오늘은 과제를 했는데 파이썬을 이용한 웹 크롤링에 대한 TIL을 진행하려고 한다.
IDE는 파이참을 사용한다.
이클립스와 인텔리제이만 주구장창 사용하다가 파이썬에 특화된 IDE인 파이참은 처음 사용해본다.
언어는 파이썬.
먼저, 크롤링 행위 자체는 불법은 아니지만 '안티-크롤링'이라고 크롤링 행위를 방해하는 기술을 도입해놓은 웹페이지들이 존재한다.
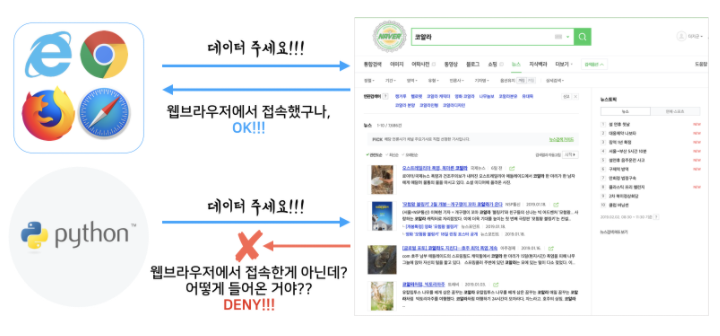
일반적으로는 우리가 일반 웹서비스에 접속해서 데이터를 요청할 때는 웹브라우저를 통해 데이터를 요청하게 되는데,
우리는 코드로 만든 데이터수집 프로그램을 통해서 데이터를 요청하는 경우이기 때문에 일부 웹서비스의 경우에는 요청한 데이터를 돌려주지 않는다.
이 경우는 request 메서드에 header값을 주는데 나중에 다뤄보겠다.
우선은 오늘은 기사를 크롤링하는 것 부터 다룬다.
내가 구현하려는 건 <언론사 별 / 백신 별>로 '코로나 백신' 과 관련된 기사를 크롤링해서 DB에 뿌려주는 기능이다.
생각해봤을 때 언론사와 백신에 대한 분기처리가 필요할 것으로 생각되며, 언론사마다 URL과 프론트의 구성이 다르기때문에 5개를 선정하여 구현하려고 한다.
또한 beautiful soup 라는 모듈을 사용한다.
웹페이지의 데이터를 쉽게 사용할 수 있는 모듈이다.

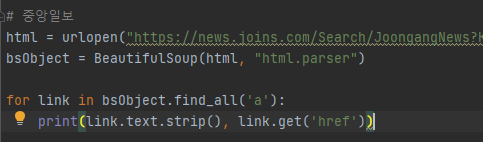
사용법은 이러하다.
뷰티풀수프를 임포트하기 위해 설정해주고, 첫 번째 인자는 str형식, 두 번째 인자는 앞에 넣은 text를 어떻게 요리할 지에 대해 해석기(parser)를 넣어준다.
보통 파이썬에서는 "html.parser"를 넣어주는데 장점은 각종 기능을 완비하며 적절한 속도를 보여주기 때문이다. 단점은 이전 버전의 파이썬에 대해 호환성이 떨어진다는 점이다.
이 상태로 실행을 해보면,
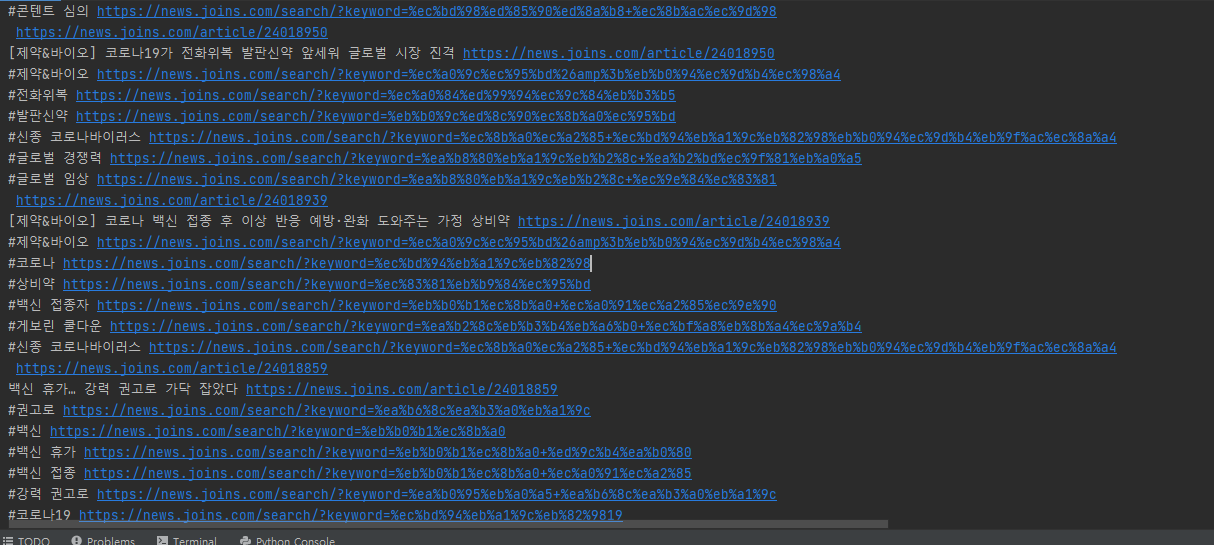
이렇게 기사를 잘 가져온 것을 확인할 수 있다.
다만 a태그를 가진 href녀석들을 다 가져왔기때문에 다른 사용하지 않을 데이터들도 들어왔다.
내일은 뷰티풀수프를 이용해 특정한 태그를 찾을 수 있는 방법을 알아본다.
오늘의 코멘트: 분명 지금 이렇게 해놓으면 나중에 업무에도 사용할 수 있을듯하다.
