
💡 이 글의 내용은 MySQL 8.0 이상 + InnoDB 스토리지 엔진 환경을 기준으로 작성되었습니다.
실행 계획이란?
동일한 쿼리여도 현재 DBMS의 상황에 따라서 가장 효율적으로 쿼리를 실행할 수 있는 방법은 다양하다.
DBMS에서는 옵티마이저가 통계 정보를 참고하여 다양한 방법 중 가장 효율적인 방법을 찾아서 쿼리를 실행하는데, 이렇게 쿼리를 실행하는 방법을 실행 계획이라고 한다.
통계 정보
- MySQL 서버의 통계 정보
- 통계 정보에는 인덱스가 가진 유니크한 값의 수, 테이블의 전체 레코드 건수 등의 정보가 저장되어 있다.
- 통계 정보는 아래와 같은 이벤트들이 발생하면 갱신된다.
- 테이블이 새로 오픈되는 경우
- 테이블의 레코드가 대량으로 변경되는 경우
ANALYZE TABLE명령이 실행되는 경우SHOW TABLE STATUS명령이나SHOW INDEX FROM명령이 실행되는 경우
- 히스토그램 기존 통계 정보만으로는 최적의 실행 계획을 수립하기에는 많이 부족했다. MySQL 8.0부터는 컬럼의 데이터 분포도를 참조할 수 있는 히스토그램을 활용할 수 있다.
쿼리의 실행 시간 확인 - EXPLAIN ANALYZE
EXPLAIN ANALYZE명령으로 쿼리의 실행 계획과 단계별 소요된 시간 정보를 확인할 수 있다.
EXPLAIN ANALYZE명령은 기본적으로 TREE 포맷으로 출력되며 아래 규칙으로 호출 순서를 파악할 수 있다.
- 들여쓰기가 같은 레벨에서는 상단에 위치한 라인이 먼저 실행된다.
- 들여쓰기가 다른 레벨에서는 가장 안쪽에 위치한 라인이 먼저 실행된다.
-> Index lookup on s using PRIMARY (emp_no=e.emp_no) (cost=0.98 rows=10)
(actual time=0.007..0.009 rows=10 loops=233)EXPLAIN ANALYZE명령으로 확인한 실행 계획 중 일부를 살펴보며 의미를 알아보자.
Index lookup on s using PRIMARY (emp_no=e.emp_no)s테이블의emp_no와e테이블의emp_no가 일치하는 레코드를 PK를 이용해 검색한다는 뜻이다.
actual time=0.007 ..0.009e테이블에서 읽은emp_no을 기준으로s테이블에서 검색하는 데 걸린 시간(밀리초)을 뜻한다.- 두 숫자는 각각 첫 레코드를 찾는 데 걸린 평균 시간, 마지막 레코드를 찾는데 걸린 평균 시간을 의미한다.
rows=10e테이블에서 읽은emp_no에 일치하는s테이블의 평균 레코드 건수를 의미한다.
loops=233e테이블에서 읽은emp_no를 이용해s테이블의 레코드를 찾는 작업이 반복된 횟수를 의미한다. →e테이블에서 읽은emp_no의 개수가 233개임을 의미한다.
→ s테이블에서 emp_no가 일치하는 레코드를 찾는 작업을 233번 반복했는데, s테이블에서 첫 레코드를 찾는데 평균 0.007ms가, 10개의 레코드를 모두 찾는 데 평균 0.009ms가 걸렸다는 뜻이다.
실행 계획 확인 - EXPLAIN
MySQL의 실행 계획은 EXPLAIN명령으로 확인할 수 있다.
EXPLAIN명령을 실행하면 12개의 컬럼과 값들이 테이블 형식으로 나온다.
각 컬럼이 나타내는 정보에 대해서 알아보자.
id 컬럼
실행 계획의 id 컬럼은 단위 SELECT쿼리별로 부여되는 식별자 값이다.
만약 한 SELECT에서 여러 테이블을 조인하면 조인 테이블 수 만큼 레코드가 생성되지만, 같은 id가 부여된다.
id가 큰 SELECT쿼리 부터 실행되고, id가 같은 레코드들은 레코드 순서대로 조인이 실행된다.
select_type 컬럼
각 단위 SELECT쿼리가 어떤 타입의 쿼리인지 표시되는 컬럼이다.
