데이터분석종합반 3주차
스파르타코딩클럽 데이터분석종합반
강의: 데이터분석종합반
학습일자: 2022/06/15 ~ 2022/06/23
진도: 3-1 ~ 14
============================
맨 위 인포메이션을 일자에서 주차로 바꿨다. 요즘 업무에 치여서 공부를 제대로 못하고 있어서..
============================
3-1. 3주차에 배울 것
1,2주차를 토대로 이것저것 한다는데, 1,2주차를 잘 따라왔으면 무리없다고 한다. 제대로 못따라갔는데요.... 일단 한바퀴 돌리고나서 복습해야지
============================
3-2. 주류 데이터 분석 - 데이터 프레임 익숙해지기
# 판다스 함수들(python)
import pandas as pd
url = 'https://raw.githubusercontent.com/justmarkham/DAT8/master/data/drinks.csv'
drink_df = pd.read_csv(url, ',')
# pd.read_csv(불러올 파일or주소, '구분자') <- sep=''
# 타입 확인
type(drink_df)
# pandas.core.frame.DataFrame
# 상위 5개의 행을 출력
drink_df.head()
# 상위 10개의 행을 출력
drink_df.head(10)
# 하위 5개의 행을 출력
drink_df.tail()
# 하위 5개의 행을 출력
drink_df.tail()
# 데이터프레임의 인덱스 확인
df.index
# RangeIndex(start=0, stop=193, step=1)
# 0번 인덱스부터 193개가 있음 = 인덱스는 0~192, 총데이터는 193개라는 뜻
# 각 컬럼의 타입 출력
```drink_df.dtypes
country object
beer_servings int64
spirit_servings int64
wine_servings int64
total_litres_of_pure_alcohol float64
continent object
dtype: object```
# 데이터프레임의 행과 열의 개수 출력
drink_df.shape
# (193, 6) < 몇행 몇열인지 확인하고 싶을 때
# Numpy 타입으로 출력
drink_df.values # 각 행을 리스트로 만드는 것. numpy 타입임
numpy타입인것 확인. 리스트나 다름없다고 확인
array([['Afghanistan', 0, 0, 0, 0.0, 'AS'],
['Albania', 89, 132, 54, 4.9, 'EU'],
['Algeria', 25, 0, 14, 0.7, 'AF'],
...,
['Yemen', 6, 0, 0, 0.1, 'AS'],
['Zambia', 32, 19, 4, 2.5, 'AF'],
['Zimbabwe', 64, 18, 4, 4.7, 'AF']], dtype=object)
numpy에 대한 대충 설명
# 각 원소를 순차적으로 꺼내서 출력
for element in drink_df.values[0]:
print(element)
Afghanistan
0
0
0
0.0
AS============================
3-3. 주류 데이터 분석 - 데이터 프레임에 익숙해지기 (2)
열에 접근하는 방법, 종합적으로 정보를 출력하는 방법
drink_df에 6개의 열이 있었다. 특정한 열에만 접근하겠다.
하나의 열에 접근하는 방법
데이터프레임의 이름.열의 이름
데이터프레임의 이름['해당 열의 이름']
위 방식으로 출력된 자료들은 표(데이터프레임)이 아닌 시리즈라고 한다
# beer_servings 열에 접근
drink_df.beer_servings
# 또 다른 방법
drink_df['beer_servings']Q. 시리즈끼리 더하기가 가능한가?
dtype이 일치할 경우에는 가능하다
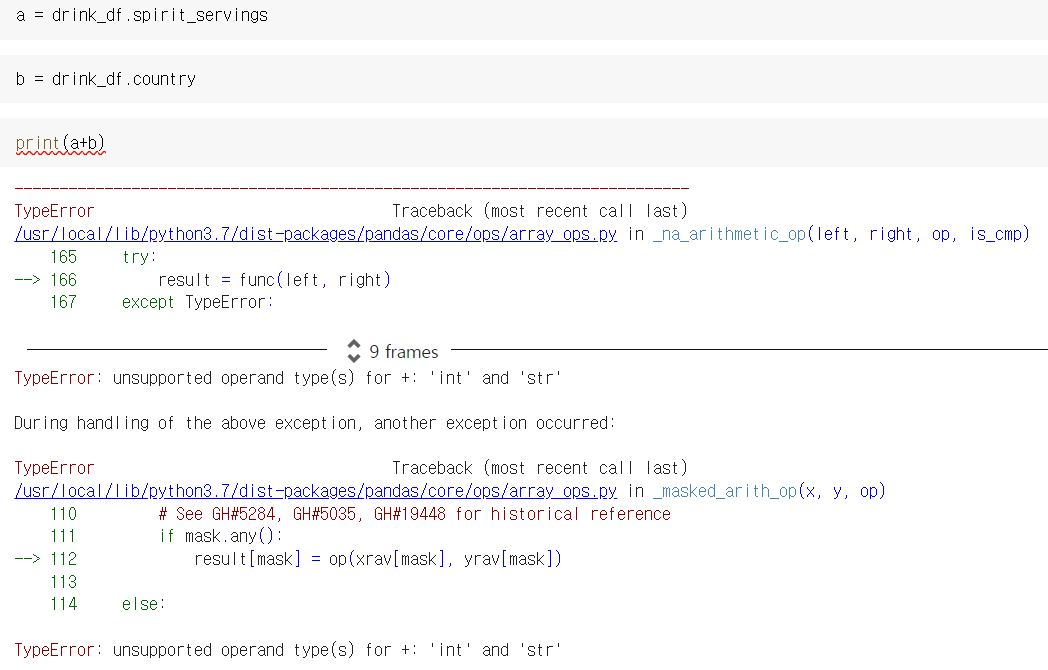
a = drink_df.spirit_servings의 dtype: int
b = drink_df.country의 dtype: str
이땐 에러가 뜨지만!
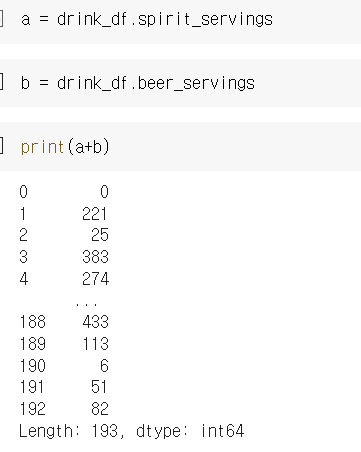
a = drink_df.spirit_servings의 dtype: int
b = drink_df.beer_servings의 dtype: int
이땐 사칙연산 후 나오는 값이 출력된다.
근데 내가 궁금했던건 두 시리즈가 데이터프레임으로 합쳐지는가였는데... 그건 안되고 열을 여러개 불러와야 하나보다.
다수의 열에 접근하는 방법
데이터프레임의 이름[['특정열의 이름1', '특정열의 이름2']]
# 컬럼의 타입 확인
type(drink_df.beer_servings)
# 다수의 컬럼에 접근
drink_df[['beer_servings','wine_servings']]
# 다른 방법
cols = ['beer_servings','wine_servings']
drink_df[cols]
# 데이터프레임의 전반적인 정보
drink_df.info()============================
3-4. 주류 데이터 분석 - 데이터 파악하기
drink_df = 주류데이터 데이터프레임을 담은 변수
drink_df.mean() = 평균
drink_df.max() = 최대값
drink_df.min() = 최소값
drink_df.count() = 개수
drink_df.sum() = 합계
등등...
drink_df.describe() = 각 컬럼들의 모든 정보
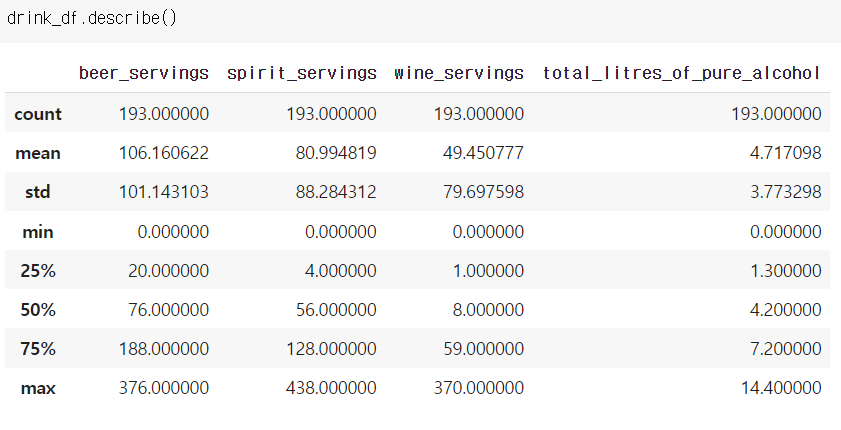
drink_df.mean() 대신 평균 구하는 산수는?
drink_df.beer_servings.sum() / drink_df.beer_servings.count()

============================
3-5. 주류 데이터 분석 - 원하는 데이터 찾기
조건부 로직
건을 걸고 만족하는 데이터만 출력
2주차때 했다고 함...응?
데이터프레임의 이름.특정 열의 이름 == '특정값'
불리언으로 나옴
drink_df.continent == 'EU'
값을 출력하고 싶다면?
