나쁜 상황에 대비한 스프링 클라우드와 Resilience4j를 사용한 회복성 패턴
여기서는 회복성(resilience)에 대해서 다룰 것입니다.
분산 시스템에서 실패를 겪는 경우가 있는데, 대게 이것은 인프라스트럭처나 중요 서비스의 한 부분이 완전히 실패한 경우만 고려하는 경우가 많습니다.
이러한 설계는 다음과 같은 문제가 생길 수 있습니다.
- 서비스 성능 저하는 간헐적으로 시작되어 확산될 수 있습니다: 애플리케이션의 스레드 풀이 완전히 소진되고 붕괴되기 전까지, 실패의 첫 징후는 소규모 사용자가 문제에 대해 불평하는 정도로 나타날 수 있습니다.
- 원격 서비스 호출은 대게 동기식이며 장기간 수행되는 호출을 중단하지 않습니다: 호출자에게 서비스 호출이 행(hanging)되는 것을 방지하는 타임아웃 개념이 없습니다.
- 대개 원격 자원의 부분적인 저하가 아닌 완전한 실패를 처리하도록 애플리케이션을 설계합니다: 서비스가 완전히 실패하지 않는 한 애플리케이션은 계속해서 불량한 서비스를 호출하고 빠르게 실패하지 못하는 경우가 많습니다.
이러한 문제점들은 공통적으로 문제가 확산되는 것으로 인해 "장애 전파"가 발생한다는 것입니다.
회복성 패턴은 이러한 문제점들을 해결하기 위한 마이크로서비스 아키텍처의 가장 중요한 요소 중 하나입니다.
7.1 클라이언트 측 회복성이란?
클라이언트 측 회복성 소프트웨어 패턴들은 에러나 성능 저하로 원격 자원이 실패할 때 원격 자원의 클라이언트가 고장 나지 않게 보호하는 데 중점을 둡니다.
이들 패턴을 사용하면 클라이언트가 빨리 실패하고 데이터베이스 커넥션과 스레드 풀 같은 소중한 자원을 소비하는 것을 방지할 수 있습니다.
또한 재대로 성능이 낮은 원격 서비스 문제가 소비자에게 '상향(upstream)'으로 확산되는 것을 막습니다.
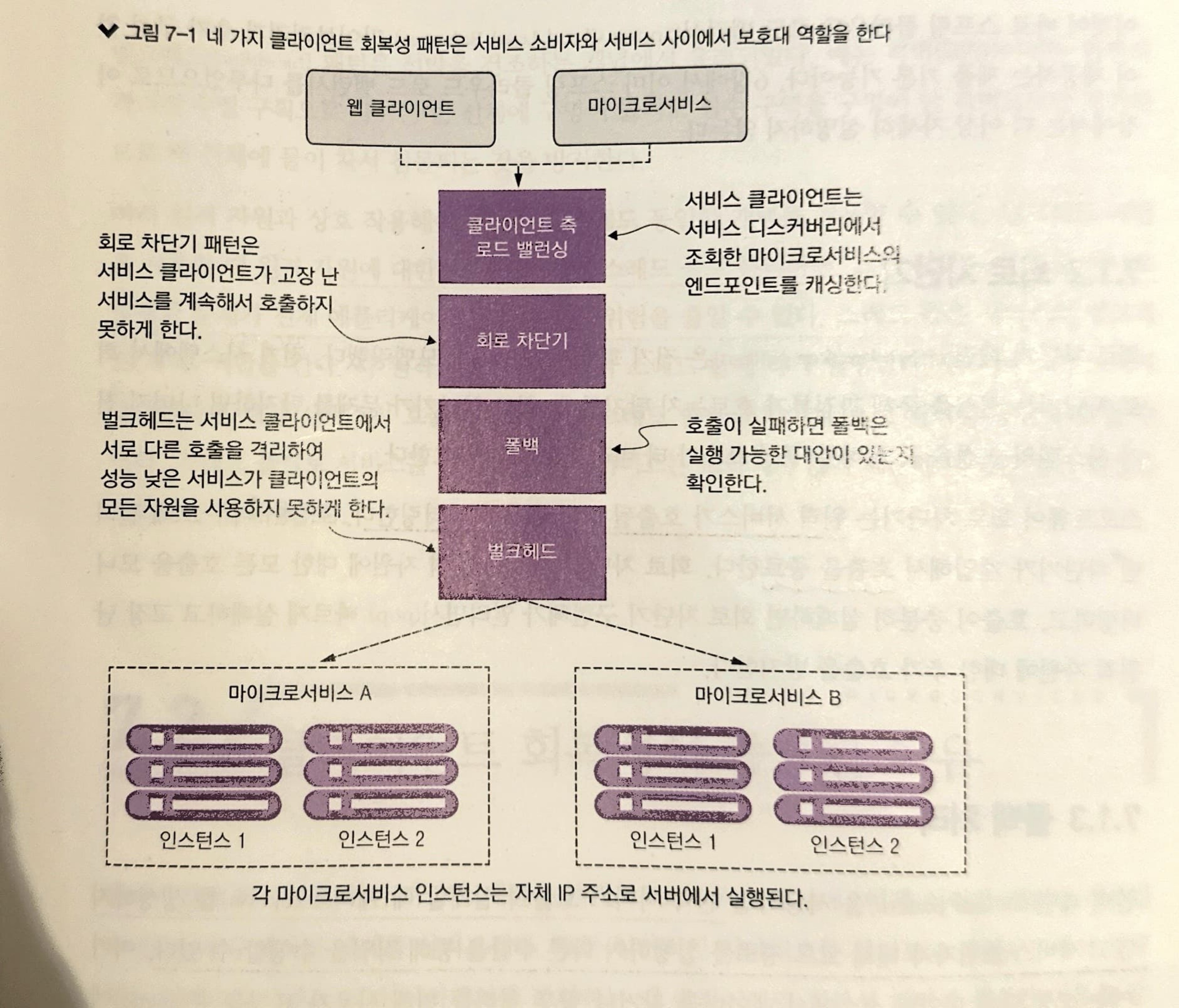
7.1.1 클라이언트 측 로드 밸런싱
클라이언트 측 로드 밸런싱은 클라이언트가 서비스 디스커버리 에이전트(넷플릭스의 유레카와 같은)에서 서비스의 모든 인스턴스를 검색한 후 해당 서비스 인스턴스의 물리적 위치를 캐싱하는 작업을 포함합니다.
