
반복문, 딕셔너리
-
아직도 자바처럼 코드를 짜는 습성이 있다. python언어는 python 언어만의 장점을 살리자!
-
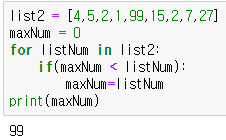
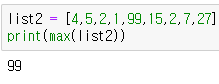
max값 찾기
-
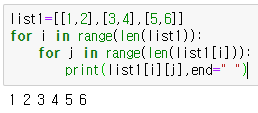
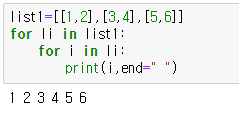
2차원 배열 출력
1. 반복문
1) for문
- for문에서 in 다음에 list를 쓰게 되면 알아서 java의 향상된 for문(for each문) 처럼 한개씩 가져와서 처리한다.
- 이는 문자열, 리스트, 튜플 모두 처리할 수 있다.
hi = "안녕하세요"
for i in hi:
print(i, end=' ')
#result
안 녕 하 세 요- python의 for문은 강력해서 인덱스를 한번에 2개를 꺼내올 수 있다.
list1=[[1,2],[3,4],[5,6]]
# 이 원리를 이용하여
a,b=[10,20]
print(a)
print(b)
for i,k in list1:
print(i)
print(k)
# 단, "정방형" data일때만!!2) range
- for문에서 range는 해당 숫자만큼이 아닌 해당 숫자만큼의 반복을 의미한다 즉, range 3일 경우 0,1,2,3 이 아닌 0,1,2에서 그치게 된다.
- 또한 증가량을 조작할 수 있고 시작점과 끝점을 조절할 수 있다.
range(1, 10, 1) => 1부터 9까지 1씩 증가
range(1, 100, 3) => 1부터 99까지 3씩 증가
range(10, 1, -1) => 10부터 2까지 1씩 감소- range(시작값 (기본값=0), 종료할 숫자, 증가값 (기본값=1))
여기서 말한 기본값은 default 즉, 쓰지 않아도 자동으로 들어가는 값을 말한다. - 증가값이 1이 아닐경우 시작값은 생략을 할수 없음! 즉, 증가값이 생략이 되어있어야만 시작값이 생략된다.
for i in range(,10,2):
print(i)
# result
Input In [24]
for i in range(,10,2):
^
SyntaxError: invalid syntax2. 딕셔너리
- dictionary는 key와 value를 갖는 한쌍의 자료형
- dictionary type은 innutable한 key와 mutable한 value로 mapping되어있는 unordered set이다.
1) 특징
- key값으로 숫자를 지정할 수도 있지만 키값은 항상 마지막의 것이 반영된다.
2) 추가, 수정
- 딕셔너리명[key] = value
- 추가와 수정의 문법은 완전히 동일하며 차이는 key값이 신규나 기존에 존재하냐에 차이이다.
3) 호출
- dic5['name']
dic5.get('name') - 2가지 방법 모두 가능. 하지만 index로 불러오는 것과 get함수로 불러오는 것의 차이는 error의 유무이다. index로 호출한는 것은 Keyerror을 일으키지만 get함수는 None을 return할 뿐이다. 이것을 이용하여 또다른 코드를 짤 수 있다.
- dictionary 도 마찬가지로 for-each문으로 값을 동시에 불러올 수 있다. 하지만 이땐 items()라는 함수를 써준 후 리스트화 하여 불러와야 한다.
for key, value in listName.items():
print(key, value)4) 삭제
- del 딕셔너리명[key]
5) in
- key in dictionaryName
in은 dictionary의 키에 한에서만 동작한다.
3. 기타
- expected an indented block
들여쓰기 error - In [*] => 계속 실행중이다 따라서 Kernel 에 들어가서 restart를 눌러줘야 함.
- 변수를 선언할 때 색깔이 바뀌는 단어는 되도록 사용하지 않는것이 좋다. 예약어 이어서 충돌할 수 있기 때문이다.

智(지)! 德(덕)! 體(체)!