여러 타입이 있지만, 그 중 몇 가지만 설명하겠다.
- SIMPLE
UNION이나 서브쿼리를 사용하지 않는 단순한SELECT쿼리의 경우select_type이SIMPLE이다.SIMPLE쿼리는 하나만 존재하고, 일반적으로 제일 바깥SELECT쿼리이다.
- PRIMARY
UNION이나 서브쿼리를 사용하는SELECT쿼리의 가장 바깥 쿼리는select_type이PRIMARY다.
- DERIVED
DERIVED는 단위SELECT쿼리의 결과로 메모리나 디스크에 임시 테이블을 생성하는 것을 의미한다.
table 컬럼
실행 계획은 테이블 기준으로 표시되고, table컬럼에는 실행 계획의 테이블 이름이 들어간다.
id, select_type, table 컬럼을 통해 아래 실행 계획을 간단하게 살펴보자.
| id | select_type | table |
|---|---|---|
| 1 | PRIMARY | |
| 1 | PRIMARY | h |
| 2 | DERIVED | h |
| 2 | DERIVED | r |
| 2 | DERIVED | res |
위 실행 계획을 예시로 들면 총 2번의 SELECT쿼리가 실행되었고, id가 2인 SELECT쿼리는 세 개의 테이블(h, r, res)이 조인되었고, id가 2인 SELECT쿼리는 두 개의 테이블(<derived2>, h)이 조인되었다.
이때, id가 2인 쿼리의 select_type은 DERIVED인데, 이는 2번 쿼리의 결과로 임시 테이블이 생성된다는 것을 뜻하고, 1번 쿼리의 table 컬럼의 <derived2>는 2번 쿼리에서 생성된 임시 테이블을 뜻한다.
partitions 컬럼
partitions컬럼은 해당 쿼리가 어느 파티션에 접근했는지를 알려준다.
type 컬럼
type 컬럼은 각 테이블의 접근 방법이라고 생각하면 된다.
총 12가지 방법이 있으며, ALL을 제외한 나머지 타입은 모두 인덱스를 사용한다.
12가지 방법 중 중요하다고 생각하는 몇 가지만 설명하겠다.
- const
- PK나 유니크 키 컬럼을 이용하는
WHERE절을 가지고 있고, 1건만 반환하는 방식의 쿼리를 말한다. type이const인 실행 계획은 옵티마이저가 쿼리를 최적하며 먼저 실행해서 통째로 상수화한다.- 예를 들어,
SELECT name FROM user WHERE id=1이런 서브쿼리가 있다면 이를 통째로‘name1'으로 상수화 하는 것이다.
- PK나 유니크 키 컬럼을 이용하는
- eq_ref
- 조인에서 처음 읽은 테이블의 칼럼값을 두번째 테이블의 PK나 유니크키 칼럼의 검색 조건에 사용할 때의 접근 방법을
eq_ref라고 한다. - 아래 쿼리로 예로 들면
rooms,hotels와 가 조인하고,h.id는 PK이기 때문에r.hotel_id=h.id를 만족하는hotels의 레코드가 단 하나이므로eq_ref접근 방법이다.SELECT r.id, h.id FROM rooms r JOIN hotels h ON r.hotel_id = h.id; - 처음 읽는 테이블의 한 행마다 1건의 레코드만 검색하면 되므로 성능이 뛰어난 접근 방법이다.
- 조인에서 처음 읽은 테이블의 칼럼값을 두번째 테이블의 PK나 유니크키 칼럼의 검색 조건에 사용할 때의 접근 방법을
- ref
ref접근 방법은 인덱스의 종류와 상관없이 동등 조건으로 검색할 때 사용된다.- 레코드가 반드시 1건이란 보장이 없으므로
const나eq_ref보다 느리지만 매우 빠른 조회 방법이다.
- range
- 인덱스 레인지 스캔 형태의 접근 방법으로, 나쁘지 않은 접근 방법이다.
- index_merge
- 여러개의 인덱스를 이용해 검색 결과를 만들어낸 뒤 그 결과를 병합해서 처리하는 방식이다.