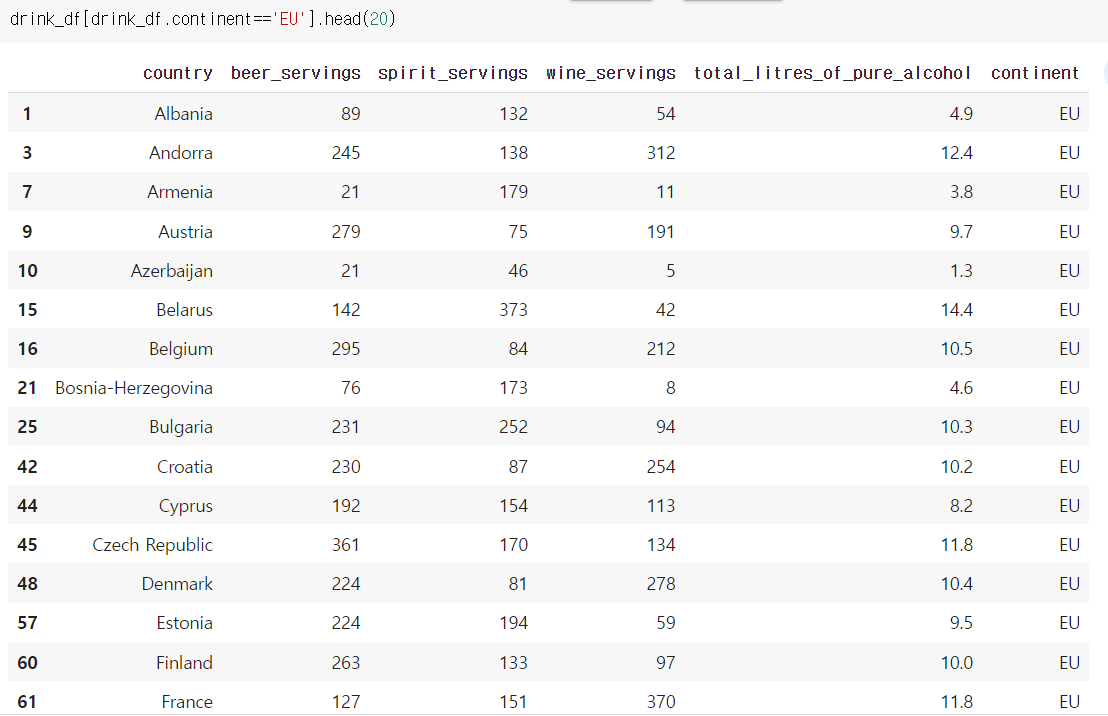
drink_df[drink_df.continent=='EU'].head(20)
데이터프레임의 열을 호출하는 두가지 방법
데이터프레임의 이름.열의 이름
데이터프레임의 이름['열의 이름']
두가지 형식을 모두 사용할 수 있음
drink_df[drink_df.beer_servings > 158]
drink_df[drink_df['beer_servings'] > 158]
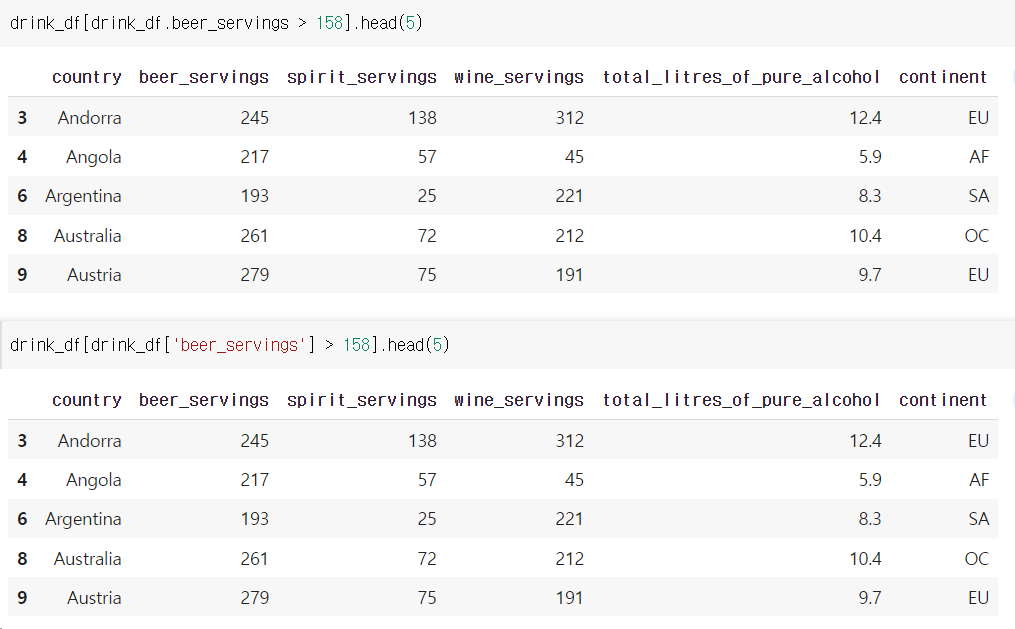
조건을 걸되, 특정 열만 출력할 때
데이터프레임의 이름[['특정 열의 이름1, '특정 열의 이름2']]
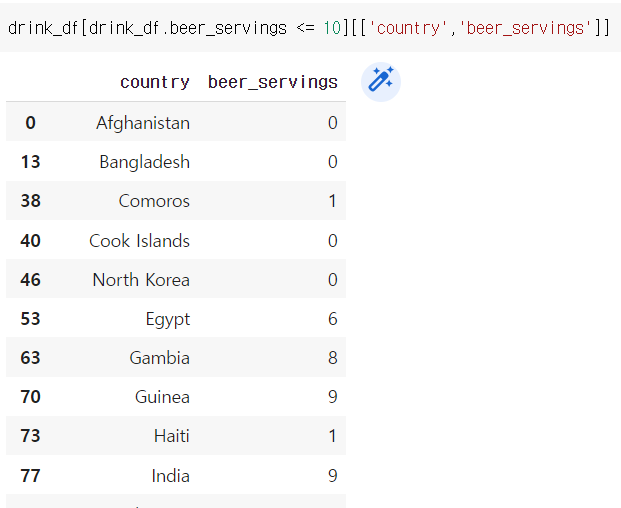
예시) beer_servings 값이 10 이하면서 country, beer_servings 두개 열만 출력
drink_df[drink_df.beer_servings <= 10][['country','beer_servings']]
조건을 걸면서 평균값을 원하면
예시) continent 값이 EU인 것들만 모아서 beer_servings의 평균값
drink_df[drink_df.continent=='EU'].beer_servings.mean()

기타 등등
예시) beer_servings의 평균값을 넘는 beer_servings 값들을 출력
drink_df[drink_df.beer_servings > drink_df.beer_servings.mean()]
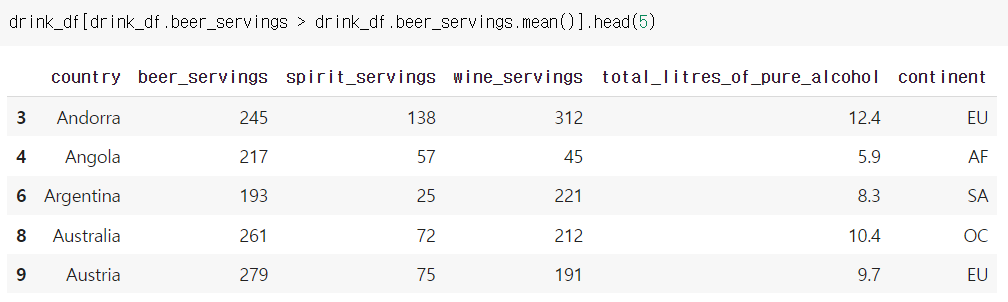
연산자 활용(and, or, not)
&: and
|: or
~: not
A조건 & B조건: A조건과 B조건 모두 만족하는 경우A조건 | B조건: A조건 또는 B조건 둘 중 하나를 만족하는 경우~A조건: A조건을 만족하는 경우의 반대. 즉, A조건을 만족하지 않는 경우.
예) continent가 eu가 아닌 것들만 모으고 싶다면
drink_df[~(drink_df.continent=='EU')]
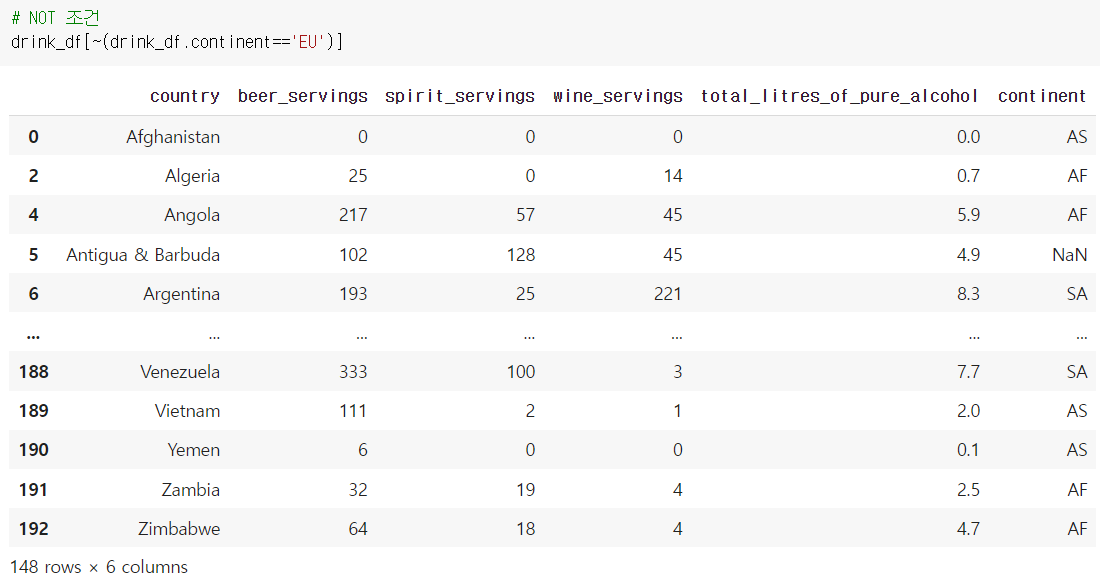
~ 기호 뒤에 소괄호
예) continent가 eu면서 wine_servings가 300 이상인 데이터만
drink_df[(drink_df.continent=='EU') & (drink_df.wine_servings > 300)]
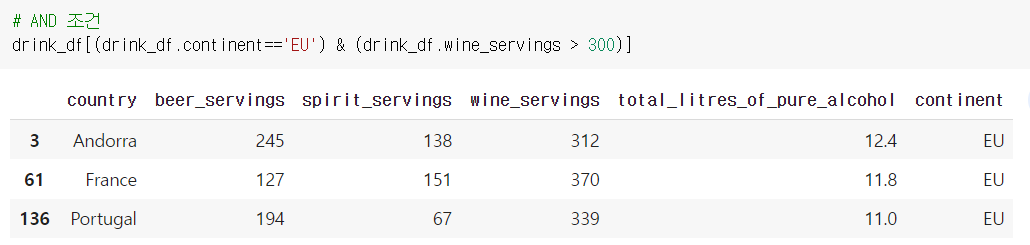
& 양옆에 소괄호
예) eu거나, 와인소비량이 300 이상이거나 둘 중 하나라도 만족하는 데이터의 길이(개수)
len(drink_df[(drink_df.continent=='EU') | (drink_df.wine_servings > 300)])

| 양옆에 소괄호
내가 궁금한 거) 유럽대륙이 아니면서 맥주 소비량이 평균보다 높은 나라와, 맥주 소비량은?
drink_df[~(drink_df.continent == 'EU') & (drink_df.beer_servings > drink_df.beer_servings.mean())][['country', 'beer_servings']]
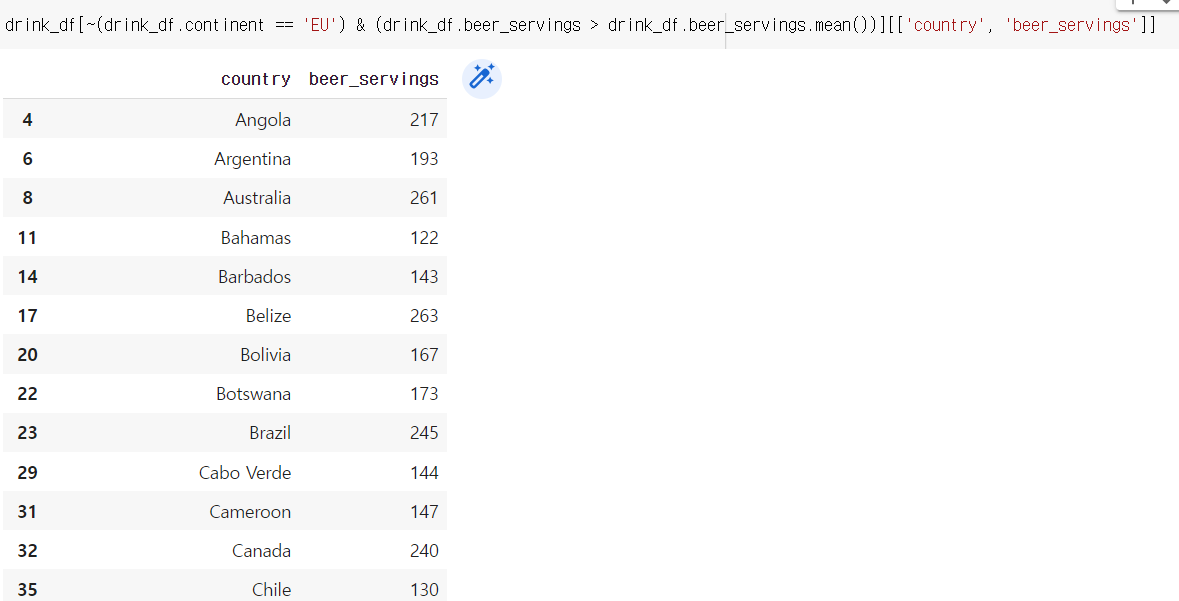

사우스코리아가 역시나 있었다. 근데 이거 맥주소비량이 높은 순서대로 출력되게 하는 방법을 배웠었나..?
