터 시스템에서는 높은 우선순위의 프로세스들이 꾸준히 들어올 수 있다는 점을 주의하자.
이를 해결하기 위한 방안으로 노화(aging)을 고려해볼 수 있습니다.
즉, 시간이 지날수록 우선순위를 점진적으로 증가시키는 것입니다.
다른 옵션으로는 라운드 로빈과 우선순위 스케줄링을 결합하는 방법입니다.
일반적인 동작은 우선순위 스케줄링으로 하되, 우선순위가 같은 프로세스들은 라운드 로빈으로 스케줄링 하는 것입니다.

3.5 다단계 큐 스케줄링
앞서 사용했던 방식들은 큐가 관리하는 방식에 따라 우선순위가 가장 높은 프로세스를 결정하기 위해 O(n) 검색이 필요할 수 있습니다.
실제로, 우선순위마다 별도의 큐를 갖는 것이 더 쉬운 때도 있으며 우선순위 스케줄링은 우선순위가 가장 높은 큐에서 프로세스를 스케줄 합니다.
다단계 큐는 우선순위 스케줄링이 라운드 로빈과 결합한 경우에도 효과적입니다.
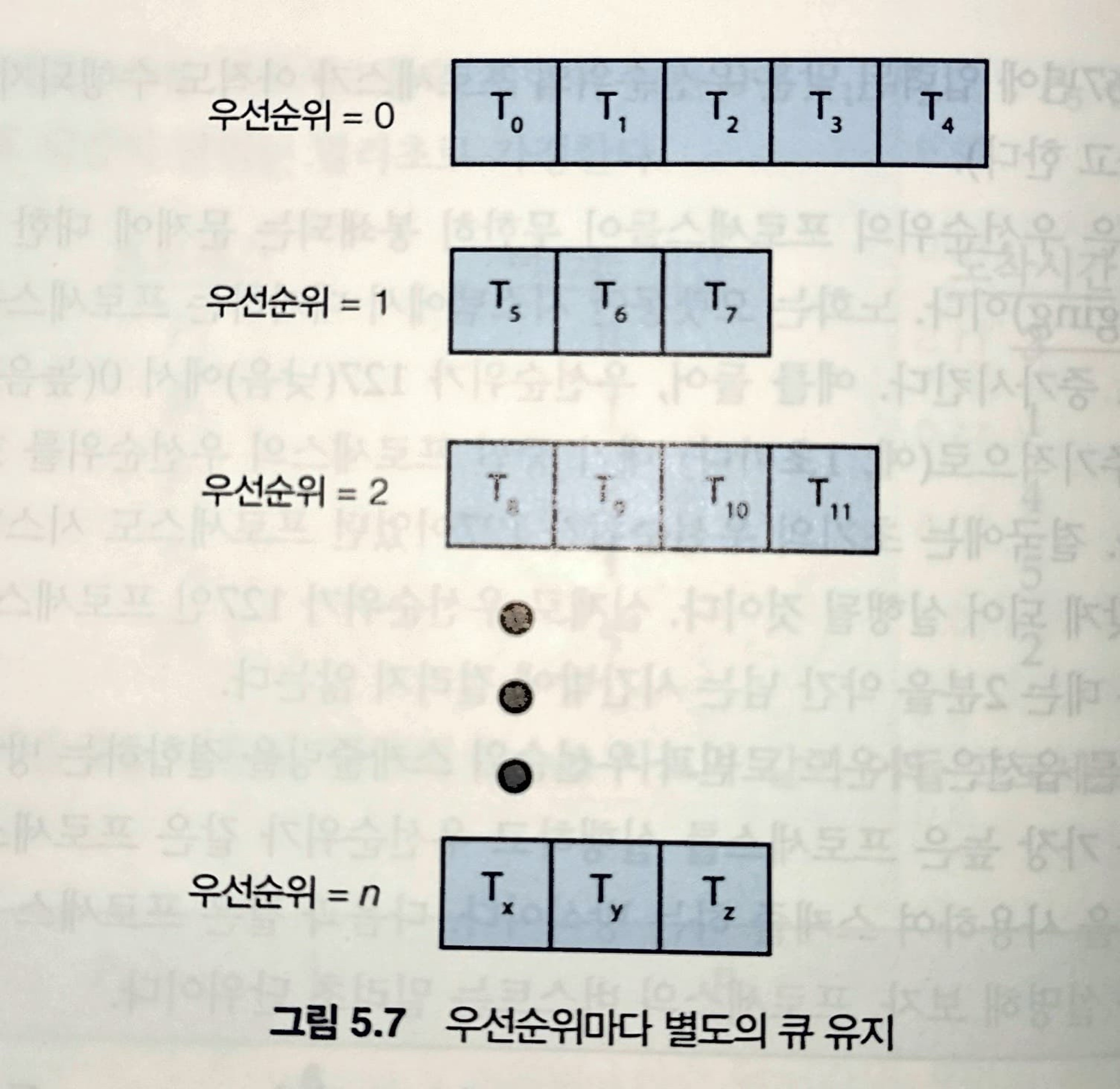
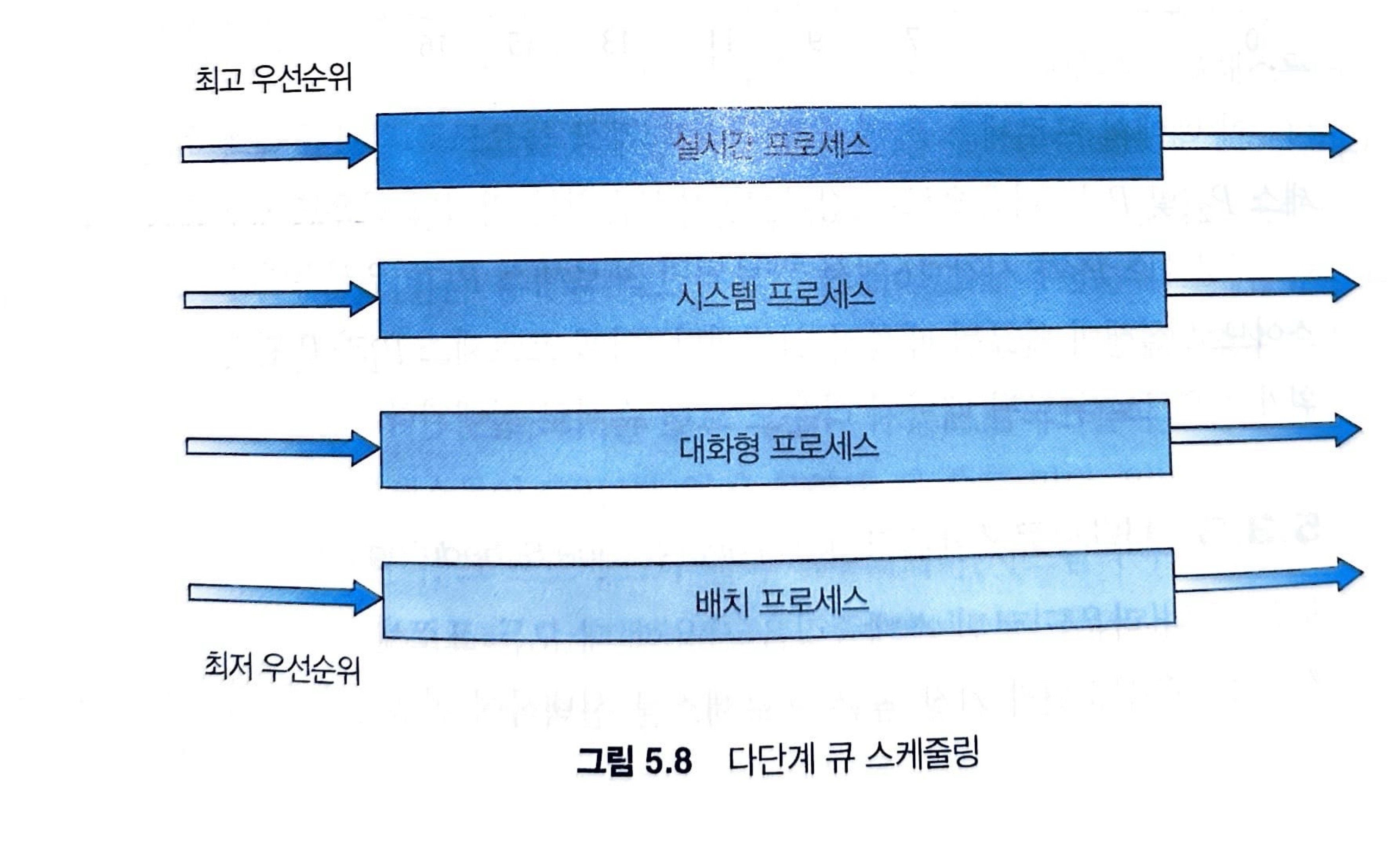
여기서는 포그라운드 프로세스가 더 높은 우선순위를 가지는 형태로 정의된 그림입니다.
일반적인 라운드 로빈방식처럼 시간할당량을 각 큐에 동일하게 분배할 수 있지만, 우선순위 별로 나눠진 큐들에게 각각 다른 가중치를 부여할 수도 있습니다.
이것은 WFQ(Weighted Fair Queue) 방식이라고 생각할 수 있습니다. 우선순위가 높을수록 높은 가중치를 매겨 더 높을 시간 할당량을 받을 수 있습니다.
3.6 다단계 피드백 큐 스케줄링
다단계 큐 스케줄링 알고리즘에서는 일반적으로 프로세스들이 시스템 진입 시에 영구적으로 하나의 큐에 할당됩니다. 예를 들어서, 포그라운드와 백그라운드 프로세스를 위해 별도의 큐가 있으면, 프로세스들은 한 큐에서 다른 큐로 이동하지 않습니다.
이러한 방식은 스케줄링 오버헤드가 장점이 있으나 융통성이 적습니다.
다단계 피드백 큐 스케줄링 알고리즘은 프로세스가 큐들 사이를 이동하는 것을 허용합니다.
다음과 같은 요소들을 고려할 수 있습니다.
- CPU 점유 시간
- 대기 시간
- 등등
만약 우선순위가 낮은 큐에서 너무 오래 대기하는 프로세스가 있다면 점차 우선순위은 프로세스로 이동하여 기아를 방지할 수 있을 것입니다.
다단계 피드백 큐 스케줄러는 다음의 매개변수에 의해 정의됩니다.
- 큐의 개수
- 각 큐를 위한 스케줄링 알고리즘
- 한 프로세스를 높은 우선순위 큐로 올려주는 시기를 결정하는 방법
- 한 프로세스를 낮은 우선순위 큐로 강등시키는 시기를 결정하는 방법
- 프로세스에 서비스가 필요할 때 프로세스가 들어갈 큐를 결정하는 방법
이 스케줄링 알고리즘은 가장 일반적인 CPU 스케줄링 알고리즘입니다.
설계 중인 시스템에 부합하도록 구성이 가능하지만 그에 맞춰서 모든 매개변수들의 값을 선정하는 특정 방법이 필요하기 때문에 또한 가장 복잡한 알고리즘이기도 합니다.
4. 스레드 스케줄링
프로세스 모델에서 스레드를 도입하면서 두 가지 수준으로 스레드를 구분했습니다.
- 사용자 수준 스레드
- 커널 수준 스레드
사용자 수준 스레드는 스레드 라이브러리에 의해 관리되고 커널은 그들의 존재를 알지 못합니다.
중요한 점은 CPU상에서 실행되려면 커널의 도움이 필요하다는 것입니다.
LWP를 통한 간접적인 방식일지라도 사용자 수준 스레드는 궁극적으로 연관된 커널 수준 스레드에 사상되어야 합니다.
여기서 필요한 내용들을 정리하고 가겠습니다.