- 아래 쿼리로 예로 들면
detail_region_idx를 이용해서detail_region_id=1인 레코드들과,category_id_idx를 이용해서category_id=1인 레코드들을 가져와서 교집합 연산을 수행한다.// detail_region_idx(detail_region_id), category_id_idx(category_id) SELECT * FROM hotels h WHERE detail_region_id=1 AND category_id=1 - 이 실행 계획은 여러 인덱스를 읽어야하고, 두 결과를 가지고 교집합, 합집합, 중복 제거와 같은 부가적인 작업이 더 필요하기 때문에 그렇게 효율적이지 않다.
index_merge접근 방법이 이용되면 Extra 컬럼에 추가적인 내용이 표시된다.Using union: 합집합 /Using sort_union: 정렬 후 합집합 /Using intersect: 교집합
- index
- 인덱스 풀 스캔을 의미하는 접근 방법이다.
- 비효율적인 방법이다.
- ALL
- 풀 테이블 스캔을 의미하는 접근 방법이다.
- 비효율적인 방법이다.
possible_keys 컬럼
옵티마이저가 사용을 고려했던 인덱스의 목록들을 담고있는 컬럼이다.
즉, 사용되지 않은 인덱스들이 들어있고, 그냥 무시해도 되는 컬럼이다.
key 컬럼
옵티마이저가 최종으로 선택한 인덱스를 담고있는 컬럼이다.
key_len 컬럼
key_len 컬럼은 ****쿼리를 처리하기 위해 인덱스에서 몇 바이트 까지 썼는지를 의미한다.
예를 들어 크기가 8바이트인 두 컬럼으로 구성된 복합 인덱스를 사용했을 때 key_len이 8이면 복합 인덱스의 선행 컬럼만 사용했다는 것을 의미하고 key_len이 16이면 두 컬럼을 다 사용했다는 것을 의미한다.
ref 컬럼
접근 방법이 ref면 참조 조건으로 어떤 값이 제공됐는지 보여준다.
상숫값을 지정했다면 const, 다른 테이블의 컬럼 값이면 그 테이블이름과 컬럼이름이 표시된다.
ref 컬럼의 값이 func면 값에 연산을 거쳐서 참조했다는 것을 의미한다.
rows 컬럼
rows 컬럼은 인덱스를 사용하는 조건에만 일치하는 레코드 건수를 예측한 값이다.
filtered 컬럼
fintered 컬럼은 인덱스를 사용한 조건으로 걸러진 레코드들 중 인덱스를 사용하지 못하는 조건으로 인해 필터링되고 남은 레코드의 비율을 의미한다.
즉, rows가 233이고, filtered가 16.03이면 결과 레코드 건수는 233 * 0.1603 = 37이 된다.
Extra 컬럼
쿼리의 실행 계획에서 성능에 관련된 중요한 내용이 Extra 컬럼에 자주 표시된다.
정말 많은 내용이 표시될 수 있지만, 그 중 자주 나타나고 중요한 내용만 설명하겠다.
- Using where
- MySQL 엔진 레이어에서 필터링 작업을 처리한 경우 표시된다.
- Using index(커버링 인덱스)
-
인덱스만 읽어서 쿼리를 모두 처리할 수 있을 때(커버링 인덱스) 표시된다.
인덱스로만 쿼리를 처리할 수 있으면 디스크 접근이 필요 없어지므로 성능이 향상된다.
-
- Using temorary
- 쿼리 실행 시 임시 테이블이 생성되면 표시된다. (표시 안되도 생성되는 경우도 있음)
- Using filesort
ORDER BY처리가 인덱스를 사용하지 못할 때 표시된다.Using filesort가 표시되는 쿼리는 많은 부하를 일으키므로 튜닝이 필요하다.
- Using union, sort_union, intersect
index_merge접근 방법으로 실행되는 경우 어떤 방식의index_merge인지 알려주기 위해 표시된다.
- Using index for group-by 인덱스를 사용하여
GROUP BY처리를 수행하면 별도의 정렬 작업이 필요 없어지고, 인덱스의 필요한 부분만 읽으면 되므로 성능이 향상되는데, 이 때Using index for group-by메시지가 표시된다. 인덱스를 이용하여GROUP BY를 처리할 수 있더라도AVG(),SUM()처럼 조회하려는 값이 모든 인덱스를 다 읽어야 할 경우 루스 인덱스 스캔이 불가능하다. 이 경우에는Using index for group-by메시지가 표시되지 않는다. 참고로, 루스 인덱스 스캔은 대량의 레코드를GROUP BY하는 경우엔 성능 향상효과가 있지만 레코드 건수가 적으면 루스 인덱스 스캔을 사용하지 않아도 빠르게 처리가 가능하므로 무조건 좋은 것은 아니다.