============================
3-6. 주류 데이터 분석 - 정렬과 로직과 수치 정보의 결합
문제 풀고 정렬 공부한다고 함. 정렬이 여기서 나오는구나;;
문제: drink_df에서 total_litres_of_pure_alchohol의 값이 최대값인 경우의 country 열을 출력
답: drink_df[drink_df.total_litres_of_pure_alcohol.max() == drink_df.total_litres_of_pure_alcohol]['country']
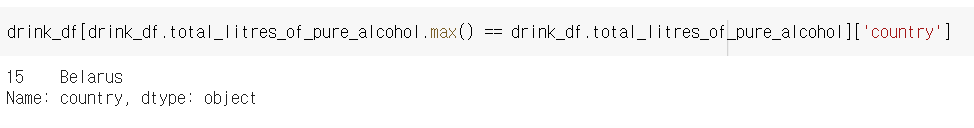
문제: drink_df에서 wine_servings의 값이 300보다 크거나, beer_servings의 값이 300보다 크거나, spirit_servings의 값이 300보다 큰 경우의 country열의 데이터를 모두 카운트하였을 때의 숫자를 출력
답: len(drink_df[(drink_df.wine_servings > 300) | (drink_df.beer_servings > 300) | (drink_df.spirit_servings > 300)]['country'])

.count() 함수를 써도 된다.
drink_df[(drink_df.wine_servings > 300) | (drink_df.beer_servings > 300) | (drink_df.spirit_servings > 300)]['country'].count()

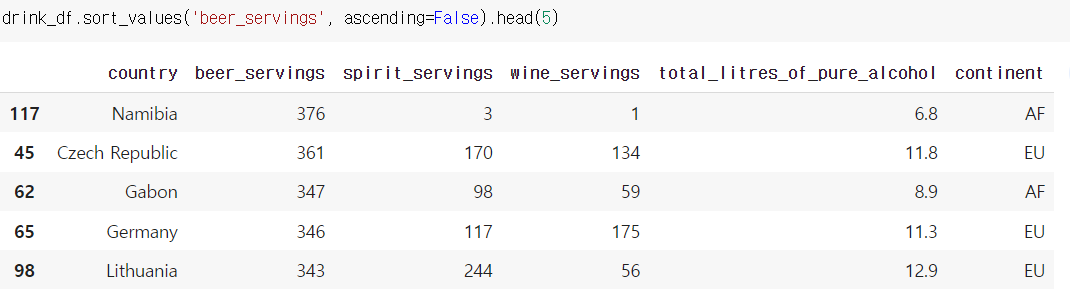
정렬방법
sort.values('정렬할 열') 기본값: 오름차순
sort.values('정렬할 열', ascending=False) 내림차순으로 정렬
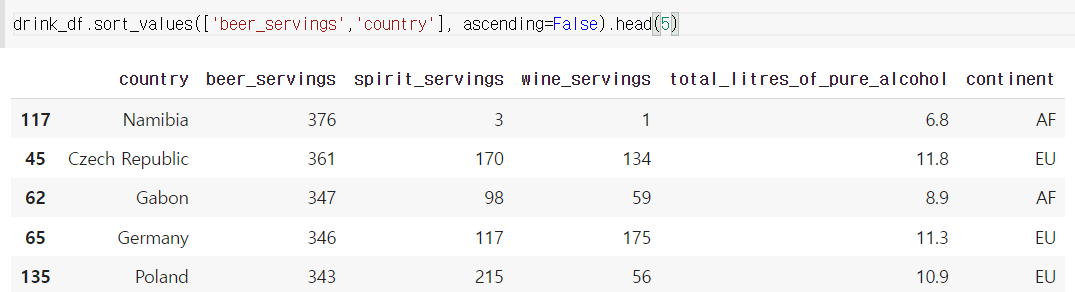
두개의 열을 기준으로 정렬하기
열을 리스트로 넣으면 된다
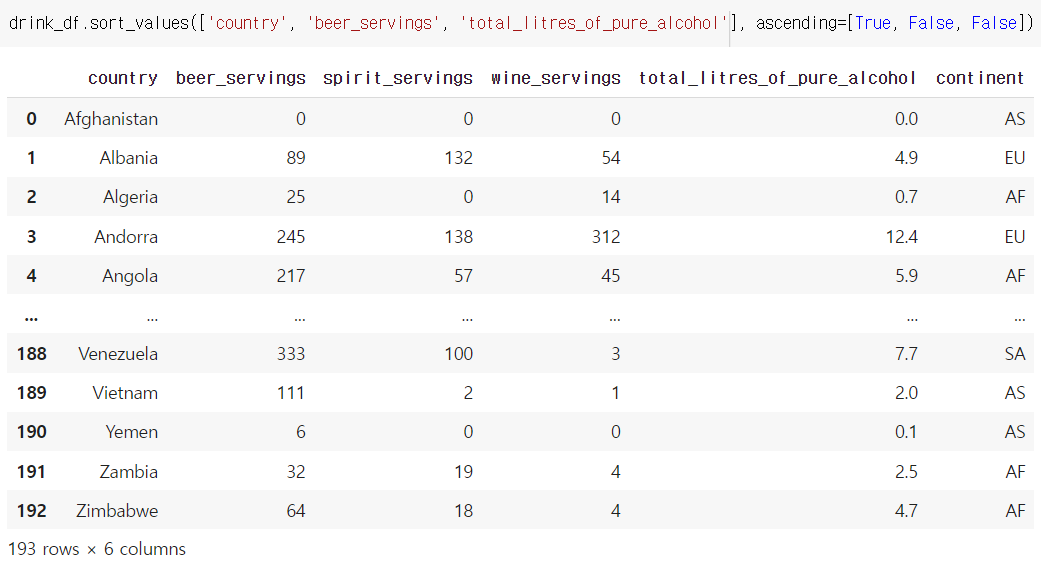
drink_df.sort_values(['beer_servings','country'], ascending=False).head(5)
country를 내림차순, beer_servings를 오름차순으로 정렬하고 싶다면??? 띠요옹???
김준태 튜터님의 답변 코드
df.sort_values(['country', 'beer_servings'], ascending=[True, False])
ascending에도 리스트로 값을 넣을 수 있다! 3개, 4개라도 가능할듯??
가능하다고 한다.
============================
3-7. 탐색적 데이터 분석 - 상관관계 분석
상관 분석이란 두 변수 간의 선형적 관계를 상관 계수로 표현하는 것을 말합니다.
상관 계수를 구하는 것은 공분산의 개념을 포함하는데, 공분산은 2개의 변수에 대한 상관 정도. 2개의 변수 중 하나의 값이 상승하는 경향을 보이면 다른 값도 상승하는 경향을 수치로 표현한 것입니다. 하지만 공분산만으로 두 확률 변수의 상관 관계를 구한다면 두 변수의 단위 크기에 영향을 받을 수 있습니다. 따라서 이를 -1과 1 사이 값으로 변환합니다. 이를 상관 계수라 합니다.
만약 상관 계수가 1에 가깝다면 서로 강한 양의 상관 관계가 있는 것이고, -1에 가깝다면 음의 상관 관계가 있는 것입니다. - 강의자료 중 -
오늘 외워야 할 코드
데이터프레임의 이름.corr(method='pearson')
피어슨 상관관계 분석을 하겠다. 가장 대중적인 방식
sns.heatmap(데이터프레임의 상관계수 데이터)
히트맵. 넣어주는 상관계수를 기반으로 차트형태로 표현해준다.
상관계수를 넣는 것!
sns.pairplot(데이터프레임)
산점도. 차트 대신 시각화 하는 또다른 방법.
상관계수를 넣는게 아니라 데이터 전체를 넣는 것!
기본코드
import pandas as pd
# matplotlib과 seabron 임포트!
import matplotlib.pyplot as plt
import seaborn as sns
샘플용 데이터
test_df = pd.DataFrame({"v1":[100,200,300,400], "v2":[400,200,100,250], "v3":[40,60,60,100]})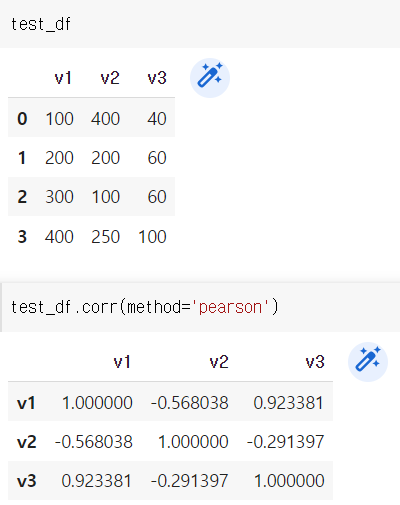
계속해서
corr = test_df.corr(method='pearson')
corr.values
#컬럼 이름을 미리 작성
column_names = ['ver1', 'ver2', 'ver3']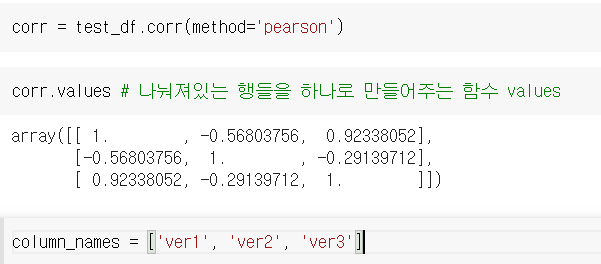
이어서
# 히트맵 코드
# 레이블의 폰트 사이즈를 조정
sns.set(font_scale=2.0)
test_heatmap = sns.heatmap(corr.values, # 데이터
cbar = True, # 오른쪽 컬러 막대 출력 여부
annot = True, # 차트에 숫자를 보여줄 것인지 여부
annot_kws={'size' : 20}, # 숫자 출력 시 숫자 크기 조절
fmt = '.2f', # 숫자의 출력 소수점자리 개수 조절
square = True, # 차트를 정사각형으로 할 것인지
yticklabels=column_names, # x축에 컬럼명 출력
xticklabels=column_names) # y축에 컬럼명 출력
plt.tight_layout()
plt.show()
# 산점도
sns.pairplot(test_df)
plt.show()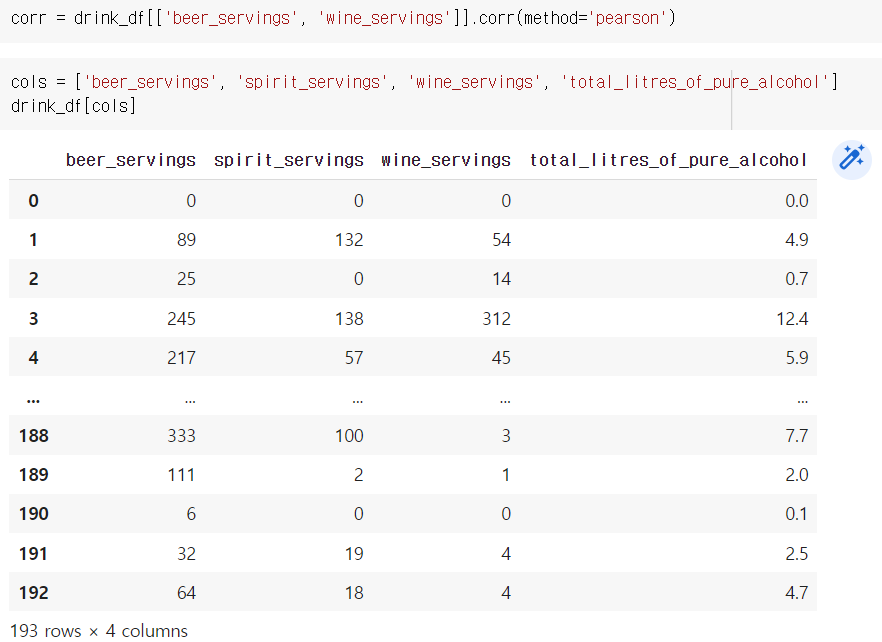
점들이 각각의 데이터.