클라이언트 측 로드 밸런싱은 관리 중인 서비스 위치 풀에서 위치를 반환하는데, 이것은 클라이언트와 서비스 소비자 사이에 위치 하기 때문에 서비스 인스턴스가 에러를 발생하거나 정상적으로 동작하지 않는지 탐지할 수 있습니다.
문제가 있는 서비스 인스턴스를 제거함으로써 더이상 호출하지 않도록 합니다.
7.1.2 회로 차단기
회로 차단기 패턴(circuit breaker pattern)은 호출이 너무 오래 걸릴 경우 차단기가 개입해서 호출을 종료합니다. 회로 차단기 패턴은 원격 자원에 대한 모든 호출을 모니터링하고, 호출이 충분히 실패하면 회로 차단기 구현체가 열리면서(pop) 빠르게 실패하고 고장 난 원격 자원에 대한 추가 호출을 방지합니다.
7.1.3 폴백 처리
폴백 패턴(Fallback Pattern)을 사용하면 원격 서비스 호출이 실패할 때 예외(exception)를 생성하지 않고 서비스 소비자가 대체 코드 경로를 실행하여 다른 수단을 통해 작업을 수행할 수 있습니다.
즉, 문제 발생시 예외를 발생시키는 것이 아닌 다른 방법을 고려하는 것입니다.
이때 다음과 같은 방법들을 고려할 수 있습니다.
- 다른 데이터 소스에서 데이터를 찾는다.
- 향후 처리를 위해 사용자 요청을 큐(queue)에 입력
예를 들어 사용자 행동 양식을 모니터링하고 구매 희망 항목을 추천하는 기능을 제공하는 전자 상거래 사이트가 있다고 가정해 봅시다.
일반적으로 마이크로서비스를 호출하여 사용자 행동을 분석하고 특정 사용자에게 맞춤화된 추천 목록을 반환합니다. 하지만 기호 설정(preference) 서비스가 실패하면, 폴백은 모든 사용의 구매 정보를 기반으로 더욱 일반화된 기호 목록을 검색할 수 있습니다. 그리고 이 데이터는 완전히 다른 서비스와 데이터 소스에서 추출될 수 있습니다.
7.1.4 벌크헤드
벌크헤드(bulkhead) 패턴을 사용할 때 원격 자원에 대한 호출을 '자원별 스레드 풀'로 분리하면, 느린 원격 자원 호출 하나로 발생한 문제가 전체 애플리케이션을 다운시킬 위험을 줄일 수 있습니다.
예시를 통해 한번 살펴봅시다.
이커머스 플랫폼에서 여러 마이크로서비스를 운영하는 상황을 가정해봅시다. 각 마이크로서비스는 예를 들어 상품 정보, 사용자 리뷰, 상품 사진 등 다양한 데이터를 처리합니다. 이때, 상품 사진을 가져오는 서비스가 느려지거나 포화 상태에 이르렀다고 해봅시다.
- 벌크헤드 패턴 없이: 모든 원격 자원 호출이 단일 스레드 풀 또는 공유 자원을 사용한다면, 상품 사진 서비스의 지연이나 실패는 전체 시스템의 성능 저하나 실패로 이어질 수 있습니다. 이는 상품 정보나 사용자 리뷰 같은 다른 서비스의 응답 시간에도 영향을 미치며, 최악의 경우 전체 시스템이 다운될 수 있습니다.
