
[13~15장]
[13장] 검색어 자동완성 시스템
개략적 설계안
- 데이터 수집 서비스: 사용자가 입력한 질의를 수집 → 검색어의 빈도 수집
- 질의 서비스: 데이터 수집 서비스를 통해 수집한 검색어의 빈도에 따라서 top 5 자동완성 검색어 표시
이런 쿼리를 통해서 가장 많이 사용된 검색어를 구할 수 있지만, 데이터 양이 아주 많아지면 DB가 병목이 될 수 있음SELECT * FROM frequency_table WHERE query LIKE `prefix%` LIMIT 5
상세 설계
트라이 자료구조
관계형 데이터베이스는 사용빈도가 높은 5개의 검색어를 골라내기에 효율적이지 않음 → 트라이를 사용하여 해결

- 문자열들을 간략하게 저장할 수 있는 자료구조 → 문자열을 꺼내는 연산에 초점을 맞춰 설계됨
- 트리형태의 자료구조, 각 노드는 글자 하나를 저장, 각 트리 노드는 하나의 단어 or 접두어 문자열을 나타냄
- 위 그림처럼 각 검색어의 빈도를 저장
- p = 접두어의 길이, n = 트라이 안에 있는 노드 개수, c = 주어진 노드의 자식노드 개수
→ 가장 많이 사용된 질의어를 찾으려면
- 해당 접두어를 표현하는 노드 찾기 → 시간 복잡도 O(p)
- 해당 노드부터 시작하는 하위트리를 탐색하여 모든 유효 노드 찾기 → 시간 복잡도 O(c)
- 유효 노드들을 정렬하여 가장 인기있는 검색어 찾기 → 시간 복잡도 O(clogc)만약 접두어 최대 길이를 제한 → 접두어 노드 찾기 시간복잡도 O(1) 만약 노드에 인기 검색어 캐시 → 모든 단계의 시간복잡도 O(1) → BUT 각 노드에 검색어를 저장할 공간이 많이 필요하게 됨
데이터 수집 서비스
기존 방식: 검색창에 타이핑을 할 때마다 데이터 수정 → 매 입력마다 트라이 갱신 → 속도 매우 느려짐,
트라이가 만들어 지면 인기 검색어는 자주 바뀌지 않음 → 자주 갱신할 필요 X
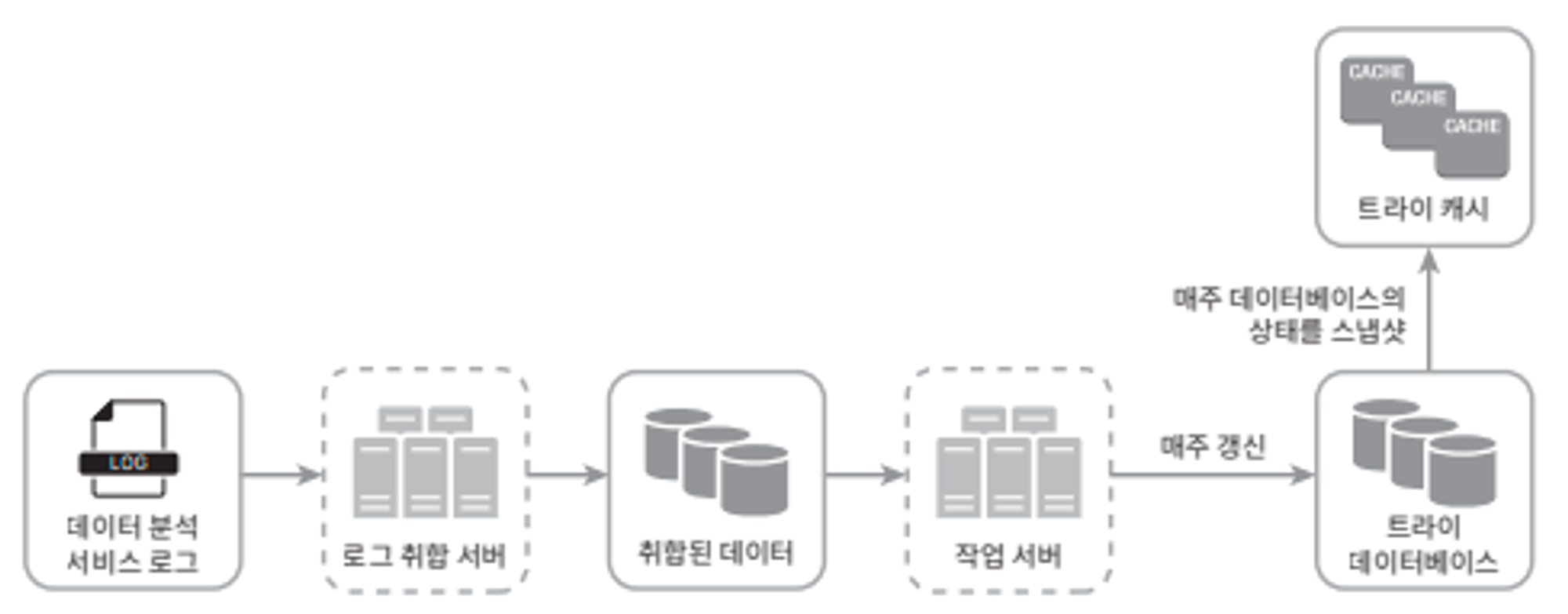
- 데이터 분석 서비스 로그: 검색창에 입력된 검색어에 관한 원본 데이터 보관
ex) query = “tree”, time = 2019-10-01 22:01:01 - 로그 취합 서버: 로그의 양이 매우 많고, 데이터 형식도 제각각 → 이런 로그들을 취합(aggregation)
ex) query = “tree”, time = 2019-10-01, frequency = 100 - 작업 서버: 주기적으로 비동기 작업을 실행하는 서버들, 트라이 자료구조를 만들고 트라이 DB에 저장
- 트라이 캐시: 분산 캐시 시스템, 데이터를 메모리에 유지하여 읽기 성능 향상, 매주 트라이 DB의 스냅샷을 떠서 갱신