- Select tables optimized away
MIN()또는MAX()만SELECT절에 사용되거나GROUP BY로MIN(),MAX()를 조회하는 쿼리가 인덱스를 이용해 1건만 읽는 형태의 최적화가 적용되면 표시된다.
실행 계획 분석 예시
이제 실제 쿼리의 실행 계획을 상세히 분석해보며 위 내용들을 정리해보자.
WITH available_rooms AS (
SELECT r.id,
r.hotel_id,
r.price
FROM rooms r
JOIN hotels h
ON r.hotel_id = h.id
LEFT OUTER JOIN reservation_check rc
ON r.id = rc.room_id
AND rc.stay_date BETWEEN '2023-06-22' AND '2023-06-25'
WHERE r.max_people_count >= 3
AND r.price >= 50000
AND r.price <= 200000
AND h.detail_region_id = 1
AND h.category_id
AND h.id > 100000
GROUP BY r.id, r.count
HAVING COALESCE(MAX(rc.count), 0) <= r.count
)
SELECT h.id,
h.name AS hotel_name,
MIN(ar.price) AS min_price,
h.rating,
h.address,
h.detail_region_name,
h.category_name
FROM hotels h
JOIN available_rooms ar
ON h.id = ar.hotel_id
GROUP BY h.id
ORDER BY h.id
LIMIT 10;위 쿼리는 내가 개발 중인 사이드 프로젝트 “여기서 놀자”의 호텔 검색 쿼리이다.
쿼리를 간단히 설명하면, 호텔과 객실의 조건에 따라 필터링한 뒤 예약 내역을 확인하여 예약이 가능한 객실을 찾아 CTE로 생성하고, 이를 이용하여 예약이 가능한 객실을 보유한 호텔을 조회한다.
이제 위 쿼리의 실행 계획을 Explain, Explain Analyze 명령을 이용하여 분석해보자.
- Explain (
partitions,possible_keys컬럼은 미표시)id select_type table type key key_len ref rows filtered Extra 1 PRIMARY ALL null null null 1003 100 Using temporary; Using filesort 1 PRIMARY h eq_ref PRIMARY 8 ar.hotel_id 1 100 null 2 DERIVED h range detail_regions_categories_idx 24 null 196 100 Using where; Using index; Using temporary 2 DERIVED r ref hotel_id 8 h.id 3 3.7 Using where 2 DERIVED rc ref reservation_check_ibfk_1 8 r.id 6 100 Using where - Explain Analyze