- 벌크헤드 패턴 사용 시: 상품 정보, 사용자 리뷰, 상품 사진 등 각각의 서비스 호출을 위해 별도의 스레드 풀(자원별 스레드 풀)을 사용합니다. 이 경우, 상품 사진 서비스의 문제가 해당 서비스의 스레드 풀 내에서만 한정되며, 다른 서비스는 영향을 받지 않습니다. 따라서 상품 정보나 사용자 리뷰 등의 서비스는 정상적으로 응답할 수 있고, 사용자는 상품 사진을 제외한 나머지 정보를 계속해서 받아올 수 있습니다.
7.2 클라이언트 회복성이 중요한 이유
해당 파트에서는 예시를 통해서 살펴볼 것입니다.

먼저 위의 그림을 살펴보면 라이선싱 서비스는 조직 서비스에 의존하고 있고, 조직 서비스는 재고 서비스를 의존하고 있습니다.
재고 서비스는 NAS(Network Attached Storage)를 사용하고 있습니다.
만약, 재고 서비스에서 과부화가 발생했다고 가정해 봅시다.
애플리케이션 A, B가 조직 서비스를 호출하게 되는 요청을 라이선싱 서비스로 보냈다고 가정해 봅시다.
해당 요청이 재고 서비스에 대한 호출 + 자신의 데이터베이스에 대한 CRUD 작업으로 동일한 트랜잭션 안에서 수행되는 코드라면 재고 서비스가 느리게 실행되기 시작했을 때 재고 서비스 요청에 대한 스레드 풀이 쌓이기 시작할 뿐 아니라 서비스 컨테이너의 커넥션 풀에 있는 데이터베이스 커넥션 수도 고갈될 것입니다.
즉, 조직 서비스에 대한 요청을 다 처리하지 못하여 트랜잭션 종료까지 도달하지 못하여 커넥션이 끊어지지 않아서 커넥션 수가 고갈된다는 의미입니다.
만약 재고 서비스 호출에 회로 차단기를 구현했다면 해당 서비스가 재대로 수행되지 못하기 시작했을 때 해당 호출에 대한 회로 차단기가 작동해서 스레드를 소모하지 않고 빠르게 실패했을 것입니다.
조직 서비스에 여러 엔드포인트가 있다면 재고 서비스에 대한 특정 호출과 연관된 엔드포인트만 영향을 받을 것입니다.
회로 차단기를 사용하는 아래의 그림을 살펴봅시다.
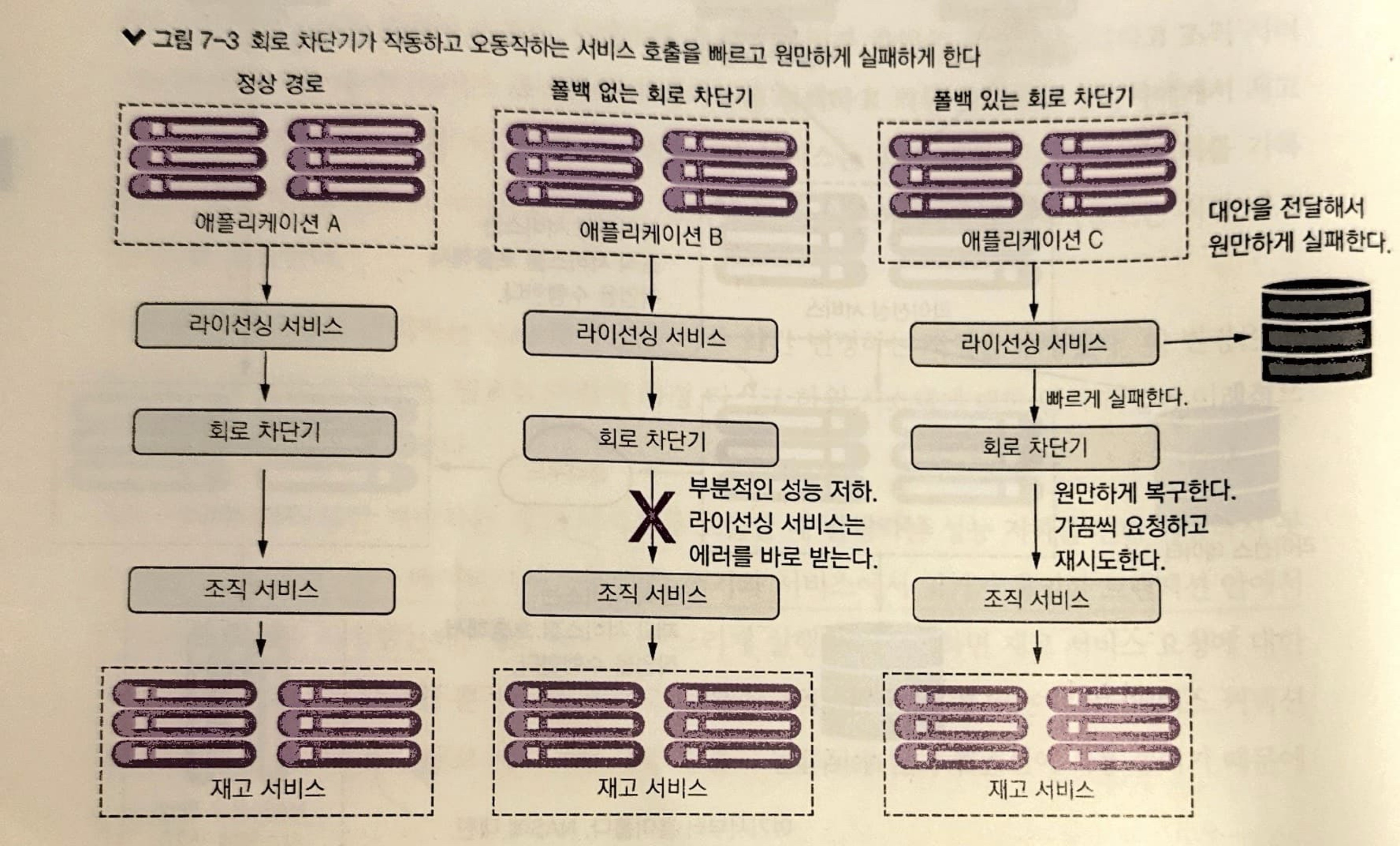
라이선싱 서비스는 조직 서비스를 직접 호출하는 것이 아닌 회로 차단기에 서비스에 대한 실제 호출을 위임합니다.
