배경

이전 글에서 티켓팅 서비스를 구현한 뒤 부하 테스트를 진행하면서 두 가지 동시성 문제를 발견했다.
그 중 첫 번째 문제를 다양한 방식을 비교해본 뒤 낙관적 락을 통해 해결했다.
이번에는 1인당 티켓 구매 제한 수량을 초과한 문제를 해결해보자.
테스트 환경 및 결과
테스트 환경 및 테스트 결과는 아래 링크를 통해 확인할 수 있다.
구매 제한 수량 초과 문제 해결하기

현재 시나리오에서는 1인당 최대 4매의 티켓을 구매할 수 있다.
하지만 이전에 진행한 부하 테스트 결과, 4매 보다 더 많은 티켓을 구매한 유저가 발생하였다.
왜 이러한 문제가 생겼는지 분석해보자.
원인 분석 - 결제 완료 API
구매 제한 초과 여부는 결제 완료 API에서 검사하고 있다. 아래는 결제 완료 API를 구현한 코드이다.
@Transactional
fun completePayment(req: PaymentCompleteRequest) {
// 1. 예매 조회
val reservation = reservationRepository.getById(req.reservationId)
/** 중간 로직 생략 */
// 2-1. 구매한 티켓 수 조회
val paidTicketCount = reservationRepository.getPaidTickets(reservation.roundId, req.userId).size
// 2-2. 구매 제한 초과 확인(구매 제한 수량 < 결제한 티켓 수 + 결제하려는 티켓 수)
val isCountExceed = performance.maxCount < reservation.tickets.size + paidTicketCount
if (isCountExceed) throw BusinessException(RESERVATION_COUNT_EXCEED)
// 3. 예매 확정 및 결제 완료
reservationRepository.save(reservation.confirm(/** */))
val payment = paymentRepository.getById(req.paymentId)
paymentRepository.save(payment.complete())
}결제 완료 API는 아래와 같은 과정으로 이루어진다.
- 예매 조회
결제한 티켓 수 + 결제하려는 티켓 수가 구매 제한을 초과했는지 확인- 예매 확정 및 결제 완료
이 과정에서 같은 유저가 동시에 결제 요청을 보내게 되면 어떻게 될까?
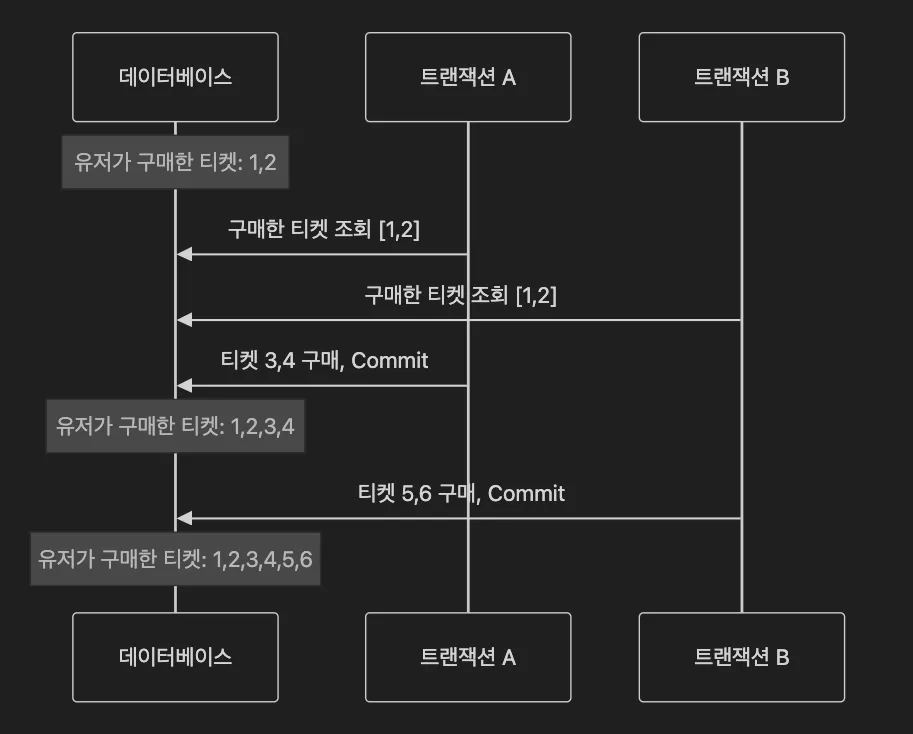
트랜잭션 A와 B가 동시에 구매한 티켓들을 조회하고, 구매 제한을 초과하지 않았기 때문에 두 트랜잭션 모두 결제 및 예매 완료 처리를 하게되며 1인당 구매 제한을 초과하는 문제가 발생하게 되었다.
