1. 상속관계 매핑
사실 RDB 에는 상속 개념이 없다.
다만 슈퍼타입 서브타입 관계라는 모델링 기법이 객체 상속과 유사하다.
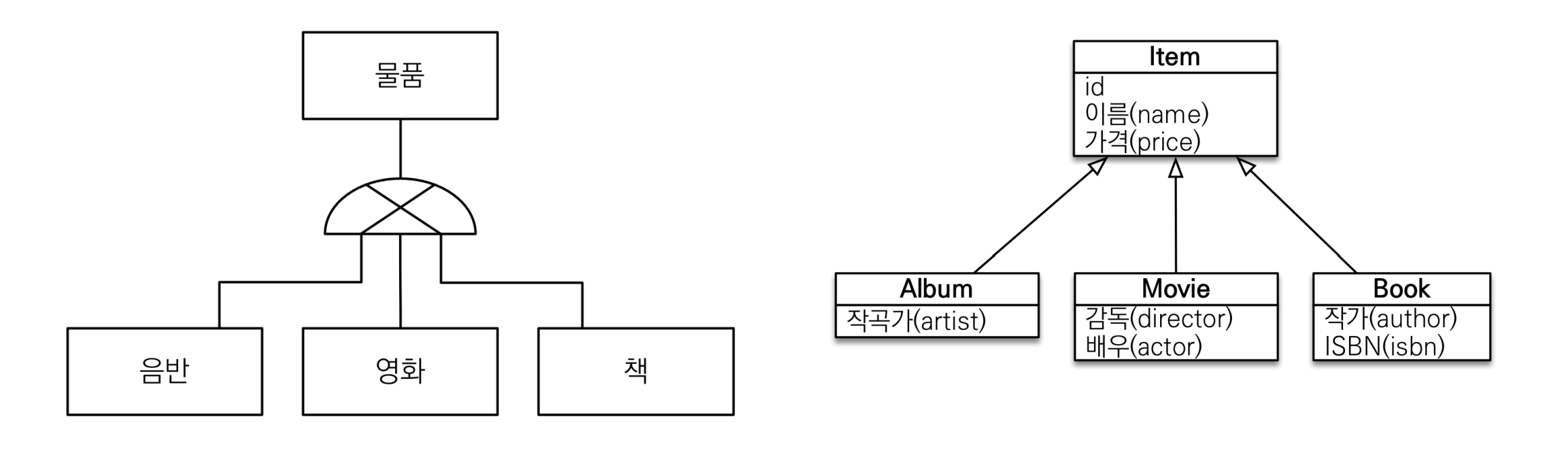
그래서 정리하면 상속관계 매핑: 객체의 상속과 구조 와 DB에서 슈퍼타입, 서브타입 관계 를 서로 매핑하겠다는 것이다.
따라서 앞선 포스팅의 연관관계에서는 DB는 바뀌지 않고 어떻게 연관관계를 설정할 것이냐로 application level 이 바뀌었는데
이번에는 application 의 객체 구조는 그대로 있고 RDB 구성을 어떻게 할 것이냐를 알아보자.