회로 차단기는 해당 호출을 스레드(대게 스레드 풀에서 관리되는)로 래핑(wrapping)합니다.
호출을 스레드로 래핑하면 클라이언트는 더 이상 호출이 완료되길 직접 기다리지 않아도 됩니다. 회로 차단기가 스레드를 모니터링하고 너무 오래 실행된다면 호출을 종료할 수 있습니다.
조직 서비스에 대한 호출 시간이 만료되면 회로 차단기는 발생한 실패 횟수를 추적하기 시작하는데, 특정 시간 동안 서비스에서 오류가 필요 이상으로 발생하면 회로 차단기는 회로를 '차단'(trip)하고 조직 서비스에 대한 모든 호출은 조직 서비스 호출 없이 실패합니다.
세번째 시나리오를 보면 회로 차단기의 타임아웃을 기다릴 필요 없이 문제가 있다는 것을 즉시 알 수 있습니다. 그런 다음 "완전히 실패"하거나 "대체 코드(폴백)"를 사용하여 조치하는 것중에서 선택할 수 있습니다.
회로 차단기가 차단되면 라이선싱 서비스가 조직 서비스를 호출하지 않았기 때문에 조직 서비스는 회복할 수 있는 기회가 생깁니다.
회복하는 경우는 회로 차단기가 저하된 서비스에 대한 호출을 때때로 허용함으로써, 연속적으로 필요한 만큼 성공하면 스스로 재설정을 합니다.
원격 호출에 대한 차단기 패턴이 제공하는 주요 이점은 다음과 같습니다.
- 빠른 실패(fail fast): 원격 서비스가 성능 저하를 겪으면 애플리케이션은 빠르게 실패하고 전체 애플리케이션을 완전히 다운시킬 수 있는 자원 고갈 이슈를 방지합니다.
- 원만한 실패(fail gracefully): 타임아웃과 빠른 실패를 사용하는 회로 차단기 패턴은 원만하게 실패하거나 사용자 의도를 충족하는 대체 매커니즘을 제공할 수 있게 해줍니다.
- 원할한 회복(recover seamlessly): 회로 차단기 패턴이 중개작 역할을 하므로 회로 차단기는 요청 중인 자원이 다시 온라인 상태가 되었는지 확인하고, 사람의 개입 없이 자원에 대한 재접근을 허용하도록 주기적으로 확인합니다.
7.3 Resilience4j 구현
Resilience4j는 내결함성 라이브러리입니다. 네트워크 문제나 여러 서비스의 고장으로 발생하는 결함 내성을 높이기 위해 다음 패턴을 제공합니다.
- 회로 차단기(circuit breaker): 요청받은 서비스가 실패할 때 요청을 중단합니다.
- 재시도(retry): 서비스가 일시적으로 실패할 때 재시도합니다.
- 벌크헤드(bulkhead): 과부하를 피하고자 동시 호출하는 서비스 요청 수를 제한합니다.
- 속도 제한(rate limit): 서비스가 한 번에 수신하는 호출 수를 제한합니다.
- 폴백(fallback): 실패하는 요청에 대해 대체 경로를 설정합니다.
Resilience4j의 재시도 순서에서 주목할 사항은 다음과 같습니다.
Retry(CircuitBreaker(RateLimiter(TimeLimiter(Bulkhead(Function)))))호출의 마지막에 Retry(재시도)가 적용됩니다(필요한 경우). 패턴을 결합하려고 할 때는 이 순서를 기억해야 하며, 각 패턴을 개별적으로 사용할 수도 있습니다.
순서를 좀 더 구체적으로 정리하자면 다음과 같습니다.
