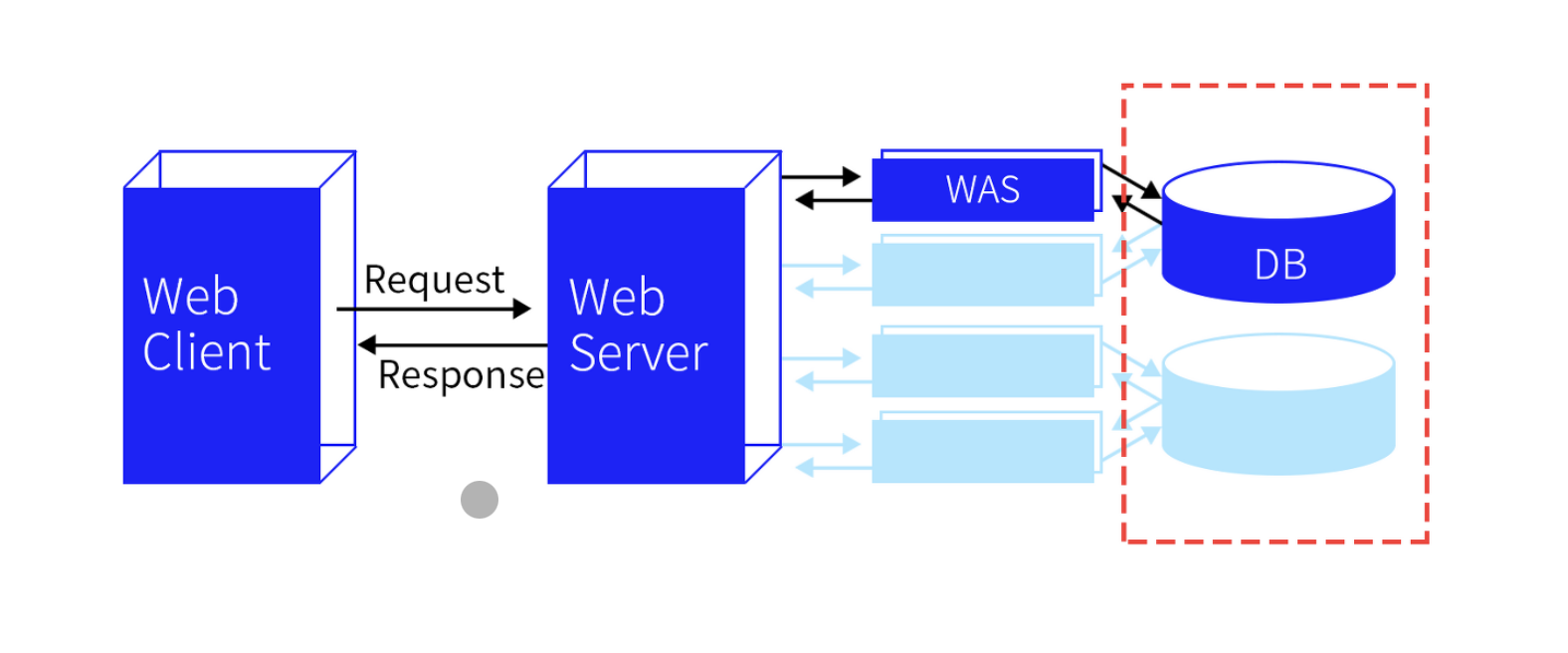
1. 웹이 작동하는 방식
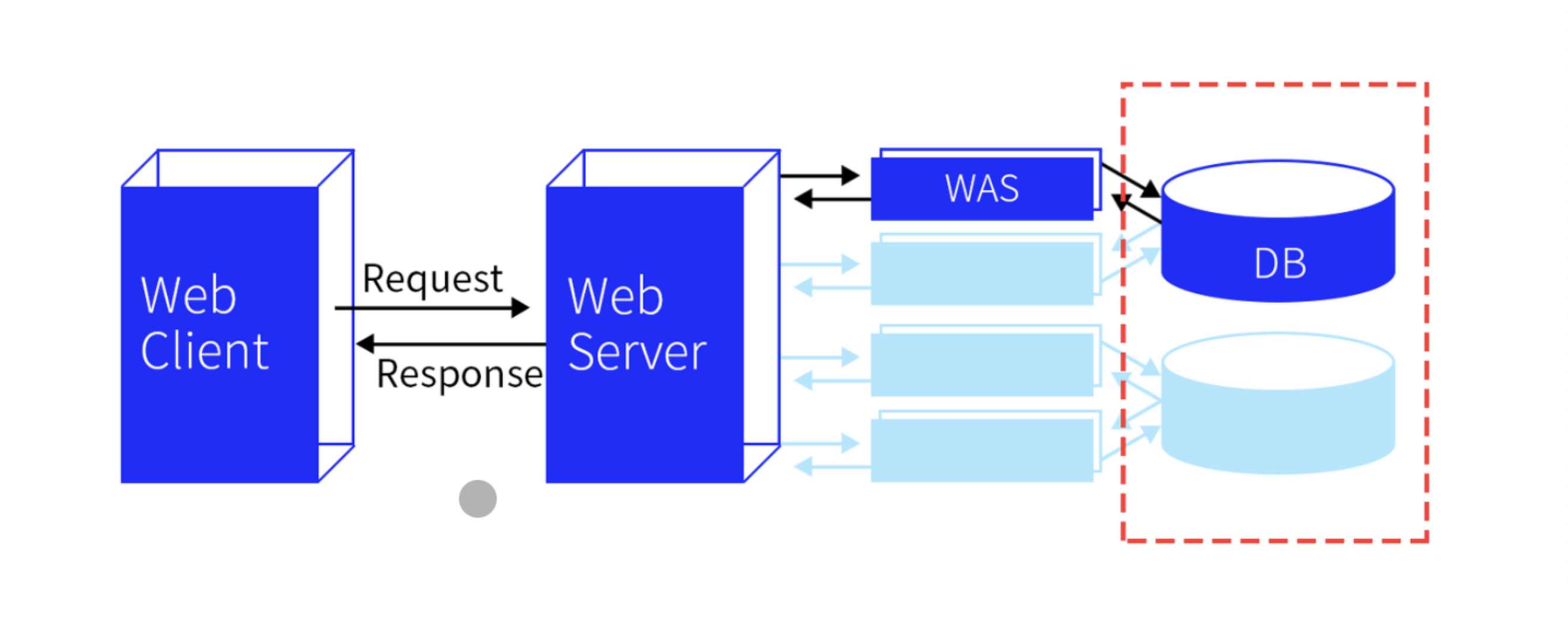
웹 클라이언트
- 사용자가 웹에 접근하는 프로그램
- 우리가 아는 크롬, 사파리 등등
웹 서버
- 웹 페이지, 사이트 또는 앱을 저장하는 프로그램
- 서버는 클라이언트에서 요청한 HTTP 메세지를 확인한 후, 이에 맞는 데이터를 처리한 뒤에 다시 클라이언트에 응답
WAS
- 웹 어플리케이션 서버로 이름에서 알 수 있듯이 사용자 컴퓨터나 장치에 웹 어플리케이션을 수행해주는 미들웨어
- 리퀘스트가 오면 서버는 요청에 필요한 페이지의 로직이나 데이터베이스의 연동을 위해 WAS에 처리를 요청
WAS는 동적인 페이지 처리를 담당하고 DB에서 데이터 정보를 받아옴
DB
- 데이터의 정보를 저장하는 곳
2. HTTP 메세지
HTTP
- 웹 브라우저와 웹 서버 간에 데이터를 주고 받기 위해 사용하는 인터넷 프로토콜
특징
- 클라이언트 / 서버 모델을 따름 : 서로 관계를 맺고 있는 컴퓨터 프로그램이 클라이언트와 서버로 구분이 됨
HTTP 메세지
- 요청 메세지 : 클라이언트가 서버에서 요청하는 메세지

- 메서드 : 어떻게 처리를 해야 하는지를 담고 있음
- GET : 존재하는 자원에 대한 요청
- POST : 새로운 자원을 생성
- PUT : 존재하는 자원에 대한 변경
- DELETE : 존재라는 자원에 대한 삭제
- 경로 : 가져오려는 리소스의 경로를 표시
- 프로토콜 버전 : HTTP 프로토콜의 버전을 표시
- 헤더 : 서버에 대한 추가 정보를 전달. 호스트의 정보나 접속하고 있는 사용자의 정보, 그리고 열려고 하는 페이지의 정보 등을 확인할 수 있습니다.
