비지도학습(Unsupervised-Learning)이란 라벨링 되어 있지 않은 데이터로 학습하는 방법이다.
비지도 학습의 대표적인 종류에는 차원축소(Dimensionality Reduction)와 군집화(Clustering)가 있다.
1️⃣ 차원축소(Dimensionality Reduction)
👉🏻 차원의 저주
- feature(변수)의 종류가 학습 데이터 수 보다 더 많아지면서 성능이 저하되는 현상
- 변수가 많아질수록 차원이 깊어지는데, 고정된 학습데이터 수가 있을 때 차원이 깊어질 수록 빈 공간이 많아진다.
- 때문에 차원 축소를 통해 이를 해결해야한다.
👉🏻 차원 축소(Dimensionality Reduction)
성능 좋은 AI, 머신러닝을 위해서는 많은 학습 데이터를 필요로 하는데
데이터가 많아질 수록 계산성능과 저장 공간의 한계, 잡음 데이터(noise)가 존재할 가능성이 증가한다.
-> 데이터 전처리 단계에서 차원 축소를 통해 해결하고자한다!
👉🏻 차원 축소의 방법
- Feature Selection
- 종속변수와 가장 관련성이 높은 피처만을 선택하고, 나머지는 제외한다.
- 만약 독립변수들 사이에서 높은 상관관계를 보이는 변수가 있다면 이 또한 제외한다.
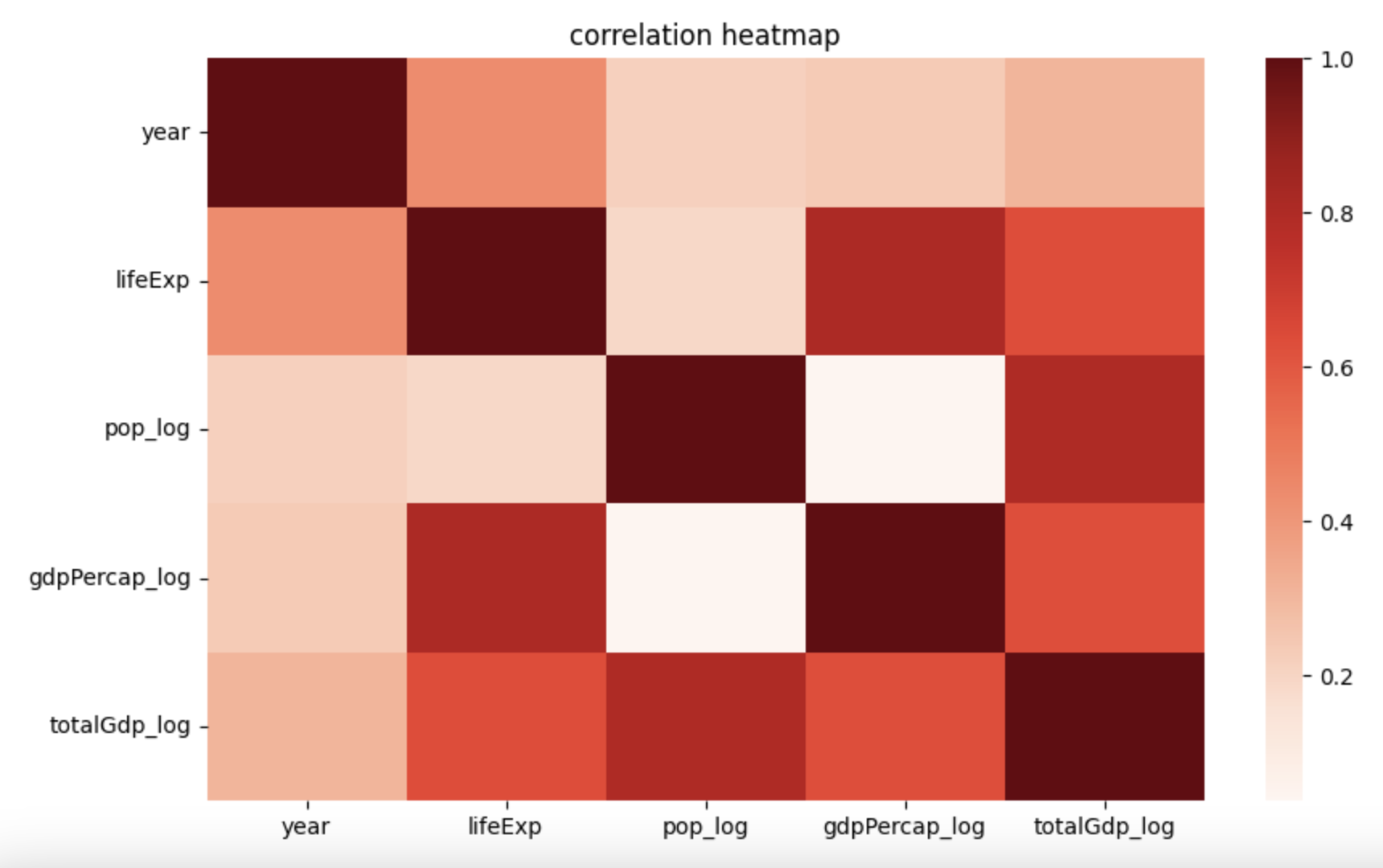
👉🏻 상관관계는 heatmap을 이용하여 파악할 수 있다.