-> Limit: 10 row(s) (actual time=11.6..11.6 rows=10 loops=1) -> Sort: h.id, limit input to 10 row(s) per chunk (actual time=11.6..11.6 rows=10 loops=1) -> Table scan on <temporary> (actual time=11.5..11.5 rows=123 loops=1) -> Aggregate using temporary table (actual time=11.5..11.5 rows=123 loops=1) -> Nested loop inner join (cost=142 rows=0) (actual time=11..11.3 rows=155 loops=1) -> Table scan on ar (cost=2.5..2.5 rows=0) (actual time=11..11 rows=155 loops=1) -> Materialize CTE available_rooms (cost=0..0 rows=0) (actual time=11..11 rows=155 loops=1) -> Filter: (coalesce(max(rc.count),0) <= r.count) (actual time=11..11 rows=155 loops=1) -> Table scan on <temporary> (actual time=11..11 rows=157 loops=1) -> Aggregate using temporary table (actual time=10.9..10.9 rows=157 loops=1) -> Nested loop left join (cost=697 rows=149) (actual time=0.0933..10.8 rows=187 loops=1) -> Nested loop inner join (cost=540 rows=22.5) (actual time=0.061..3.03 rows=157 loops=1) -> Filter: ((h.category_id = 1) and (h.detail_region_id = 1) and (h.id > 100000)) (cost=40.8 rows=196) (actual time=0.0197..0.146 rows=196 loops=1) -> Covering index range scan on h using detail_regions_categories_idx over (detail_region_id = 1 AND category_id = 1 AND 100000 < id) (cost=40.8 rows=196) (actual time=0.018..0.104 rows=196 loops=1) -> Filter: ((r.max_people_count >= 3) and (r.price >= 50000) and (r.price <= 200000)) (cost=2.24 rows=0.115) (actual time=0.0141..0.0146 rows=0.801 loops=196) -> Index lookup on r using hotel_id (hotel_id=h.id) (cost=2.24 rows=3.11) (actual time=0.00922..0.0141 rows=3.12 loops=196) -> Filter: (rc.stay_date between '2023-06-22' and '2023-06-25') (cost=6.33 rows=6.6) (actual time=0.0485..0.0491 rows=0.382 loops=157) -> Index lookup on rc using reservation_check_ibfk_1 (room_id=r.id) (cost=6.33 rows=6.6) (actual time=0.0206..0.0471 rows=5.86 loops=157) -> Single-row index lookup on h using PRIMARY (id=ar.hotel_id) (cost=0.945 rows=1) (actual time=0.00167..0.0017 rows=1 loops=155)-