- user-agent : 웹 브라우저의 다른 표현. 요청하는 웹 브라우저의 정보 및 운영체제를 표시
- accep-encoding : 클라이언트가 이해할 수 있는 압축 방식을 표시. 이를 표시해서 서버에 전송하면 서버는 필요한 경우 리소스를 압축하여 반환
- 공백 라인 : 헤더와 본문 구분하는 역할
- 본문 : POST처럼 서버에 새로운 자원을 추가하는 경우에 들어가는 선택적인 요소- 응답 메세지 : 클라이언트의 요청을 해석한 서버가 응답하는 메세지

- 프로토콜 버전 : HTTP 프로토콜의 버전을 나타냄
- 상태 코드 : 클라이언트 요청의 성공 여부를 숫자로 나타낸 것
- 1xx (조건부 응답) : 요청을 받았으며 작업을 계속
- 2xx (성공) : 정상적으로 요청을 수행했을 때 나타나는 코드
- 3xx (리다이렉션 오류) : 클라이언트가 요청을 마치기 위해 추가 동작을 취해야 할 때 나타냄
- 4xx (요청 오류) : 클라이언트의 요청에 오류가 있을 때 나타나는 코드
- 5xx (서버 오류) : 서버가 들어온 요청을 수행하지 못했을 때 나타남
- 헤더
- content-type : 전달한 리소스의 타입.
- content-encoding : 응답 메세지의 헤더의 accept-encoding처럼 컨텐츠가 압축된 방식을 표시
-date : 해당 메세지가 만들어진 날짜와 시간을 포함
- 본문3. 프록시 서버
프록시
- 클라이언트와 서버 사이에서 HTTP 메세지를 대신 전달하는 중계 기능
특징
- 주고 받은 적이 있는 데이터의 사본이 있어서 다시 요청할 시 캐싱해 둔 데이터를 반환하여 전송시간을 줄일 수 있음
- 메세지가 지나갈 때마다 via 헤더에 정보를 추가해야 하는데, 프록시 서버의 정보 또한 기록되어 나중에 메세지 접근을 제어하거나 추적하는데 사용할 수 있음.