예시) lifeExp와 gdpPercap_log는 높은 상관관계를 가지고 있음을 알 수 있다.
- Feature Extraction
- 일부 feature를 제거하는 Feature Selection과 달리 Feature Extraction는 고차원에서 저차원으로 공간을 투영시켜 데이터 모델을 단순화한다.
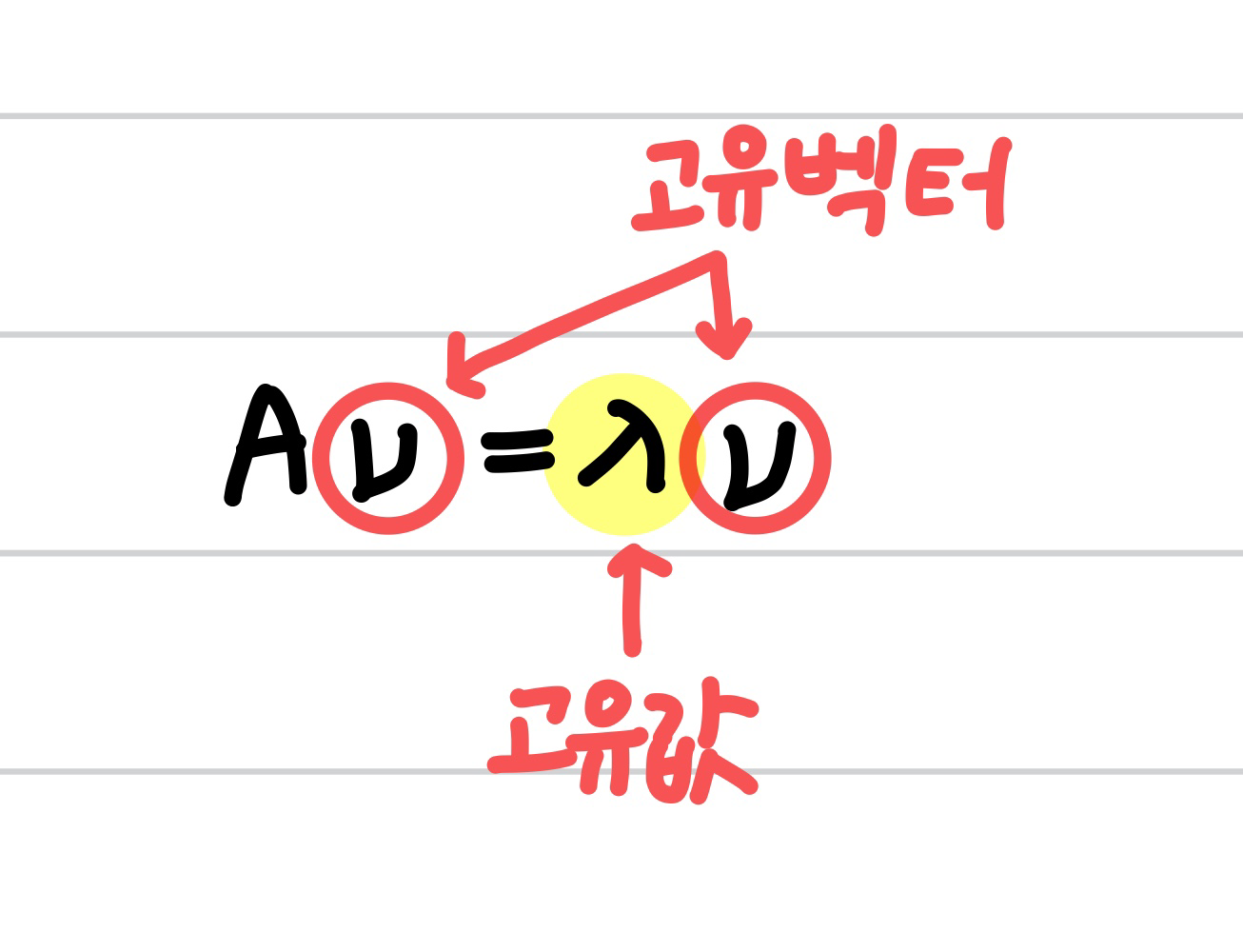
- 주성분분석(PCA : Principal Component Analysis)은 전체 데이터의 분포를 가장 잘 설명할 수 있는 주성분을 찾는 방법으로 데이터의 공분산 행렬의 고유값 분해를 통해 얻을 수 있다.
👉🏻 공분산 : 두 변수의 상관관계를 나타내는 척도이다.
