jupyter lab에서 함수 자동완성은 tab이다.
데이터 전처리
✅ 데이터 구조 만들기 -> 데이터 분석
✅ 모델링을 위한 전처리 -> ML, DL 모델링
1. 분석을 위한 데이터 구조
🎃 데이터 분석 큰 그림 : CRISP-DM
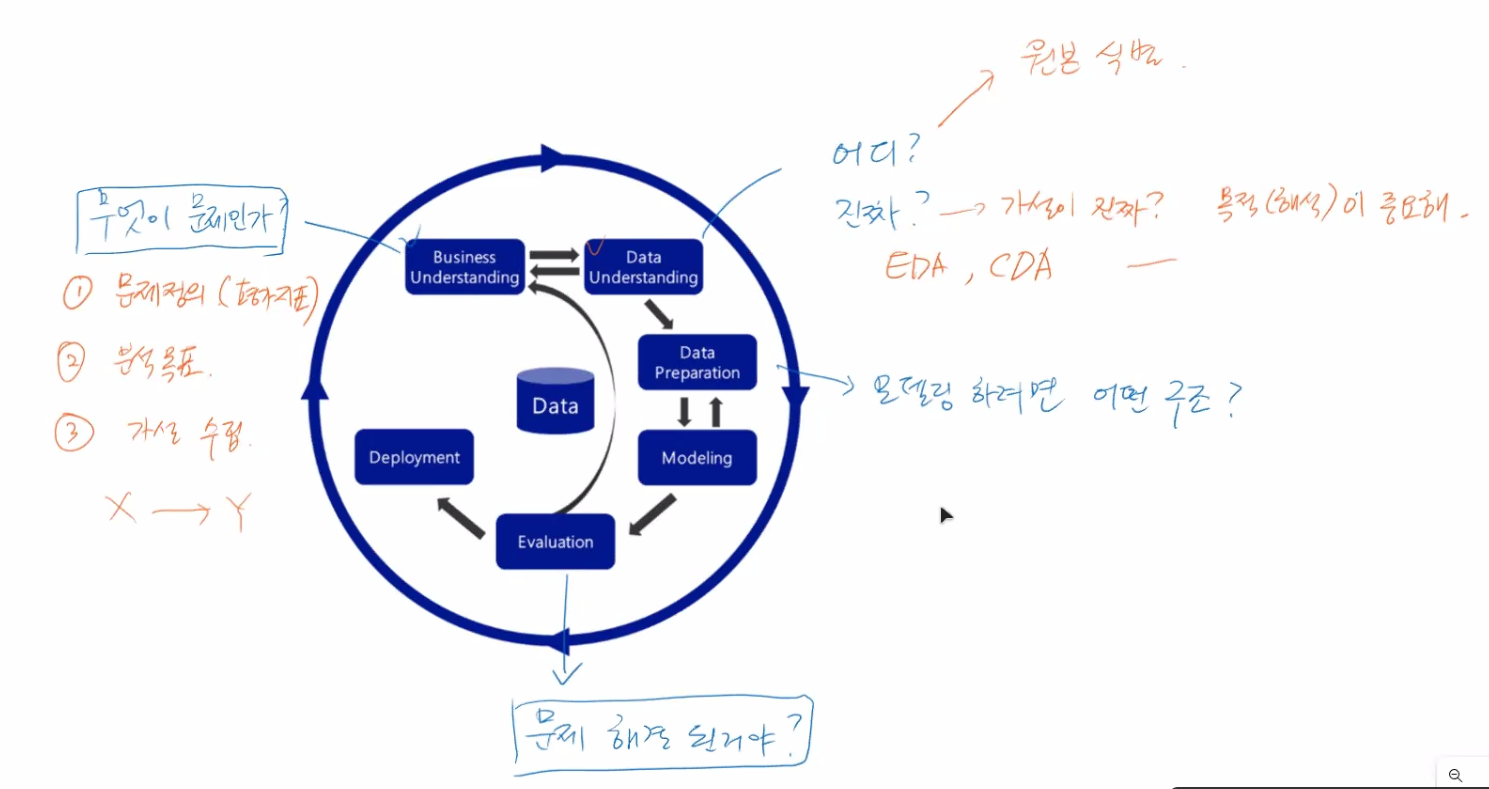
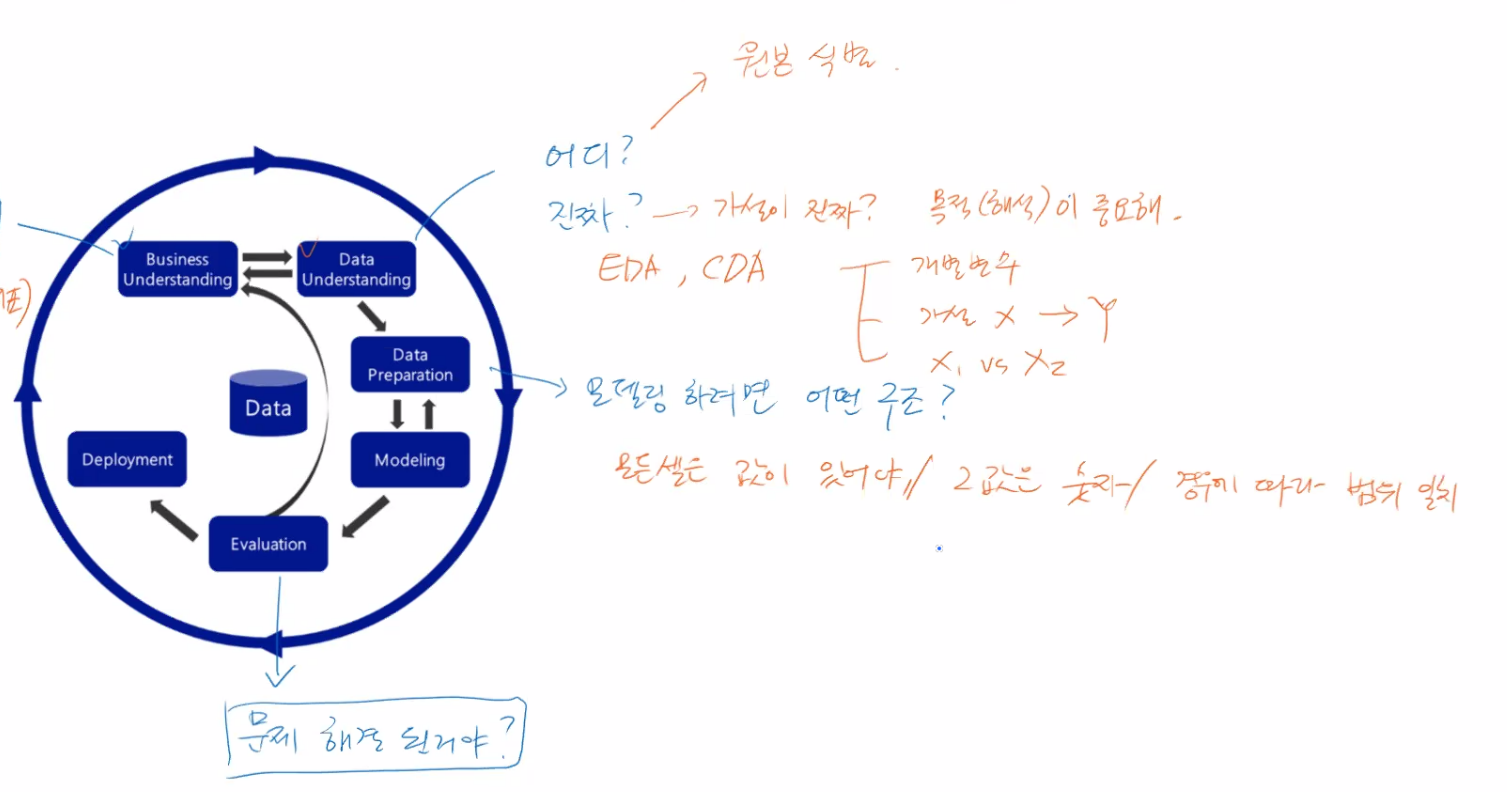
🎃 분석할 수 있는 정보의 종류
- x: feature, 요인, input, 독립변수 -> 정보, 변수, 열
- y: targer, 결과, output, 종속변수, Label -> 분석단위, 관측치, 행
2. 데이터프레임 변경
🎃 열 이름 변경
tip.columns = ['열이름1', '열이름2', '열이름3', '열이름4' ...]
- 모든 열 이름 변경
tip.rename(columns={'열이름1': '변경할 열이름1','열이름2': '변경할 열이름2'...}, inplace = True)
- 지정한 열 이름 변경
- 'inplace = False' -> 새로운 내용은 조회하여라.
- 'inplace = True' -> 새로운 내용으로 변경하여라.
🎃 열 추가
tip[추가할 열 이름] = tip[열이름1] + tip[열이름2]
- 맨 뒤에 열을 추가
- 없는 열을 변경하면 그 열이 추가됨
tip.insert(열인덱스, 추가할 열 이름, 추가할 내용)
- 원하는 위치에 열을 추가할 수 있음
- 적은 인덱스 번호 바로 앞에 추가된다. ex) 1을 적으면 1열 바로 앞(0열과 1열 사이)에 열이 추가된다.