- 사용자 수준 스레드와 커널 수준 스레드:
- 사용자 수준 스레드(User-Level Threads, ULT)는 사용자 영역의 스레드 라이브러리에 의해 관리됩니다. 커널은 이러한 스레드의 존재를 직접적으로 알지 못합니다.
- 반면에, 커널 수준 스레드(kernel-Level Threads, KLT)는 운영체제의 커널에 의해 직접 관리됩니다.
- LWP(Lightweight Process):
- LWP는 "경량 프로세스"라고도 하며, 사용자 수준 스레드와 커널 수준 스레드 사이의 중간 단계를 제공합니다.
- 하나 이상의 사용자 수준 스레드가 하나의 LWP에 매핑될 수 있으며, 이 LWP는 다시 커널 수준 스레드에 매핑됩니다.
- LWP는 사용자 수준 스레드가 실제 CPU 자원을 사용하기 위한 경로를 제공합니다. (여기서 말하는 경로는 진짜 통로같은 느낌이 아닙니다. CPU 스케줄링이 될 수 있도록 커널 수준 스레드와 매핑해주는 경로의 의미입니다.)
- 스레드의 CPU 점유:
- 사용자 수준 스레드가 CPU에 실행되기 위해서는 결국 커널 수준 스레드에 매핑되어야 합니다.
- 이 과정에서 LWP가 중간 역할을 할 수 있으며, 이는 사용자 수준 스레드가 커널에 의해 스케줄링될 수 있게 합니다.
- 스레드가 CPU를 점유하고 있는 동안에는
커널 모드의 개입이 필요하지 않을 수 있습니다.(즉, 스케줄링으로 인해 CPU 선점을 하고 있는 상태)
하지만 스레드 스케줄링, 시스템 콜 처리, 입출력 처리 등은 커널 모드에서 수행됩니다.
- 스레드 스케줄링:
- 스레드가 준비 큐에 들어가고 CPU를 점유하기 위한 스케줄링은 커널 수준에서 이루어집니다.
- 사용자 수준 스레드는 스케줄링 매커니즘에 직접적으로 영향을 주지 않습니다. 하지만 LWP를 통해 커널 수준 스레드와 연결될 때, 커널은 이 스레드들을 스케줄링할 수 있습니다.
해당 로직을 이해할 때, 필자는 스레드의 동작의 초점을 커널에 맞춰서 생각한다. 스레드가 CPU를 선점하기 전까지 모드 비트는 0으로 커널 비트로 설정되어서 PCB에 저장되어 있을 것이고 PCB의 주소값을 참조하는 것은 준비 큐에서 스케줄링 되고 있거나 다른 작업(I/O 처리 혹은 입출력 처리 등등)을 하고 있을 수 있다.
그러다가 스레드가 CPU 스케줄링에 의해 CPU를 선점하게 되는 순간 모드 비트는 1로 사용자 비트로 변경되고 응용 프로세스 작업을 수행하다가 할당량 시간이 종료되거나 혹은 인터럽트가 발생하거나 종료되는 등과 같은 작업이 발생했을 때 다시 위의 과정으로 돌아갈 것입니다.
즉, 초점을 커널에 두고 선점되었을 때 응용 프로세스를 수행하도록 하고 다시 커널 모드로 돌아온다고 생각하는 것이 동작을 이해하기 수월했습니다.
추가적으로 처음에 프로세스를 생성할 때도 아마도 프로세스 안의 스레드가 LWP를 할당받고 거기서 하나의 커널 스레드랑 연결 되면서 처음에 커널 모드에서 커널 스레드가 필요 자원 체크 및 할당과 PCB 생성 등의 작업을 수행하고 이후 스케줄러가 스케줄링을 시작할 것이라고 생각한다.
4.1 경쟁 범위
사용자 수준과 커널 수준 스레드의 차이 중 하나는 그들이 어떻게 스케줄 되느냐에 있습니다.
다대일과 다대다 모델을 구현하는 시스템에서는 스레드 라이브러리는 LWP 상에서 스케줄 됩니다. 이러한 기법은 동일한 프로세스에 속한 스레드들 사이에서 CPU를 경쟁하기 때문에 프로세스 경쟁 범위(Process Contention Scope, PCS)라고 합니다.
우리가 스레드 라이브러리가 사용자 수준 스레드를 가용한 LWP 상에서 스케줄 한다고 말하는 경우, 스레드가 실제로 CPU 상에서 실행 중이라는 것을 의미하지는 않습니다.
알기 쉽게 말하자면, 하나의 커널 스레드에 mapping 되어 있는 LWP를 두고 여러 사용자 수준 스레드들이 경쟁할 수 있고 이것 또한 스케줄 한다고 말하는 것이고, 사용자 수준 스레드들이 경쟁을 통해 LWP의 사용을 선점했다고 해도 그것이 CPU의 사용 선점을 의미하지는 않다는 것입니다.
단지, CPU 스케줄링의 대상이 되었다는 것일 뿐 입니다.
실제로 CPU상에서 실행되기 위해서는 운영체제가 LWP의 커널 스레드를 물리적인 CPU 코어로 스케줄 하는 것을 필요로 합니다.
CPU 상에서 어느 커널 스레드를 스케줄 할 것인지 결정하기 위해서 커널은 시스템-경쟁 범위(System-Contention Scope, SCS)를 사용합니다.
SCS 스케줄링에서의 CPU에 대한 경쟁은 시스템상의 모든 스레드 사이에서 일어납니다.
Windows와 Linux 같은 일대일 모델을 사용하는 시스템은 오직 SCS만을 사용하여 스케줄합니다.
전형적으로 PCS는 우선순위에 따라 행해지고, 높은 우선순위를 가진 실행 가능한 프로세스를 선택합니다. PCS는 통상 더 높은 우선순위의 스레드를 위하여 현재 실행 중인 스레드를 선점한다는 것을 주의해야 합니다. 그러나 같은 우선순위의 스레드들 사이에는 타임 슬라이스에 대한 보장은 없습니다.
Pthread의 스레드 생성을 소개하면서 Scope 설정하는 방법과 확인하는 코드에 대한 설명을 제시하고 있지만 넘어가겠습니다.
5. 다중 처리기 스케줄링
현재까지는 단일 처리기 코어를 가진 시스템을 고려해봤지만, 여기서는 다중 처리기에 대해서 살펴볼 것이다. 단일 처리기 코어를 가진 시스템에서는 불가능했던 부하 분산(load sharing)이 가능해졌다는 것에 주목합시다.
전통적으로 다중 처리기라는 용어는 여러 개의 물리적 프로세서를 제공하는 시스템을 말하며, 각 프로세서에는 하나의 단일 코어 CPU가 포함되어 있습니다.
물론 이러한 개념은 과거의 개념이고 현재 다중 처리기는 다음 시스템 아키텍어들에 사용될 수 있습니다.
- 다중 코어 CPU
- 다중 스레드 코어
- NUMA 시스템
- 이기종 다중 처리
5.1 다중 처리기 스케줄링에 대한 접근 방법
다중 처리기 시스템의 CPU 스케줄링에 관한 한 가지 해결 방법은 마스터 서버(master server)라는 하나의 처리기가 모든 스케줄링 결정과 I/O 처리 그리고 다른 시스템의 활동을 취급하게 하는 것입니다.
마스터 서버가 아닌 처리기들은 다만 사용자 코드만을 수행합니다.
이러한 비대칭 다중 처리(asymmetric multiprocessing)는 오직 하나의 코어만 시스템 자료구조에 접근하여 자료 공유의 필요성을 배제하기 때문에 간단합니다.
이 접근 방식의 단점은 마스터 서버가 전체 시스템 성능을 저하시킬 수 있는 병목이 된다는 것입니다.
다중 처리기를 지원하기 위한 표준 접근 방식은 대칭 다중 처리(symmetric multiprocessing, SMP)이며 각 프로세서는 스스로 스케줄링 할 수 있습니다.
각 프로세서의 스케줄러가 준비 큐를 검사하고 실행할 스레드를 선택하여 스케줄링이 진행됩니다. 이는 스케줄 대상이 되는 스레드를 관리하기 위한 두 가지 가능한 전략이 제공합니다.
- 모든 스레드가 공통 준비 큐에 있을 수 있습니다.
- 각 프로세서는 자신만의 스레드 큐를 가질 수 있습니다.
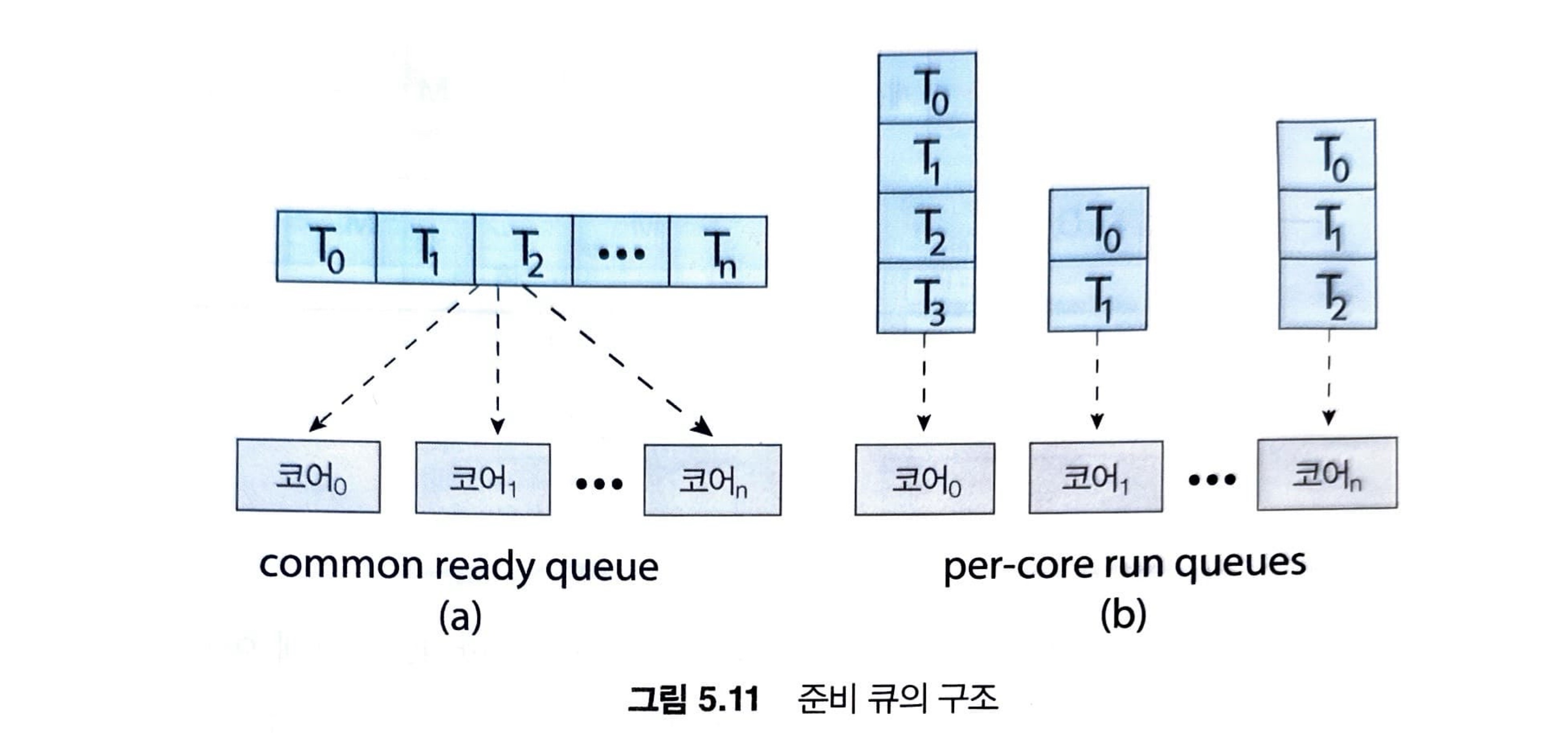
첫 번째 옵션을 선택하면 공유 준비 큐에 race condition이 생길 수 있으므로 두 개의 다른 프로세서가 동일한 스레드를 스케줄 하지 않도록 그리고 큐에서 스레드가 없어지지 않도록 보장해야 합니다.