슈퍼타입 서브타입 논리 모델(RDB)을 실제 물리 모델(객체)로 구현하는 방법
주요 어노테이션
- @Inheritance(strategy=InheritanceType.XXX)
• JOINED: 조인 전략
• SINGLE_TABLE: 단일 테이블 전략
• TABLE_PER_CLASS: 구현 클래스마다 테이블 전략 - @DiscriminatorColumn(name=“DTYPE”)
- @DiscriminatorValue(“XXX”)
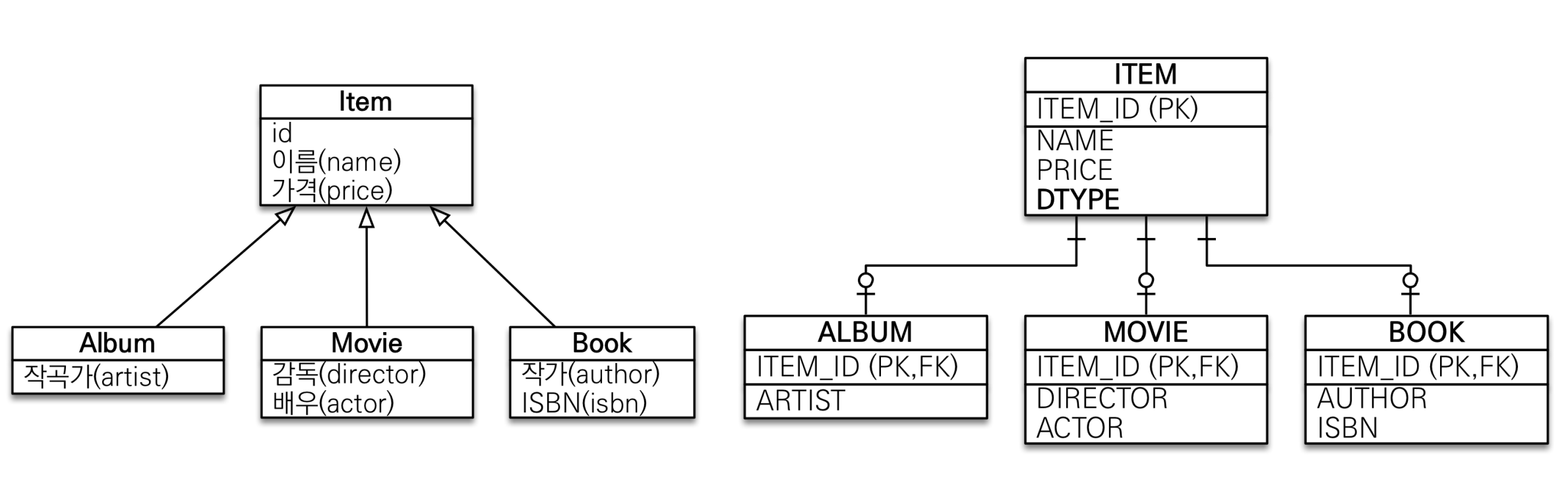
• 각각 테이블로 변환 -> 조인 전략
가장 FM 인 전략
-
장점
• 테이블 정규화 => 저장공간 효율화
• 외래 키 참조 무결성 제약조건 활용가능 => 제 3의 테이블에서 조인을 하더라도 굉장히 용이함 "ITEM" 만 보면 되니까 -
단점
• ITEM 테이블의 PK 만으론 조회가 안 되기 때문에 FK까지 사용하여 조인을 사용하여 => 조회시 조인을 많이 사용 => 성능 저하 => 얘도 막 느리진 않다.
• 조회 쿼리가 복잡함
• 각각의 테이블에 2번씩 넣어줘야하기 때문에 데이터 저장시 INSERT SQL 2번 호출 => 큰 단점은 아니다.
@Data
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
public abstract class Item {
@Id
@GeneratedValue
private Long id;
private String name;
private int price;
}Data
@Entity
public class Movie extends Item {
private String director;
private String actor;
}public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
Movie movie = new Movie();
movie.setDirector("봉준호");
movie.setActor("조여정");
movie.setName("기생충");
movie.setPrice(8000);
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}
emf.close();
}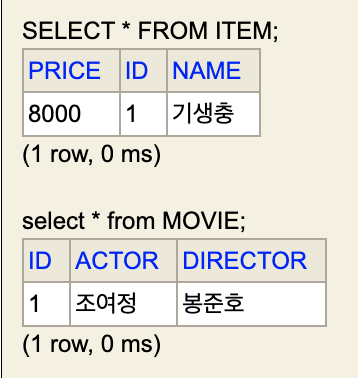
보면 @Inheritance(strategy = InheritanceType.JOINED) 을 사용하여 MOVIE 테이블에도 ID 값이 들어있는 것을 확인할 수 있다. 이 ID 값은 ITEM 의 PK 값을 가져와서 PK 이자, FK 로 사용하는 것이다.
@Data
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn(name = "DTYPE")
public abstract class Item {
@Id
@GeneratedValue
private Long id;
private String name;
private int price;
}
추후 조회해올 때도 그렇고 Discriminator 옵션은 있는 것이 좋다. 그리고 DTYPE 은 default 값이기에 실제 관련있는 컬럼명을 부여하면 좋다.