- 익명성을 보호
유형
- 포워드 프록시 : 서버의 메세지를 클라이언트에게 전달하는 역할 ⇒ 클라이언트에게 데이터를 전달
- 리버스 프록시 : 클라이언트의 요청을 다수 서버에 분배하여 전달하는 역할 ⇒ 앞에 있던 클라이언트가 뒤에 있는 서버에게 역으로 데이터를 전달
Via 헤더
- 해당 http 메시지가 거쳐온 프록시 또는 게이트웨이의 정보를 담고 있음
💡 [<프로토콜 이름 />]<프로토콜 버전> <호스트>[:<포트>] [<프로토콜 이름 />]<프로토콜 버전> <내부 프록시의 이름 or 별칭>
4. DNS
IP
- 인터넷 장치 각각을 식별할 수 있는 고유한 주소
- 인터넷 상에서 서로 데이터를 주고 받을 때 필요한 규약
- 종류
- IPv4
- IPv6
- 사설 IP 주소와 공인 IP 주소
라우터가 공공 IP 주소를 가지며 그 라우터에 속한 기기들은 각자를 구분하는 사설 IP 주소를 가짐
-LAN : 기기들이 연결된 지역 네트워크
-WAN : LAN들을 연결한 광역 네트워크
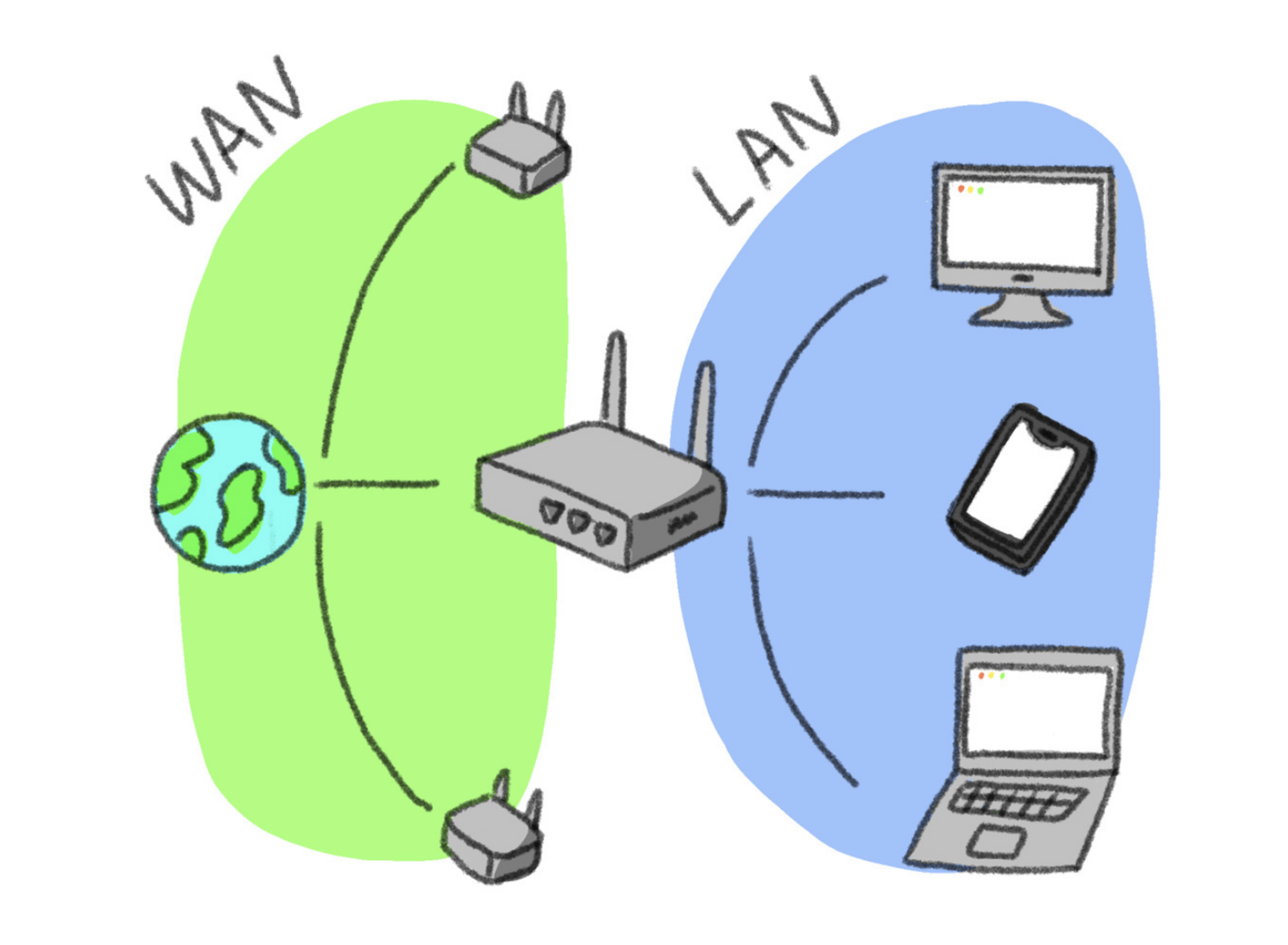
- 사설 IP로 통신하는 과정
라우터를 거치며 자동으로 공인 IP 주소로 변경하는데 이는 라우터에 내장된 NAT(network address translation)이 담당
도메인
- 외우기 힘든 IP 대신 사람이 기억하기 쉽게 만든 인터넷 주소
- 구성 요소
- 국가 도메인
- 일반 도메인
DNS
- 도메인 주소를 IP 주소로 변환해주는 역할을 하는 시스템
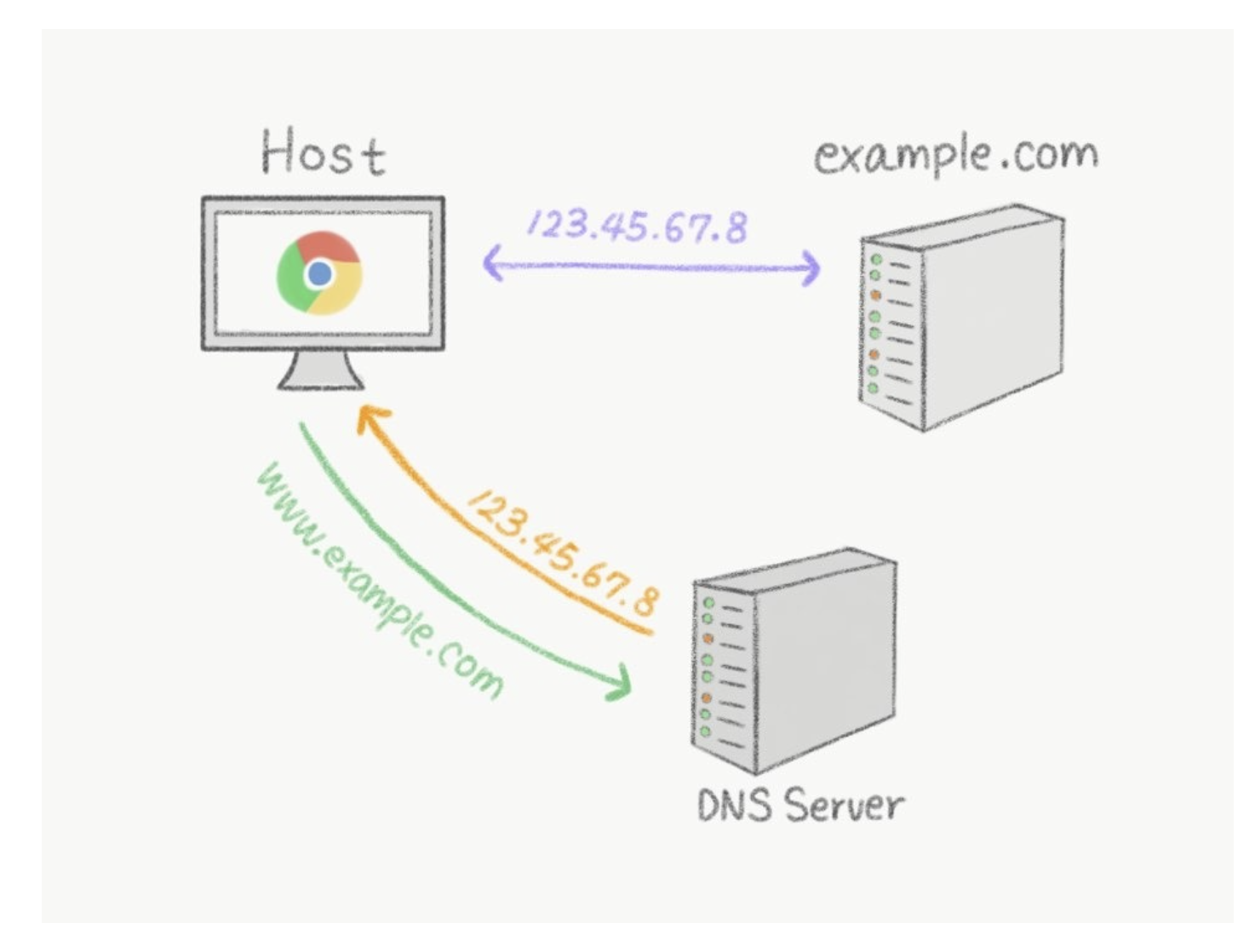
- DNS 서버는 평소에 수많은 도메인 이름들을 기억하다가 그에 맞는 IP 주소를 반환
5. TCP
우리가 네트워크에서 데이터를 주고 받는 과정에서 한꺼번에 많은 양을 하면 큰 과부하가 올 수 있기에, 패킷이라는 단위로 쪼개서 다양한 경로로 주고 받는다. 하지만 이 과정에서 쪼개진 패킷들이 제대로 도착했는지 그리고 순서대로 잘 들어왔는지를 파악해야 했음. 이를 해결하기 위해 사용된 프로토콜이 TCP!