이것을 위해서 락킹 기법의 하나를 사용할 수 있으나 큐에 대한 모든 액세스는 락 소유권이 필요하므로 락킹은 매우 경쟁이 심할 것이고 공유 큐 액세스는 성능의 병목이 될 수 있습니다.
두번째 옵션은 각 프로세서가 자신만의 실행 큐에서 스레드를 스케줄 할 수 있도록 허용하므로 공유 실행 큐와 관련되어 발생할 수 있는 성능 문제를 겪지 않습니다.
따라서 SMP를 지원하는 시스템에서 가장 일반적인 접근 방식입니다.
또한 자신만의 프로세스별 큐가 있으면 캐시 메모리를 보다 효율적으로 사용할 수 있습니다.
프로세스별 실행 큐마다 부하의 양이 다를 수 있지만 나중에 살펴볼 균형 알고리즘을 사용하여 모든 프로세서 간에 부하를 균등하게 만들 수 있습니다.
5.2 다중 코어 프로세서
SMP 시스템은 다수의 물리 처리기를 제공함으로써 다수의 프로세스가 병렬로 실행되게 합니다.
그러나 현대 컴퓨터 하드웨어는 동일한 물리적 칩 안에 여러 개의 처리 코어를 장착하여 다중 코어 프로세서(multicore processor)가 됩니다.
각 코어는 구조적인 상태를 유지하고 있어서 운영체제 입장에서는 개별적인 논리적 CPU처럼 보이게 됩니다.
다중 코어 프로세서를 사용하는 SMP 시스템은 각 CPU가 자신의 물리 칩을 가지는 시스템과 비교해 속도가 빠르고 적은 전력을 소모합니다.
다중 코어 프로세서는 스케줄링 문제를 복잡하게 합니다. 여러 개의 코어를 사용해서 스레드를 병렬로 실행시키려고 하는 것일 뿐인데 왜 그런 것일까? 살펴봅시다.
CPU의 처리속도와 메모리 접근 속도는 차이가 있습니다. 최신 프로세서가 메모리보다 훨씬 빠른 속도고 작동하기 때문에 많은 시간 허비가 발생한다는 의미입니다.
이러한 상황을 우리는 메모리 스톨(memory stall)이라고 합니다.
그리고 이러한 상황은 캐시 미스로 인해도 발생할 수 있습니다.
이러한 상황을 해결하기 위해 최근의 많은 하드웨어 설계는 다중 스레드 처리 코어를 구현하였습니다. 이러한 설계는 하나의 코어에 2개 이상의 하드웨어 스레드가 할당됩니다.
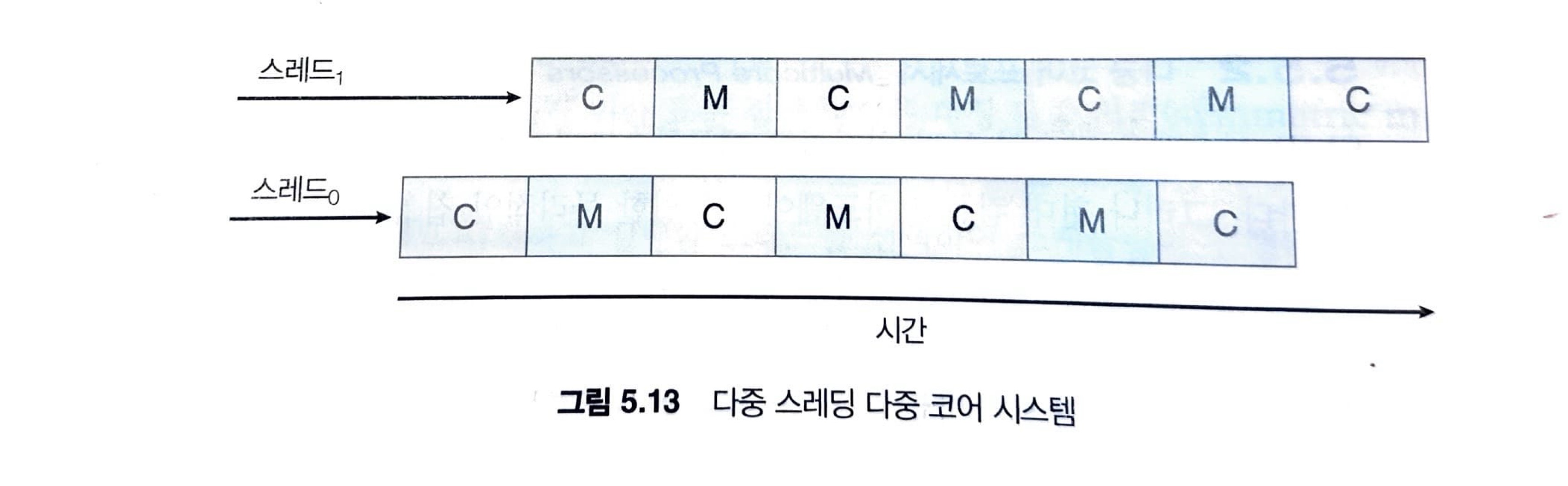
해당 그림을 보면 이중 스레드 처릴 코어를 보이고 이 코어에서 스레드 0과 스레드 1의 실행이 인터리브 되는 모습을 보입니다.
운영체제 관점에서 각 하등웨어 스레드는 명령어 포인터 및 레지스터 집합과 같은 구조적 상태를 유지하므로 소프트웨어 스레드를 실행시킬 수 있는 논리적 CPU로 보입니다. 칩 다중 스레딩(Chip MultiThreading, CMT)으로 알려진 이 기술은 아래 그림과 같습니다.
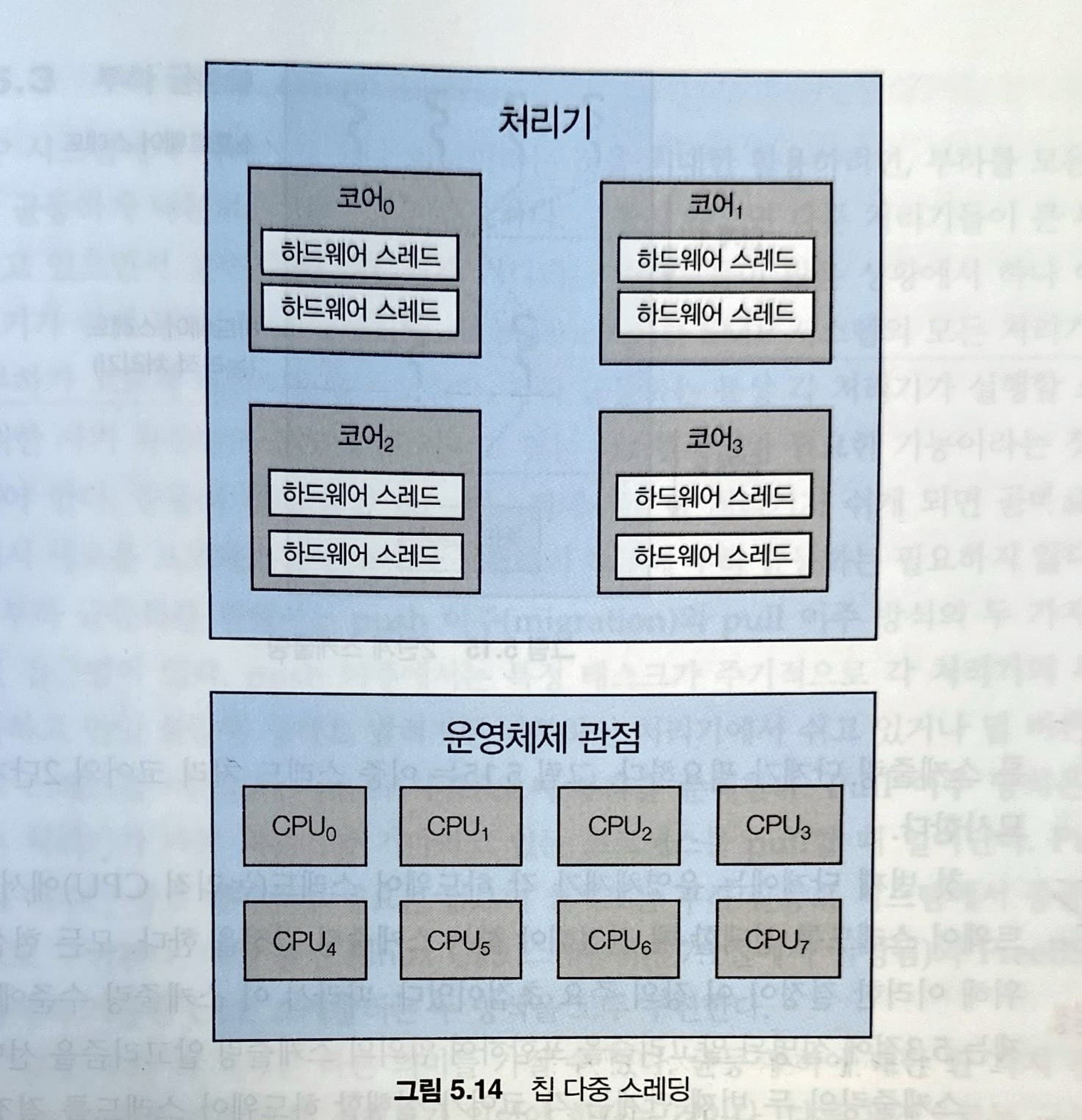
Intel 프로세서는 이러한 방식을 설명하기 위하여 하이퍼 스레딩[동시 다중 스레딩(simultaneouse multithreading) 또는 SMT라고도 함]이라는 용어를 사용합니다.
처리기를 다중 스레드화 하는 데에는 두 가지 방법이 있습니다.
- 거친(Coarse-grained) 다중 스레딩
- 세밀한(Fine-grained) 다중 스레딩
이 두 가지의 스레드 교체 방식에 대해서 정리를 해봅시다.
- 거친 방식(Coarse-Grained Switching)
- 거친 방식에서는 긴 지연 시간(예: memory stall)이 발생했을 때 다른 스레드로 교체합니다.
- 이 경우, 명령어 파이프라인을 비우고 다른 스레드의 상태를 파이프라인에 로드하는 과정이 필요합니다. 이로 인해 상당한 오버헤드가 발생할 수 있습니다.
- 파이프라인을 비우는 것은 현재 수행 중인 스레드의 명령어를 모두 제거하고 새로운 스레드의 명령어를 파이프라인에 채우는 것을 의미합니다.
- 세밀한 방식(Fine-Grained Switching)
- 세밀한 방식은 명령어 주기의 경계에서 보다 정밀하게 스레드 교환을 수행합니다.
- 이 방식에서는 명령어 파이프라인을 비우지 않고, 스레드 간에 교체를 수행할 수 있는 특별한 하드웨어 회로가 포함됩니다.
- "세밀한 정밀도"는 스레드 교환을 더 자주 하고 더 빠르게 할 수 있다는 것을 의미합니다. 이는 파이프라인에 덜 파괴적인 방식으로 스레드를 교체할 수 있게 함으로써, 오버헤드를 줄입니다.
추가적으로 개념을 좀 더 안정성 있게 이해하기 위해서 다음도 정리를 해두겠습니다.
❗️ 하드웨어 스레드와 명령어 파이프라인
- 하나의 코어에서 SMT를 사용할 경우, 실제로는 여러 개의 논리적 스레드가 있지만, 기본적인 명령어 처리 파이프라인은 하나입니다.