🎃 열 삭제
drop()
- axis=0: 행
- axis=1: 열
- inplace = False: 삭제한 것처럼 보여줘
- inplace = True: 진짜 삭제해
🎃 값 변경
tip['tip'] = 0
- 열 전체 값 변경
- tip['tip']의 모든 값을 0으로 바꾸기
tip.loc[tip['tip'] < 10, 'tip'] = 참일때 값
- 조건에 의한 값 변경
- tip['tip']의 값이 10보다 작을 경우, 0으로 바꾸기
tip['tip'] = np.where(tip['tip'] < 10, 참일때 값, 거짓일때 값)
- 10보다 작을 경우 0, 아니면 1로 바꾸기
tip[열이름].map({딕셔너리})
cut()
- tip[추가할 열이름] = pd.cut(tip[변경할 열 이름], 등분수, labels=[구간별 라벨]
- 숫자형 변수 -> 범주형 변수로 변환
3. 데이터프레임 결합
pd.concat([테이블1, 테이블2], join = , axis = )
- 매핑기준: 행, 열
- join = 'outer' -> 모든 행과 열 합치기 => 합집합 (공통된 이름은 합치고 공통되지 않는 것들은 표기해준다. 값이 없으면 NaN으로 표기)
- join = 'inner' -> 매핑되는 행과 열만 합치기 => 교집합 (공통된 것들만 표기해준다.)
- axis = 0 -> 행방향(세로방향)으로 합친다.
- axis = 1 -> 열방향 (가로방향)으로 합친다.
pd.merge()
- 매핑기준: 특정키의 값 기준으로 결합
- DB 테이블 join과 같음
- left, right: 왼쪽/오른쪽 데이터에 맞추어 열을 추가함
- outer, inner: 행을 추가함
- merge는 방향성 없이 무조건 옆(가로방향)으로 붙인다
dataframe.pivot(index, 열, 값)
- 집계된 데이터를 재구성할 수 있다
- 먼저groupby로 집계하고 진행한다
- 데이터프레임을 결합시키는 것은 아니지만, 구조를 변형시키는 것이다
4. 시계열 데이터 처리
🎃 시계열 데이터
- 행과 행에 시간의 순서가 있음
- 행과 행의 시간간격이 동일한 데이터
df[열이름].dt.날짜요소
- 날짜 타입의 변수로부터 날짜의 요소를 뽑아낼 수 있다.
.shift()
- temp[생성할 열1] = temp[기준열].shift() -> 행방향 아래로 한칸씩 이동
- temp[생성할 열2] = temp[기준열].shift(2) -> 행방향 아래로 두칸씩 이동
- temp[생성할 열3] = temp[기준열].shift(-1) -> 행방향 위로 한칸씩 이동
.rolling().mean()
- temp[생성할 열1] = temp[기준열].rolling(3).mean() -> 행방향 3개씩 묶어서 평균을 구한다.
- temp[생성할 열2] = temp[기준열].rolling(3).max() -> 행방향 3개씩 묶어서 최댓값을 구한다.
- temp[생성할 열3] = temp[기준열].rolling(3, min_periods = 1).mean() -> 집계 최소 크기 1
- min_periods : 계산할 최소 크기(기간). window 안의 값의 수가 min_periods의 값보다 작을경우 NaN을 출력한다. 기본적으로 window 크기와 동일.
.diff()
- temp[생성할 열1] = temp[기준열].diff()
- temp[생성할 열1] = temp[기준열].diff(2)
- 특정 시점 데이터, 이전시점 데이터와의 차이 구하기
5. 데이터분석 방법론(강의 다시듣고 정리하기)
6. 시각화 라이브러리(강의 다시듣고 정리하기)
import matplotlib.pyplot as plt
import seaborn as sns
plt.plot(x, y, data, color = , linestyle = , marker = , label = )
- 기본 라인차트를 그려준다.
- plt.plot(data['Date'], data['Temp'])
- plt.plot('Date', 'Temp', data = data)
- color: r, g, b...
- linestyle: solid, dashed, dashdot, dotted
- marker: . , o v ^ < >
- label: 그래프별 라벨을 지정해준다.
plt.show()
- 그래프를 화면에 출력해준다.
plt.xticks(rotation=각도)
- x축 값들의 각도를 조정한다.
plt.xlabel(), plt.ylabel()
- x축의 이름과 y축의 이름을 지정한다.
plt.title()
- 그래프 제목을 지정한다.
plt.legend(loc=)
- loc: 범례 위치를 조절해준다.
plt.grid()
- 격자표시를 해준다.