좌하귀 데이터 기준) v1이 100일 때, v3는 40이라는 느낌의 데이터!
막대는 히스토그램. 빈도를 그래프 형태로 나타냄
주류 데이터 분석
맥주소비량과 와인소비량 간의 상관관계 분석
corr = drink_df[['beer_servings', 'wine_servings']].corr(method='pearson')
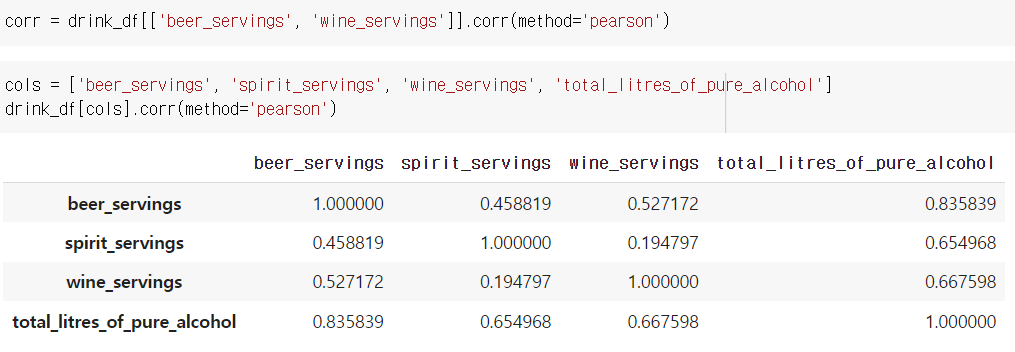
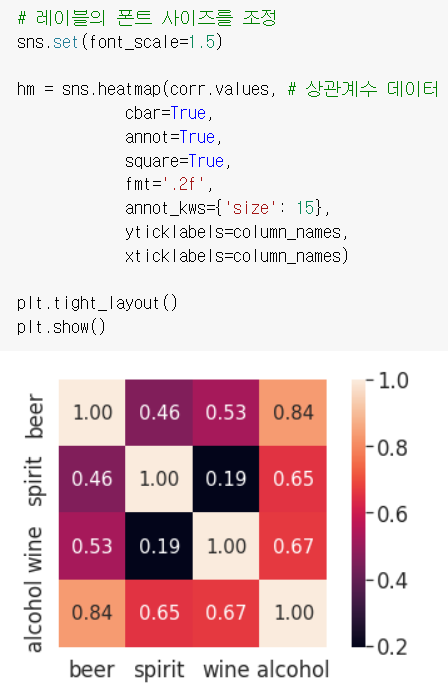
# 주류 데이터 히트맵 코드
# 레이블의 폰트 사이즈를 조정
sns.set(font_scale=1.5)
hm = sns.heatmap(corr.values, # 상관계수 데이터
cbar=True,
annot=True,
square=True,
fmt='.2f',
annot_kws={'size': 15},
yticklabels=column_names,
xticklabels=column_names)
plt.tight_layout()
plt.show()
# 주류데이터 산점도
# 시각화 라이브러리를 이용한 피처간의 scatter plot을 출력합니다.
sns.set(style='whitegrid')
sns.pairplot(drink_df[['beer_servings', 'spirit_servings',
'wine_servings', 'total_litres_of_pure_alcohol']])
plt.show()============================
3-8. 탐색적 데이터 분석 - 시각화 기초
결측값 처리
결측값 삭제 = .dropna()
결측값 채움 = .fillna('넣을내용')
샘플데이터(drink_df)는 대륙 컬럼에 빈칸이 있다.
# 결측치를 'ETC'로 변환
drink_df.continent = drink_df['continent'].fillna('ETC')
drink_df['continent'].isnull().sum()
결측치가 사라진 모습
파이차트
원모양의 그래프
라벨 데이터, 비율 데이터가 필요
value_counts()
각 종류, 각 값에 대해서 개수를 파악함
drink_df['continent'].value_counts()

왼쪽의 대륙 알파벳은 .index, 우측의 숫자는 .values로 접근.

자료형을 리스트형태로 만드는 함수는 tolist()

그냥 values를 하면 numpy 형태임. (판다스와 넘파이는 뗄레야 뗄 수 없는 관계)
아무튼 얘네를 변수에 담은 뒤에 matplotlib를 통해서 파이차트로 변환
# 파이차트 출력코드
# plt 임포트 한 상태에서(import matplotlib.pyplot as plt)
plt.pie(pie_value, labels=pie_index, autopct='%.02f%%')
plt.title('Percentage of each continent')
plt.show()plt.pie(데이터값, labels=라벨값, autopct=소수점 몇째짜리까지 출력할지)
plt.title('타이틀로 지정할 이름')
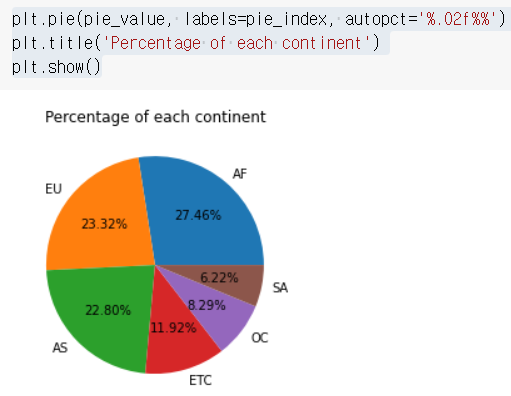
파이차트 생성 절차
pandas, plt 임포트
value_counts()를 통해 원하는 자료 추출(라벨과 값)
- 데이터프레임['컬럼'].value_counts().index -> 인덱스 추출
- 데이터프레임['컬럼'].value_counts().values -> 값 추출
각각의 데이터를 변수에 저장
- 데이터프레임['컬럼'].value_counts().index.tolist() -> 인덱스를 리스트로 저장
- 데이터프레임['컬럼'].value_counts().values.tolist() -> 값을 리스트로 저장(하지 않으면 넘파이형태)
파이차트 생성
plt.pie(값 리스트 변수, labels=인덱스 리스트 변수, autopct='%.02f%%') autopct에서 소수 몇째짜리까지 출력할지 지정
plt.title('제목 지정')
plt.show()
group by
sql에서 다뤘던 그 그룹바이...?
특정 열을 기준으로 그룹핑 후 통계적인 수치를 확인
데이터프레임의 이름.groupby('그룹핑 기준이 되는 열')['보고자 하는 열'].통계 함수
예) 대륙별 평균 맥주 소비량은?
drink_df.groupby('continent')['beer_servings'].mean()

예) 대륙별 모든 수치의 평균치는?
추출값(대괄호 안에 있는거)를 빼고 통계함수 넣으면 됨
drink_df.groupby('continent').mean()
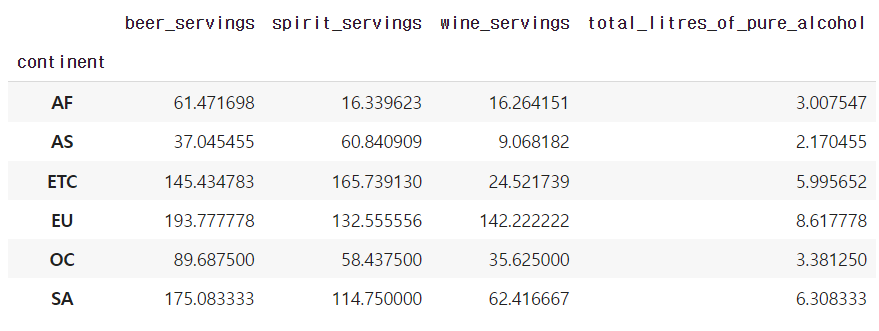
예) 총 알코올 소비량 평균보다 더 많이 알콜을 섭취하는 대륙은?
(1) 총 알콜 소비량 평균을 알아야 함
total_mean = drink_df.continent.mean()
4.717098445595855 출력됨
(2) 대륙별 알콜 소비량 평균을 알아야 함
continent_mean = drink_df.groupby('continent')['total_litres_of_pure_alcohol'].mean()

(3) 조건문으로 만족하는 값만 출력
그룹별로 묶은 뒤에 조건문을 만족하는지?의 순으로 코딩해야함
continent_over_mean = continent_mean[continent_mean >= total_mean]

조건문 복습!
데이터프레임의 열을 호출하는 두가지 방법
데이터프레임의 이름.열의 이름
데이터프레임의 이름['열의 이름']
두가지 형식을 모두 사용할 수 있음
drink_df[drink_df.beer_servings > 158]
drink_df[drink_df['beer_servings'] > 158]
*drink_df.continent == 'EU' ---> 불리언 형태로 출력됨
대괄호 안에서 따옴표를 언제 쓰냐가 좀 헷갈린다! 튜터님한테 물어봐야지...
개인적으로는,
continent_over_mean = continent_mean[continent_mean >= total_mean]
여기에서 대괄호 안에 따옴표가 없는 이유는 컬럼이 하나뿐인 변수라 그런게 아닌가 싶다.
예) 평균 wine_servings이 가장 높은 대륙은?
.idxmax() 인덱스맥스 함수
시리즈 중에서 가장 높은 값을 출력함
drink_df.groupby('continent').mean().idxmax()

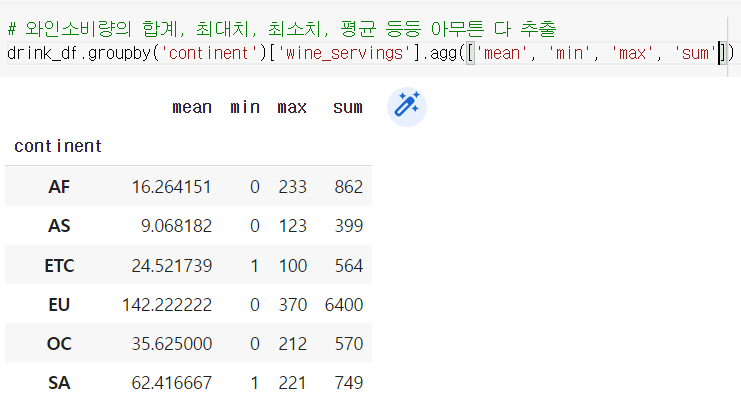
예) 각 대륙 별로 wine_servings 소비에 대해서 평균, 최소, 최대값, 합을 출력해보자.
.agg() 어그 함수
여러가지 수치정보를 표시하는 함수를 동시에 사용 가능
drink_df.groupby('continent')['wine_servings'].agg(['min', 'mean', 'max', 'sum'])
============================
3-9. 탐색적 데이터 분석 - bar chart 시각화
matplotlib를 이용해서 시각화한다.