- 이 파이프라인은 여러 개의 논리적 스레드 간에 공유됩니다. 따라서, 스레드 간의 스위칭은 파이프라인의 상태를 저장하고 복원하는 복잡한 작업을 포함합니다.
❗️ 상태 정보 저장
- 각 스레드의 상태 정보(레지스터 상태, 프로그램 카운터 등)는 코어 내의 별도의 저장 영역에 유지됩니다.
- 스레드 교환 시 이 정보를 활용하여 현재 스레드의 상태를 저장하고 새로운 스레드의 상태를 복원합니다.
- 이러한 방식은 메모리 스톨과 같은 대기 시간을 효율적으로 활용할 수 있게 해줍니다.
❗️ 메모리 접근과 CPU 사용
- 메모리에 접근하는 작업 또한 CPU의 자원을 필요로 합니다. 하지만 이 과정에서 모든 CPU의 자원이 활용되는 것이 아닌 메모리 컨트롤러와 같은 자원이 요구됩니다.
- ALU, 레지스터 집합 등과 같은 자원들은 해당 작업에서 필요로 하지 않기 때문에 이것을 다른 스레드에게 넘겨줘서 실행할 수 있도록 하는 것이 SMT 방식입니다.
- 결국, SMT는 정확히 말하자면 하나의 스레드 동작을 중지하는 것이 아닌 동시에 실행할 수 있도록 자원을 적절하게 분배하는 기술입니다.
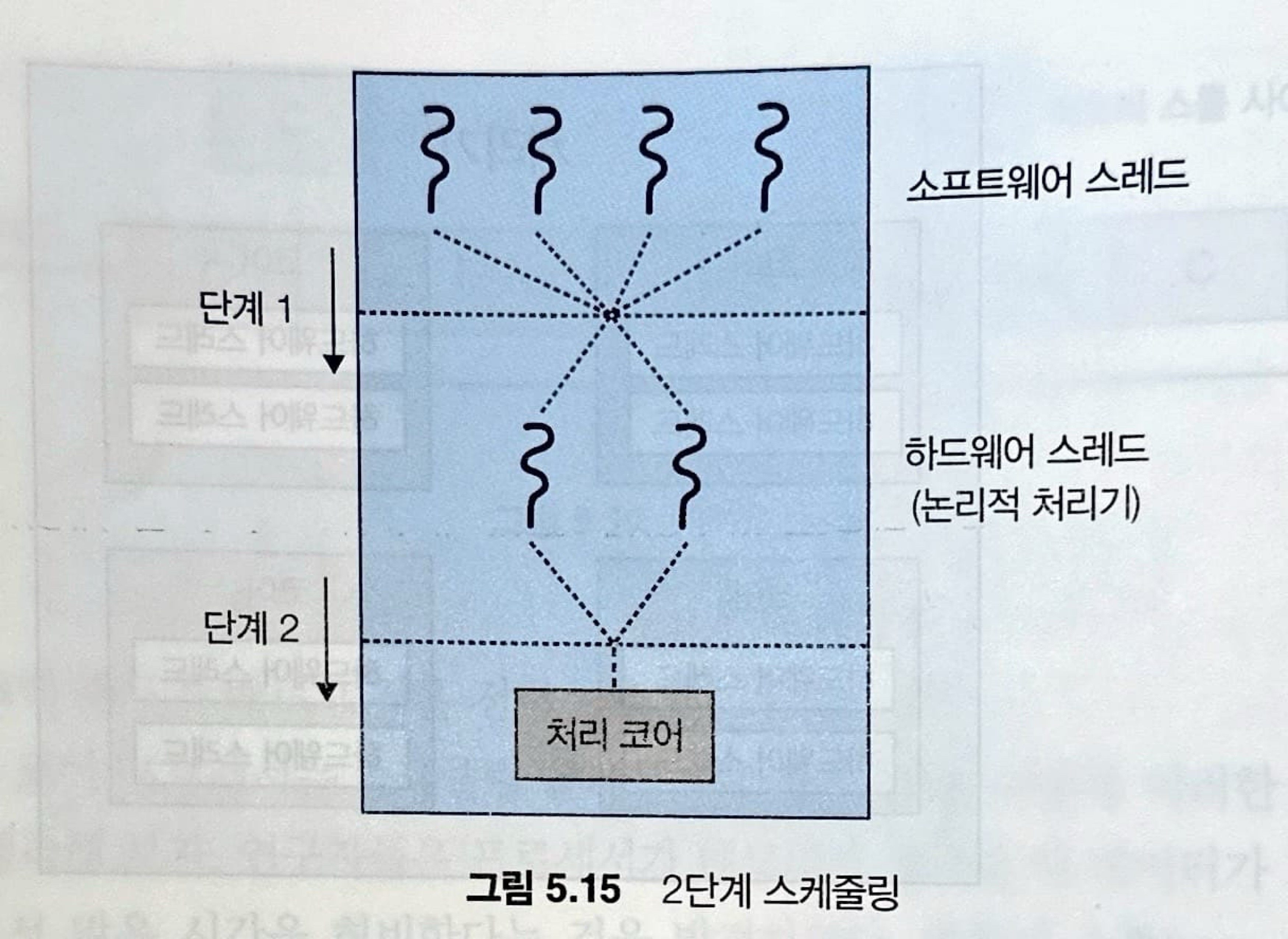
해당 그림은 이중 스레드 처리 코어의 2단계 스케줄링을 묘사하고 있습니다.
첫 번째 단계에는 운영체제가 각 하드웨어 스레드(논리적 CPU)에서 실행할 소프트웨어 스레드를 선택할 때 결정해야 하는 스케줄링 결정을 합니다.
스케줄링의 두 번째 단계는 각 코어가 실행할 하드웨어 스레드를 결정하는 방법을 명시합니다. 이 상황에서 채택할 수 있는 몇 가지 전략이 있습니다.
여기서는 다음 두 가지를 확인해 봅시다.
- 라운드 로빈 방식(Round Robin, RR)
- 동적 긴급도(urgency value)
라운드 로빈 알고리즘을 사용하여 처리 코어에 하드웨어 스레드를 결정하는 방법은 UltraSPARC T3에 의해 채택된 접근법입니다.
코어당 2개의 하드웨어-관리 스레드를 가진 이중 코어 프로세서인 Intel Itanium에서 채택한 방식인 동적 긴급도는 각 하드웨어에 0부터 7까지의 긴급도를 매기며 긴급도를 비교하여 높은 긴급도를 가진 스레드를 선택하여 처리 코어에서 실행합니다.
그림과 같이 서로 다른 두 가지 스케줄링 단계가 반드시 상호 배타적일 필요는 없고, 사실 운영체제 스케줄러(첫 번째 단계)가 프로세서 자원 공유를 인식하면 보다 효과적인 스케줄링 결정을 내릴 수 있습니다.
이것이 무슨말인가 하면 두개의 소프트웨어 스레드가 실행 중이라고 했을 때 이것은 동일한 코어 또는 서로 다른 코어에서 실행될 수 있습니다. 만약, 이것을 동일한 코어의 두 하드웨어 스레드에 각각 할당한다면 프로세서 자원을 공유해야 하므로 서로 다른 코어에서 스케줄 될 때보다 더 느리게 진행될 수 있습니다.
만약, 이 두 스레드가 하나의 프로세스에서 동작하는 서로 다른 스레드이고 공유 메모리를 많이 사용한다고 가정하면 서로 다른 코어에 배치하는 것보다 같은 코어에 배치하는 것이 더 나을 수 있습니다. 가장 근접해 있는 캐시를 효과적으로 사용할 수 있을테니깐요.
결국 이러한 여러가지 요인을 고려하여 결정해야 합니다.
⚡️ 스레드 스케줄링 최적화 ⚡️
이것은 뒤에서 부하 분산을 위해서 코어 그룹에 대한 개념이 나오면 설명이 나오겠지만 여기서도 적어놓고 가겠습니다.
자원 공유 인식의 중요성
- 리소스 공유: 멀티코어 프로세서에서는 여러 코어가 동일한 메모리, 캐시 등의 자원을 공유할 수 있습니다. 이러한 공유 자원의 효율적 사용은 시스템 전반의 성능에 큰 영향을 미칩니다.
- 캐시 공유: 같은 프로세스 내의 스레드들이 동일한 코어나 코어 그룹에 스케줄되면, L1 및 L2 캐시 같은 근접 캐시를 공유할 수 있습니다. 이는 메모리 접근 시간을 줄이고, 데이터 공유 효율을 높여 프로그램 실행 속도를 개선할 수 있습니다.
스케줄링 최적화
- 코어 분배 결정: 두 스레드가 상호작용을 많이 하거나 같은 데이터를 자주 접근하는 경우, 동일한 코어 또는 코어 그룹에 스케줄링 하는 것이 성능상 이점을 제공할 수 있습니다. 이는 캐시 일관성 오버헤드를 줄이고, 빠른 캐시 접근을 가능하게 합니다.
- 스케줄링 전략: 반면, 스레드가 서로 독립적인 작업을 수행하고 자원 경쟁이 덜한 경우, 서로 다른 코어에 스레드를 분산시켜 스케줄링하는 것이 좋을 수 있습니다. 이는 자원 경쟁을 줄이고, 병렬 처리 능력을 최대화할 수 있습니다.
5.3 부하 균등화
SMP 시스템에서 처리기가 하나 이상이라는 것을 최대한 활용하려면, 부하를 분산해주는 작업이 요구된다.
부하 균등화(load balancing)은 SMP 시스템의 모든 처리기 사이에 부하가 고르게 배분되도록 시도합니다.
부하 균등화는 공통 실행 큐가 아닌 자신의 실행 큐가 별도로 있는 경우에 고려해야 하는 기능입니다.
부하 균등화를 위해서는 두 가지 접근 법이 있습니다.
- push 이주(migration)
- pull 이주 방식
Push 이주에서는 특정 태스크가 존재하고 다음과 같은 동작을 수행합니다.
- 주기적으로 각 처리기의 부하 검사
- 불균형 상태를 확인시 부하 분배를 위해서 덜 바쁜 처리기로 스레드를 이동(또는 push)
Pull 이주 방식은 쉬고 있는 처리기가 바쁜 처리기를 기다리고 있는 프로세스를 pull할 때 일어납니다.
Push와 Pull 이주는 상호 배타적일 필요는 없으며 실제로는 부하 균등화 시스템에서 종종 병렬적으로 구현됩니다.
"균등 부하"라는 개념도 결국 기준이 무엇이냐에 따라 달라질 수 있다는 점을 기억하자.
5.4 처리기 선호도
스레드가 특정 처리기(첫번째 프로세서)에서 실행 중일 때 해당 스레드가 다른 처리기(두번째 프로세서)로 이주한다면 어떤일이 벌어지는가? 캐시 메모리 관점에서 살펴보자.
첫 번째 프로세서의 캐시 메모리 내용은 무효화 되어야 하며 두 번째 프로세서의 캐시는 다시 채워져야 합니다.
캐시 무효화 및 다시 채우는 비용이 많이 들기 때문에 SMP를 지원하는 대부분의 운영체제는 스레드를 한 프로세서에서 다른 프로세서로 이주시키지 않고 대신 같은 프로세서에서 계속 실행시키면서 warm cache를 이용하려고 합니다.
이를 프로세서 선호도라고 합니다.
즉, 프로세스는 현재 실행 중인 프로세서에 대한 선호도를 보입니다.
앞서 우리는 스레드의 큐를 구성하기 위한 두 가지 전략을 확인했습니다.
- 공통 준비 큐 방식
- 자신만의 스레드 큐 방식
공통 준비 큐 방식을 채택하면 선택된 스레드는 어느 처리기에서건 실행될 수 있습니다. 따라서 스레드가 새 프로세서에 스케줄 되면 해당 프로세서의 캐시를 다시 채워야 합니다.