이제 원인을 알았으니 해결 방법을 찾아보자.
해결 방법 1. 낙관적 락 → X
이전에 경험한 중복 예매 문제 처럼 낙관적 락을 적용하면 해결될까?
결론부터 말하자면 아니다. 낙관적 락을 적용하고 테스트를 진행한 결과는 아래와 같다.
| 테스트 회차 | 1차 | 2차 | 3차 | 4차 | 5차 | avg |
|---|---|---|---|---|---|---|
| 구매 제한 초과 | 0명 | 1명 | 1명 | 1명 | 0명 | 0.6명 |
왜 낙관적 락을 적용했는데 문제가 해결되지 않았을까?
낙관적 락은 업데이트 대상의 version 컬럼 정보를 통해 충돌을 감지한다. 그러므로 여러 트랜잭션이 동시에 같은 row를 업데이트 하는 경우에 효과가 있다.

하지만, 결제 완료 API는 구매한 티켓 수를 확인하기 위해 조회하는 티켓들은 두 트랜잭션 모두 같지만, 업데이트 하는 티켓들은 각 트랜잭션 마다 다르다.
- 구매한 티켓 수를 확인하기 위해 조회하는 티켓들 - A, B 모두: 1, 2
- 업데이트하는 티켓들 - A: 3, 4 / B: 5, 6
그렇기 때문에, 낙관적 락으로는 구매 제한 수량 초과 문제를 해결할 수 없다.
해결 방법 2. 비관적 락
@Query(
"""
SELECT t
FROM ReservationEntity r
JOIN r.tickets t
WHERE t.performanceRoundId = :roundId
AND r.userId = :userId
AND t.isPaid = true
""",
)
@Lock(LockModeType.PESSIMISTIC_WRITE)
fun getPaidTicketsByRoundIdAndUserIdWithPessimistic(
roundId: UUID,
userId: UUID,
): List<TicketEntity>그렇다면, 위와 같이 비관적 락을 적용시키면 되지 않을까? 이렇게 하면 유저가 구매한 티켓들을 조회할 때 락이 걸리기 때문에, 문제를 해결할 수 있을 것 같다.