# plt 기본코드
import matplotlib.pyplot as plt바 차트, 즉 막대그래프에는 3가지 자료가 필요하다
- 인덱스(바의 위치를 결정)
- 레이블(바 차트로 사용할 데이터의 이름이 담긴 리스트)
- 데이터 값(이름에 해당하는 값을 가진 리스트. 실질적인 데이터)
# 바차트 샘플코드
# 여기서 index 값인 0, 1, 2는 순차적으로 어디에 배치될 것인지를 의미합니다.
# 어떤 의미인지 궁금하다면 0, 1, 5로 바꿔서 실행해보세요!
index = [0, 1, 2]
years = ['2017', '2018', '2019']
values = [100, 400, 900]
plt.bar(index, values, width=0.2, color='g') # width = 굵기, color = 색깔
plt.xticks(index, years) # xticks = 라벨부분을 설명하기 위한것
plt.show()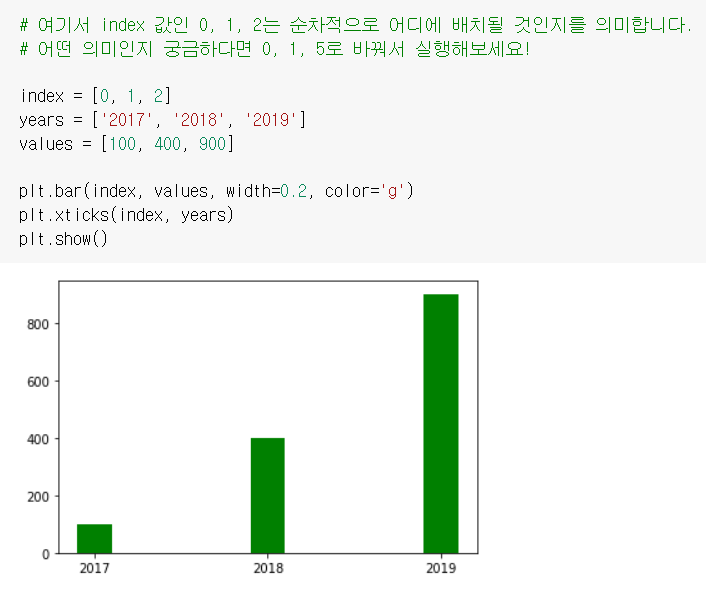
근데, 인덱스가 백개, 천개라면???
numpy 모듈(arange) - 인덱스가 백만개일 때
numpy 모듈을 사용한다
import numpy as np
np.arange(3)

백개든 천개든 문제없다 이말이야
그러므로 위 바 차트 예제 코드에서 index는 이렇게 수정할 수 있다.
index = np.arange(len(year))
혹은 plt.bar()안에서 index라는 함수 대신 np.arange(len(year))
이걸 그대로 적용하면,
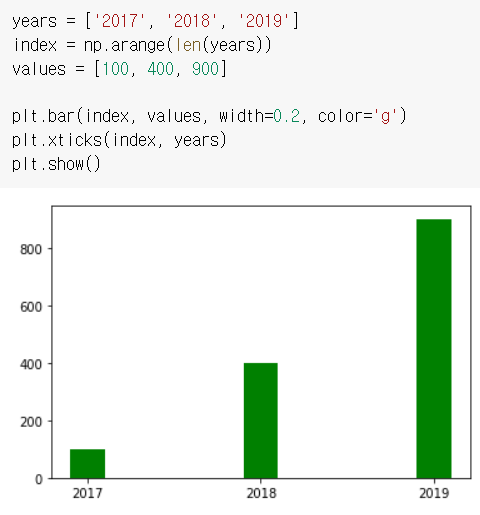
이렇게 된다
대륙별 맥주소비량에 대한 통계수치를 가지고 실습
# 대륙별 주류 데이터(맥주 소비량에 대한 통계수치)
beer_servings_table = drink_df.groupby('continent').beer_servings.agg(['mean', 'min', 'max', 'sum'])
print(beer_servings_table)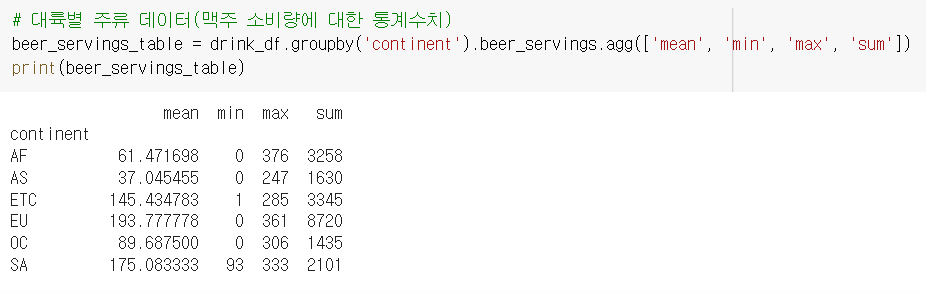
여기서 한가지 발견
값들을 추출할 때 사용할 수 있는 방법
1) beer_servings_table['mean'].values.tolist()
2) beer_servings_table['mean'].tolist()
둘 다 똑같다
맥주소비량 데이터를 바 차트로 만들기 위한 인덱스 설정
index = np.arange(len(beer_servings_table.index.tolist()))

이제 바 차트를 만들어보자!
# 바 차트에 넣을 데이터 완성 및 차트 출력
continents = beer_servings_table.index.tolist()
values = beer_servings_table['mean'].values.tolist()
plt.ylabel(beer_servings)
plt.bar(index, values, width = 0.2, color = 'r')
plt.xticks(index, continents)
plt.show()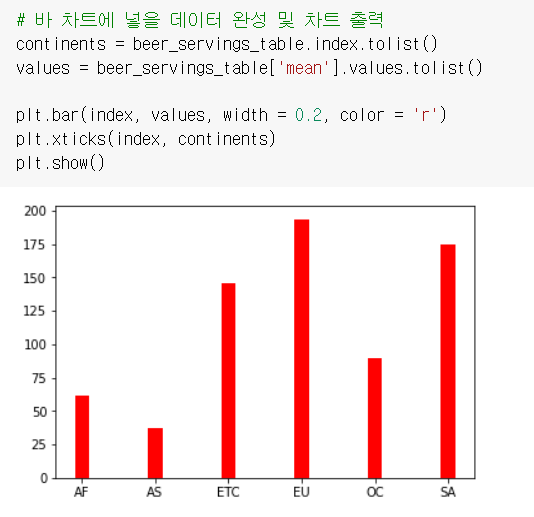
잡다한거 조금 더 추가하면
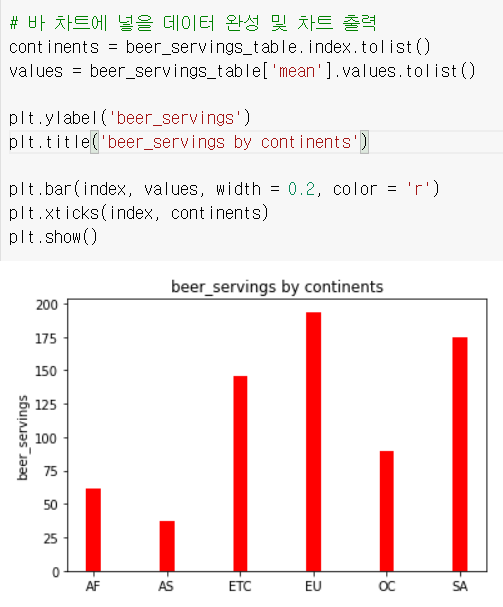
이렇게 됩니다.
============================
3-10. 코로나 데이터 분석 - 분석 준비
별 내용 없었으니까 패스
============================
3-11. 코로나 데이터 분석 - 차트 그리기
뼈대 - 판다스와 시각화모듈, csv파일 임포트
#판다스 임포트
import pandas as pd
#csv파일 임포트하기
###
#시각화모듈 임포트
import matplotlib.pyplot as plt
import seaborn as sns일별 확진자 수 데이터
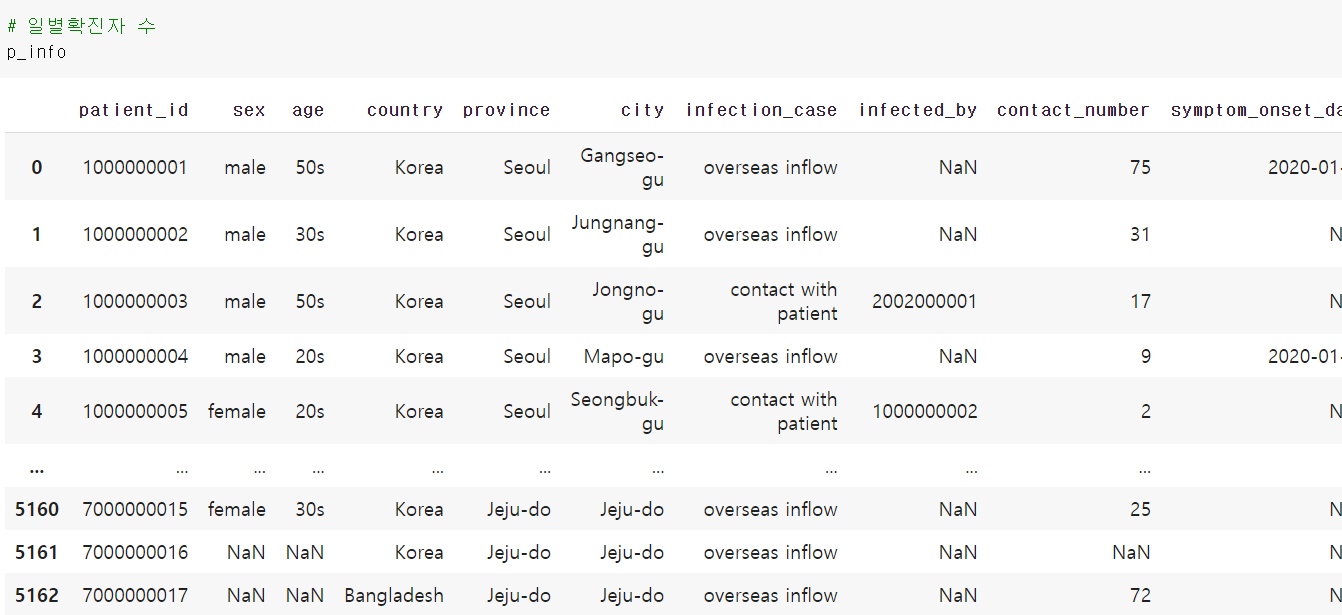
일별 확진자 수 그룹화
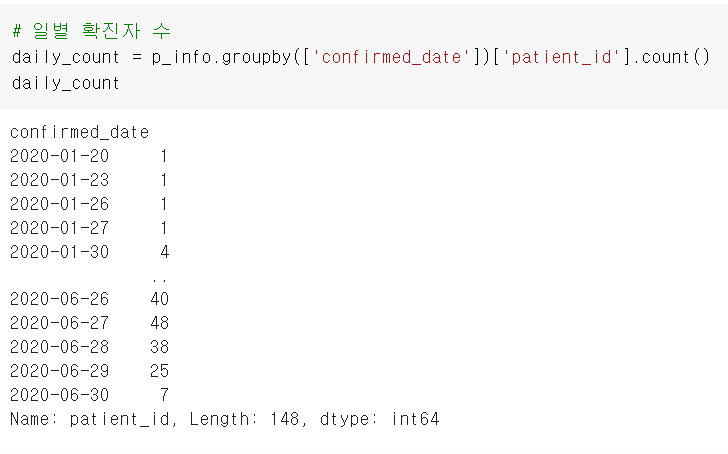
시각화 기초 중의 기초
변수.plot()
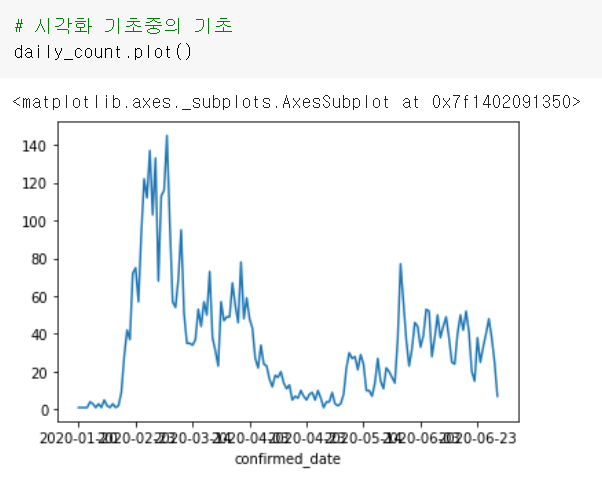
날짜가 너무 많아서 겹치고 잘 안보이고 아무튼 불편하긴 함. 그래서!
plt.rcParams['figure.figsize'] = (15, 5)
차트의 가로, 세로 길이 조절
plt.title('number of daily confirmed patients')
원래는 마지막에plt.show()가 들어가야 출력된다.