만약 자신만의 스레드 큐 방식을 채택하면 스레드는 항상 동일한 프로세서에 스케줄 되므로 warm cache의 내용을 활용할 수 있습니다.
기본적으로 프로세서별 준비 큐는 프로세서 선호도를 무료로 제공하는 것입니다.
처리기 선호도는 여러 행태를 띱니다.
- 약한 선호도(soft affinity): 프로세스를 특정 처리기에서 실행시키려고 노력은 하지만 보장은 하지 않습니다.
- 강한 선호도(hard affinity):
System call을 통하여 프로세스는 자신이 실행될 처리기 집합을 명시할 수 있습니다.
약한 선호도의 경우, 운영체제가 동작하는 방식으로 프로세스를 특정 처리기에서 실행시키려고 노력은 하지만 프로세스가 처리기 사이에서 이주하는 것이 가능합니다.
강한 선호도의 경우 System call을 통하여 지원하는 형태로 보았을 때, 명시적으로 선언하여 사용하는 것으로 이 경우에는 특정 처리기만 사용하도록 지정하는 것입니다.
시스템의 메인 메모리 아키텍처는 프로세스 선호도 문제에도 영향을 줄 수 있습니다.
다음 그림을 확인하면, 각각 고유한 CPU와 로컬 메모리를 가진 두 개의 물리적 프로세서 칩이 있는 NUMA (non-uniform memory access)를 특징으로 하는 아키텍처를 확인할 수 있습니다.
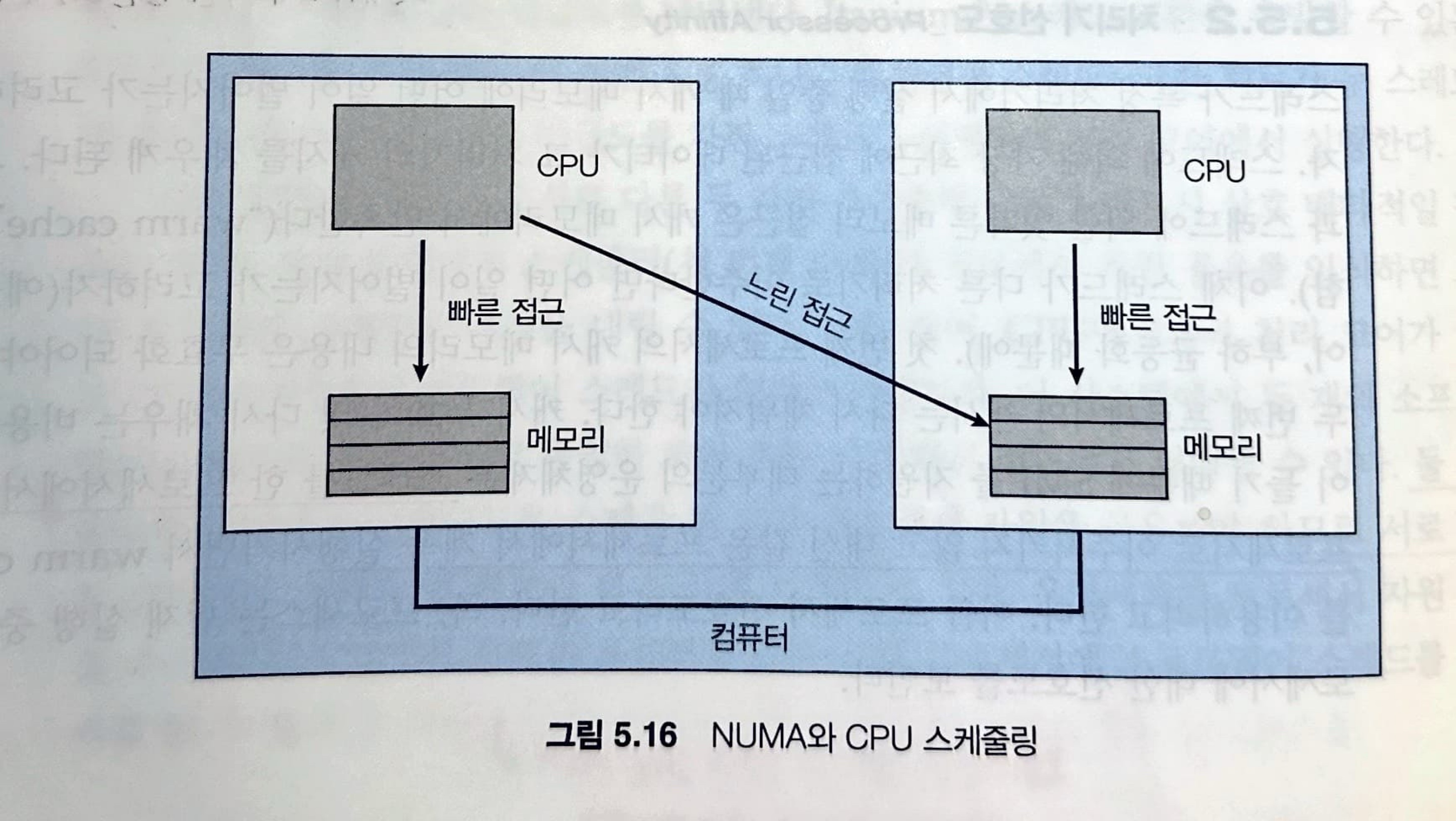
시스템 연결망을 통해 NUMA 시스템의 모든 CPU가 하나의 물리적 주소 공간을 공유할 수 있지만 CPU는 다른 CPU의 로컬 메모리보다 자신의 로컬 메모리에 더 빠르게 액세스 할 수 있습니다.
운영체제의 CPU 스케줄러 및 메모리 배치 알고리즘이 NUMA를 인식하고 협력하는 경우 특정 CPU에 스케줄 된 스레드를 CPU가 있는 위치에 가장 가까운 메모리에 할당하여 가능한 가장 빠른 메모리 액세스를 제공할 수 있습니다.
결국 위에서도 봤지만, 부하 균등 작업을 하기 위해서 "스레드 이전" 작업을 수행하면 NUMA 시스템에서 손해가 발생할 수 있으며, 이 경우 스레드는 더 긴 메모리 액세스 시간이 필요한 프로세서로 이동할 수 있는 것입니다.
뒤에서 이러한 상충하는 목표의 균형을 맞추는 방법에 대해서 살펴볼 것이다.
5.5 이기종 다중 처리
이기종 다중 처리(heterogeneous multiprocessing, HMP)은 모바일 시스템에서 사용하는 방식 중 하나로, 다중 코어 아키텍처를 사용하면서 일부 시스템은 동일한 명령어 집합을 실행하지만 전력 소비를 유휴 수준으로 조정하는 기능을 포함하여 클록 속도 및 전력 관리 측면에서 차이가 나는 코어를 사용하여 설계된 방식을 의미합니다.
간단하게 말하자면, 고성능의 코어를 가진 처리기(시스템)들은 기존대로 사용하면서 그것을 보조 하기 위한 저성능 시스템들을 같이 사용하는 것입니다.
HMP의 목적은 작업의 특정 요구에 따라 특정 코어에 작업을 할당하여 전력 소비를 더 잘 관리하는 것입니다.
이를 지원하는 ARM 프로세서의 경우 이 유형의 아키텍처를 big,LITTLE이라고 하며 고성능 big 코어가 에너지 효율적인 LITTLE 코어와 결합합니다.
Big 코어는 더 많은 에너지를 소비하므로 짧은 시간 동안만 사용해야 하며, Little 코어는 더 적은 에너지를 사용하므로 더 오랫동안 사용할 수 있습니다.
장점은 다음과 같습니다.
장점
- 고성능을 요구하지 않는 작업을 little 코어에 할당하여 배터리 충전을 보존할 수 있습니다.
- 더 많은 처리 능력이 필요하지만 짧은 기간 동안 실행될 수 있는 대화형 응용 프로그램을 big 코어에 할당할 수 있습니다.
- 절전 모드일 경우, big 코어를 비활성화 할 수 있습니다.
6. 실시간 CPU 스케줄링
실시간 운영체제는 CPU를 스케줄링 할 때 다음과 같이 시스템을 구분합니다.
- 연성(soft) 실시간 시스템
- 경성(hard) 실시간 시스템
연성 실시간 시스템은 중요한 실시간 프로세스가 스케줄 되는 시점에 관해 아무런 보장을 하지 않습니다. 연성 실시간 시스템은 오직 중요 프로세스가 그렇지 않은 프로세스에 비해 우선권을 가진다는 것만 보장합니다.
경성 실시간 시스템은 더 엄격한 요구 조건을 만족시켜야 합니다. 태스크는 반드시 마감시간까지 서비스를 받아야 하며 마감시간이 지난 이후에 서비스를 받는 것은 서비스를 전혀 받지 않는 것과 동일한 결과를 낳습니다.
즉, 조건이 만족되지 않은 서비스는 아무런 실행 결과를 가져오지 않습니다.
6.1 지연시간 최소화
실시간 시스템의 이벤트-중심의 특성을 생각해 보자.
시스템은 일반적으로 실시간으로 발생하는 이벤트를 기다립니다. 이벤트는 소프트웨어 적으로, 또는 하드웨어적으로 발생할 수 있습니다.
이벤트가 발생하면, 시스템은 가능한 빨리 그에 응답을 하고 그에 맞는 동작을 수행해야 합니다.
이벤트 지연시간은 이벤트가 발생해서 그에 맞는 서비스가 수행될 때까지의 시간을 말합니다.
두 가지 지연시간이 실시간 시스템의 성능을 좌우합니다.
- 인터럽트 지연시간
- 디스패치 지연시간
인터럽트 지연시간은 CPU에 인터럽트가 발생한 시점부터 해당 인터럽트 처리 루틴이 시작하기까지의 시간을 말한다.
여기서 주의할 점은 종료 시간을 인터럽트 처리 루틴이 시작하기까지의 시간을 말하는 것이고, 인터럽트가 끝나는 시간을 의미하는 것이 아니다.
인터럽트의 동작은 다음과 같이 동작합니다.
- 인터럽트가 발생 -> 인터럽트 종류 결정
- ISR을 사용하여 처리하기 전에 프로세스 상태 저장
이러한 작업을 모두 수행하는 데 걸리는 시간이 인터럽트 지연 시간입니다.
인터럽트 지연시간에 영향을 주는 요인 중 하나는 커널 데이터 구조체를 갱신하는 동안 인터럽트가 불능케 되는 시간이다. 실시간 운영체제는 이 시간을 매우 잛게 해야 합니다.
디스패치 지연시간은 스케줄링 디스패처가 하나의 프로세스를 블록시키고 다른 프로세스를 시작하는 데까지 걸리는 시간을 말합니다.
실시간 운영체제는 이 지연시간도 최소화하는 것을 목표로 해야하고 가장 효과적인 방법은 선점형 커널입니다.
6.2 우선순위 기반 스케줄링
실시간 운영체제에서 가장 중요한 기능은 실시간 프로세스에 CPU가 필요할 때 바로 응답을 해주는 것입니다.
이를 위해서 우선순위 기반의 스케줄링 알고리즘은 각각의 프로세스의 중요성에 따라서 그 우선순위를 부여합니다. 또한 스케줄러가 선점 기법을 제공한다면, 현재 CPU를 이용하고 있는 프로세스가 더 높은 우선순위를 갖는 프로세스에 선점될 수 있습니다.
선점 및 우선순위 기반의 스케줄러가 제공하는 것은 단지 연성 실시간 기능을 제공하는 것에 불과합니다. 실제로 마감시간을 지키지 못한다고 해당 프로세스의 실행을 무효화 시키지는 않습니다.
경성 실시간 시스템에서는 실시간 태스크가 마감시간 내에 확실히 수행되는 것을 보장해야만 하며, 그렇기 때문에 부가적인 스케줄링 기법이 필요합니다.
해당 스케줄링 기법은 뒤에서 다루니깐 지금은 왜 필요한지만 인지하고 넘어가면 된다.