그리고 저기 DTYPE 의 Movie 는 기본적으로는 Entity 이름이 들어가는데 만약 특정 값을 넣고 싶다면 DiscriminatorValue 옵션을 넣어주면 된다.
@Entity(name = "Movie")
@Data
@DiscriminatorValue("MOVIE")
public class Movie extends Item {
private String director;
private String actor;
}
• 통합 테이블로 변환 -> 단일 테이블 전략

-
장점
• 조인이 필요 없으므로 일반적으로 조회 성능이 빠름
• 조회 쿼리가 단순함
• INSERT query문 도 1번 나감 -
단점
• 자식 엔티티가 매핑한 컬럼은 모두 null 허용
• 단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있다. 상황에 따라서 조회 성능이 오히려 느려질 수 있다.
@Data
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
public abstract class Item {
@Id
@GeneratedValue
private Long id;
private String name;
private int price;
}
참고로 앞서 @DiscriminatorColumn 어노테이션이 있어야 DTYPE 이 생긴다고 하였는데 이 싱글 테이블 전략에서는 항상 생긴다.
why? => 테이블이 분리 되어있기 때문에 어떤 카테고리인지 알 수 있었으나 단일 테이블은 알 수 없기 때문에 DTYPE 이 필수로 생성된다.
하지만 결론은 운영상 DTYPE 은 항상 있는 것이 좋다.
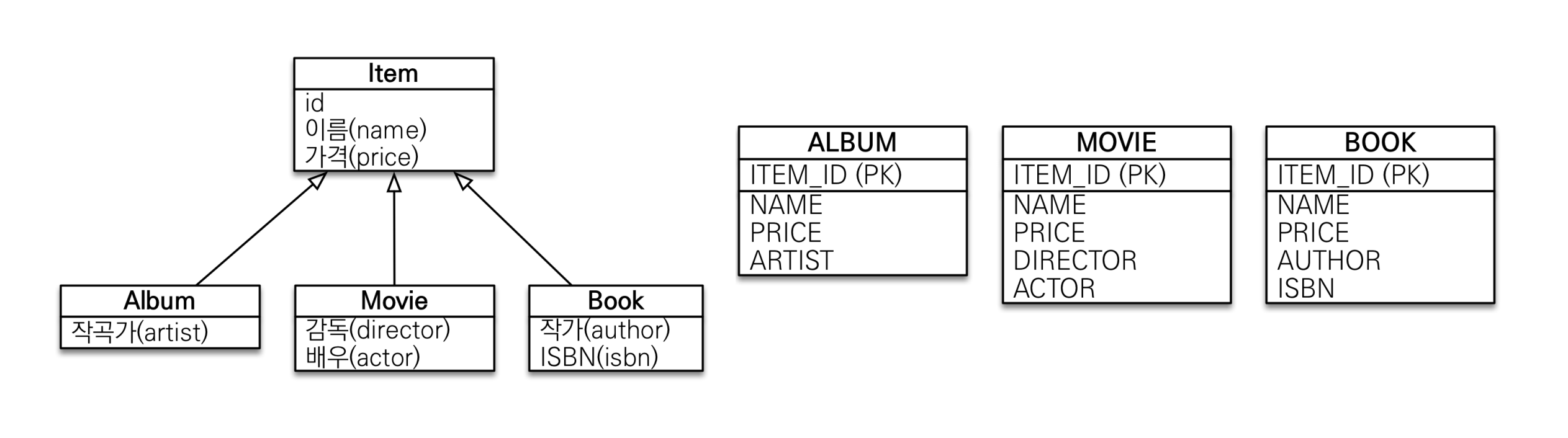
• 서브타입 테이블로 변환 -> 구현 클래스마다 테이블 전략
• 이 전략은 데이터베이스 설계자와 ORM 전문가 둘 다 추천X
- 장점
• 서브 타입을 명확하게 구분해서 처리할 때 효과적
• not null 제약조건 사용 가능 - 단점
• 여러 자식 테이블을 함께 조회할 때 성능이 느림(UNION SQL 필요)
• 자식 테이블을 통합해서 쿼리하기 어려움
@Data
@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
@DiscriminatorColumn
public abstract class Item {
@Id
@GeneratedValue
private Long id;
private String name;
private int price;
}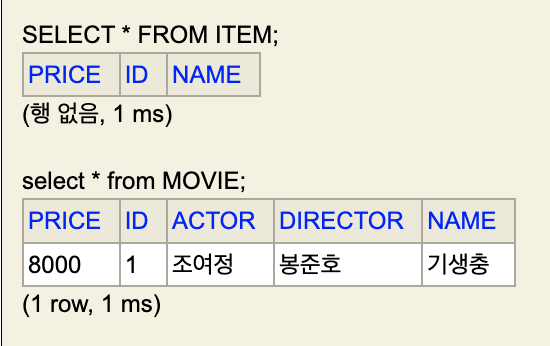
실제로는 ITEM 테이블이 아예 생성이 되지 않으나 H2 DB 특성상 이전에 생성해둔 테이블이 존재함.