| 테스트 회차 | 1차 | 2차 | 3차 | 4차 | 5차 | avg |
|---|---|---|---|---|---|---|
| 구매 제한 초과 유저 수 | 0명 | 0명 | 0명 | 0명 | 0명 | 0명 |
- 유저 당 티켓 구매 수
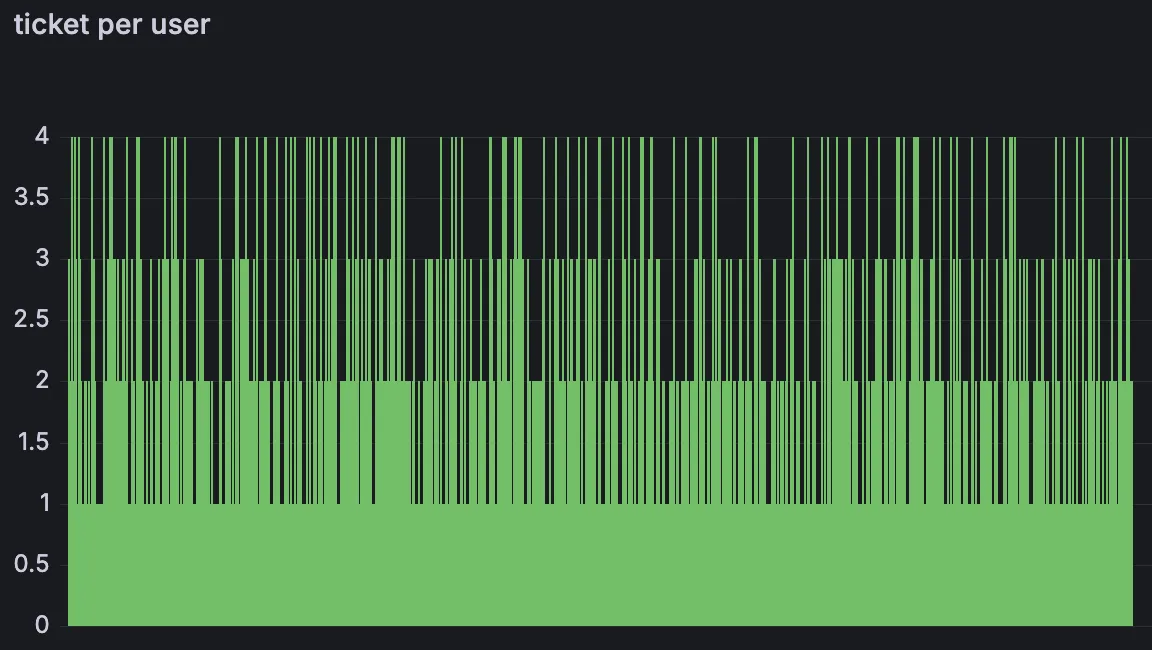
- 구매 제한 수량인 4를 초과한 유저가 없다.
예상대로 잘 해결된 모습이다.
하지만, 이전 동시성 문제 해결 시 비관적 락으로 인해 Lock 대기 시간이 높아져서 성능이 저하되는 문제가 있었다. 과연 문제가 없을지 쿼리의 실행계획과 Lock이 걸리는 범위를 분석해보자.
구매 티켓 조회 쿼리 분석
📢 해당 분석은 MySQL 8.0.35, InnoDB 환경에서 진행되었습니다.
- SQL
-- 구매 티켓 조회 쿼리 -- SELECT t FROM reservation r JOIN ticket t ON r.id = t.reservation_id WHERE t.performance_round_id = {roundId} AND r.user_id = {userId} AND t.is_paid = TRUE FOR UPDATE; - Explain
id select_type table type key ref rows filtered Extra 1 SIMPLE reservation ref idx_reservation_user_id const 2 100 Using where; Using index 1 SIMPLE ticket ref fk_reservation_ticket reservation.id 5 5 Using where
실행 계획 분석
실행 계획을 바탕으로 구매 티켓 조회 쿼리가 실행되는 과정을 정리하면 아래와 같다.
-
reservation 테이블에서 user_id가
{userId}인 row들을 조회id select_type table type key ref rows filtered Extra 1 SIMPLE reservation ref idx_reservation_user_id const 2 100 Using where; Using index - Extra의
Using index를 통해 해당 쿼리는 reservation 테이블에 대한 직접적인 접근 없이 인덱스(idx_reservation_user_id)만으로 처리되었음을 알 수 있다. 즉, 커버링 인덱스가 적용된 것이다. 테이블에 대한 접근 없이 인덱스만으로 처리되었기 때문에 성능적으로 더 좋다. - InnoDB의 세컨더리 인덱스는 PK를 포함하고 있기 때문에, 위 쿼리에서 필요한
reservation.id와user_id컬럼은 전부idx_reservation_user_id인덱스에 포함되어 있다.