- TCP의 기능
- 오류 없는 데이터를 전송
- 순서에 맞는 전달
- 조각나지 않는 데이터 스트림
- TCP/IP는 패킷 교환 네트워크 프로토콜의 집합
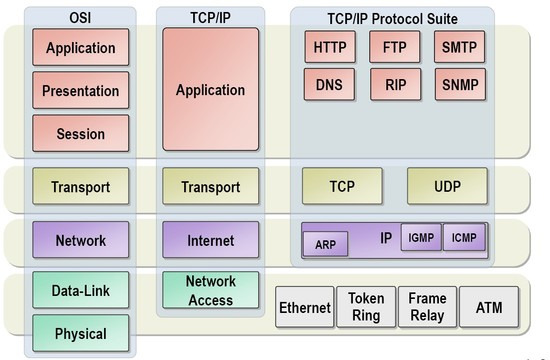
- TCP와 IP
IP는 적힌 IP주소와 일치하는 장소로 보내는 데만 집중 → 비연결형
TCP는 목적지에 데이터가 안정적으로 도착하는 데 집중. 그래서 수신자가 데이터를 받을 수 있는지를 계속 파악함 → 연결형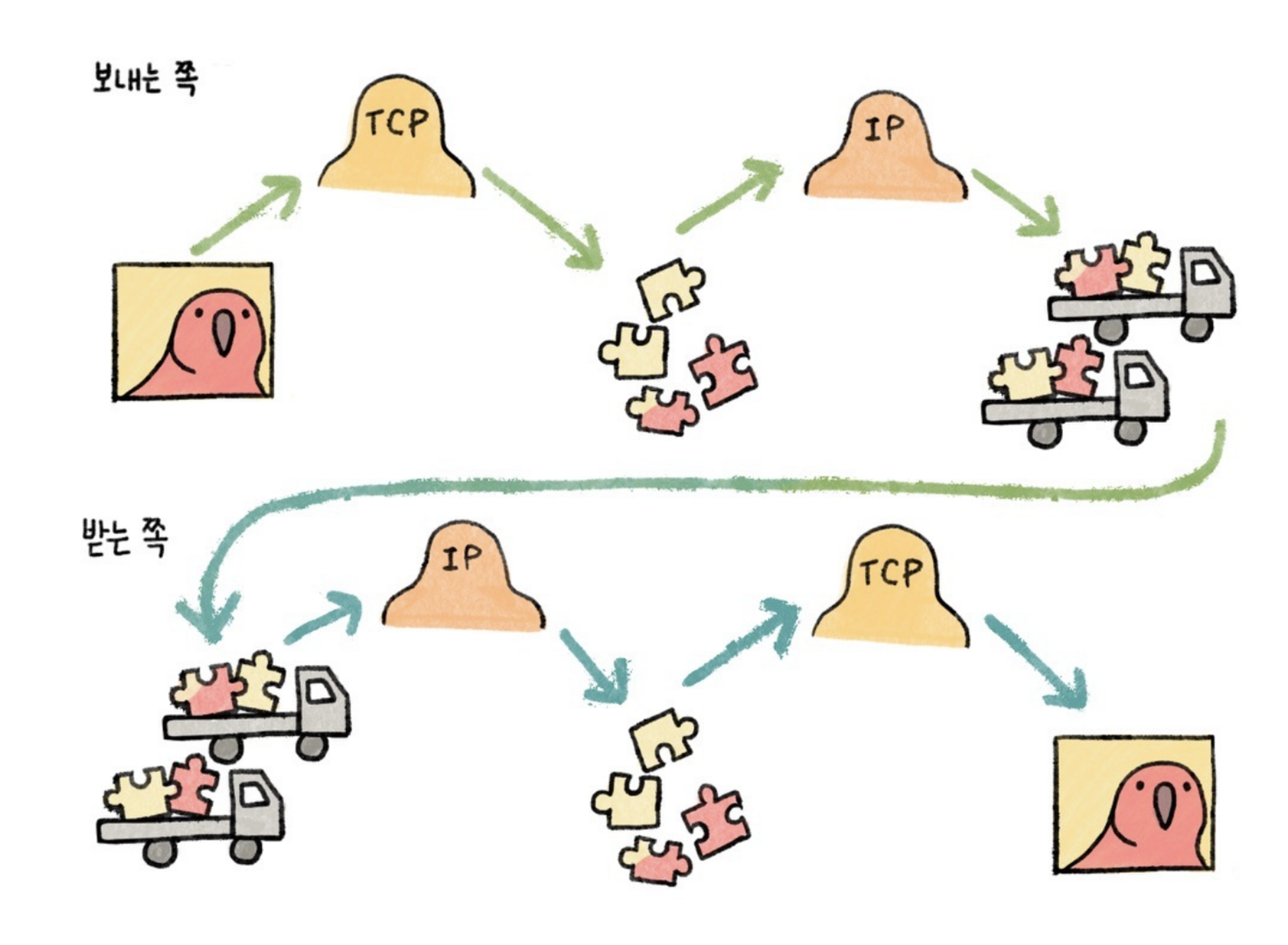
- 보내는 쪽 : 데이터에 대한 요청이 들어오면 TCP에서는 데이터를 적당한 크기의 패킷을 자르고 IP에 전달
받는 쪽 : IP는 도착한 패킷의 주소가 내 주소와 일치하는지 확인한 뒤 맞다면 받는 쪽 컴퓨터의 TCP로 전달하고, TCP는 받는 패킷을 다시 재조립