그리고 이렇게 무식한 방법의 아주 큰 단점은 바로 부모 class 로 조회 할 때 나온다.
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
Movie movie = new Movie();
movie.setDirector("봉준호");
movie.setActor("조여정");
movie.setName("기생충");
movie.setPrice(8000);
em.persist(movie);
em.flush();
em.clear();
Item item = em.find(Item.class, movie.getId());
System.out.println("item = "+ item);
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}
emf.close();
}대충 이렇게 테스트 코드를 작성하고 query 를 보면 아래와 같은 union 을 사용하여 모든 table 을 뒤지고 있는 것을 확인할 수 있다.
예를 들어 movie.getId 가 5 번이 나왔을 때 id 가 5인 것이 Album 인지, Movie 인지 를 알 수 없기 때문에 결국 모든 테이블을 다 돈다는 것이다.
Hibernate:
select
i1_0.id,
i1_0.clazz_,
i1_0.name,
i1_0.price,
i1_0.artist,
i1_0.author,
i1_0.isbn,
i1_0.actor,
i1_0.director
from
(select
price,
id,
artist,
name,
null as author,
null as isbn,
null as actor,
null as director,
1 as clazz_
from
Album
union
all select
price,
id,
null as artist,
name,
author,
isbn,
null as actor,
null as director,
2 as clazz_
from
Book
union
all select
price,
id,
null as artist,
name,
null as author,
null as isbn,