- 요청이 들어오면
Bulkhead를 통해 해당 서비스의 동시 요청 수 제한을 검사 - 요청이 Bulkhead를 통과하면,
TimeLimit를 통해 요청처리 시간을 제한 - 요청의 빈도는
RateLimiter에 의해 제한 CircuitBreaker는 연속된 실패 횟수나 비율을 검사하여 요청의 성공/실패를 결정- 만약 요청이 실패하면,
Retry매커니즘에 의해 설정된 횟수나 시간만큼 재시도
7.4 스프링 클라우드와 Resilience4j를 사용하는 라이선싱 서비스 설정
resilience4j-spring-boot2 산출물에 대한 <dependency> 태그는 Resilience4j 스프링부트 라이브러리를 내려받도록 지시하는데, 이 라이브러리는 커스텀 패턴의 어노테이션을 사용할 수 있게 해줍니다.
resilience4j-circuitbreak와 resilience4j-timelimiter 산출물에는 회로 차단기 및 속도 제한기(rate limiter)를 구현한 로직이 포함됩니다.
spring-aop는 스프링 AOP 관점을 실행하는 데 필요합니다.
AOP의 사용은 횡단 관심사를 분리하여 모듈성을 높여 코드를 수정하지 않고 새로운 동작을 기존 코드에 추가할 수 있게 해줍니다.
7.5 회로 차단기 구현
코드에서 회로 차단기가 추구하는 것은 원격 호출을 모니터링하고 서비스를 장기간 기다리지 않게 하는 것입니다.
빠른 실패(fast fail)를 구현하여 실패한 서비스에 추가로 요청하는 것을 방지합니다.
아래의 그림은 다양한 상태와 상태 간 상호 작용을 보여줍니다.
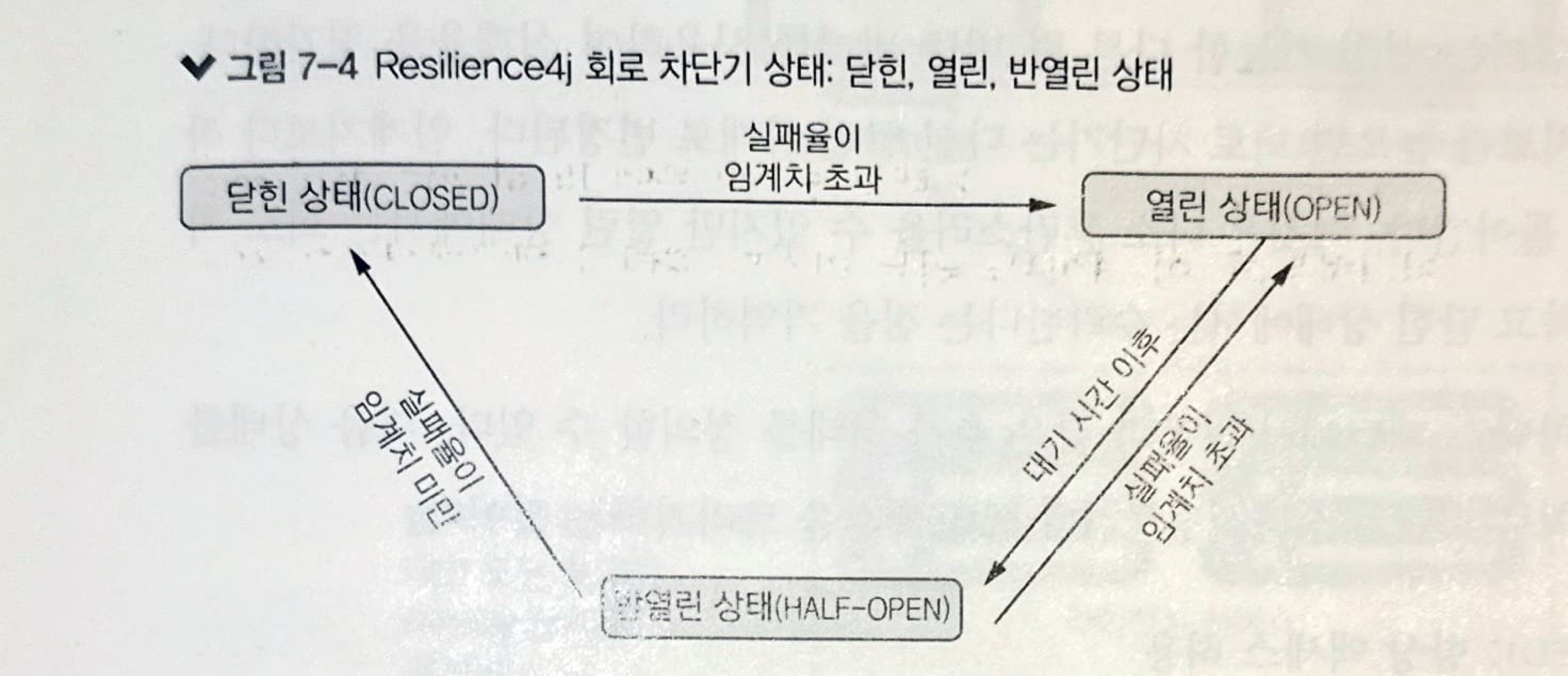
처음에 Resilience4j 회로 차단기는 닫힌 상태에서 시작한 후 클라이언트 요청을 기다립니다.