개별 스케줄러에 대해서 알아보기 전에 스케줄 될 특성들의 특성을 정의하고 가자.
- 주기적: 주기 태스크의 실행 빈도는
1/p입니다. - 스케줄러는 이들 주기, 마감시간, 수행 시간 사이의 관계를 이용하여 마감시간과 주기적 프로세스의 실행 빈도에 따라서 우선순위를 결정
- 승인 제어(admission-control) 알고리즘을 이용해서 스케줄러는 이미 완수할 수 있는 프로세스를 허락, 그렇지 못한 경우에는 요구를 거절
6.3 Rate-Monotonic 스케줄링
Rate-monotonic 스케줄링 알고리즘은 선점 가능한 정적 우선순위 정책을 이용하여 주기 태스크들을 스케줄 합니다.
각각의 주기 태스크들은 시스템에 진입하게 되면 주기에 따라서 우선순위가 정해집니다.
- 높은 우선순위 -> 주기가 짧은 태스크
- 낮은 우선순위 -> 주기가 긴 태스크
이 정책은 CPU를 더 자주 필요로 하는 태스크에 더 높은 우선순위를 주려는 원리에 기반을 두고 있습니다.
더욱이, rate-monotonic 스케줄링은 주기 프로세스들의 처리 시간은 각각의 CPU 버스트(burst)와 같다고 가정합니다. 즉, 프로세스가 CPU를 차지한 시간은 각각의 CPU 버스트 시간과 같습니다.
먼저, Rate-Monotonic 스케줄링 기법을 살펴보기 전에 우선순위 기반 스케줄링을 사용했을 때 생길 수 있는 문제에 대해서 살펴봅시다.
만약 두개의 프로세스 P1, P2가 있다고 할 때, 다음의 표와 같이 되어 있다고 해보겠습니다.
| 프로세스 | 주기 | 수행시간 |
|---|---|---|
| P1 | 50 | 20 |
| P2 | 100 | 35 |
각 프로세스의 마감시간은 다음 주기가 시작하기 전까지입니다.
먼저 두 프로세스가 모두 마감시간을 충족시키도록 스케줄링 가능한지 생각해 봐야합니다.
각 프로세스의 CPU 이용률, 즉 주기에 대한 수행시간 t/p를 구해보면
- P1의 CPU 이용률: = =
- P2의 CPU 이용률: = =
총 CPU 이용률은 75%가 됩니다.
따라서 두 프로세스 모두 마감시간을 충족시키고도 여유시간이 있을 것으로 보입니다.
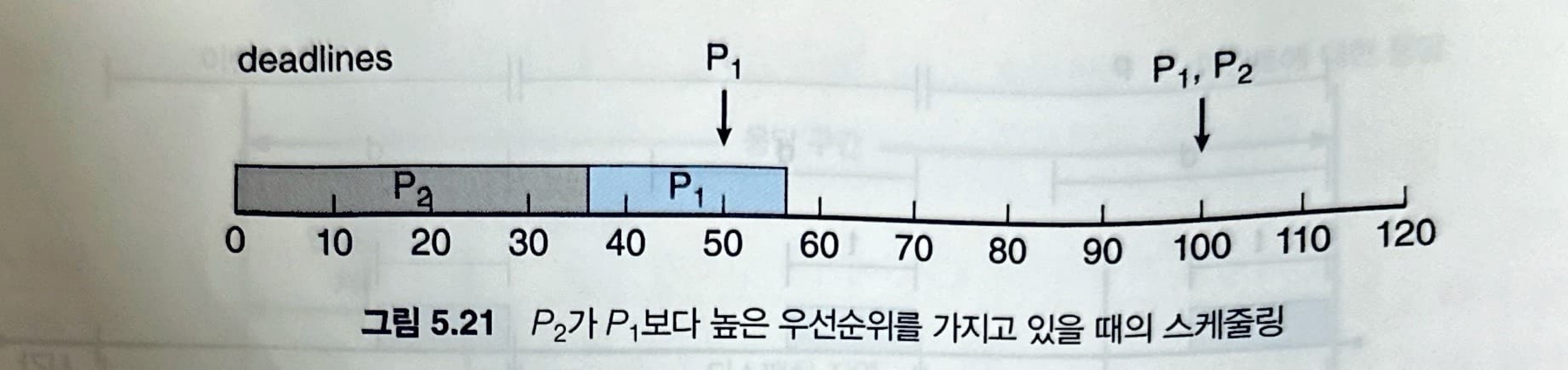
P2의 우선순위가 P1보다 높다고 가정해봅시다. 해당 상황의 수행 모습이 위의 그림인데, 여기서 보면 P1의 마감시간을 충족시키지 못한 것을 확인할 수 있습니다.
Rate-monotonic 스케줄링을 사용하면, P1의 주기가 P2보다 짧기 때문에 P1의 우선순위가 P2의 우선순위보다 높습니다. 이 스케줄링을 사용할 때의 수행 모습은 아래 그림과 같습니다.

Rate-monotonic 스케줄링 기법이 스케줄 할 수 없는 프로세스 집합의 경우 다른 방식의 정적 우선순위를 이용하는 알고리즘도 스케줄 할 수 없다는 측면에서 봤을 때 최적(optimal)이라고 할 수 있습니다.
스케줄 할 수 없는 프로세스 집합의 예시는 다음과 같습니다.
| 프로세스 | 주기 | 수행 시간 |
|---|---|---|
| P1 | 50 | 25 |
| P2 | 80 | 35 |
이 경우에 두 프로세스의 전체 CPU 이용률을 계산해 보면 로, CPU에 6%의 여유를 가지고 모두 스케줄 할 수 있을 것으로 보입니다.
하지만 실제로 동작했을 때 결과는 아래와 같습니다.

Rate-Monotonic 스케줄링 기법은 최적이기는 하지만 많은 제약이 있습니다. CPU 이용률은 한계가 있기 때문에 CPU 자원을 최대화해서 사용하는 것은 불가능합니다.
N개의 프로세스를 스케줄 하는 데 있어 최악의 경우 CPU 이용률은
입니다. 시스템에 한 개의 프로세스만 존재한다면 CPU 이용률은 100%입니다.
그러나 프로세스가 증가함에 따라 69%까지 떨어지고, 두개의 프로세스가 존재할 경우 CPU 이용률은 양 83%가 한계입니다.
따라서 위의 스케줄 할 수 없는 프로세스 집합의 경우 94%에 CPU 이용률이 근접했기 때문에 두 프로세스가 마감시간을 만족시킬지를 보장할 수 없습니다.
6.4 Earliest-Deadline-First 스케줄링
Earliest-Deadline-First(EDF) 스케줄링 기법은 마감시간에 따라서 우선순위를 동적으로 부여합니다.
- 높은 우선순위 -> 마감시간이 빠른 경우
- 낮은 우선순위 -> 마감시간이 늦을 경우
EDF 정책에서는, 프로세스가 실행 가능하게 되면 자신의 마감시간을 시스템에 알려야 합니다.
우선순위는 새로 실행 가능하게 된 프로세스 마감시간에 맞춰서 다시 조정됩니다.
바로 이러한 점이 우선순위가 고정되어 있는 rate-monotonic 스케줄링 기법과 다른 점입니다.
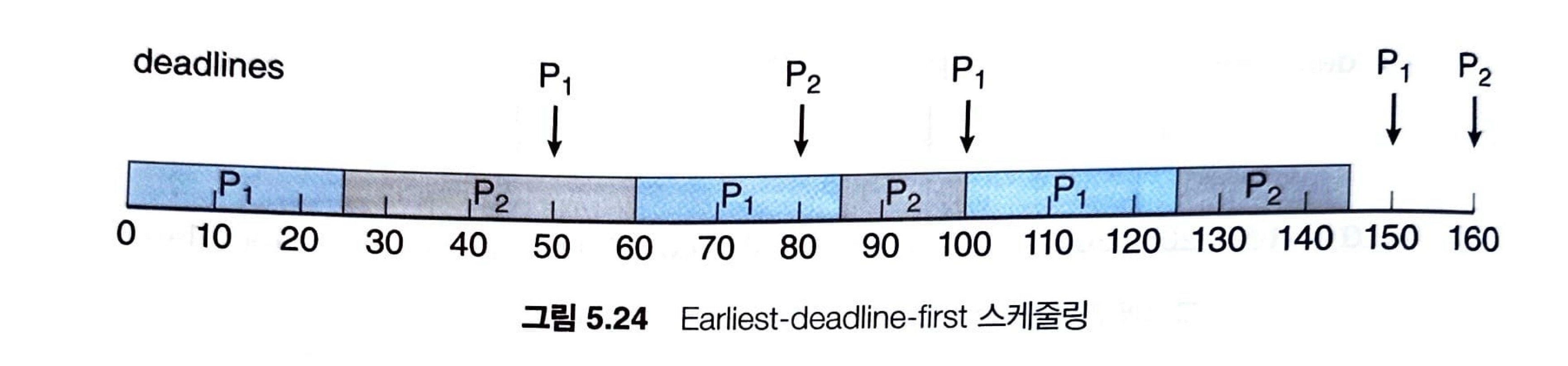
앞서, rate-monotonic 스케줄링 기법에서 마감시간을 지키지 못했던 케이스를 다시 가져와 봅시다.
| 프로세스 | 주기 | 수행 시간 |
|---|---|---|
| P1 | 50 | 25 |
| P2 | 80 | 35 |
여기서 하나의 동작만 확인하면 전부 이해할 수 있는데, P1의 첫 번째 주기가 끝나느 50을 한번 확인해보자.
50이 된 시점에 주기가 종료되고 다시 조정을 해야되는데 P1의 마감 시간은 25일 것이고, P2는 현재 25가 진행된 상황이라 마감 시간이 10일 것입니다.
따라서, 앞서 봤던 rate-monotonic 스케줄링 기법과는 다르게 P2가 계속해서 선점해서 사용하여 수행을 마무리하는 것을 확인할 수 있습니다.
이와 같은 방식으로 동작하면서 해당 프로세스 집합은 마감시간을 만족하게 됩니다.
EDF 스케줄링 알고리즘은 rate-monotonic과 이와 같은 차이점을 가지고 있습니다.
- 프로세스들이 주기적일 필요가 없습니다.
- CPU 할당 시간도 상수 값으로 정해질 필요가 없습니다.
- 그러나 자신의 마감시간을 스케줄러에게 알려주어야 합니다.
EDF가 매력적인 이유가 이론적으로 최적이라서 그렇습니다. 이론적으로, 모든 프로세스가 마감시간을 만족시키도록 스케줄 할 수 있고, CPU 이용률 역시 100%가 될 수 있습니다. 그러나 실제로는 프로세스 사이, 또는 인터럽트 핸들링 때의 문맥 교환 비용 때문에 100%의 CPU 이용률은 불가능합니다.
6.5 일정 비율의 몫 스케줄링
일정 비율의 몫(proportional share) 스케줄러는 모든 응용들에 T 개의 시간 몫을 할당하여 동작합니다.
이것은 매우 간단합니다.
한 개의 응용이 N 개의 시간 몫을 할당받으면 그 응용은 모든 프로세스 시간 중 N/T 시간을 할당받게 됩니다.
예를 들어서, T = 100인 시간 몫이 있다고 할 때, 3개의 프로세스 A, B, C에 각각 50 몫, 15 몫, 20 몫을 할당했다고 가정해봅시다.
해당 기법은 A가 모든 처리기 시간의 50%를, B가 15%를, C가 20%를 할당받는 것입니다.
이후 POSIX를 사용하여 실시간 스케줄링 예시 코드를 설명하는 부분이 나오는데 넘어가겠습니다.
7. 운영체제 사례들
여기서는 Solaris와 Windows 시스템의 경우의 커널 스레드 스케줄링에 관해 설명하고, Linux 스케줄러의 경우에는 태스크 스케줄링에 관해 설명할 것입니다.