- Extra의
-
1번에서 조회한 reservation의 row들과 ticket 테이블을 왜래키(
fk_reservation_ticket)를 통해 Join한다.id select_type table type key ref rows filtered Extra 1 SIMPLE ticket ref fk_reservation_ticket reservation.id 5 5 Using where -
performance_round_id와is_paid에 대한 필터링을 진행한다.WHERE t.performance_round_id = {roundId} AND t.is_paid = TRUE- 해당 과정에서
performance_round_id와is_paid에 인덱스가 없기 때문에 직접 필터링을 진행한다. 하지만, 한 유저가 많은 예약을 하지 않는 이상 필터링 할 row가 많지 않기 때문에, 성능에 큰 영향은 없어보인다.
- 해당 과정에서
이렇게 실행 계획을 살펴본 결과, 쿼리 자체는 큰 문제가 없어보인다. 추후 유저별 예매 건 수가 많아지게 되면, 추가 인덱스를 생성하는 등의 튜닝을 고려할 수 있겠다.
락 범위 분석
-- 트랜잭션 시작 --
START TRANSACTION;
-- 구매 티켓 조회 --
SELECT t.*, r.user_id
FROM reservation r
JOIN ticket t ON r.id = t.reservation_id
WHERE t.performance_round_id = {roundId}
AND r.user_id = {userId}
AND t.is_paid = TRUE
FOR UPDATE;
-- Lock 상태 조회 --
SELECT * FROM performance_schema.data_locks;
-- 트랜잭션 커밋 --
COMMIT;락 범위를 자세히 알아보기 위해서 위와 같이 performance_schema.data_locks를 조회해봤다.
SELECT * FROM performance_schema.data_locks;결과Row Table Index Name Lock Mode Lock Data 3 reservation idx_reservation_user_id X user_id: 3, id: 3 4 reservation idx_reservation_user_id X user_id: 3, id: 4 5 reservation PRIMARY X, REC_NOT_GAP id: 3 6 ticket fk_reservation_ticket X reservation_id: 3, id: 5 7 ticket fk_reservation_ticket X reservation_id: 3, id: 6 8 ticket PRIMARY X, REC_NOT_GAP id: 6 9 ticket PRIMARY X, REC_NOT_GAP id: 5 10 ticket X, GAP reservation_id: 3 11 reservation PRIMARY X, REC_NOT_GAP id: 4 12 ticket fk_reservation_ticket X reservation_id: 4, id: 7 13 ticket fk_reservation_ticket X reservation_id: 4, id: 8 14 ticket PRIMARY X, REC_NOT_GAP id: 8 15 ticket PRIMARY X, REC_NOT_GAP id: 7 16 ticket fk_reservation_ticket X, GAP reservation_id: 4 17 reservation idx_reservation_user_id X, GAP user_id: 3 - Lock Type이 RECORD가 아닌 row는 생략했다.
이렇게만 보면 이해하기 어렵기 때문에, 쿼리의 실행 과정을 따라가며 자세히 분석해보자.
-
reservation 테이블에서
user_id가3인 row들을 조회
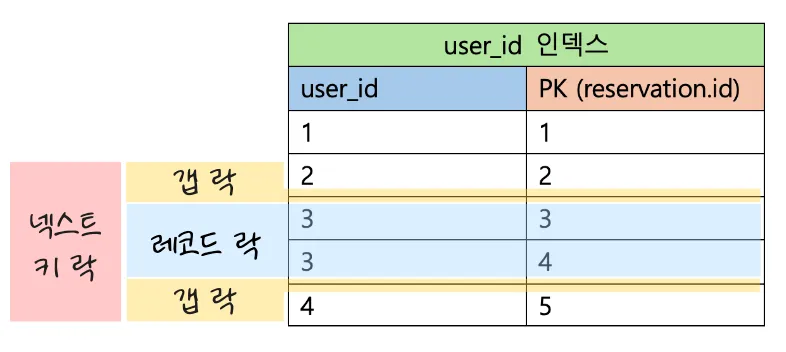
Row Table Index Name Lock Mode Lock Data 3 reservation idx_reservation_user_id X user_id: 3, id: 3 4 reservation idx_reservation_user_id X user_id: 3, id: 4 5 reservation PRIMARY X, REC_NOT_GAP id: 3 11 reservation PRIMARY X, REC_NOT_GAP id: 4 17 reservation idx_reservation_user_id X, GAP user_id: 3 - row 3, 4, 5, 11을 보면 user_id가 3인 두 개의 row에 X락(베타 락, Exclusive Lock)이 걸린 것을 알 수 있다. 이렇게 레코드 단위로 Lock을 거는 것을 레코드 락(Record Lock)이라고 한다.
