
numpy
7. numpy 조건 함수
- 조건을 가져다 index에 넣어버리면 자동으로 indexing 다시 실행됨.
- 이때 1, 0로 결과값을 반환받고싶다면 조건을 작은 것 부터 먼저 실행해야한다.
score = np.array(np.random.randint(50,100, size=8))
score[score < 70] = 0
score[score >= 70] = 1
# result
## array([0, 0, 1, 0, 1, 1, 1, 1])8. 범용함수
arr30 = np.array([3,4,2,3,6,5])
arr31 = np.array([3,7,8,4,6,9])
arr32 = np.array([[3,4,2,3,6,5],
[3,7,8,4,6,9]])
arr33 = np.array([[1,2,3,4,5,6],
[7,8,9,1,0,2]])- 위와 같이 함수가 있다고 가정할 때
1) sum 함수
- 파이썬 내장함수를 써도 된고 numpy 함수를 써도 된다.
print(arr30.sum())
print(np.sum(arr30))
print(arr32.sum())
print(np.sum(arr32))
# result
## 23 23 60 602) mean 함수
- 마찬가지로 파이썬 내장함수 or numpy 함수를 써도 된다.
print(arr30.mean())
print(np.mean(arr30))
print(arr32.mean())
print(np.mean(arr32))
# result
## 3.83... 3.83... 5.0 5.03) sqrt 함수
- 제곱근을 반환하는 함수이다. 즉, 루트를 씌우는 함수.
- 그럼 왜 쓸까? : 어떤 AI 모델을 평가할 때 결과값을 명확하게 보기위해 제곱을 한다. 하지만 제곱은 실제 값이 아니므로 다시 루트를 해줘야한다.
print(np.sqrt(arr30))
print(np.sqrt(arr32))
# result
## [1.73205081 2. 1.41421356 1.73205081 2.44948974 2.23606798]
[[1.73205081 2. 1.41421356 1.73205081 2.44948974 2.23606798]
[1.73205081 2.64575131 2.82842712 2. 2.44948974 3. ]]4) abs 함수
- 배열 요소의 절대값을 계산해주는 함수
arr34 = np.array(np.random.randint(-10,10,size=8))
array([ 2, 2, 8, -7, -10, -2, -5, 1])
# result
np.abs(arr34)
array([ 2, 2, 8, 7, 10, 2, 5, 1])5) maximum, minimum
- 2개의 배열의 같은 위치의 값들 중 큰(작은) 값을 반환
arr30 = np.array([3,4,2,3,6,5])
arr31 = np.array([3,7,8,4,6,9])
# result
array([3, 7, 8, 4, 6, 9])6) isnan
- 배열에서 결측치가 있는 요소를 검색
- 결측치(null) : 값이 없는 것.
결측치를 처리하는 방법
채우는 방법 : 데이터가 적거나 결측치가 많은 경우
삭제하는 방법 : 데이터가 많거나 결측치가 적은 경우
arr35 = np.array([30, np.nan, 20, np.nan, 50, np.nan, 30])
arr35[np.isnan(arr35)]=arr35[np.isnan(arr35)==False].mean()
# result
array([30. , 32.5, 20. , 32.5, 50. , 32.5, 30. ])7) unique
- 배열에서 중복된 값을 제거
np.unique(ratings[:,0])8) 기타 함수
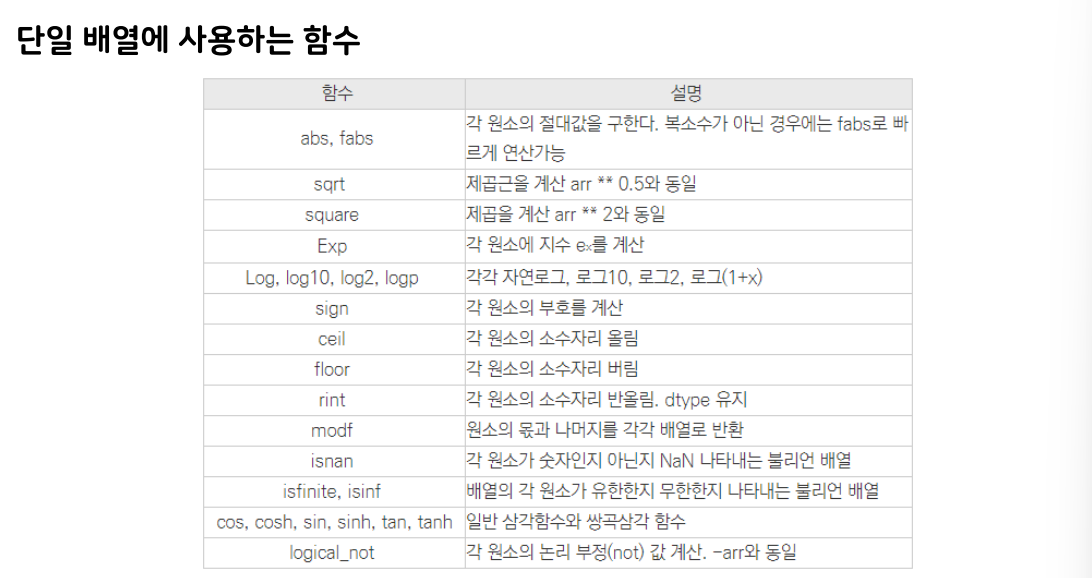

9. 파일 데이터 불러오기
- numpy에서 텍스트 파일을 읽어주는 함수 : np.loadtxt()
delimiter = "원하는 값" : data에서 원하는 값을 제거해서 읽는다.
path = "본인이 원하는 경로"
data = np.loadtxt("path", delimiter=",")10. 파일 데이터 저장하기
- np.savetxt() : 파일로 저장
delimiter="," 저장할 때 각 값들을 ,로 구분해서 저장
fmt : 저장한 데이터의 포맷
fmt="%.3f" : 소수점 3째자리 까지만 저장
path = "본인이 원하는 경로"
np.savetxt("path", 파일명, delimiter=",", fmt="%.3f")
智(지)! 德(덕)! 體(체)!