- UDP와 TCP
TCP의 단점으론 데이터 교환 과정에서 확인하는 게 많아서 전송 속도가 느림
UDP는 TCP보다 빠르지만, 3 웨이 핸드쉐이크 처럼 확인하는 과정을 스킵해서 데이터의 유실 가능성이 늘어나고 순서가 바뀔 위험이 있음
6. HTTP의 역사
HTTP/1.1
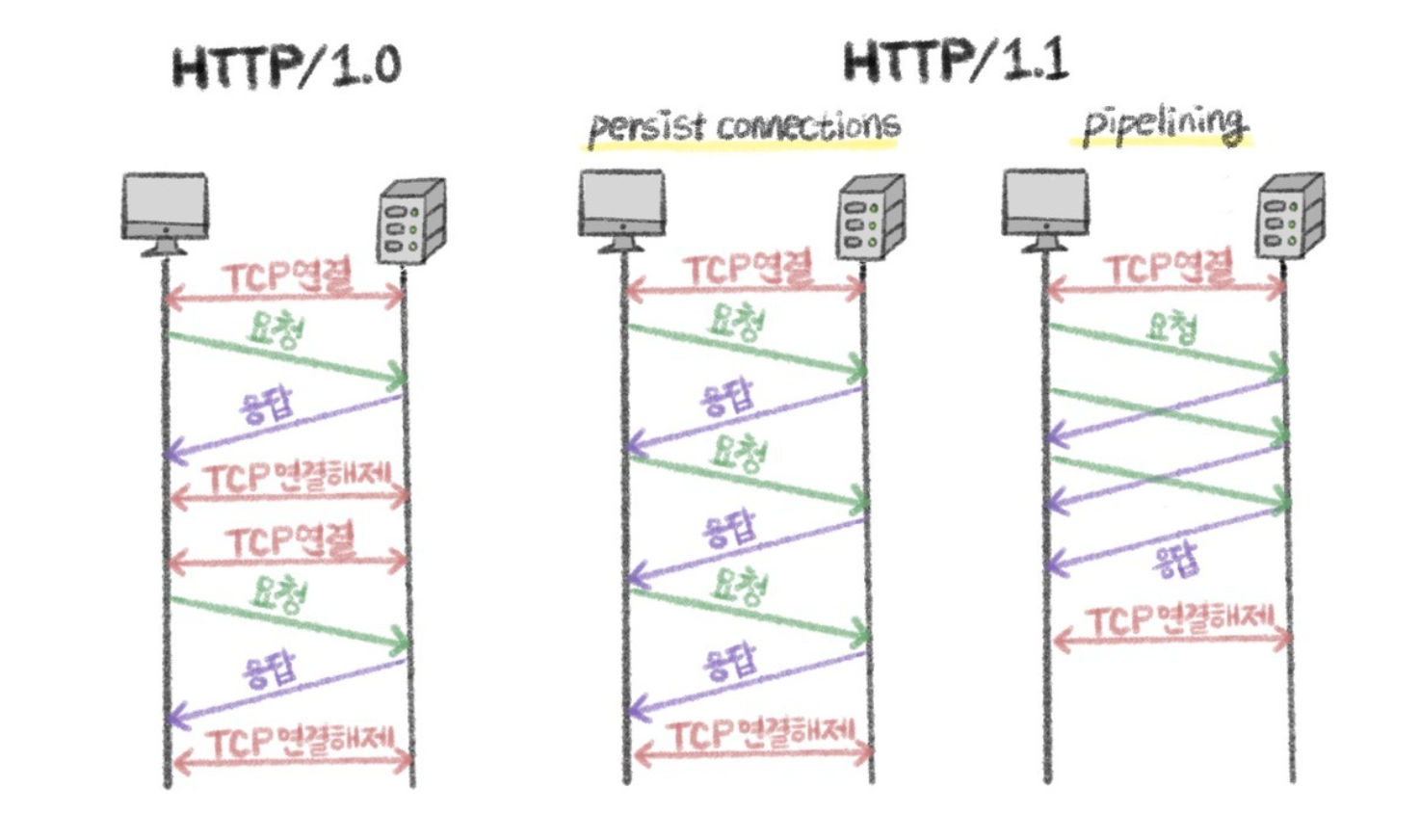
- 한 번 TCP 연결을 맺으면 끊지 않고 계속 유지할 수 있음
이로 인해 핸드쉐이크를 계속 하는 과정을 줄이고 안정적이고 속도감 있는 통신이 가능
HTTP/2
- 이전 버전에선 1:1 대응을 이루고 있어서 순서대로 처리가 되지 않으면 밀리는 문제가 생김
이를 고치기 위해 모든 요청과 응답을 병렬적으로 처리 → 더 높은 성능과 안정적인 처리 - 바이너리 프레이밍
텍스트 형식인 HTTP 메시지를 바이너리 형태로 캡슐화
HTTP/3
- TCP가 아닌 UDP 위에서 작동하는 방식인 QUIC를 적용