👉🏻 교유값 분해(eigen decomposition)
- 분산이 가장 큰 주성분을 기준(교유값이 제일 큰 것)으로 데이터를 변형시킨다.
2️⃣ 군집화(Clustering)
데이터 샘플들을 별개의 군집으로 묶는 것으로 classification에 해당된다.- 모수적 추정
- 데이터가 특정 분포를 따른다고 가정 - 비모수적 추정
- 데이터가 특정 분포를 따르지 않는다고 가정
- K-means, Mean Shift, DBSCAN
👉🏻 군집화의 종류
-
K-means clustering
- K-means, K-means++
👉🏻 K-means : 중심점(평균)을 기반으로 K개의 군집으로 나눈다.
👉🏻 K-means++ : K-means를 개선 한 방식으로 초기 K개의 임의 점을 효율적으로 선택하여 cost를 줄인다. - K-medians, K-medoids
- K-means, K-means++
-
Density-based clustering
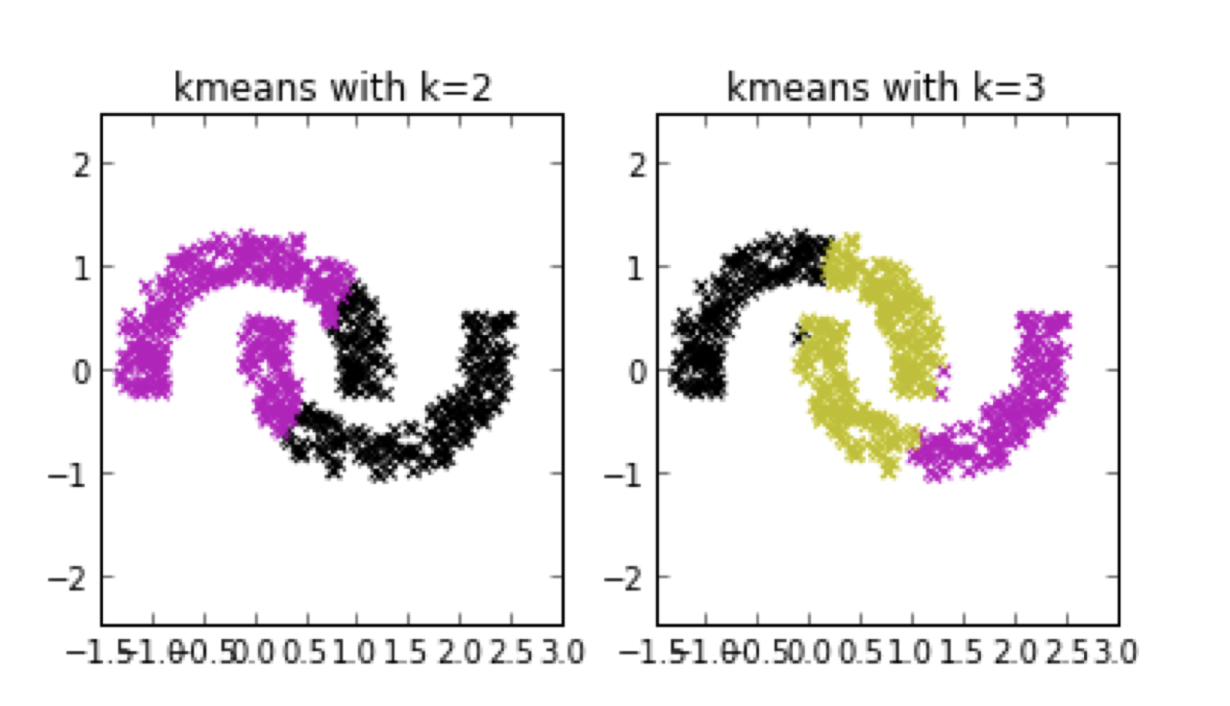
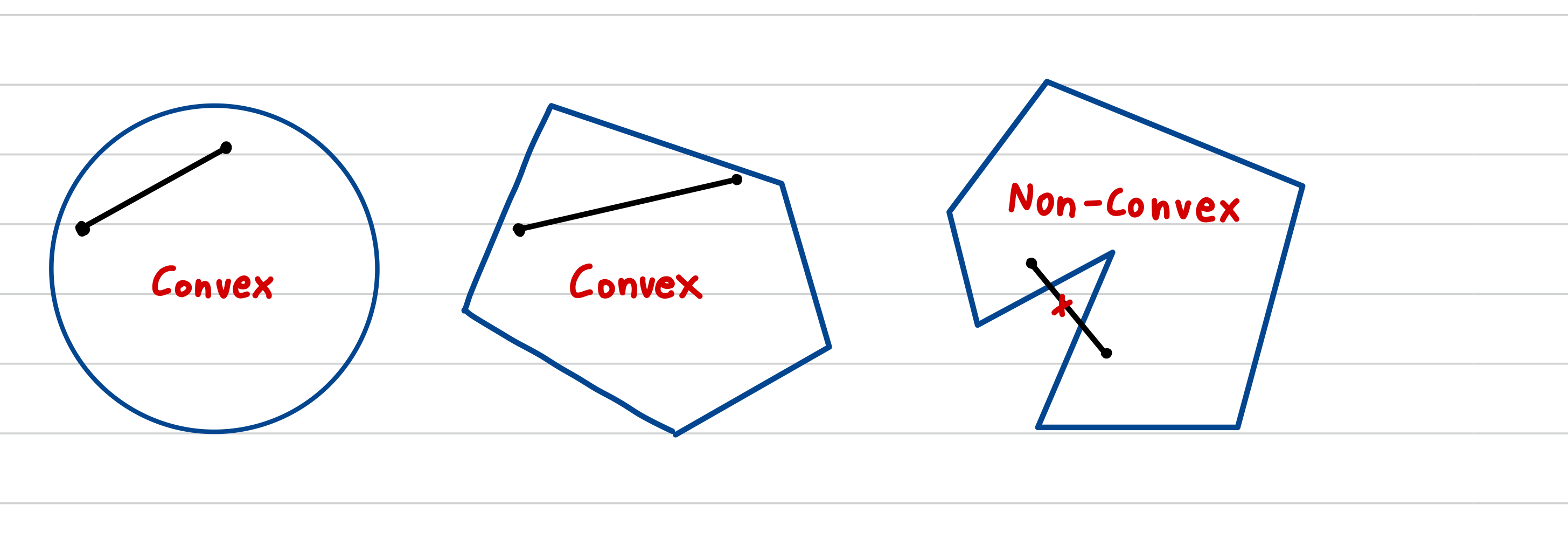
❓ 만약 데이터의 분포가 Non-Convex라면?
convex : 임의의 두 점을 이는 선 안에 있는 point가 set안에 존재
👉🏻 Non-Convex일 때 K-means clustering으로 잘 다루지 못한다.