그러나 코랩에서는 편의성을 위해 알아서 출력해줄 뿐임
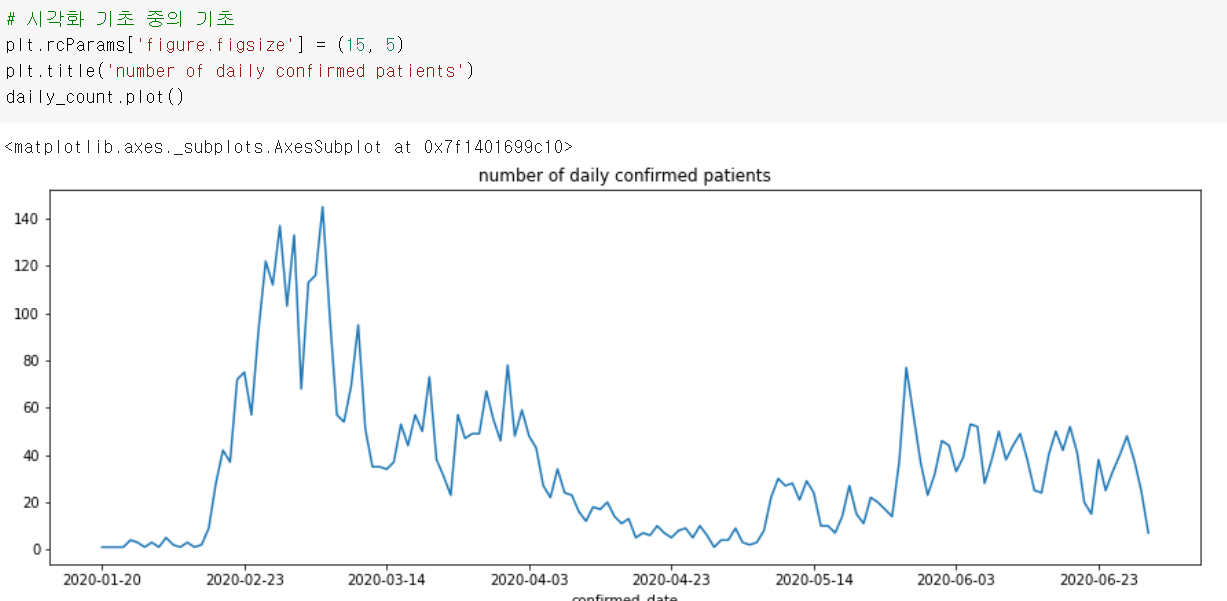
누적 확진자 수 데이터
daily_count.cumsum()
cumulative sum의 줄임말
누적으로 합하면서 데이터를 만들어나감
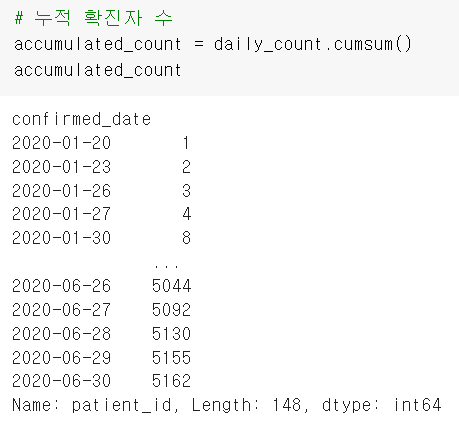
마찬가지로 시각화
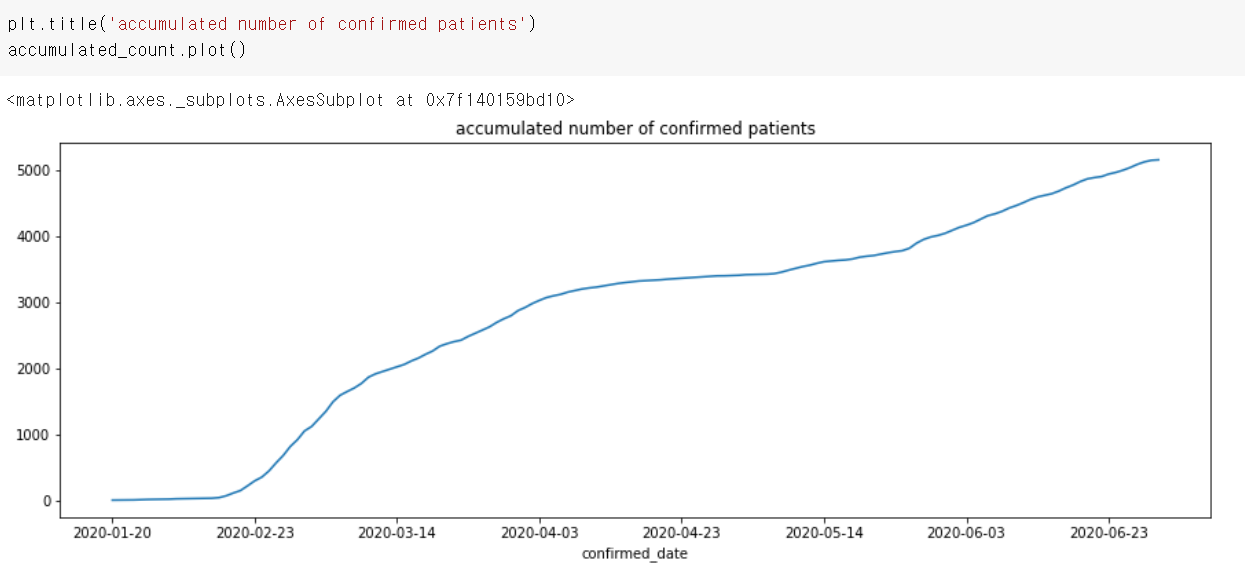
일별 확진자 수 데이터 시각화할 때 plt.rcParams['figure.figsize'] = (15, 5)를 통해서 설정을 변경해줬기 때문에, 이번 차트도 길게 나왔다.
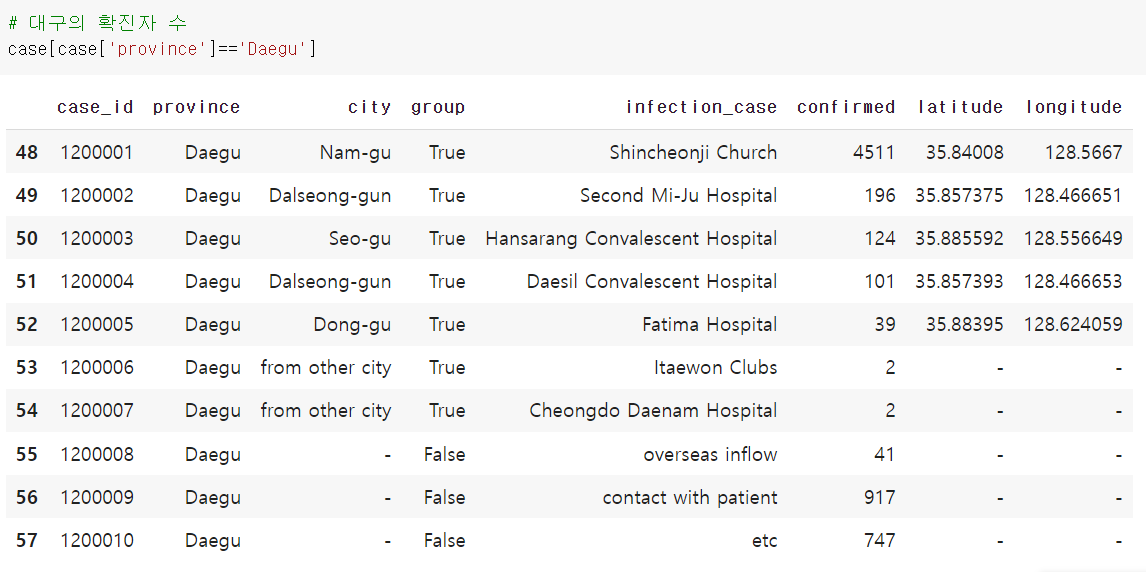
지역별 확진자 수 시각화
case 문서 활용, province가 Daegu인 것만 찾기
case[case['province']=='Daegu']
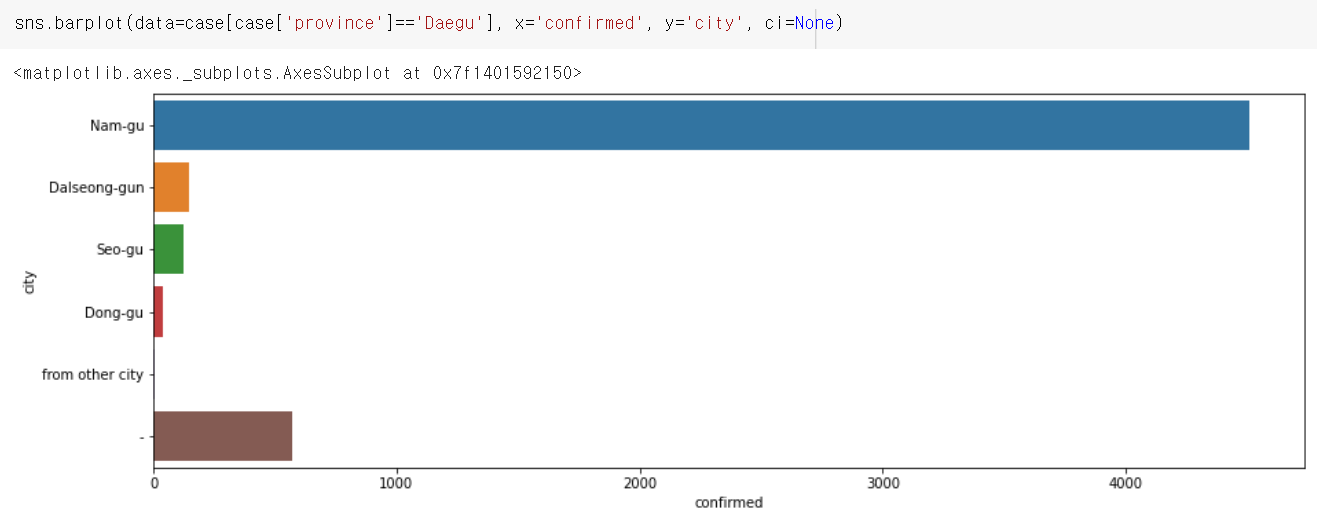
막대그래프로 표시할건데, 지난시간과 달리 조금 간단하게 만들 수 있다.