닫힌 상태는 링 비트 버퍼(ring bit buffer)를 사용하여 요청의 성과 및 실패 상태를 저장합니다.
요청이 성공하면 회로 차단기는 링 비트 버퍼에 0비트를 저장하지만, 호출한 서비스에 응답받지 못하면 1비트를 저장합니다.
실패율을 계산하려면 링을 모두 채워야 합니다. 회로 차단기는 고장률이 임계 값(구성 설정 가능한)을 초과할 때만 열립니다.
회로 차단기가 열린 상태라면 설정된 시간 동안 호출은 '모두 거부'되고 회로 차단기는 CallNotPermittedException 예외를 발생시킵니다. 설정된 시간이 만료되면 회로 차단기는 반열린 상태로 변경되고 서비스가 여전히 사용 불가한지 확인하고자 일부 요청을 허용합니다.
반열린 상태에서 회로 차단기는 설정 가능한 다른 링 비트 버퍼를 사용하여 실패율을 평가합니다.
이 실패율이 설정된 임계치보다 높으면 회로 차단기는 다시 열린 상태로 변경됩니다.
임계치보다 작거나 같다면 닫힌 상태로 돌아갑니다.
해당 패턴에서는 다음과 같은 추가 상태를 정의할 수 있습니다.
- 비활성 상태(DISABLED): 항상 액세스 허용
- 강제 열린 상태(FORCED_OPEN): 항상 액세스 거부
Resilience4j 구현 방법을 두 가지 큰 범우제서 살펴보면 다음과 같습니다.
- Resilience4j 회로 차단기로 라이선스 및 조직 서비스의 데이터베이스에 대한 모든 호출을 래핑(wrapping)합니다.
- Resilience4j를 사용하여 두 서비스 간 호출을 래핑합니다.
Resilience4j와 스프링 클라우드는 @CircuitBreaker를 사용하여 Resilience4j 회로 차단기가 관리하는 자바 클래스 메서드를 표시합니다.
스프링 프레임워크가 이 어노테이션을 만나면 동적으로 프록시를 생성해서 해당 메서드를 래핑하고, 원격 호출을 처리할때만 별도로 설정된 스레드 풀을 이용하여 해당 메서드에 대한 모든 호출을 관리합니다.
다음 코드 예시를 살펴봅시다.
@CircuitBreaker(name="licenseService")
public List<License> getLicensesByOrganization(String organizationId) {
return licenseRepository.findByOrganizationId(organizationId);
}해당 코드는 Resilience4j 회로 차단기를 사용하여 getLicensesByOrganization() 메서드를 @CircuitBreaker로 래핑합니다.
7.5.1 서비스에 회로 차단기 추가
메서드 레벨의 어노테이션으로 회로 차단기 기능을 호출에 삽입할 경우 장점은 데이터베이스를 액세스하든지 마이크로서비스를 호출하든지 간에 동일한 어노테이션을 사용할 수 있다는 것입니다.
예를 들어서, 회로 차단기로 조직 서비스에 대한 호출을 래핑하고 싶다면, 간단하게 다음과 같이 RestTemplate 호출 부분을 메소드로 분리하고 @CircuitBreaker를 추가하면 됩니다.
@CircuitBreaker(name="organizationService")
private Organization getOrganization(String organizationId) {
return organizationRestClient.getOrganization(organizationId);
}회로 차단기의 기본값을 알아보려면 포스트맨에서 URL(http://localhost:<service_port>/actuator/health)을 선택합니다.
기본적으로 스프링 부트 액추에이터의 상태 정보(health) 서비스로 회로 차단기 구성 정보를 노출합니다.
회로 차단기 사용자 정의는 스프링 컨피그 서버 저장소에 있는
application.yml,bootstrap.yml또는 서비스 구성 파일에 몇 가지 파라미터를 추가하면 되고, 해당 내용은 넘어가겠습니다.
7.6 폴백 처리
회로 차단기 패턴의 장점 중 하나는 이 패턴이 '중개자'로, 원격 자원과 그 소비자 사이에 위치하기 때문에 서비스 실패를 가로채서 다른 대안을 취할 수 있다는 것입니다.
Resilience4j에서 이 대안을 폴백 전략(fallback strategy)이라고 합니다.
다음 코드는 폴백 전략을 보여줍니다.
// @CircuitBreaker(name = "licenseService") //코드 7-2의 경우 이 애너테이션만 추가한다.
@CircuitBreaker(name = "licenseService", fallbackMethod = "buildFallbackLicenseList")
@RateLimiter(name = "licenseService", fallbackMethod = "buildFallbackLicenseList")
@Retry(name = "retryLicenseService", fallbackMethod = "buildFallbackLicenseList")
@Bulkhead(name = "bulkheadLicenseService", type= Type.THREADPOOL, fallbackMethod = "buildFallbackLicenseList")
public List<License> getLicensesByOrganization(String organizationId) throws TimeoutException {
logger.debug("getLicensesByOrganization Correlation id: {}",
UserContextHolder.getContext().getCorrelationId());
randomlyRunLong();
return licenseRepository.findByOrganizationId(organizationId);
}
@SuppressWarnings("unused")
private List<License> buildFallbackLicenseList(String organizationId, Throwable t){
List<License> fallbackList = new ArrayList<>();
License license = new License();
license.setLicenseId("0000000-00-00000");
license.setOrganizationId(organizationId);
license.setProductName("Sorry no licensing information currently available");
fallbackList.add(license);
return fallbackList;
}코드를 그대로 가져온 것이며 해당 코드에서는
@CircuitBreaker외에도 다른 실패에 관련해서도 폴백 전략을 보여줍니다.