- 트라이 DB: 문서 저장소 혹은 키-값 저장소 사용
- 문서 저장소: 주기적으로 트라이를 직렬화하여 저장.(ex: 몽고DB)
- 키-값 저장소: 트라이에 보관된 모든 접두어를 해시 테이블 키로 변환, 각 트라이 노드에 보관된 모든 데이터를 해시 테이블 값으로 변환
질의 서비스
- 요청을 받으면 API서버는 트라이 캐시에서 데이터를 가져와 해당 요청의 자동완성 검색어 반환
- 트라이 캐시에 데이터가 없으면 DB에서 가져와 캐시에 채움
최적화 방안
- Ajax 요청
- Ajax: 자바스크립트를 이용해 클라이언트-서버 간 데이터를 주고받는 비동기 HTTP통신. XML Http Request 객체를 이용하여 전체 페이지가 아닌 필요한 데이터만 불러옴, Jquery
- 브라우저 캐싱: 제안된 검색어들을 브라우저 캐시에 넣어둬 후속 질의의 결과는 해당 캐시에서 가져갈 수 있음
- 데이터 샘플링: 모든 질의 결과를 로깅하면 자원을 많이 소모 → N개 요청 가운데 1개만 로깅
트라이 연산
- 트라이 생성: 작업 서버가 담당, 데이터 분석 서비스의 로그, DB로 부터 취합된 데이터 이용
- 트라이 갱신
- 매주 한 번 갱신: 새 트라이를 만든 다음 기존 트라이 대체
- 트라이의 각 노드를 개별적으로 갱신: 성능이 좋지않지만 트라이가 작으면 고려가능
- 검색어 삭제: API서버와 트라이 캐시 사이 필터 계층을 두어 부적절한 질의어가 반환되지 않도록함
저장소 규모 확장
트라이의 크기가 한 서버에 넣기 너무 큰 경우를 대비하여 샤딩 필요
→ 질의 데이터의 패턴을 분석하여 샤딩
ex) s로 시작하는 검색어의 수와 u,v,w,x,y,z로 시작하는 검색어 수가 비슷하면 s에 대한 샤드, u~z에 대한 샤드를 둠
[14장] 유튜브 설계
개략적 설계안
비디오 업로드

- 메타데이터 DB, 캐시: 비디오의 메타데이터 보관. 샤딩과 다중화를 적용하여 성능 및 가용성 향상 시킬 예정. 성능을 높이기 위해 비디오 메타데이터와 사용자 객체 캐싱
- 원본 저장소: 원본 비디오를 보관할 BLOB 저장소
- 트랜스코딩 서버: 트랜스코딩 = 인코딩, 최적의 비디오 스트림을 제공하기 위해 비디오의 포맷을 변경하는 서버
- 트랜스코딩 비디오 저장소: 트랜스코딩이 완료된 비디오를 저장하는 BLOB 저장소
- CDN: 비디오를 캐시하는 역할을 담당
- 트랜스코딩 완료 큐: 비디오 트랜스코딩 완료 이벤트들을 보관할 메시지 큐
- 트랜스코딩 완료 핸들러: 트랜스코딩 완료 큐에서 이벤트를 꺼내 메타데이터 캐시, DB를 갱신할 적업 서버
비디오 업로드는 비디오 업로드 과정과 메타데이터 갱신 과정이 병렬적으로 진행