- 아직 draft 상태
7. WEB
웹 1.0
- 주로 읽기 전용
웹 2.0
- 양방향 소통이 가능해져 읽기와 쓰기가 가능해짐
- 하지만 소유권 문제에서 서비스에서 발생하는 데이터는 모두 기업이 소유하고, 이를 활용한 이익도 기업이 독점
웹 3.0
- 초기 시맨틱 웹에 초점 : 컴퓨터가 문장, 단어의 뜻을 이해하고 논리적인 추론을 하는 웹 기술
- 최근 탈중앙화에 초점 : 데이터를 일부 기업이나 플랫폼을 독점하는 현상에서 벗어남. 즉 일반 사용자들이 소유를 하는 형태
8. HTTPS, SSL, TLS
HTTPS
- http에서 보안이 강화된 프로토콜
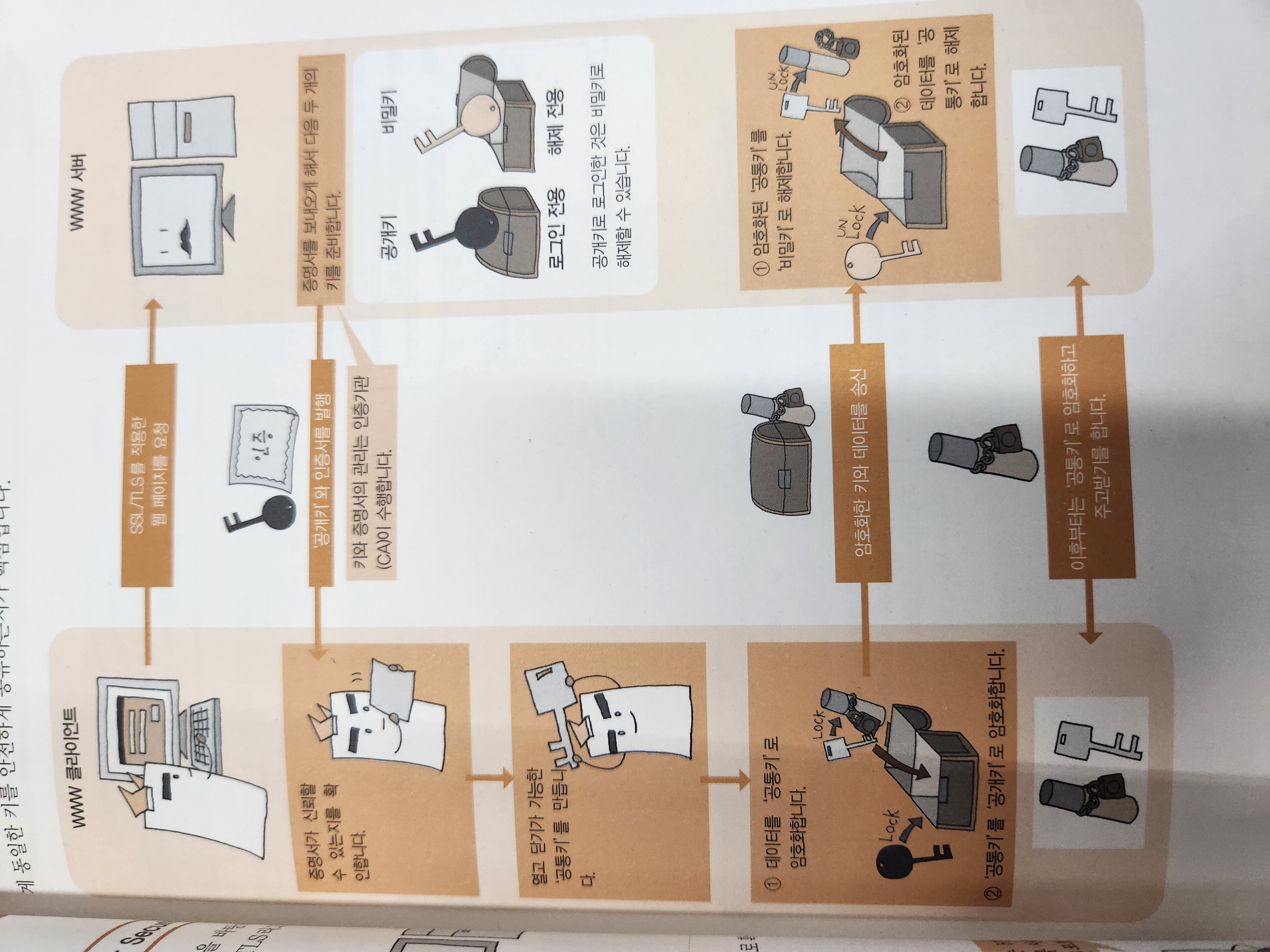
SSL/TLS
- 클라이언트와 서버가 서로 데이터를 암호화해 통신할 수 있도록 돕는 보안계층
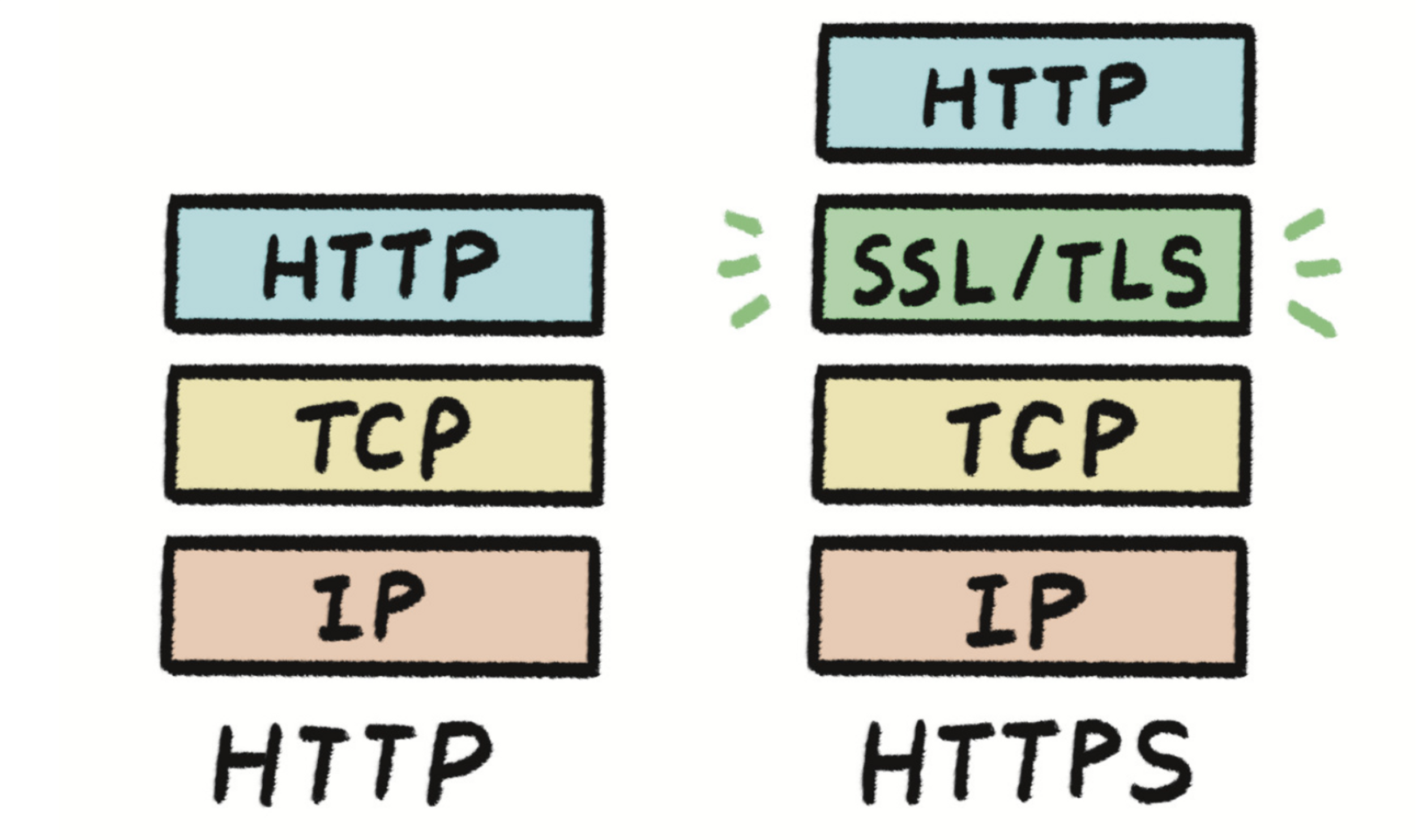
- tls는 ssl 3.0
암호화 기법