이해를 돕기위한 다이어그램
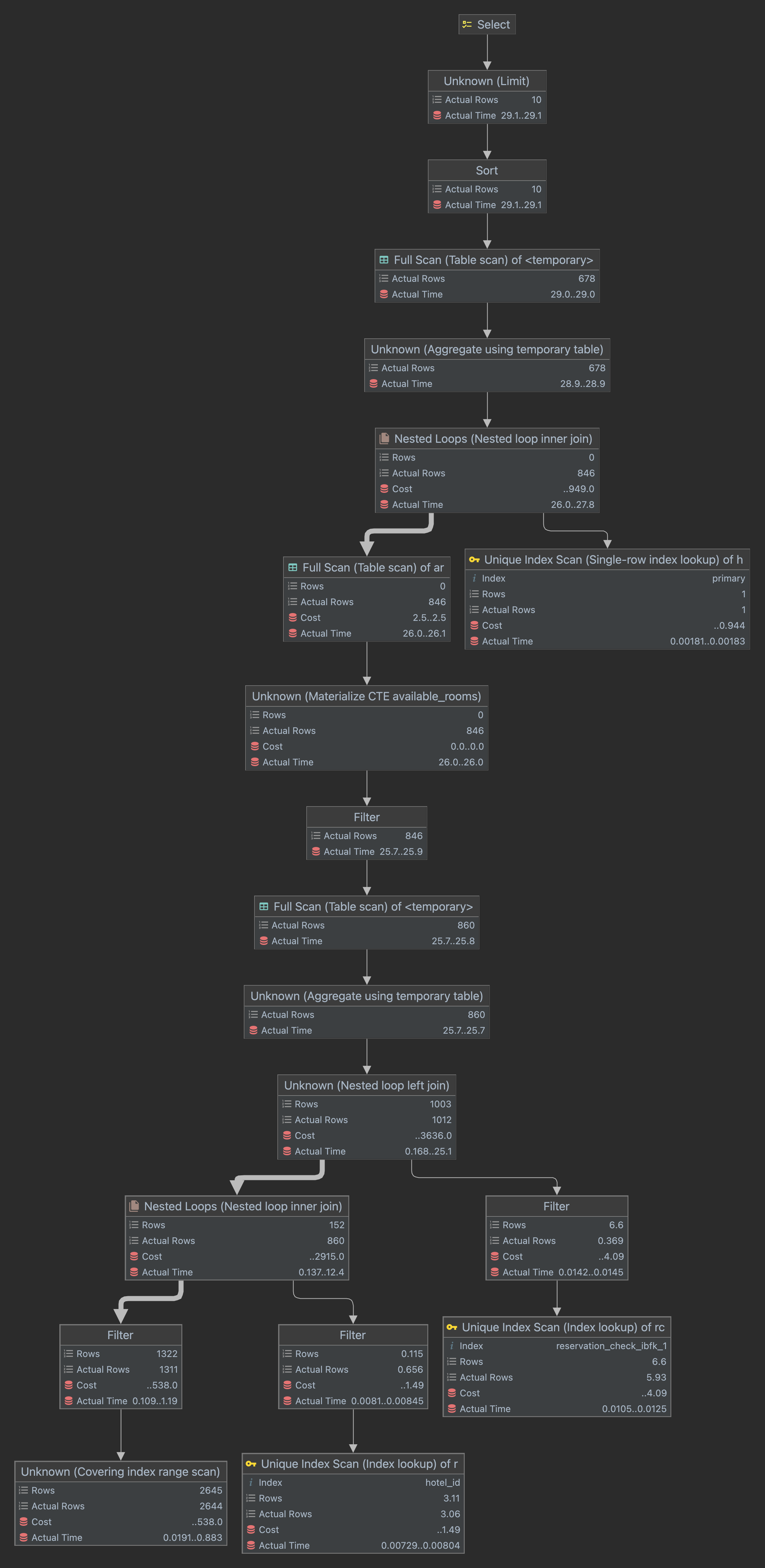
-
실행 계획 상세 설명
**h테이블(hotels)에서h.detail_region_id = 1 AND h.category_id = 1 AND h.id > 100000조건에 맞는 레코드 탐색**- Explain
id select_type table type key key_len ref rows filtered Extra 2 DERIVED h range detail_regions_categories_idx 24 null 196 100 Using where; Using index; Using temporary - Explain Analyze
-> Filter: ((h.category_id = 1) and (h.detail_region_id = 1) and (h.id > 100000)) (cost=40.8 rows=196) (actual time=0.0197..0.146 rows=196 loops=1) -> Covering index range scan on h using detail_regions_categories_idx over (detail_region_id = 1 AND category_id = 1 AND 100000 < id) (cost=40.8 rows=196) (actual time=0.018..0.104 rows=196 loops=1) - 위 과정에서 사용된 인덱스는
key컬럼에서 볼 수 있듯이detail_regions_categories_idx이다. 해당 인덱스는detail_region_id와category_id두 컬럼으로 구성된 복합 인덱스이다. 두 컬럼 다 bigint 자료형이므로 각각 8byte의 용량을 가지지만key_len컬럼을 보면 24인 것을 볼 수 있다. 그 이유는, MySQL의 세컨더리 인덱스에는 기본적으로 PK가 포함되어 있고, 조건을 보면h.id > 100000이 있고, 이를 위해detail_regions_categories_idx에 포함된h.id까지 사용했기 때문이다.
Extra컬럼에 표시된Using temporary메시지와select_type컬럼의DERIVED는 해당 과정에서 임시 테이블이 생성되었다는 뜻이다.Extra컬럼에 표시된Using index메시지는 테이블에 접근하지 않고 인덱스에 포함된 데이터만을 사용하여 쿼리를 처리했다는 의미이다. 즉, 커버링 인덱스가 적용되었다는 뜻이다. 해당 쿼리의SELECT절과WHERE절을 살펴보면detail_regions_categories_idx에 포함된 컬럼만을 사용하고 있기 때문에 실제hotels테이블에 접근하지 않고도 쿼리를 처리할 수 있다.
Extra컬럼에 표시된Using where메시지는 MySQL엔진 레벨에서 필터링이 수행되었다는 뜻이다. 즉, 인덱스를 활용한 검색만으로 조건을 만족하는 데이터를 찾지 못하고 추가적인 필터링 작업이 일어났다는 뜻이다.detail_regions_categories_idx에서h.id는 선행 컬럼이 아니기 때문에 정렬이 선행 컬럼을 기준으로 이루어져 있다. 그렇기 때문에h.id > 100000조건은 인덱스 탐색만으로 해결하지 못하였고, MySQL엔진에서 추가적인 필터링이 이루어진 것이다.