seaborn 모듈의 barplot() 함수
sns.barplot(data=case[case['province']=='Daegu'], x='confirmed', y='city', ci=None)
x = x축에 해당할 data 내의 열
y = y축에 해당할 data 내의 열
ci = 오차범위를 표시하기 위한 옵션. 당장 쓸건 아님
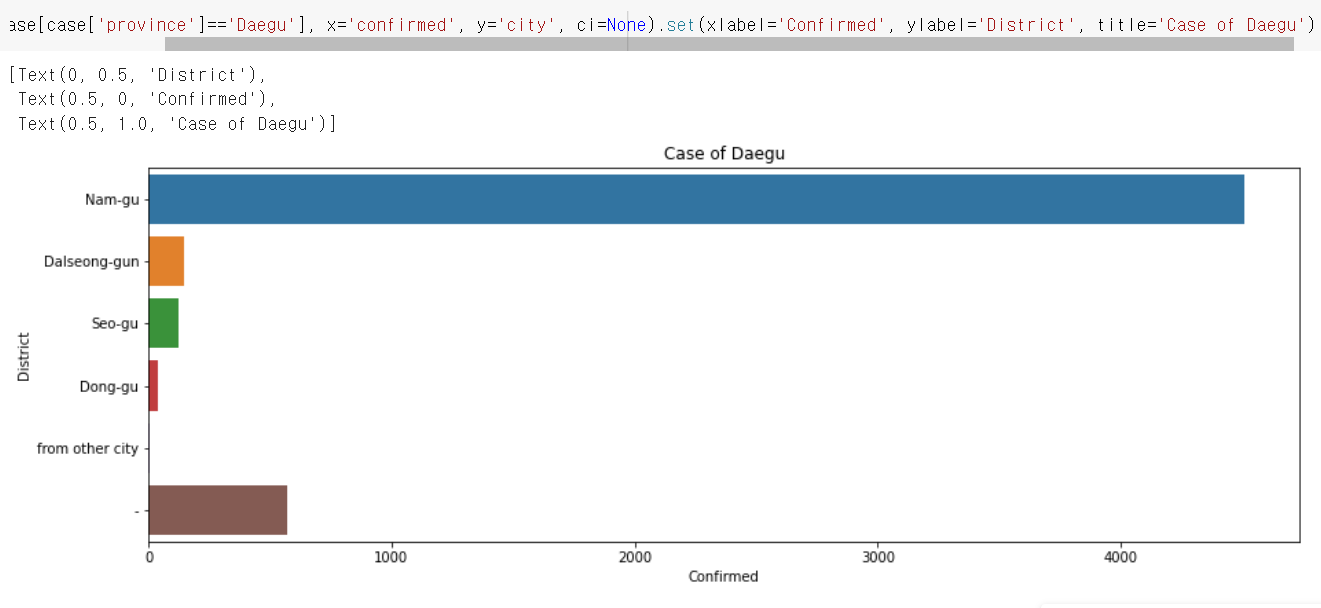
x라벨 = confirmed / y라벨 = city를 바꾸고 싶다면?
set()
sns.barplot(데이터,x,y,ci).set(xlabel='Confirmed', ylabel='District', title='Case of Daegu')
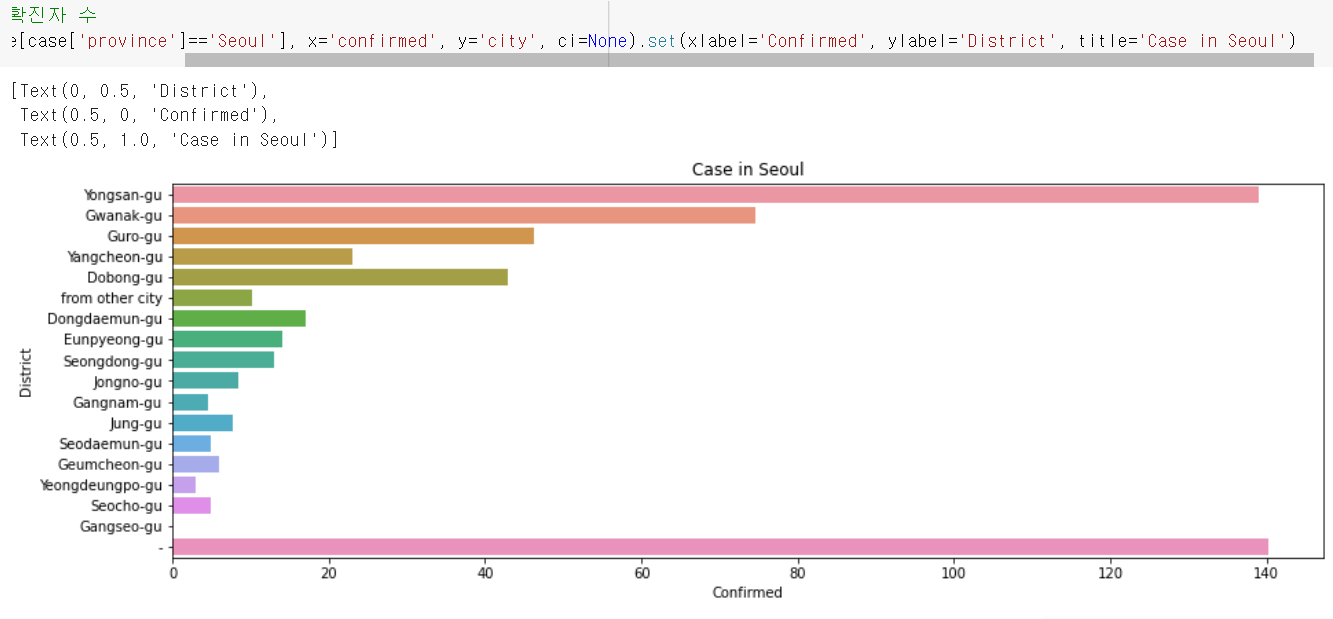
복습) 서울의 구별 확진자 수
sns.barplot(data=case[case['province']=='Seoul'], x='confirmed', y='city', ci=None).set(xlabel='Confirmed', ylabel='District', title='Case in Seoul')
파이차트 만들기 연습
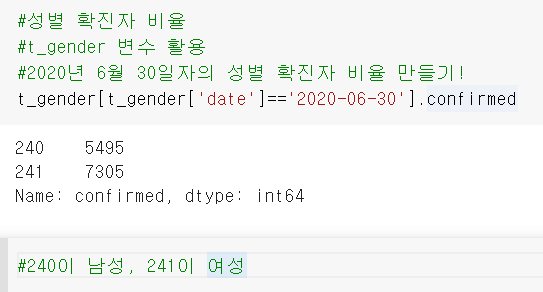
성별 확진자 비율
t_gender 변수 활용
2020년 6월 30일자의 성별 확진자 비율 만들기!
t_gender[t_gender['date']=='2020-06-30'].confirmed
파이차트 준비물
라벨, 레이블(데이터가 어디 속해있는지 표시하는), 데이터
튜터님이 말은 이렇게 3개 말했는데,
라벨이랑 데이터만 있으면 됨. 사이즈 지정해주고.
pie_label = ['male', 'female']
pie_value = t_gender[t_gender['date']=='2020-06-30'].confirmed.values.tolist()

plt.pie(pie_value, labels=pie_label, autopct='%.02f%%')
plt.show()
파이차트 코드 정리(원형 그래프)
#matplotlib 임포트
import matplotlib.pyplot as plt
#변수에 데이터원본(csv파일) 할당
#파이차트엔 데이터, 라벨이 필요
#라벨과 데이터는 리스트 형태로 저장되어야 함
#차트 출력
plt.pie(데이터를 담아둔 변수, labels=라벨을 담아둔 변수, autopct='%.02f%%')
#여기서 autopct는 숫자 표시형식
plt.show()연령별 확진자 비율 확인
2020년 6월 30일자 기준으로 확인할 것
t_age 데이터 활용
t_age[t_age['date']=='2020-06-30']
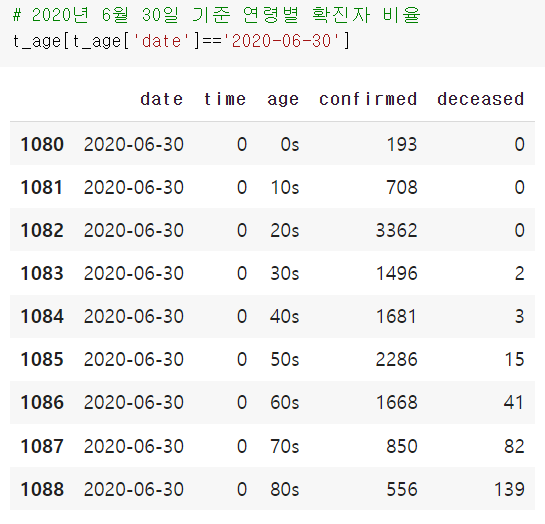
여기서 인덱스 만들고, 라벨 만들고, 밸류 만들면 됨
파이차트 진행순서 복습
# 정제된 데이터를 변수에 할당 (조건문 활용)
population_by_age = t_age[t_age['date']=='2020-06-30']
# 라벨과 데이터를 담은 변수를 선언
pie_labels = population_by_age['age'].values.tolist()
pie_valeus = populatio_by_age['confirmed'].values.tolist()
# 파이차트의 크기 조정
plt.figure(figsize = (15, 15))
# 파이차트 실행(코랩에선 불필요)
plt.show()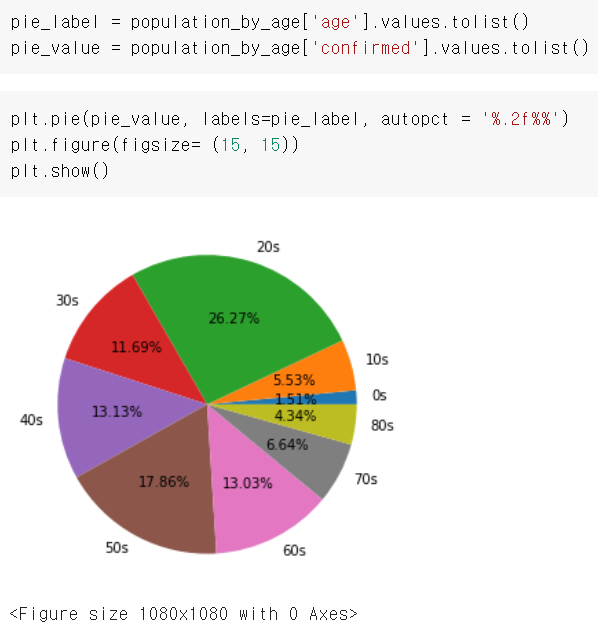
autopct와 plt.figure(figsize=(숫자,숫자))에 대해
autopct 자체가 백분율을 표시하는 듯 하다. 그렇다고 없이 쓰자니 차트가 이상하게 나온다. 파이차트, 원형그래프 자체가 백분율을 나타내기 위한 차트인가 싶다. 나중에 찾아봐야지.
plt.figure(figsize=(15,15))로 코딩했는데, 이걸 (1,1)로 하든 (150,150)으로 하든 눈으로 보기엔 차이가 없었다.