- 대칭키 : 하나의 키로 암호화와 복호화를 둘 다 할 수 있는 암호화 기법
공개키 : 서로 다른 키 두 개로 암호화, 복호화를 한다는 특징
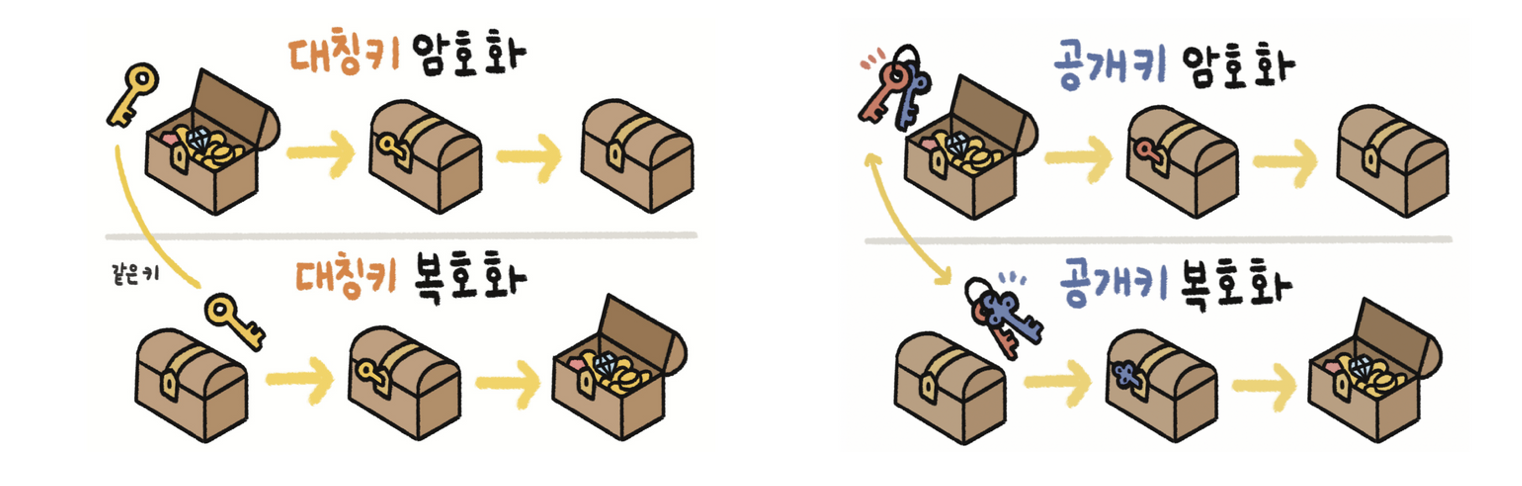
-출처: TCP/IP가 보이는 그림책(성안당)-
SSL 동작 과정
- 핸드 셰이크 → 세션 → 세션 종료

9. 쿠키
- 브라우저에서 서버로 요청이 있을 때 도메인 단위로 발급하는 작은 텍스트 파일
어떤 상태를 기억해야 할 대 매우 간단히 사용할 수 있음
웹사이트를 방문하거나 배너에 노출되거나 배너를 클릭하는 등 개발자가 사전에 설정해 놓은대로 유저의 디바이스의 특정 위치에 자동 저장
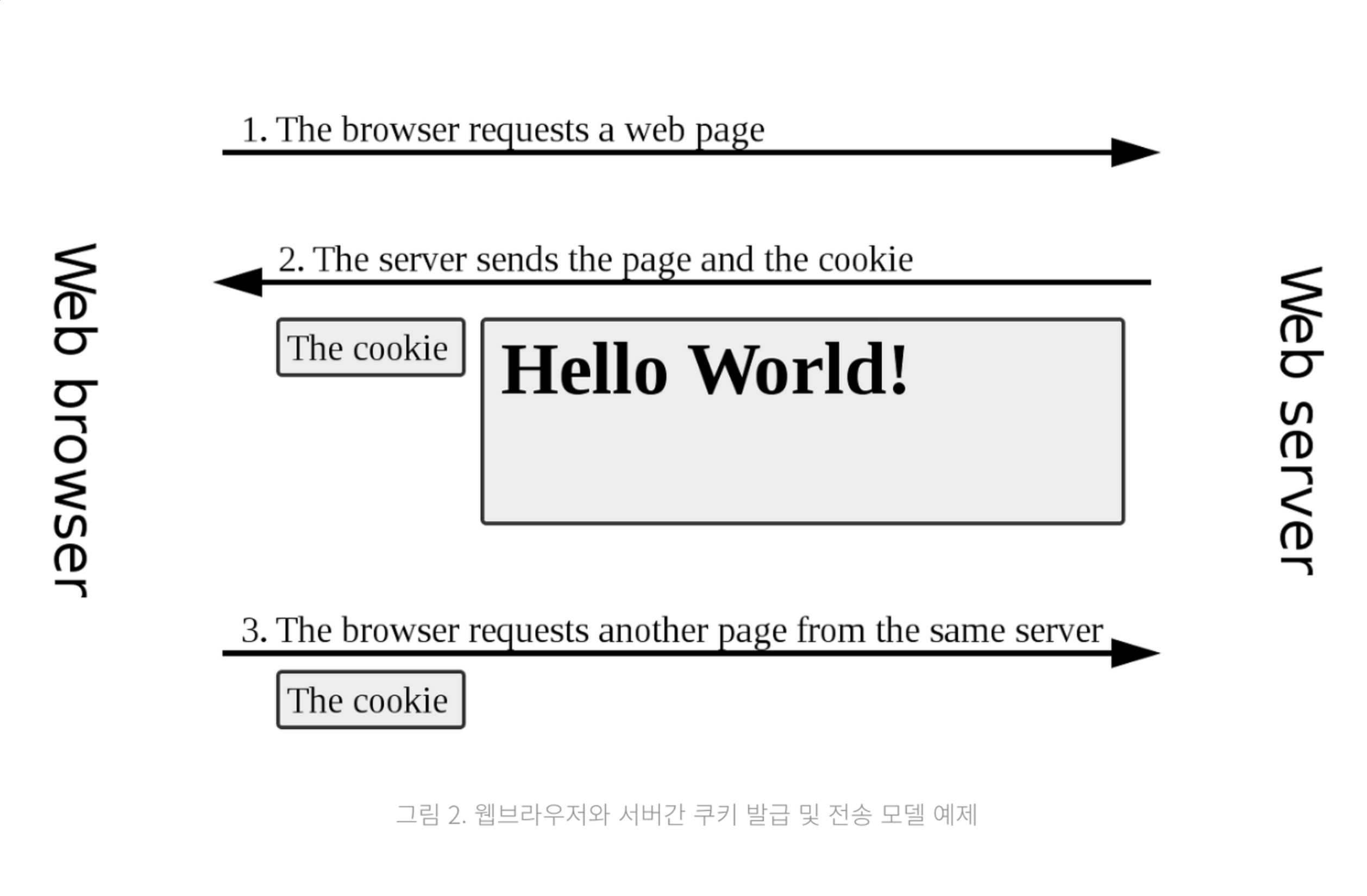
참고사항
해치지 않는 웹 네트워크 매거진
https://brunch.co.kr/magazine/webnetwork
42서울 카뎃 hoslim의 slack 정리노트

좋은 글이네요. 공유해주셔서 감사합니다.