- row 17을 보면 user_id가 3인 reservation 테이블에 갭 락(Gap Lock)이 걸려있는 것을 알 수 있다. 이를 통해, user_id가 3인 인덱스 범위에 락을 걸어 해당 범위에 레코드의 생성, 수정, 삭제를 막는다.
- 이렇게 레코드 락과 갭 락이 합쳐진 형태를 넥스트 키 락(Next Key Lock)이라고 한다.
-
ticket 테이블에서
reservation_id가3,4인 row들을 조회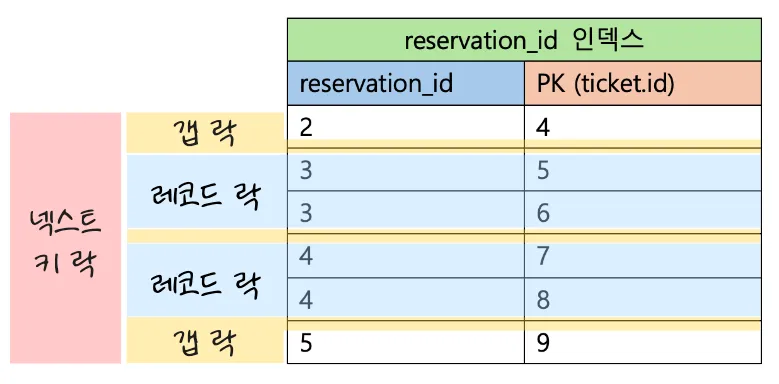
Row Table Index Name Lock Mode Lock Data 6 ticket fk_reservation_ticket X reservation_id: 3, id: 5 7 ticket fk_reservation_ticket X reservation_id: 3, id: 6 8 ticket PRIMARY X, REC_NOT_GAP id: 6 9 ticket PRIMARY X, REC_NOT_GAP id: 5 10 ticket fk_reservation_ticket X, GAP reservation_id: 3 12 ticket fk_reservation_ticket X reservation_id: 4, id: 7 13 ticket fk_reservation_ticket X reservation_id: 4, id: 8 14 ticket PRIMARY X, REC_NOT_GAP id: 8 15 ticket PRIMARY X, REC_NOT_GAP id: 7 16 ticket fk_reservation_ticket X, GAP reservation_id: 4 - row 6, 7, 8, 9 와 12, 13, 14, 15 에선 각각 reservation_id가 3과 4인 ticket들에 대해서 레코드 락이 걸린 것을 알 수 있다.
- row 10, 16에선 각각 reservation_id가 3, 4인 ticket 테이블에 갭 락(Gap Lock)이 걸려있는 것을 알 수 있다.
결과적으로는, user_id가 3인 reservation들과 이와 Join되는 ticket들에 전부 베타 락이 걸리게된다.
이렇게 락의 범위에 대해서 분석을 하다보니 두 가지 궁금한 점이 생겼다.
1. 왜 나머지 필터링 조건들에 대해선 Lock이 안걸리는가?
WHERE t.performance_round_id = {roundId} AND t.is_paid = TRUE구매 티켓 조회 쿼리는 user_id 말고도 performance_round_id, is_paid에 대한 필터링 조건이 더 있다.
그런데, 왜 user_id에 대해서만 락이 걸렸을까?
이유는, InnoDB는 인덱스를 통해 Lock을 걸기 때문이다. performance_round_id와 is_paid에 대해서는 별도의 인덱스가 없기 때문에 락이 걸리지 않은 것이다.