다만, 파이차트 밑에 figure size 1080x1080이라고 써있는 부분이 늘었다 줄었다 하더라.
============================
3-12. 코로나 데이터 분석 - 지도 시각화
와 이건 뭐지? 네이버지도나 카카오지도 쓰는건가? ㅎㅎㅎ;;그랬음좋겠다.
파이썬 이용하여 지도 띄우기
탐색적 데이터 분석 - folium으로 지도 시각화
folium - 파이썬 지도 시각화 패키지
특정 지역을 표시하고자 할 때는 Map() 함수를 사용해서 표시하고자하는 지역의 위도와 경도를 입력하면 됩니다. zoom_start는 처음에 표시할 때 얼마나 확대를 할 지를 결정하는 값으로 궁금하다면 값을 바꿔서 여러번 실행해보시기 바랍니다.
folium 기본 형식
import folium
.map(location = [위도, 경도], zoom_start=숫자, titles = 옵션)
예) seoul = folium.map(location=[37.55, 126.98], zoom_start=12, tiles='Stamen Terrain')
folium 맵 옵션
Folium의 Map() 함수을 이용해서 브라우저에 지도를 표시할 때 사용할 수 있는 옵션은 Stamen Terrain, Stamen Toner, OpenStreetMap 등 여러가지가 있으며 옵션을 지정하지 않으면 기본적으로 OpenStreetMap 형태(기본값)로 출력됩니다.
네이버나 카카오 api를 이용하는건 아니었군요
============================
3-13. 코로나 데이터 분석 - 히트맵 그리기
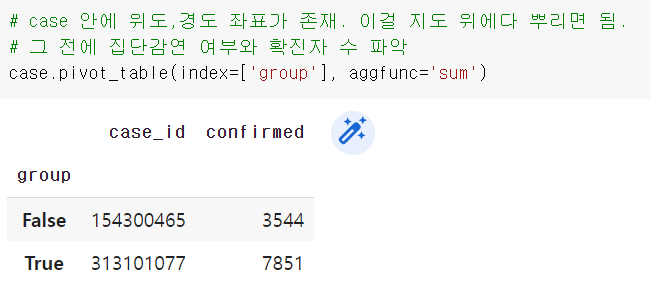
case 데이터에 확진자의 위도,경도가 포함돼있음. 이 데이터를 이용해서 지도 위에 좌표를 뿌리면 됨. marker가 나오려나?
pivot_table() 함수
데이터.pivot_table(index=['열'], aggfunc='사용할함수')
case 내의 group 컬럼 = 지역 내 집단 감염 여부(y=true, n=false)
피벗테이블을 이용해서 true끼리 그룹화, false끼리 그룹화해서 개수 파악하기
case.pivot_table(index=['group'], aggfunc='sum')
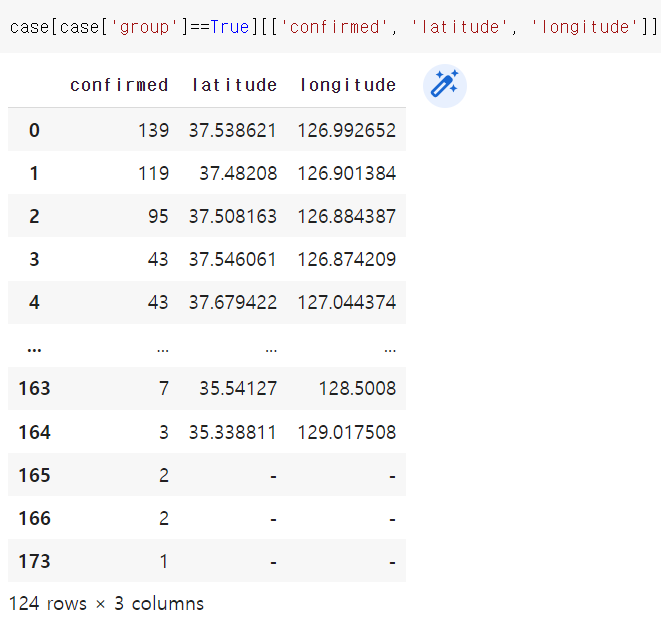
group = true인 값에 대해서만 확진자 수, 위도, 경도 추출하기
case[case['group']==True][['confirmed', 'latitude', 'longitude']]
위도경도가 -인 데이터는 필요없으니 삭제(결측치는 아님, 결측치는 NaN으로 나옴)
local_infected = case[(case['group']==True) & (case['latitude'] != '-') & (case['longitude'] != '-')][['confirmed', 'latitude', 'longitude']]
꼼꼼하게 재확인(.isnull().sum() 이용)
이제 이 데이터를 지도에 띄우면 된다
위에서 만든 local_infected라는 변수와 folium 패키지 활용
folium 내의 plugins 함수
포리움으로 띄운 지도 위에 뭔가를 표시할땐 plugins 함수가 필요
folium 을 변수에 담아서 활용
#예제 코드
import folium
from folium import plugins
latitude, longitude = 35.9078, 127.7669 # 대한민국의 좌표
S_korea = folium.Map(location = [latitude, longitude], zoom_start = 8)
S_korea.add_child()
어떤 요소를 추가할때 쓰는 함수
예)
S_korea.add_child(plugins.HeatMap(zip(local_infected['latitue'], local_infected['longitude'], local_infected['confirmed']), radius = 18))
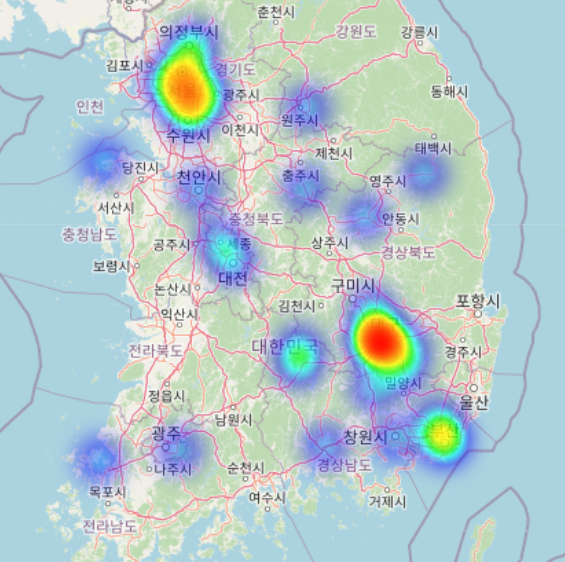
HeatMap = 수치가 높을수록 색이 달라지는 요소
zip = 데이터들을 '묶어서' 히트맵으로 사용하겠다는 뜻
radius = 마커의 크기
S_korea.add_child(plugins.HeatMap(zip(local_infected['latitude'], local_infected['longitude'], local_infected['confirmed']), radius = 18))
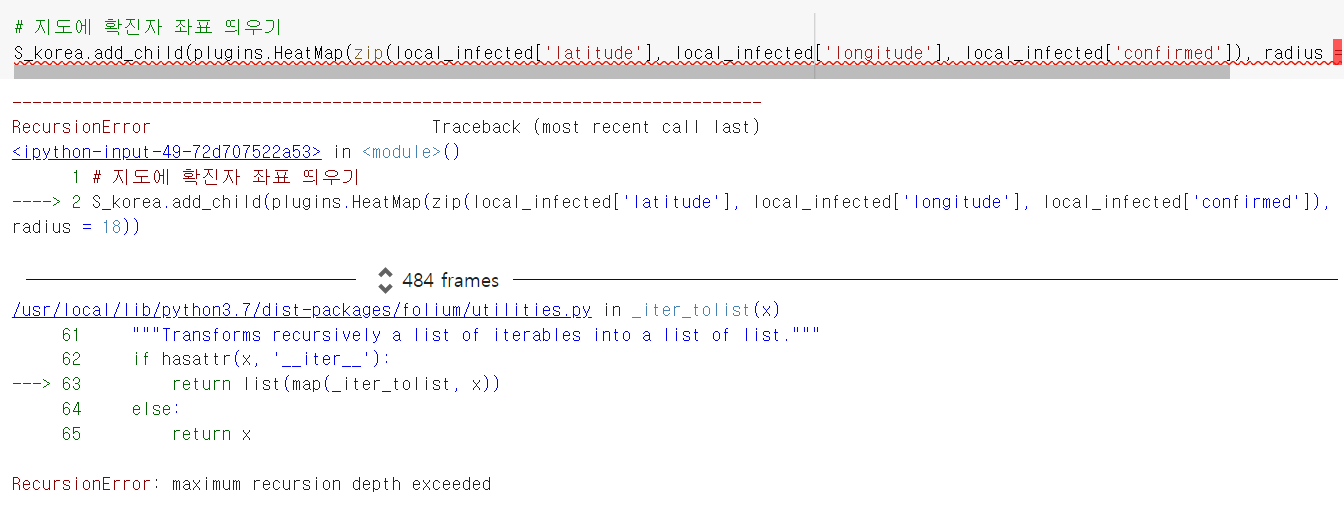
에러가 떴다. 이유가 뭐지?
데이터타입을 명확하게 확인할 것
local_infected.info()

위도, 경도 데이터엔 숫자가 들어가야 하지만 object(문자열)로 지정되어있다. 변경해야함
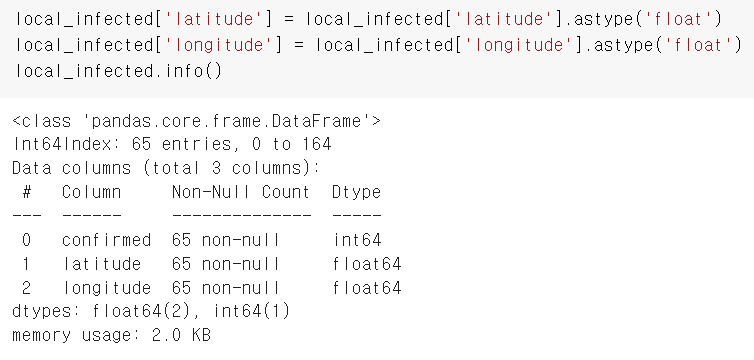
pandas 컬럼의 자료형 변경방법
변수['컬럼'] = 변수['컬럼'].astype('바꿀자료형')
local_infected['latitude'] = local_infected['latitude'].astype('float')
local_infected['longitude'] = local_infected['longitude'].astype('float')
지도에 확진자 좌표 띄우기
S_korea.add_child(plugins.HeatMap(zip(local_infected['latitude'], local_infected['longitude'], local_infected['confirmed']), radius = 18))
folium
참고자료: Mark lee 님의 블로그

이런 식으로 html파일로 저장이 가능하다

마커 표시도 가능하다. 나중에 해봐야지...
============================
3-14. 3주차 끝 & 숙제 설명
붓꽃데이터로 여러가지 차트, 맵, 분석을 해볼 것
히트맵, 바그래프, 파이차트
#기본코드
# 과제에 필요한 패키지는 아래의 두 가지가 전부가 아닙니다.
# 여러분들의 필요에 따라서 패키지를 지속 추가하셔도 됩니다.
import pandas as pd
from sklearn import datasets
# 붓꽃 데이터 로드
iris_data = datasets.load_iris()============================
============================
