
1. 이미지 수집
- 키워드로 폴더생성 (해당 폴더의 존재여부 판단)
- 폴더 내 이미지를 저장
1. urlretrieve
- 이미지 주소만 있다면 해당 이미지를 다운해주는 라이브러리
from urllib.request import urlretrieve - urlretrieve(이미지 주소, 저장위치)
- 이미지 주소 : 다운로드 받을 실제 이미지 URL
- 저장위치 : 파일명.확장자 or 특정 폴더명 / 파일명.확장자
imgUrl = "원하는 이미지의url"
saveDir = "test.jpg"
urlretrieve(imgUrl, saveDir)os객체를 이용하여 폴더를 만들어서 거기에 이미지 저장
- 매개변수로 검색할 키워드를 받아 폴더가 존재한다면 실행하지 않고 존재하지 않다면 폴더를 생성
def createDirectory(keyword):
if os.path.isdir(keyword) == False:
os.mkdir(keyword)
print(f"{keyword} 폴더 생성 완료")
else:
print(f"{keyword} 폴더는 이미 존재합니다")2. 실습
1. get url
keyword = "빅토리아시크릿 쇼"
img_url = f"https://search.naver.com/search.naver?where=image&sm=tab_jum&query={keyword}"
driver = wb.Chrome()
driver.get(img_url)
time.sleep(1)2. 스크롤 끝까지 내리기
for i in range(10):
driver.find_element(By.TAG_NAME, value="body").send_keys(Keys.END)
time.sleep(1)3. img 태그 수집 및 저장할 배열 초기화
imgs = driver.find_elements(By.CSS_SELECTOR, value="img._image._listImage")
imgUrlList=[]4. 추출한 이미지 배열에 저장
for img in tqdm(imgs):
imgUrlList.append(img.get_attribute('src'))5. 폴더생성 및 이미지 저장
createDirectory(keyword)
pic_num = 1
for url in tqdm(imgUrlList):
# url이 'data'로 시작하는 값은 저장되지 않도록 조건문 추가
if url.startswith("data"):
continue
else:
saveDir = f"{keyword}/{keyword}{pic_num}.jpg"
urlretrieve(url, saveDir)
pic_num += 16. 웹 드라이버 종료
driver.quit()3. 기타
- 구글을 네이버와 달리 페이지 형식이 다르기 때문에 이미지를 클릭 후 해당 이미지의 src값을 가져와야 url을 무사히 가져올 수 있다.