- 업로드 과정
- 비디오 원본 저장소 업로드
- 트랜스코딩 서버는 원본 저장소에서 비디오를 가져와 트랜스코딩 시작
- 트랜스코딩 완료 후엔 아래 두 절차 병렬적으로 수행
- 완료된 비디오를 트랜스코딩 비디오 저장소 업로드 → CDN 업로그
- 트랜스코딩 완료 이벤트를 트랜스코딩 완료 큐에 넣음 → 완료 핸들러가 큐에서 데이터 꺼내와서 메타데이터 DB와 캐시 갱신
- API 서버가 사용자에게 스트리밍 준비가 됨을 알림
- 메타데이터 갱신 과정: 비디오가 업로드 되는 동안 사용자는 병렬적으로 비디오 메타데이터 갱신 요청을 API 서버에 보냄 → 이 정보로 메타데이터 DB, 캐시 업데이트
비디오 스트리밍
- 비디오 스트리밍은 스트리밍 프로토콜을 사용해서 CDN에서 바로 스트리밍
상세 설계
비디오 트랜스코딩
- 비디오 트랜스코딩이 중요한 이유는 다음과 같음
- 원본 비디오는 많은 저장 공간을 차지함
- 상당수의 단말과 브라우저는 특정 종류의 비디오 포맷만 지원 → 다양한 포맷으로 인코딩 해둬야함
- 끊김 없는 비디오 재생을 위해서는 네트워크 환경이 좋지 않은 사용자는 저화질, 좋은 사용자는 고화질 비디오를 보내야함
- 인코딩 포맷은 다양하지만 대부분 다음 두 부분으로 구성됨
- 컨테이너: 비디오 파일, 오디오, 메타데이터를 담는 바구니 같은 것. 확장자 이름이 컨테이너 포맷임
- 코덱: 비디오 화질은 보존하며 파일 크기를 줄일 목적으로 고안된 압축 알고리즘
유향 비순환 그래프(DAG) 모델
- 사람마다 다른 비디오 프로세싱 요구사항이 있음(ex: 워터마크 표시, 고/저화질)
- 각기 다른 유형의 비디오 프로세싱 파이프라인을 지원하고 처리과정의 병렬성을 높이기 위해 추상화를 도입하여 실행할 작업을 손수 정의 할 수 있도록 해야함
→ DAG 모델을 도입하여 작업을 단계별로 배열 할 수 있도록 하여 해당 작업들이 순차적 or 병렬적으로 실행될 수 있도록 함
비디오 트랜스코딩 아키텍처

- 전처리기
- 비디오 분할: 비디오 스트림을 GOP라는 단위로 쪼갬
- DAG 생성: 설정 파일에 따라 DAG를 만듦
- 데이터 캐시: 분할된 비디오의 캐시 역할도 함. 안정성을 높이기 위해 GOP와 메타데이터를 임시저장소에 보관 → 인코딩 실패시 이렇게 보관된 데이터로 다시 시작
- DAG 스케줄러: DAG 스케줄러는 DAG 그래프를 몇 개 단계로 분할한 다음에 각각을 자원 관리자의 작업 큐에 넣음
ex: 첫 단계에선 비디오, 오디오, 메타데이터 분리. 두 번째 단계에선 비디오 파일 인코딩, 섬네일 추출, 오디오 파일 인코딩 - 자원 관리자: 자원 배분을 효과적으로 수행하는 역할 담당. 3개의 큐와 작업 스케줄러로 구성