여기서 중요한 점은 폴백 메서드를 정의하는 것입니다. 폴백 메서드는 원래 메서드와 동일한 클래스에 위치해야 합니다.
또한, 폴백 메서드를 생성하려면 원래 메서드(getLicensesByOrganization())처럼 하나의 매개변수를 받도록 동일한 서식을 가져야 합니다. 동일한 서식을 사용해야 원래 메서드의 모든 매개변수를 폴백 메서드에 전달할 수 있습니다.
7.7 벌크헤드 패턴 구현
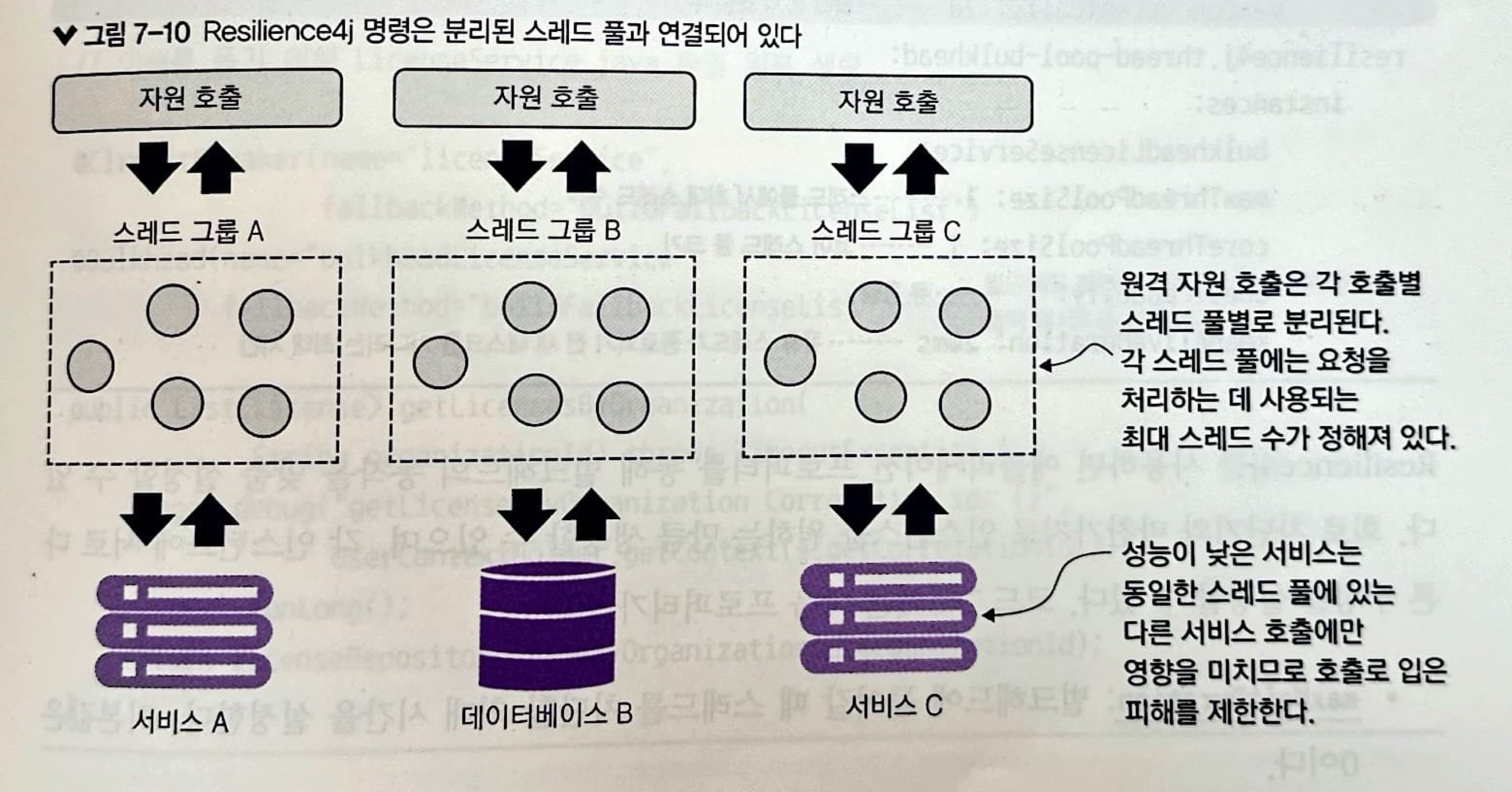
마이크로서비스 기반 애플리케이션에서 특정 작업을 완료하기 위해 여러 마이크로서비스를 호출해야 할 경우가 많습니다.