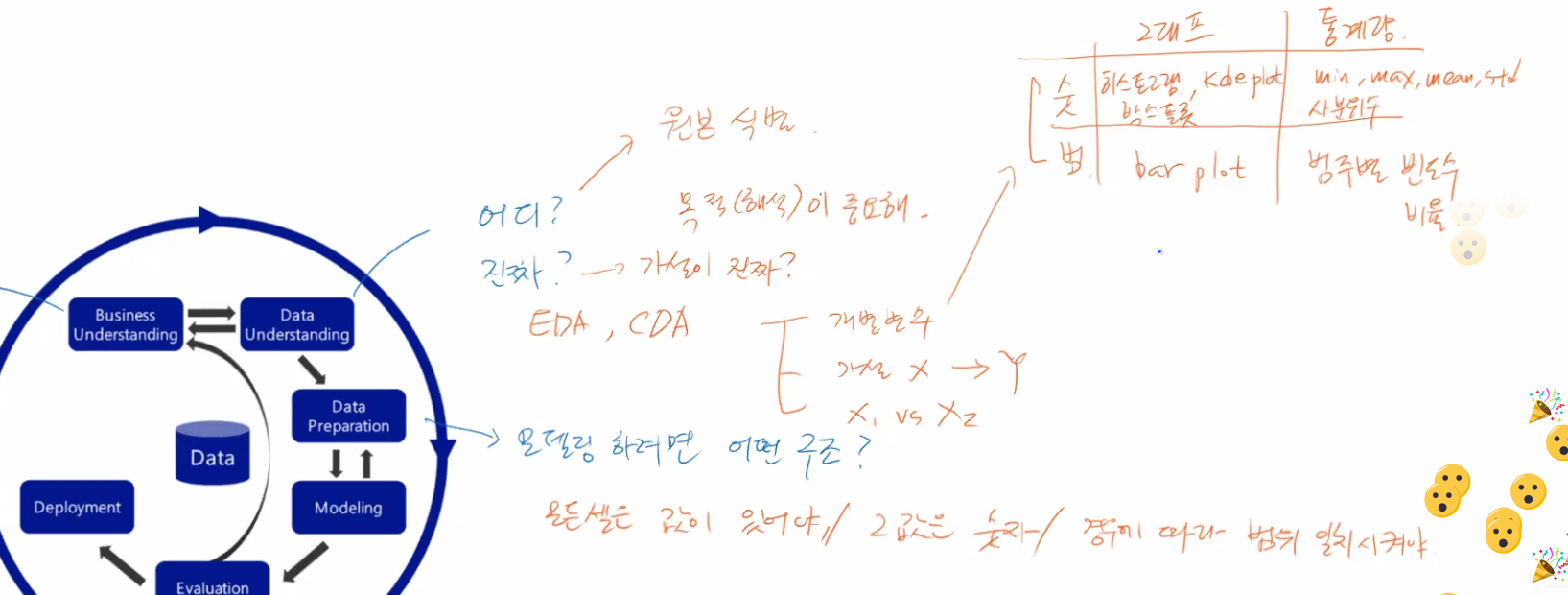
6. 개별 변수 분석 도구 (단변량 분석)(강의 다시듣고 정리하기)
🎃 숫자형 변수
1. 숫자로 요약하기 (평균, 중앙값, 최빈값, 사분위수)
- 평균(mean): 산술 평균, 기하 평균, 조화 평균
- 중위수(median): 자료의 순서상 가운데 위치한 값
- 최빈값(mode): 자료 중에서 가장 빈번한 값
- 사분위수
- 데이터를 오름차순으로 정렬한 후, 전체를 4등분하고, 각 경계에 해당되는 값을 의미한다.
- 1사분위수, 2사분위수, 3사분위수
- 데이터개수(count)
- 기초통계량(Box plot) - df.describe()
- 숫자형 변수를 쉽게 파악하기 위해 숫자 몇 개로 요약.
- count: 데이터 개수.
2. 구간을 나누고 빈도수 계산
- 도수분포표 (Histogram, Density plot):
🎃 범주형 변수
1. 범주형 변수 숫자로 요약하기 (범주별 빈도수, 범주별 비율)
- 범주별 빈도수
- 시리즈.value_counts()
- 범주별 비율
- 시리즈.value_counts()/시리즈.shape[]
- 범주별 빈도수를 전체 count로 나누기
2. 범주형 변수 시각화: Bar Plot
- sns.countplot(시리즈)
- 범주별 빈도수를 계산하고 bar plot으로 나타냄
- plt.bar
조건조회: df.loc[]
plt.subplot(행,열,순서)
.T는 행과 열을 뒤바꿔준다.
bins 그래프 내의 밀도를 지정해준다.
-> 숫자가 클수록 밀도가 높아진다.


개발 기록장