-
작업 큐: 실행할 작업이 보관되어 있는 큐
-
작업 서버 큐: 작업 서버의 가용 상태 정보가 보관되어 있는 큐
-
실행 큐: 현재 실행 중인 작업 및 작업 서버 정보가 보관되어 있는 큐
-
작업 스케줄러: 최적의 작업/서버 조합을 골라 해당 작업 서버가 작업을 수행하도록 지시
작동 과정
- 작업 큐에서 우선순위 높은 작업 꺼냄
- 해당 작업을 하기 좋은 작업 서버 고름
- 작업 스케줄러가 해당 작업 서버에게 작업 지시
- 해당 작업이 어떤 서버에 할당되었는지에 대한 정보를 실행 큐에 넣음
- 작업 완료 시 실행 큐에서 제거
-
- 임시 저장소: 작업 서버의 프로세스가 실패한 경우를 대비하여 임시로 데이터 저장. 메타데이터는 메모리, 비디오/오디오 데이터는 BLOB 저장소에 저장. 비디오 프로세싱 완료 시 삭제
시스템 최적화
- 비디오 병렬 업로드: 비디오를 여러 GOP로 나누어 병렬적으로 업로드 → 속도 향상
- 사용자와 가까운 업로드 센터 지정 → 속도 향상
- 모든 절차를 병렬화: 이전 단계의 결과물을 입력으로 받는 단계가 있어서 각 시스템에 의존성이 있음 → 메시지 큐 도입 → 각 시스템의 결합도를 낮추어 병렬처리 → 속도 향상
- 미리 사인된 업로드 URL: 클라이언트는 HTTP 서버에서 미리 사인된 URL을 받음 → 클라이언트는 해당 URL이 가리키는 위치에 비디오 업로드 → 안전성 향상
- 비용 최적화: CDN은 비쌈 → 비용을 낮춰야함, 유튜브의 비디오 스트리밍은 long-tail 분포를 따름
- 인기 비디오는 CDN, 다른 비디오는 비디오 서버
- 인기 없는 비디오는 인코딩 안하기, 짧은 비디오는 필요할 때 인코딩
- 특정 지역에서만 인기가 높은 비디오는 다른 지역으로 옮기지 않아도 됨
[15장] 구글 드라이브 설계
개략적 설계안
API
- 파일 업로드 API
- 단순 업로드: 파일 크기가 작을 때 사용
- 이어 올리기: 파일 사이즈가 크고, 네트워크 문제로 업로드 중단 가능성이 있을 때 사용
- 파일 다운로드 API
- 파일 갱신 히스토리 API
고려 사항
- 파일 시스템 용량 부족 → 샤딩 - 데이터 손실 걱정 → S3 사용 - 다중화 지원
- 메타데이터 데이터베이스: 파일 저장 서버와 분리하여 SPOF 회피, 다중화 및 샤딩 정책 적용
- 동기화 문제 해결: 두 사용자가 같은 파일 갱신 시 충돌 문제
시스템 구조

- 블록 저장소 서버: 파일 블록을 클라우드 저장소에 업로드 하는 서버. 파일을 여러개의 블록으로 나눠 저장, 각 블록에는 고유한 해시값 할당, 해시값은 메타데이터 데이터베이스에 저장됨.