벌크헤드 패턴을 사용하지 않는다면 이러한 호출의 기본 동작은 전체 자바 컨테이너에 대한 요청을 처리하려고 예약된 동일한 스레드를 사용해서 실행합니다. 대규모 요청이라면 성능 문젤르 야기할 수 있습니다.
벌크헤드 패턴은 원격 자원 호출을 자체 스레드 풀에 격리해서 한 서비스의 오작동을 억제하고 컨테이너를 멈추지 않게 합니다.
Resilience4j는 벌크헤드 패턴을 위해 두 가지 다른 구현을 제공합니다.
- 세마포어 벌크헤드(semaphore bulkhead): 세마포어 격리 방식으로 서비스에 대한 동시 요청 수를 제한합니다. 한계에 도달하면 요청을 거부합니다.
- 스레드 풀 벌크헤드(thread pool bulkhead): 제한된 큐와 고정 스레드 풀을 사용합니다. 이 방식은 풀과 큐가 다 찬 경우만 요청을 거부합니다.
Resilience4j는 기본적으로 세마포어 벌크헤드 타입을 사용합니다.
이 모델은 다음과 같은 경우 잘 작동합니다.
- 애플리케이션에서 액세스하는 원격 자원의 수가 적을 때
- 각 서비스에 대한 호출량이 상대적으로 고르게 분산되어 있을 때
문제는 다음과 같습니다.
- 다른 서비스보다 호출량이 훨씬 많거나 완료하는 데 오래 걸리는 서비스가 있다면, 즉 서비스가 불균형하다면,
- 한 서비스가 기본 스레드 풀의 모든 스레드를 점유하기 때문에 모든 스레드를 소진
아래 그림은 위와 같은 문제를 해결하기 위해 관리 자원을 각 벌크헤드로 분리하는 것을 보여줍니다.
bootstrap.yml을 이용하여 구성 매개변수를 설정하는 방법이 나오는데 넘어가겠습니다.
7.8 7.9 재시도 패턴과 속도 제한기 패턴
여기서는 코드에 대한 내용은 생략하고 두 패턴에 대해서 간략하게 알아보고 넘어가도록 하겠습니다.
재시도 패턴(retry pattern)은 서비스가 처음 실패했을 떄 서비스와 통신을 재시도 하는 역할을 합니다.
이 패턴의 핵심 개념은 고장이 나도 동일한 서비스를 한 번 이상 호출해서 기대한 응답을 얻을 수 있는 방법을 제공하는 것입니다.
그렇기 때문에 다음과 같은 요소를 고려해야 합니다.
- 재시도 최대 횟수
- 재시도 간 대기 시간
- 재시도 대상이 되는 예외(exception) 목록
이러한 요소들은 구성 파일의 매개 변수 설정을 통해 구현할 수 있습니다.
Resilience4j는 속도 제한기 패턴을 위해 AtomicRateLimiter와 SemaphoreBasedRateLimiter 라는 두 가지 구현체를 제공합니다.
RateLimiter의 기본 구현체는 AtomicRateLimiter입니다.
SemaphoreBasedRateLimiter는 단순한데 하나의 java.util.concurrent.Semaphore에 현재 스레드 허용(permission) 수를 저장하도록 구현되었습니다.
이 경우 모든 사용자 스레드는 semaphore.tryAcquire() 메서드를 호출하고 새로운 limitRefreshPeriod가 시작될 때 semaphore.release()를 실행하여 내부 스레드에 호출을 트리거합니다.
AtomicRateLimiter는 사용자 스레드가 직접 모든 허용 로직을 실행하기 때문에 스레드 관리가 필요 없습니다.
AtomicRateLimiter는 시작부터 나노초 단위의 사이클로 분할하고 각 사이클 기간이 갱신 기간(단위: ns)입니다. 그런 다음 매 사이클 시작 지점에 가용한 허용(active permissions) 수를 설정함으로써 사이클 기간을 제한합니다.
이 구현에는 몇 가지 까다로운 로직이 있습니다. 더 잘 이해하려면 이 패턴에 대해 다음 Resilience4j 선언을 고려할 수 있습니다.
- 사이클은 동일한 시간 단위입니다.
- 가용한 허용 수가 충분하지 않다면, 현재 허용수를 줄이고 여유가 생길때까지 대기할 시간을 계산함으로써 허용을 예약할 수 있습니다.
이 예약 기능은 Resilience4j에서 일정 기간 동안(limitForPeriod) 허용되는 호출 수를 정의할 수 있어 가능합니다.
허용이 갱신되는 빈도(limitRefreshPeriod)와 스레드가 허용을 얻으려고 대기할 수 있는 시간(timeoutDuration)으로 산출합니다.
ThreadLocal을 사용해서 여러 스레드가 동시에 동작하면서 객체에 접근할 때 격리해줄 수 있습니다. 이 부분은 넘어가겠습니다.
참고한 자료
- 스프링 마이크로서비스 코딩 공작소[개정 2판]