7.1 사례: Linux 스케줄링
Linux의 프로세스 스케줄리은 버전 2.5전까지는 전통적인 UNIX 스케줄링 알고리즘의 변형을 사용했습니다.
하지만 이 알고리즘은 SMP 시스템을 염두에 두고 설계되지 않았기 때문에 다중 처리기 시스템을 충분히 지원하지 않습니다.
버전 2.5에서 이 스케줄러는 시스템에 존재하는 태스크 개수와 상관없이 항상 상수 시간에 실행되는 O(1)이라고 알려진 스케줄링 알고리즘이 포함되었습니다.
이 새로운 스케줄러는 또한 처리기 진화 정책과 처리기 사이에 부하를 균등하게 하는 기능 등 SMP를 위한 향상된 지원을 제공합니다.
실제 운용 면에서 O(1) 스케줄러는 SMP 시스템에서 출중한 성능을 보이지만 대화형 프로세스에 대해서는 느린 응답을 보입니다.
2.6 커널을 개발하는 동안 스케줄러는 다시 개선되었고, 2.6.23 커널로부터는 완전 공평 스케줄러(Completely Fair Scheduler, CFS)가 Linux 시스템의 디폴트 스케줄링 알고리즘이 되었습니다.
윗 내용은 제가 몇 번씩 읽어보고 싶은 용으로 작성한 것이고 핵심은 Linux 커널은 스케줄링 알고리즘을 CFS를 선택했다는 것입니다.
설명을 이어나가가기 전에 CFS에 대해서 정리하고 가야될 것 같습니다.
⚡️ 완전 공평 스케줄러(Completely Fair Scheduler, DFS) ⚡️
완전 공평 스케줄러는 이전에 널리 사용하던 O(1) 스케줄러와 다른 시간 공유 스케줄링 알고리즘을 대체하기 위해 설계되었습니다. CFS의 목표는 모든 프로세스에 가능한 한 '공평하게' CPU 시간을 할당하는 것입니다.
CFS의 동작 원리
CFS는 '가상 런타임'(vruntime)이라는 개념을 사용하여 프로세스에 CPU 시간을 할당합니다. 각 프로세스의 vruntime은 프로세스가 CPU에서 실행된 총 시간을 나타냅니다. CFS는
vruntime이 가장 작은 프로세스를 선택하여 CPU 시간을 할당함으로써, 모든 프로세스가 공평하게 CPU 시간을 사용할 수 있도록 합니다.주요 특징 및 매커니즘
가상 런타임(vruntime): 프로세스의 CPU 사용 시간을 공평하게 추적하기 위한 매커니즘입니다. vruntime은 프로세스가 CPU에서 실행된 시간을 나타내며, 단위는 나노초(ns)입니다.
Red-Black Tree: CFS는 레드-블랙 트리 자료 구조를 사용하여 실행 중인 프로세스를 관리합니다. 이 트리는 vruntime을 기준으로 정렬되어 있으며, CFS는 이 트리에서 가장 낮은 vruntime을 가진 노드(프로세스)를 선택하여 CPU를 할당합니다.
슬라이스 시간: CFS는 각 프로세스에 할당된 시간(슬라이스)를 선택하여 CPU를 할당합니다. 이 슬라이스는 시스템의 부하와 실행 대기 중인 프로세스의 수에 따라 변화하며, 모든 프로세스가 비슷한 양의 CPU 시간을 받도록 조정합니다.
단순성과 공평성: CFS의 설계는 단순성과 공평성에 중점을 둡니다. CFS는 프로세스의 우선순위나 종류에 관계없이 공평한 CPU 시간 할당을 목표로 하며, 실시간 스케줄링 요구 사항을 충족시키기 위한 매커니즘도 제공합니다.
동작 과정 예시
- 시스템에 여러 프로세스가 실행 대기 상태에 있습니다.
- CFS는 Red-Black Tree에서 vruntime이 가장 낮은 프로세스를 선택합니다.
- 선택된 프로세스는 할당된 시간동안 CPU에서 실행됩니다.
- 실행 후, 프로세스의 vruntime은 업데이트되고, 프로세스는 다시 레드-블랙 트리에 삽입됩니다.
- 다음 스케줄링 사이클에서는 업데이트된 vruntime을 바탕으로 새로운 프로세스가 선택됩니다.
계속해서 Linux 스케줄러에 대한 설명을 이어나가겠습니다.
Linux 스케줄러는 각 클래스별로 특정 우선순위를 부여받는 스케줄링 클래스에 기반을 두고 동작합니다.
다른 스케줄링 클래스를 사용하여 시스템과 프로세스 요구 조건에 따라 커널은 다른 스케줄링 알고리즘을 수용할 수 있습니다.
여기서도 스케줄링 클래스에 대해서 정리하고 진행하도록 하겠습니다.
⚡️ 스케줄링 클래스 ⚡️
Linux 커널의 스케줄링 시스템은 다양한 스케줄링 요구사항과 우선순위를 충족시키기 위해 여러 스케줄링 클래스를 사용합니다. 이러한 스케줄링 클래스는 각기 다른 우선순위와 스케줄링 알고리즘을 가지며, 시스템의 다양한 작업 유형에 맞게 설계되었습니다.
Linux 커널은 주로 다음과 같은 스케줄링 클래스를 제공합니다.
- CFS(Compeletly Fair Scheduler): 기본 스케줄링 클래스로, 대부분의 일반 프로세스에 사용됩니다.
- Real-Time Scheduler: 리얼타임 스케줄링 클래스는 시스템의 리얼타임 작업을 위해 설계되었습니다. 이 클래스는 FIFO, RR의 두 가지 스케줄링 정책을 제공합니다. 리얼타임 프로세스는 일반 프로세스보다 높은 우선순위를 가지며, 시간 제약 조건을 만족시키는 것이 중요합니다.
- Idle Scheduler Class: 시스템이 유후 상태일 때 사용되는 스케줄링 클래스입니다. 이 클래스의 목적은 CPU 사용률을 최소화하고 에너지 효율을 높이는 것입니다.
스케줄링 클래스의 역할
각 스케줄링 클래스는 특정 유형의 작업에 최적화된 스케줄링 알고리즘을 구현합니다. 이를 통해 Linux 커널은 다양한 프로세스 요구사항에 맞게 시스템 상황에 맞게 적절한 스케줄링 결정을 내릴 수 있습니다.
일단 앞에서 정리했던 내용을 조금만 간단하게 요약하자면,
결국 Linux는 버전의 진화되면서 CFS를 디폴트 스케줄링 알고리즘으로 선택하였으며, 요구 사항에 맞게 적절한 알고리즘을 적용할 수 있도록 스케줄링 클래스 기반으로 동작하는 것입니다.
마지막으로 CFS에 동작에 대해서 이해하려면 한 가지 개념을 더 정리해야 한다.
그것은 바로 목적 지연시간(targeted latency)입니다.
⚡️ 목적 지연시간(targeted latency)⚡️
의미:
- 목적 지연 시간은 시스템에 존재하는 모든 실행 가능한 태스크가 적어도 한 번씩 실행될 수 있는 이상적인 시간 간격을 의미합니다.
- 이는 각 태스크에 대한 CPU 시간 할당량의 합이 아니라, 시스템이 모든 태스크를 공평하게 처리할수 있는 "시간 창"을 나타냅니다.
계산:
- 목적 지연 시간은 시스템의 실행 가능한 태스크의 수에 따라 동적으로 조절됩니다. 시스템에 실행 가능한 태스크의 수가 적을 때는 latency가 짧아질 수 있으며, 태스크의 수가 많아지면 latency가 길어집니다. 이는 각 태스크가 공평한 CPU 접근 시간을 가질 수 있도록 조정하기 위함입니다.
- 목적 지연 시간의 디폴트 값과 최소값은 시스템 설정에 따라 정의됩니다. 이 값들은 시스템의 성능 요구 사항과 반응성에 따라 조정될 수 있습니다.
목적 지연 시간과 CPU 시간 할당
- CFS는 목적 지연 시간을 기준으로 각 태스크에 CPU 시간을 할당합니다. 태스크의 가상 런타임(vruntime)이 가장 낮은 태스크부터 CPU 시간을 할당받게 됩니다.
- 목적 지연 시간 내에 모든 태스크가 실행될 수 있도록 스케줄링함으로써, CFS는 시스템의 로드에 관계없이 태스크 간에 공평한 시간 분배를 보장합니다.
이제 책에서 설명하고 있는 CFS에 대해서 정리할 수 있습니다.
CFS 스케줄러는 상대 우선순위에 상응하는 시간 할댱량의 길이가 정해져 있는 경직된 규칙을 사용하지 않고 각 태스크에 CPU 처리시간의 비율을 할당합니다. 이 비율은 각 태스크에 할당된 nice 값에 기반을 두고 계산됩니다.
Nice 값은 -20부터 19까지의 범위를 가지며, 값이 적을수록 우선순위는 높아집니다.
CFS는 이산 값을 가지는 시간 할당량을 사용하지 않고 대신에 목적 지연시간(targeted latency)을 찾습니다. 목적 지연시간을 사용하여 태스크를 공평하게 스케줄링하고, 해당 latency를 사용함으로써 모든 태스크가 실행될 수 있도록 해줍니다.
CFS는 직접 우선순위를 할당하지 않고, 각 태스크 별로 vruntime이라는 변수에 태스크가 실행된 시간을 기록하여 가상 실행 시간을 유지합니다.
실행 시간은 태스크의 우선순위에 기반을 둔 감쇠 지수(decay factor)와 관련되어 있습니다.
예를 들어, nice 값이 0이라면 우선순위 태스크가 200ms 동안 실행되었을 때 vruntime 값도 200ms가 될 것입니다.
하지만 만약 nice값이 더 작아서 우선순위가 더 높다면 vruntime 값은 200ms보다 작을 것입니다.
Linux는 POSIX 표준을 사용하여 실시간 스케줄링을 구현합니다. SCHED_FIFO 또는 SCHED_RR 실시간 정책을 사용하여 스케줄 된 태스크는 보통의 태스크보다 높은 우선순위를 받고 실행됩니다.
아래의 그림은 Linux 시스템의 스케줄링 우선순위 구조를 보여줍니다.

CFS 스케줄러는 처리 코어간의 부하를 균등하게 유지하면서도 NUMA를 인식하고 스레드 이주를 최소화하는 정교화 기술을 사용하여 부하 균등화를 지원합니다.
CFS는 각 스레드의 부하를 다음 두 가지로 정의합니다.
- 스레드의 우선순위
- 평균 CPU 이용률
큐의 부하는 큐에 있는 모든 스레드의 부하 합계이며, 부하 균등화는 모든 큐의 부하가 거의 같도록 보장하면 됩니다.
하지만 앞서 스레드의 "이전 문제 중 하나"는 캐시 내용과 관련되어 있다고 했습니다.
자칫하면 캐시 내용을 무효화해야 하거나 NUMA 시스템에서 메모리 액세스 시간이 더 길어져 메모리 액세스 불이익이 발생할 수 있습니다.
이 문제를 해결하기 위해 Linux는 스케줄링 도메인의 계층적 시스템을 결정했습니다.
스케줄링 도메인(Domain)은 서로 부하 균형을 맞출 수 있는 CPU 코어의 집합입니다.
각 스케줄링 도메인의 코어는 시스템 자원을 공유하는 방법에 따라 그룹화됩니다.
아래 그림을 봐보자.