- 아카이빙 저장소: 오랫동안 사용되지 않은 비활성 데이터를 저장하는 곳
- 메타데이터 DB: 사용자, 파일, 블록, 버전 등의 메타데이터 정보 관리
- 메타데이터 캐시: 자주쓰이는 메타데이터를 캐시하여 성능 향상
- 오프라인 사용자 백업 큐: 클라이언트가 접속 중이 아니라 최신 상태를 확인할 수 없을 때 해당 정보를 이 큐에 두어 나중에 접속 시에 동기화
상세 설계
블록 저장소 서버
용량이 큰 파일의 경우 전체 파일을 서버로 보내면 네트워크 대역폭을 많이 잡아먹음 → 최적화 필요
- 델타 동기화: 파일 수정 시 수정이 일어난 블록만 동기화
- 압축: 블록 단위로 압축하여 데이터 크기를 줄임, 압축 알고리즘은 파일 유형에 따라 정함 → 파일을 블록 단위로 분할 + 압축 + 암호화 하여 업로드, 수정된 블록만 전송
높은 일관성
같은 파일이 단말이나 사용자에 따라 다르게 보이면 안됨
→ 캐시에 보관된 사본과 데이터베이스의 원본이 일치, 원본에 변경 발생 시 캐시 사본 무효화
- RDB는 강한 일관성 기본 보장, NoSQL은 기본 X → RDB 채택
업로드 절차
메타데이터 추가 요청과 클라우드 저장소 업로드 요청이 병렬적으로 전송
- 메타데이터 추가
- 메타데이터를 DB에 저장하고 업로드 상태를 대기중으로 변경
- 새 파일이 추가되었음을 알림 서비스에 통지
- 클라우드 저장소 업로드
- 블록 저장소 서버는 파일을 블록 단위로 분할, 압축, 암호화 후 클라우드 저장소로 전송
- 업로드 완료 후 클라우드 스토리지는 완료 콜백을 호출, API 서버로 전송
- 메타데이터 DB의 파일 업로드 상태를 완료로 변경
- 파일 업로드가 끝났음을 알림 서비스에 통지
다운로드 절차
- 알림 서비스가 클라이언트2에게 누군가 파일 변경했음을 알림
- 알림을 확인한 클라이언트2는 새로운 메타데이터를 요청하여 받아옴
- 클라이언트2는 메타데이터를 받자마자 블록 다운로드 요청 전송
- 블록 저장소 서버는 요청한 블록을 클라우드 저장소에서 가져와서 반환
- 클라이언트2는 전송된 블록을 사용하여 파일 재구성
- 다운로드는 파일 추가 or 편집 시 시작 → 다른 클라이언트가 파일 편집 or 추가 시 감지 방법은?
- 접속중이면 알림 서비스가 알림
- 접속중이 아니면 데이터는 캐시 보관, 접속 시 알림
알림 서비스
롱 폴링 vs 웹소켓 → 롱 폴링
- 양방향 통신이 필요하지 않음(서버는 파일이 변경된 사실을 클라이언트에게 알려야함 but 반대 방향의 통신은 필요 X)
- 알림을 보낼 일은 자주 발생하지 않고, 보낸다 해도 단시간에 많은 양을 보낼 일은 없음
- 롱 폴링을 쓰게되면 각 클라이언트는 알림 서버와 롱 폴링용 연결을 유지하다가 파일 변경 감지 시 연결을 끊음 → 클라이언트는 메타데이터 서버와 연결해 파일의 최신 내역 다운로드 다운로드 끝 or 타임아웃 시 즉시 새 요청을 보내어 롱 폴링 연결 복원 및 유지
저장소 공간 절약
안정성을 위해 여러 백업본을 저장해야함 → 저장용량 소진이 너무 빠름
- 중복 제거: 종복된 파일 블록을 계정 차원에서 제거. 해시 값을 비교하여 같은 블록인지 판별
- 지능적 백업 전략 도입
- 한도 설정: 보관할 파일 버전 개수에 상한을 두고 상한 도달 시 가장 오래된 버전 제거
- 중요한 버전만 보관: 업데이트가 자주되는 파일의 경우 업데이트 마다 새로운 버전으로 관리한다면 너무 많은 버전이 만들어짐 → 중요한 버전만 골라야함
- 아카이빙 저장소 활용: 자주 쓰이지 않는 데이터는 아카이빙 저장소로 옮김 → 이용료가 훨씬 저렴