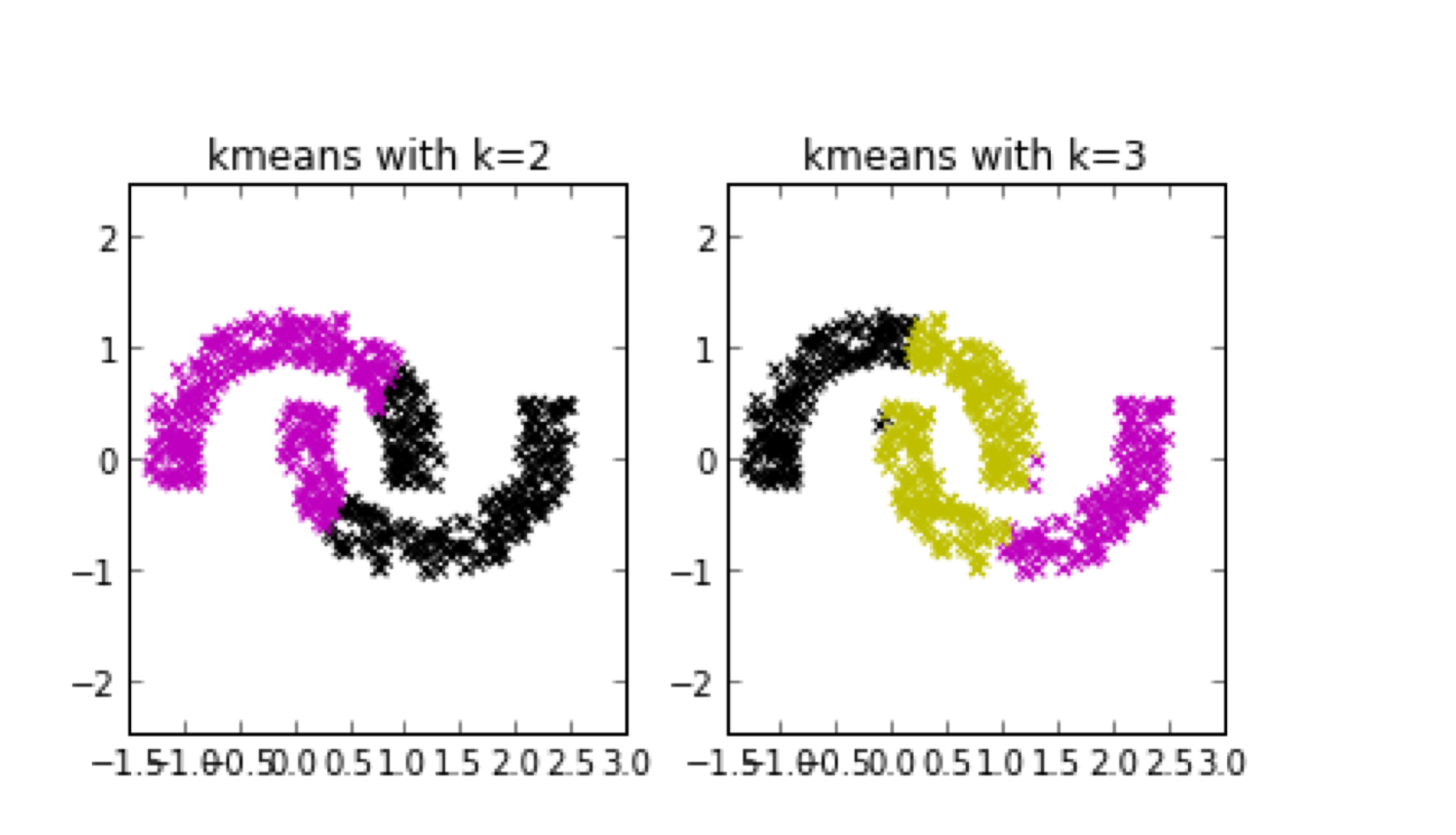
💡 DBSCAN을 사용하면 해결할 수 있다.