2. 네이버 지도 데이터 수집
1. 네이버 지도 HTML 분석
1. iframe 구조
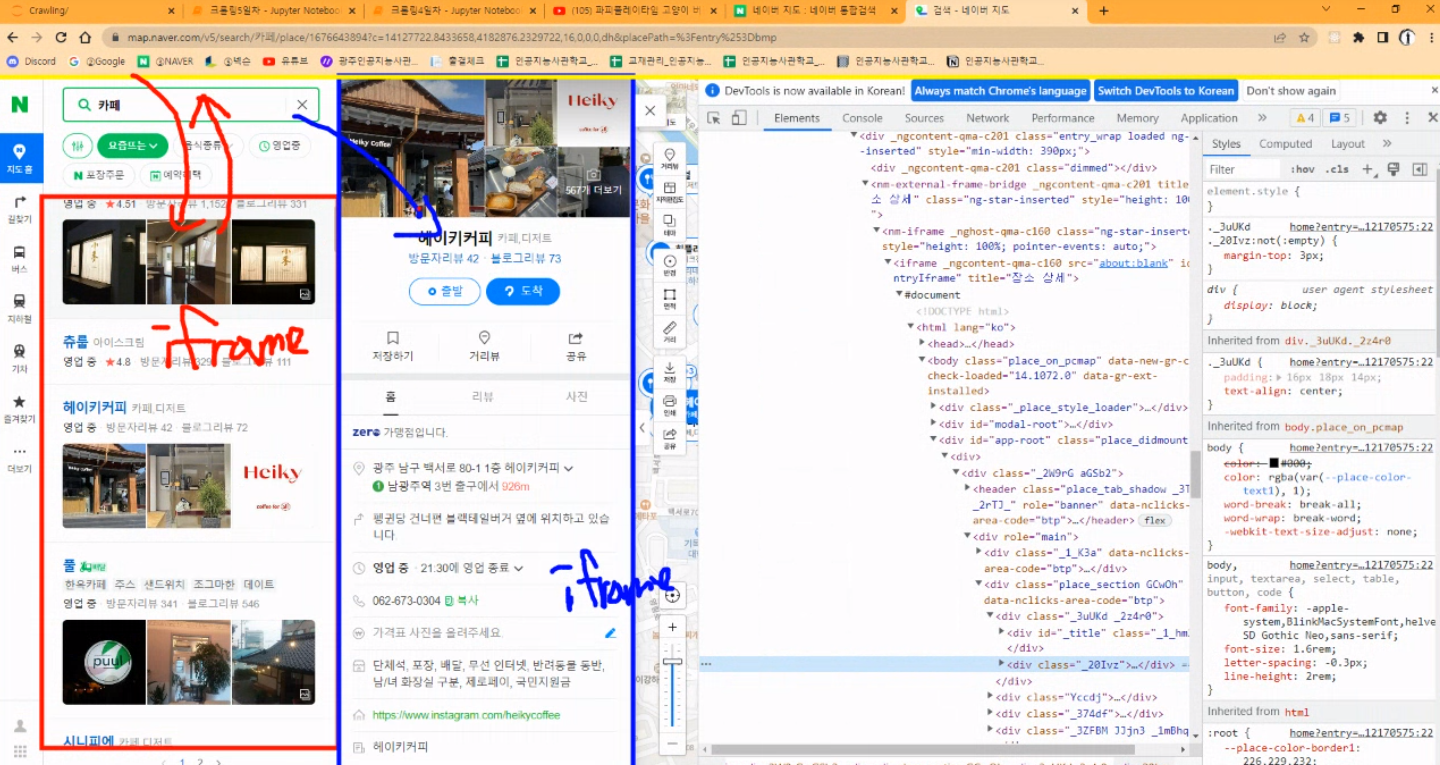
2. id 값
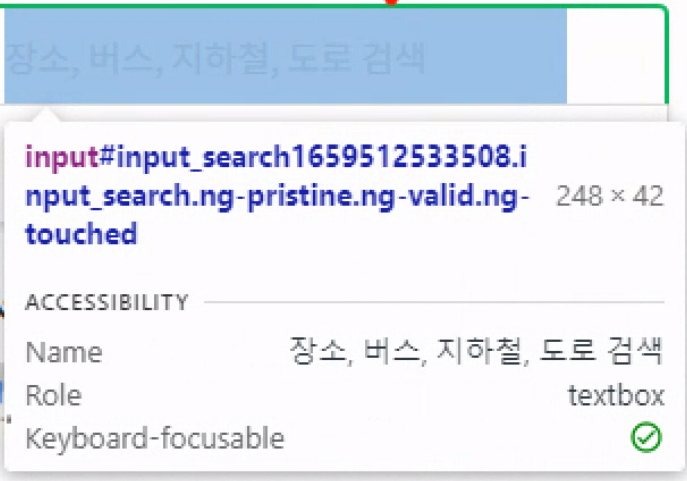 입력창의 id 값이 이러한 숫자들이 붙어있다면 안 찾아질 확률이 높으므로 그냥 class 이름으로 찾는것이 좋다.
입력창의 id 값이 이러한 숫자들이 붙어있다면 안 찾아질 확률이 높으므로 그냥 class 이름으로 찾는것이 좋다.
- 검색결과 페이지에서 가게별 정보 데이터 수집
2. driver.switch_to
- 프레임 전환 방법으로 주로 iframe의 url을 가져오기 위해 사용된다.
1) 원하는 iframe으로 전환
driver.switch_to.frame("iframe 명")2) 최초 url로 전환
driver.switch_to.default_content()3) tab 전환
driver.switch_to.window4) 창 전환
driver.switch_to.alert3. 실습
1) url get (최초 페이지)
map_url="https://map.naver.com/v5/?c=14128481.8864457,4183753.1546020,16,0,0,0,dh"
driver = wb.Chrome()
driver.get(map_url)2) 검색 후 로딩
driver.find_element(By.CLASS_NAME, value='input_search').send_keys("카페\n")
time.sleep(3)3) 검색 결과 프레이으로 전환 후 배열변수 만들기
driver.switch_to.frame("searchIframe")
stores = driver.find_elements(By.CSS_SELECTOR, value="a._3nCBm")for-1) 가게명 클릭
for i in range(len(stores)):
stores[i].click()for-2) 최초프레임으로 전환 후 상세프레임으로 전환
- 이때 iframe -> iframe으로 갈 수 없다. 반드시 default url으로 나온 후 다시 들어가야만 한다!!
driver.switch_to.default_content()
time.sleep(1)
driver.switch_to.frame("entryIframe") for-3) 데이터 수집
title = driver.find_element(By.CSS_SELECTOR, value="span._3XamX").text
print(title)for-4) 다시 최초프레임으로 전환 -> 겸색 결과 프레임으로
driver.switch_to.default_content()
driver.switch_to.frame("searchIframe")
time.sleep(1)


智(지)! 德(덕)! 體(체)!