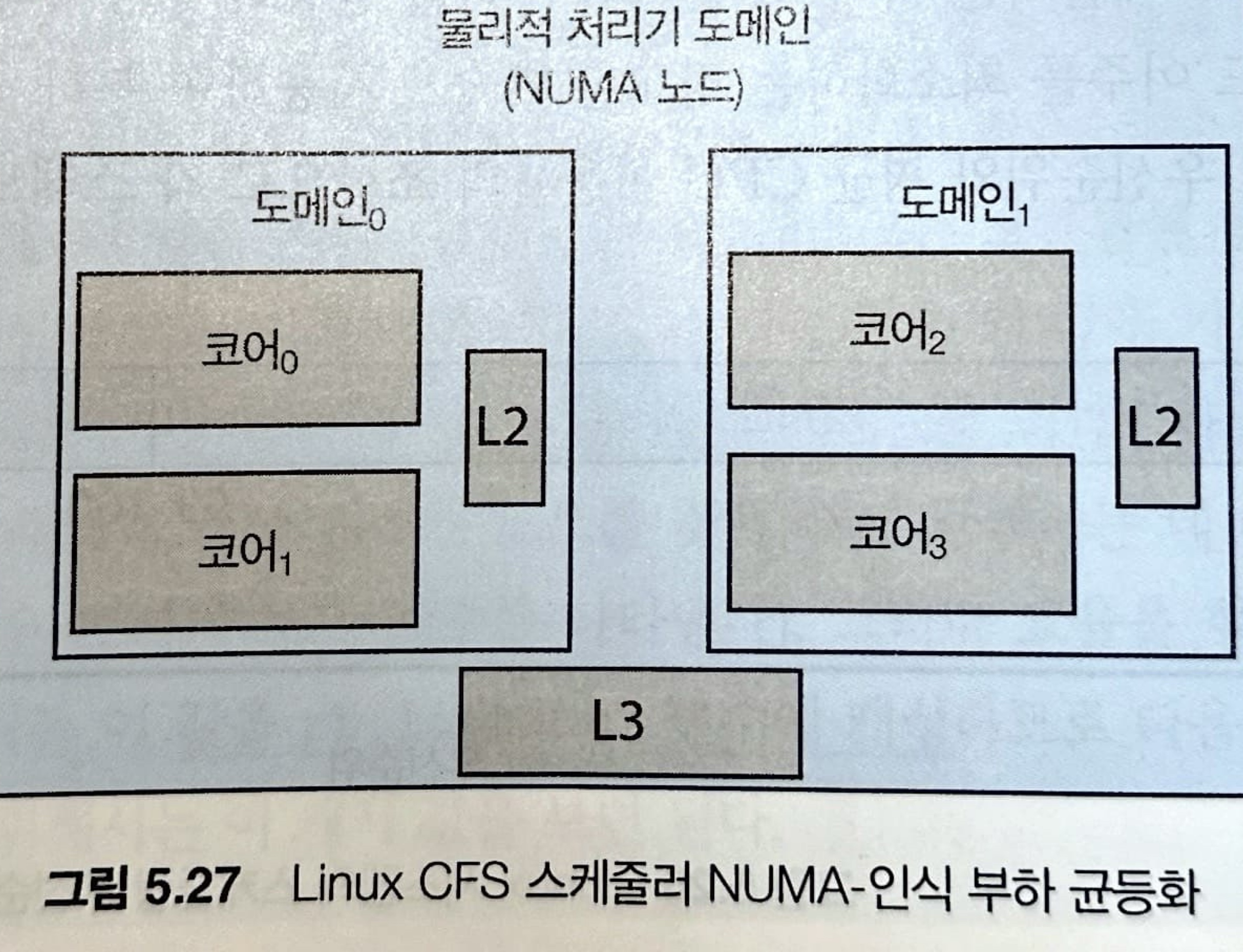
- 각 코어에는 자신만의 캐시가 있다 -> L1 캐시
- 한 쌍의 코어가 캐시를 공유하고 있다 -> L2 캐시
- 두 도메인은 캐시를 공유하고 있다 -> L3 캐시
여기서 두 도메인은 프로세서 수준 도메인(NUMA 노드)으로 구성되어 있는 것입니다.
CFS의 기본 전략은 가장 낮은 층부터 시작하여 도메인 안에서 부하의 균형을 맞추는 것입이다.
예를 들자면, 처음에는 스레드가 동일한 도메인의 코어 간에만 이주됩니다. 다음 수준의 부하 균등화는 도메인 사이에서 일어납니다.
만약 이것보다 더 멀리 이주해야 되는 경우(스레드가 로컬 메모리에서 더 멀리 이주해야 되는 경우), CFS는 다른 NUMA 노드 간에 스레드를 이주하는 것을 꺼립니다.
이러한 이주는 오직 심각한 부하 불균형이 있을 때만 일어납니다.
⚡️ 캐시 계층화 ⚡️
- L1 캐시: 하나의 코어를 위한 캐시
- L2 캐시: 스케줄링 도메인 내의 코어 그룹을 위한 캐시
- L3 캐시: 스케줄링 도메인 그룹을 위한 캐시
캐시를 계층화 구조로 사용하는 이유
- 데이터 우선순위에 따라 접근 속도 및 저장 용량간의 균형
- 여러 코어의 공통 캐시 영역
- 도메인 영역의 캐시 자원 공유
- CPU 부하 분산과 도메인 수준의 균형 조정
7.2 사례: Windows 스케줄링
Windows는 우선순위에 기반을 둔 선점 스케줄링 알고리즘을 사용합니다. Windows 스케줄러는 가장 높은 우선순위의 스레드가 항상 실행되도록 보장합니다.
Windows 커널 중 스케줄링을 담당하는 부분을 디스패처(dispatcher)라고 부릅니다.
선점이 필요한 경우에 실시간 스레드가 CPU를 액세스 할 수 있는 우선권을 줍니다.
디스패처는 스레드의 실행 순서를 정하기 위하여 32단계의 우선순위를 두고 있습니다.
우선순위는 두 클래스로 구분됩니다.
- 가변 클래스(variable class): 우선순위 1 ~ 15
- 실시간 클래스: 우선순위 15 ~ 31
또한 우선순위가 0인 스레드는 메모리 관리를 위해 사용됩니다.
디스패처는 각 우선순위를 위하여 큐를 사용하고 이들 큐를 높은 우선순위부터 낮은 우선순위까지 조사하면서 준비 상태의 스레드가 있는지를 봅니다.
준비 상태에 있는 스레드가 없으면 다스패처는 idle 스레드라고 불리는 특수한 스레드를 실행시킵니다.
Windows API는 프로세스들이 속할 수 있는 몇 가지 6 우선순위 클래스를 제공하며 아래와 같습니다.
IDLE PRIORITY CLASSBELOW NORMAL PRIORITY CLASSNORMAL PRIORITY CLASSABOVE NORMAL PRIORITY CLASSHIGH PRIORITY CLASSREALTIME PRIORITY CLASS
프로세스는 통상 NORMAL PRIORITY CLASS에 속합니다.
프로세스의 우선순위 클래스는 가변적으로 설정할 수 있지만, REALTIME PRIORITY CLASS는 바뀌지 않습니다.
우선순위 클래스의 스레드들 역시 상대적인 우선순위를 가집니다. 이 상대적인 우선순위를 위한 값은 아래와 같습니다.
IDLELOWESTBELOW NORMALABOVE NORMALHIGHESTTIME CRITICAL
이렇게 두 개의 우선순위를 사용하는 이유는 아래의 표를 보면 이해할 수 있습니다.
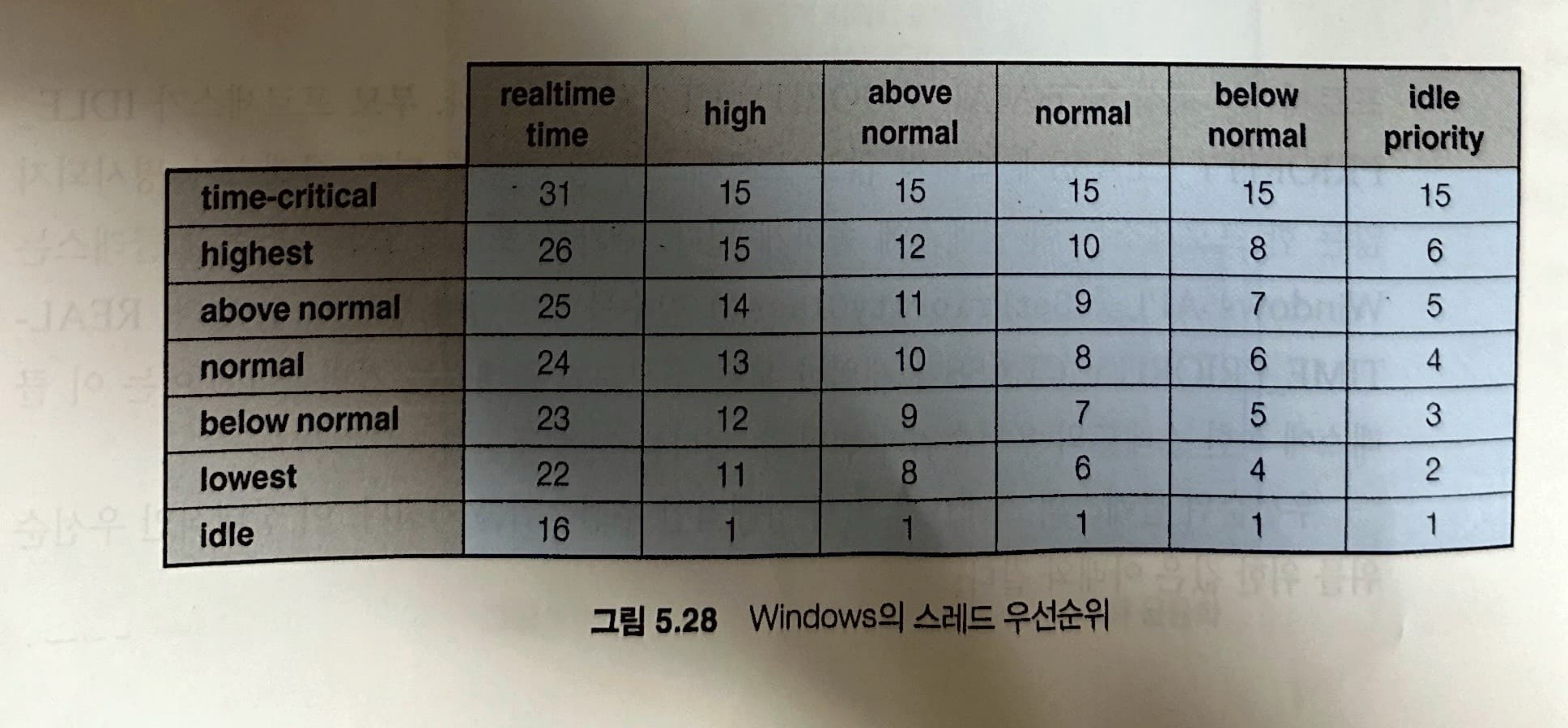
클래스로 우선순위를 나누며, 클래스 안에서의 상대적인 우선순위로 결정하여 최종적인 우선순위 값을 얻게 됩니다.
간단하게 동작을 살펴보자면,
- 스레드의 시간 할당량이 만료되면, 그 스레드는 인터럽트 됩니다.
- 그 스레드가 가변 우선순위 클래스에 속한다면 우선순위가 낮아집니다. (기본 우선순위보단 낮아지지 않습니다.)
- 가변 우선순위 스레드가 대기 연산에서 풀려나면 디스패처는 그 우선순위를 높여줍니다.
- 올려주는 정도는 목적에 따라 달라집니다.
Windows 7에서 도입된 사용자 모드 스케줄링(User-Mode Scheduling, UMS)에 대한 설명도 나오고 있습니다.
하지만 이것에 관한 내용은 나중에 정리를 하도록 하겠습니다. (다른 개념들을 충분히 이해한 뒤 정리하도록 하겠습니다.)
알고리즘 평가에 대한 정리는 넘기도록 하겠습니다.
참고한 자료
- 운영체제[공룡책]