그렇기 때문에, 두 컬럼에 대해 인덱스를 생성하게 되면 해당 조건 까지 포함하여 락이 걸리게 될 것이다. 그렇게 되면 락의 범위가 더 줄어들어 Lock 대기 시간이 감소할 수 있다.
2. 만약 조회되는 row가 없으면 어떻게 될까?
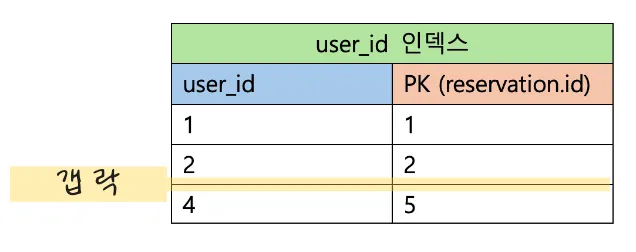
| Row | Table | Index Name | Lock Mode | Lock Data |
|---|---|---|---|---|
| 2 | reservation | idx_reservation_user_id | X, GAP | user_id: 3 |
reservation 테이블에 user_id가 3인 row가 없다면, 위와 같이 갭 락만 걸게된다. 그렇기 때문에, 조회되는 row가 없어도 user_id의 동시 구매 요청을 막을 수 있다.
개선할 수 있는 포인트
두 컬럼에 대해 인덱스를 생성하게 되면 해당 조건 까지 포함하여 락이 걸리게 될 것이다. 그렇게 되면 락의 범위가 더 줄어들어 Lock 대기 시간이 감소할 수 있다.
의문점 1에서 이야기한대로 인덱스를 추가로 생성하면 Lock 대기 시간이 감소하여 성능 향상을 기대할 수 있을 것이다.
하지만, 아래의 이유들로 추가 인덱스를 생성하지 않기로 결정하였다.
- 미미한 성능 향상 기대
- 유저별 예매 건수가 늘어나게 된다면 추가 인덱스 생성이 필요할 것이다. 하지만, 한 명의 유저가 수많은 예매를 진행하는 경우는 많지 않고, 추후 문제가 발생했을 때 추가 인덱스 생성을 고려하는게 맞다고 판단하였다.
- 인덱스 생성의 오버헤드
- 인덱스 생성이 무조건 좋은 효과만 있는 것은 아니다. 인덱스를 생성하게 되면 추가적인 디스크 용량을 차지하고, 쓰기 작업에 대한 오버헤드가 생기게된다.
- 그렇기 때문에, 성능 향상 기댓값이 낮은 상황에서 오버헤드가 있는 추가 인덱스 생성을 하지 않는게 맞다고 판단하였다.
또한, 여전히 락 획득을 위해 DB의 자원을 계속 쓰고 있다. 그러므로, 요청이 늘어날 수록 DB의 부하가 증가하여 서비스의 병목지점이 될 가능성이 높다.
이를 해결하기 위해 추후에 분산 락을 도입하여 Lock 관리에 대한 책임을 DB에서 Redis와 같은 곳으로 옮겨서 더 개선을 할 수 있겠다.
결론 및 느낀점
같은 동시성 문제라고 해도, 문제 상황과 요구 사항에 따라 해결 방법이 천차만별이라는 것을 깨달았다.
이번 경험을 통해 동시성 문제 해결을 위한 다양한 방법들을 깊게 학습하였고, 앞으로 어떤 문제가 발생해도 충분히 해결할 수 있을 것이란 자신감이 생겼다.
또한, 동시성 문제 해결에서 시작하여 MySQL(InnoDB)의 락에 대해 다시 한 번 복습할 수 있었던 알찬 경험이었다.

Ich verbringe normalerweise viel Zeit mit Programmieren, aber an einem Abend beschloss ich, eine Pause einzulegen und etwas Neues auszuprobieren. Dabei stieß ich auf , wo ich mich wunderbar entspannen konnte. Die Plattform bietet eine riesige Auswahl an Spielen, großzügige Boni und ein benutzerfreundliches Design – genau das Richtige, um den Kopf freizubekommen und einen unterhaltsamen Abend zu genießen!