- Explain
- 1번의 결과와
r테이블(rooms)을 Nested loop join- Explain
id select_type table type key key_len ref rows filtered Extra 2 DERIVED r ref hotel_id 8 h.id 3 3.7 Using where - Explain Analyze
-> Nested loop inner join (cost=540 rows=22.5) (actual time=0.061..3.03 rows=157 loops=1) # 1번 과정 -> Filter: ((r.max_people_count >= 3) and (r.price >= 50000) and (r.price <= 200000)) (cost=2.24 rows=0.115) (actual time=0.0141..0.0146 rows=0.801 loops=196) -> Index lookup on r using hotel_id (hotel_id=h.id) (cost=2.24 rows=3.11) (actual time=0.00922..0.0141 rows=3.12 loops=196) - 1번의 결과로 나온 196개의 레코드를 반복문을 돌며
h.id=r.hotel_id를 만족하고200000 >= r.price AND r.price >= 50000 AND r.max_people_count >= 3를 만족하는 레코드를 찾았다.- MySQL 엔진 레벨에서 필터링을 처리했다. (Using where)
- Explain
- 2번의 결과와
rc테이블(reservation_check)을 Nested loop left(outer) join- Explain
id select_type table type key key_len ref rows filtered Extra 2 DERIVED rc ref reservation_check_ibfk_1 8 r.id 6 100 Using where; - Explain Analyze
-> Nested loop left join (cost=697 rows=149) (actual time=0.0933..10.8 rows=187 loops=1) # 2번 과정 # 1번 과정 -> Filter: (rc.stay_date between '2023-06-22' and '2023-06-25') (cost=6.33 rows=6.6) (actual time=0.0485..0.0491 rows=0.382 loops=157) -> Index lookup on rc using reservation_check_ibfk_1 (room_id=r.id) (cost=6.33 rows=6.6) (actual time=0.0206..0.0471 rows=5.86 loops=157) - 2번의 결과로 나온 157개의 레코드를 반복문을 돌며
room.id=rc.room_id를 만족하고rc.stay_date BETWEEN '2023-06-22' AND '2023-06-25'를 만족하는 레코드를 찾았다.- MySQL 엔진 레벨에서 필터링을 처리했다. (Using where)
- Explain
- 3번의 결과를
r.id를 기준으로 그룹핑하고MAX(rc.count) <= r.count조건으로 필터링한 뒤 지금까지의 결과로available_rooms라는 이름의 CTE 생성- Explain
id select_type table type key key_len ref rows filtered Extra 1 PRIMARY ALL null null null 1003 100 Using temporary; Using filesort - Explain Analyze
-> Table scan on ar (cost=2.5..2.5 rows=0) (actual time=11..11 rows=155 loops=1) -> Materialize CTE available_rooms (cost=0..0 rows=0) (actual time=11..11 rows=155 loops=1) -> Filter: (coalesce(max(rc.count),0) <= r.count) (actual time=11..11 rows=155 loops=1) -> Table scan on <temporary> (actual time=11..11 rows=157 loops=1) -> Aggregate using temporary table (actual time=10.9..10.9 rows=157 loops=1) # 3,2,1번 과정 - Explain의
table컬럼을 살펴보면<derived2>라고 되어있는데, 이는id가 2인 단위SELECT문의 결과로 생성된 임시 테이블이라는 의미이다. Extra컬럼의Using temporary메시지를 통해 쿼리 실행을 위해 임시 테이블이 생성되었음을 알 수 있다. 위 경우는 그룹핑 작업을 위해 임시 테이블이 필요하여 생성한 것이다.Extra컬럼의Using filesort메시지는 정렬 시 filesort 방식의 정렬을 이용했음 의미한다.
- Explain
**available_roomsCTE와hotels테이블을 Nested loop join**- Explain
id select_type table type key key_len ref rows filtered Extra 1 PRIMARY h eq_ref PRIMARY 8 ar.hotel_id 1 100 null - Explain Analyze
-> Nested loop inner join (cost=142 rows=0) (actual time=11..11.3 rows=155 loops=1) # 4,3,2,1번 과정 - Explain의
type컬럼을 살펴보면eq_ref라는 타입을 볼 수 있는데, 이는available_rooms의hotel_id를hotels의 PK과 비교하므로available_rooms하나에 무조건 하나의 hotels의 레코드만 나온다는 뜻으로, 이 경우 성능이 뛰어나다.
- Explain
- 5번의 결과를
h.id를 기준으로 그룹핑하고 정렬한 뒤LIMIT 10적용- Explain Analyze
-> Limit: 10 row(s) (actual time=11.6..11.6 rows=10 loops=1) -> Sort: h.id, limit input to 10 row(s) per chunk (actual time=11.6..11.6 rows=10 loops=1) -> Table scan on <temporary> (actual time=11.5..11.5 rows=123 loops=1) -> Aggregate using temporary table (actual time=11.5..11.5 rows=123 loops=1) # 5,4,3,2,1번 과정
- Explain Analyze
이렇게 실행 계획에 대해 알아보고, Explain 명령을 이용하여 실행 계획을 분석하는 것 까지 완료하였다.