👉🏻 DBSCAN : 어느점을 기준으로 반경 x내에 점이 n개 이상 있으면 하나의 군집으로 인식하는 방식
- parameter : epsilon(반지름) & minNeighbors(원 안에 있는 neighbor의 최소 숫자)
- Hierarchical clustering
Divisive (top-down approach) 분할계층군집
전체 샘플을 포함하는 하나의 클러스터에서, 클러스터 안에 샘플이 하나만 남을 때 까지 클러스터를 작게 나누는 방법
Agglomerative (bottom-up approach) 병합계층군집
각 샘플이 하나의 독립적인 클러스터가 되고, 하나의 클러스터가 될 때까지 가장 가까운 클러스터를 합치는 방법
👉🏻 군집 간의 거리 계산을 통해 클러스터를 나누거나 합친다.- min distance(single link)
군집간 가장 가까운 원소끼리의 거리계산 - max distance(complete link)
군집간 가장 먼 원소끼리의 거리계산 - average distance(average link)
군집간 원소끼리 거리의 평균계산 - centroid distance
군집의 중심간의 거리계산
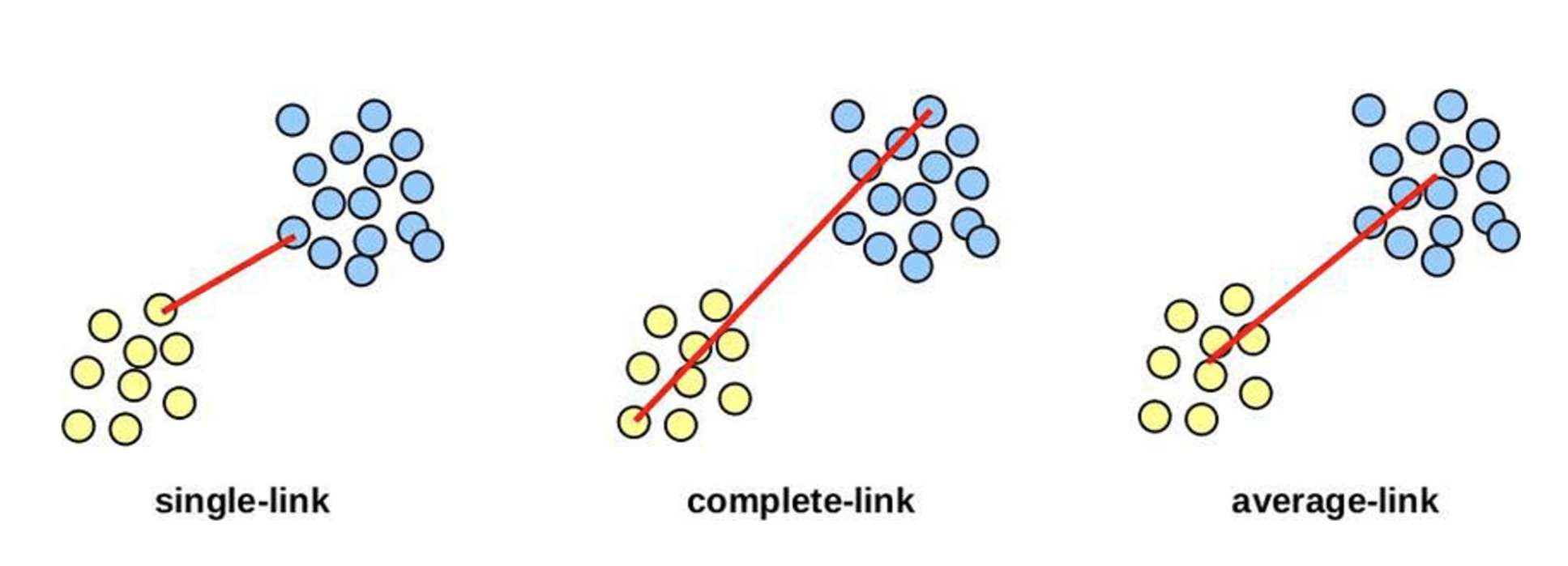
- min distance(single link)
출처
OUTTA 부트캠프

내일의 나는 오늘보다 더 나아지기를 :D
잘 봤습니다. 좋은 글 감사합니다.