actor,
director,
3 as clazz_
from
Movie
) i1_0
where
i1_0.id=?
2. @MappedSuperclass
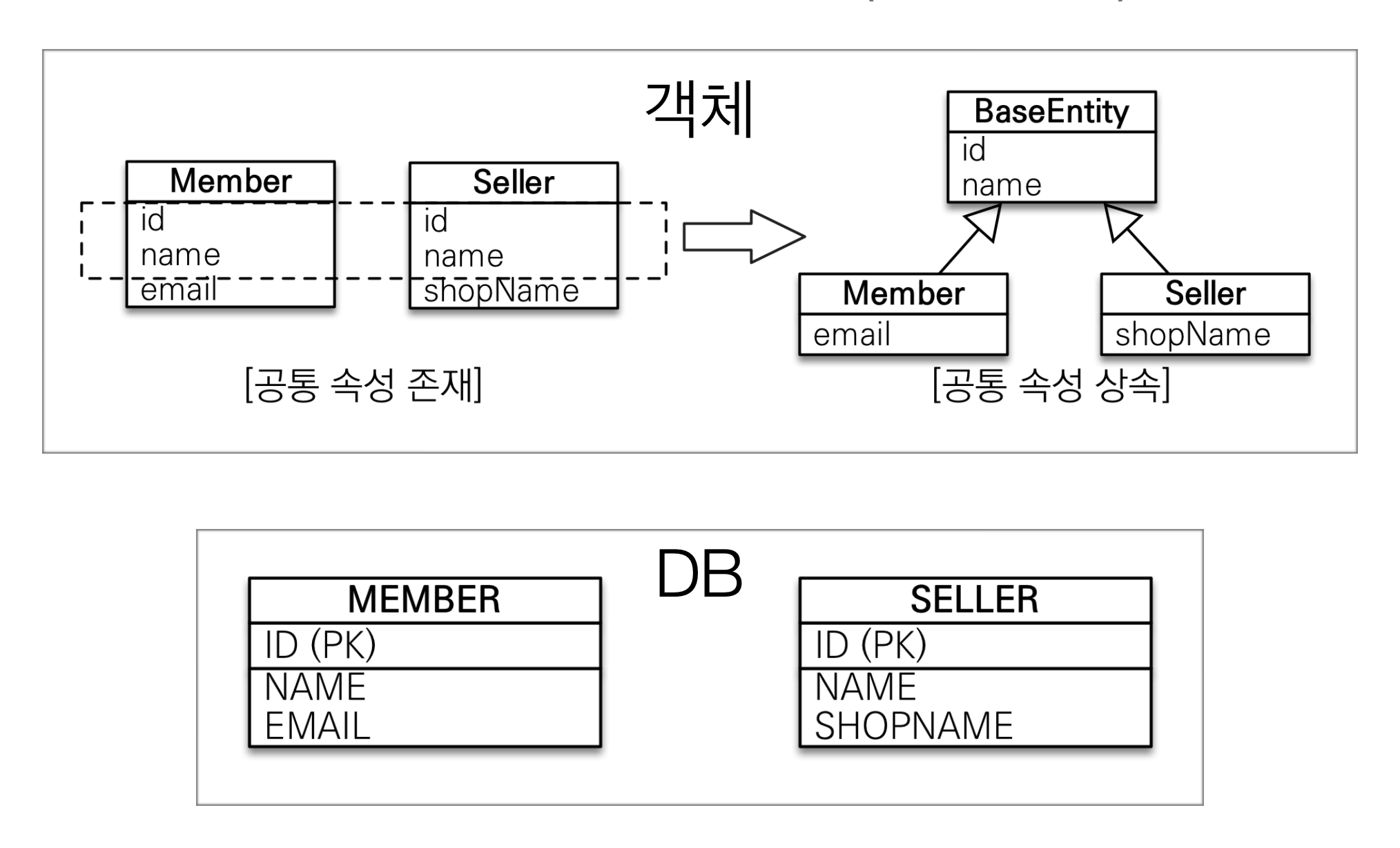
이런식으로 DB 는 따로 설계 했으나 객체 지향적으로 id, name 필드가 같으니 하나로 묶을 수 있다고 생각이 된다면 이때 사용하는 어노테이션이다.
즉, 공통 매핑 정보가 필요할 때 사용(id, name)한다.
만약 DBA 가 모든 사용자에는 생성 날짜, 수정 날짜, 생성인, 수정인 이 있어야한다고 가정할 때 모든 객체에 해당 필드를 넣는건 개발자가 아니기 때문에 따로 공통된 부분을 묶어서 객체를 생성해준다.
@Data
@MappedSuperclass
public class UpdateTime {
private String createBy;
private LocalDateTime createdDate;
private String modifiedBy;
private LocalDateTime modifiedDate;
}@Data
@Entity
public class Member extends UpdateTime{
...
}공통되는 부모 클래스에 MappedSuperclass 를 넣어주고 자식 클래스에서는 그냥 extends 만 해주면 된다.
참고로 JPA 에서 event 기능으로 create by 나 수정 시간은 나중에 편리하게 어노테이션 하나로 다 된다.
-
정리
• 상속관계 매핑X
• 엔티티X(@Entity 안 들어감.), 테이블과 매핑X
• 부모 클래스를 상속 받는 자식 클래스에 매핑 정보만 제공
• 조회, 검색 불가(em.find(BaseEntity) 불가)
• 직접 생성해서 사용할 일이 없으므로 추상 클래스 권장
• 테이블과 관계 없고, 단순히 엔티티가 공통으로 사용하는 매핑 정보를 모으는 역할
• 주로 등록일, 수정일, 등록자, 수정자 같은 전체 엔티티에서 공통 으로 적용하는 정보를 모을 때 사용 -
참고: @Entity 클래스는 또다른 @Entity나 @MappedSuperclass로 지정한 클래스만 상속 가능
3.
