
Numpy
- 빠르고 효율적인 벡터 산술 연산을 제공하는 다차원 배열 제공(ndarray class), 고속의 연산속도를 지원
- 반복문 없이 전체 데이터 배열 연산이 가능한 표준 수학 함수, 고차원 수학 계산용 라이브러리
- 선형대수, 난수 생성, 푸리에 변환, 다양한 수학 함수들을 제공
1. ndarray class
- 동일한 자료형을 가지는 값들이 배열 형태로 존재
- N차원 형태로 구성이 가능
- 각 값들은 양의 정수로 index 부여
- ndarray를 줄여 array로 표현한다.
2. 생성 및 수정
1) 1차원 배열 생성
- 리스트를 기반으로 생성
- np.array() : 배열을 생성하는 함수
arr1 = np.array([1,2,3,4,5])2) 2차원 배열 생성
- 각 행의 열의 개수를 동일하게 설정
arr2 = np.array([[20,30,40,50],
[60,70,80,90]])(1) zeros
- zeros((행, 열)) : 행과 열 크기의 행렬을 생성하고 0.0으로 초기화
(2) ones
- ones((행, 열)) : 행과 열 크기의 행렬을 생성하고 1.0로 초기화
(3) full
- full((행, 열), 값) : 행과 열 크기의 행렬을 생성하고 값으로 초기화
arr5 = np.full((3,4),10)
# result
## array([[10, 10, 10, 10],
[10, 10, 10, 10],
[10, 10, 10, 10]])3) 1차원 배열 생성 후 2차원으로 수정하여 생성
(1) np.arange
- np.arange(시작값, 끝값+1, 증가값) : 시작값부터 끝값까지 증가값만큼 증가시켜가면서 해당 숫자의 배열을 생성
- 시작값을 생략하면 0부터 시작
- 증가값을 생략하면 1로 설정
arr6 = np.arange(1,10,1)
# result
## array([1, 2, 3, 4, 5, 6, 7, 8, 9])(2) .reshape
- 배열명.reshape(행 index, 열 index)
- 변경 전과 변경 후의 size값이 같아야함.
- 이때 행이나 열을 -1로 준다면 반대값에 따라 자동으로 부여됨.
arr15 = np.arange(15).reshape(-1,5)
# result
## array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])(3) flatten()
- 1차원으로 변환하는 함수
arr16 = (np.array([[1,2,3],[4,5,6]])).flatten()
# result
## array([1, 2, 3, 4, 5, 6])(4) ravel()
- 다차원 배열을 1차원 배열로 전환
arr17 = (np.array([[1,2,3],[4,5,6]])).ravel()
# result
## array([1, 2, 3, 4, 5, 6])3. 확인
1) shape
- 배열의 크기를 확인하는 함수
arr2.shape
#result
## (2, 4)- 데이터 분석에서 (행, 열)
- 행 : 데이터의 개수
- 열 : 특성의 개수
2) size
- 배열의 요소의 개수를 확인하는 함수
arr2.size
#result
## 83) dtype
- 배열의 type을 지정하는 함수 이때, 배열은 자바의 배열처럼 1가지의 type으로밖에 지정할 수 없다.
# data type을 확인하는 방법
arr2.dtype
#result
## dtype('int32')
# data type을 지정하는 방법, 다음과 같이 버림연산으로 사용 가능.
arr9 = np.array([1.2,2.3,3.4,4.5], dtype=np.int64)
#result
## array([1, 2, 3, 4], dtype=int64)4) ndim
- 배열의 차원을 확인하는 함수
arr2.ndim
#result
## 25) astype
- 기존 배열의 data type을 change : astype(원하는 dataype)
arr9 = arr9.astype(str)
#result
## array(['1', '2', '3', '4'], dtype='<U11')
4. Random
-
배열의 요소를 임의의 값으로 할당
- rand(행, 열) : 해당 행과 열 크기의 배열에 0-1 사이의 실수의 숫자를 할당
- randint(시작값, 끝값+1, size=(행, 열)) : 시작값~끝값 사이의 정수를 할당
-
배열을 이용한 문제풀이는 추후 포스팅
5. 연산
- 같은 위치의 요소들끼리 연산이 가능
arr21 = np.array([10,20,30,40])
arr21+arr21
#result
## array([20, 40, 60, 80])6. 인덱싱과 슬라이싱
- 그냥 python의 indesing slicing과 매우 유사
1) 1차원
- arr[행,열]
- arr[시작:끝+1]
- arr[시작:끝] = 값 => 구간 내 value가 전부 지정 값으로 바뀜.
- 시작 인덱스를 생략하면 0부터 시작이고 끝을 생략하면 끝까지
2) 2차원
-
arr[시작:끝+1, 시작:끝+1]
-
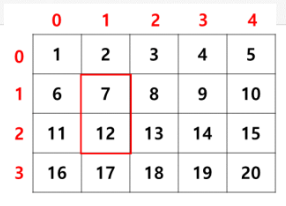
arr23 = np.arange(1,21).reshape(4,-1)
A=arr23[:,0]
B=arr23[1:3,1:3]
C=arr23[-1,:]
print(A,B,C,sep='\n')
#result
##
[ 1 6 11 16]
[[ 7 8]
[12 13]]
[16 17 18 19 20]3) boolean 인덱싱
- 조건에 맞는 요소만 가져오는 것
# 8개의 요소가 들어가는 랜덤 배열 생성
score = np.array(np.random.randint(50,100, size=8))
# 조건에 충족하는 요소들만 출력
score > 80
score[score>=80]
#result
## array([84, 83, 99, 91])score = np.array(np.random.randint(50,100, size=8))
score[score > 70] = 0
score[score <= 70] = 1
#result
## array([1, 1, 1, 1, 1, 1, 1, 1])
智(지)! 德(덕)! 體(체)!