
Pandas
- Python Data Analysis Library
- 대표적인 Python 기반 정형 데이터 분석 라이브러리
<특징>
- 테이블 형태의 데이터를 분석/처리할 수 있는 다양한 함수 제공
- Excel로 할 수 있는 모든 연산/기능 수행 가능
- 데이터 통계, 크롤링, 시각화 등 가능
- Python 자료구조와 호환
- 외부 데이터를 불러올 수 있음
Series : 1차원 데이터
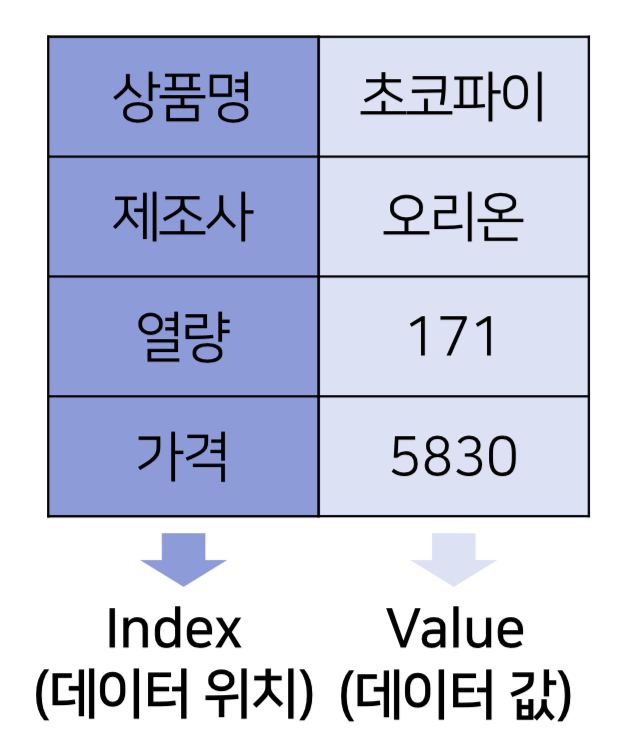
1) index 없이
pd.Series(['초코파이','오리온',171,5830])
# 0 초코파이
# 1 오리온
# 2 171
# 3 5830
# dtype: object2-1) index 생성
pd.Series(['초코파이','오리온',171,5830],
index =['상품명','제조사','열량','가격'])
# 상품명 초코파이
# 제조사 오리온
# 열량 171
# 가격 5830
# dtype: object 2-2) tuple 사용
food_info = ('초코파이','오리온',171,5830)
index_name = ('상품명','제조사','열량','가격')
series = pd.Series(food_info,index=index_name)2-3) dictionary 사용
series = pd.Series({'상품명':'초코파이','제조사':'오리온','열량':171,'가격':5830})Series 속성 확인
- obj.isnull() : 결측치 확인
- obj.notnull() : 결측치 확인
- obj.index
- obj.values
Series 데이터 선택
- obj['제조사']
- obj.loc['제조사'] : index 이름
- obj.iloc[1] : index 위치
Series 연산
- obj1.add(obj2,fill_value= )
- obj1.sum(obj2,fill_value= )
- obj1.mul(obj2,fill_value= )
- obj1.div(obj2,fill_value= )
DataFrame : 2차원 데이터

1) index 없이
data = [['초코파이','몽쉘','오예스'],['오리온','롯데','해태'],
[171,170,150],[5830,5290,4790]]
df = pd.DataFrame(data)
# 0. 1. 2
# 0 초코파이 몽쉘 오예스
# 1 오리온 롯데 해태
# 2 171 170 150
# 3 5830 5290 47902-1) index 생성
data = [['초코파이','몽쉘','오예스'],['오리온','롯데','해태'],
[171,170,150],[5830,5290,4790]]
df = pd.DataFrame(data,
index = ['상품명','제조사','열량','가격'],
columns = ['상품1','상품2','상품3'])
# 상품1 상품2 상품3
# 상품명 초코파이 몽쉘 오예스
# 제조사 오리온 롯데 해태
# 열량 171 170 150
# 가격 5830 5290 47902-2) dictionary 사용
data = {'상품1':['초코파이','오리온',171,5830],
'상품2':['몽쉘','롯데',170,5290],
'상품3':['오예스','해태',150,4790]}
df = pd.DataFrame(data,index=['상품명','제조사','열량','가격'])2-3) dictionary + series 사용
product_1 = pd.Series({'상품명':'초코파이','제조사':'오리온','열량':171,'가격':5830})
product_2 = pd.Series({'상품명':'몽쉘','제조사':'롯데','열량':170,'가격':5290})
product_3 = pd.Series({'상품명':'오예스','제조사':'해태','열량':150,'가격':4790})
df = pd.DataFrame({'상품1':product_1,'상품2':product_2,'상품3':product_3})DataFrame 데이터 선택
- df.index
- df.columns
- df.shape
DataFrame 속성 확인
- df.discribe() : 열 별 기술통계량 출력(ex) 평균, 표준편차, 삼분위수 등...)
- df.info()
DataFrame 데이터 선택
- df.loc['부산'] : 행 선택
- df.iloc[1] : 행 선택
- df['최고기온'] : 열 선택
- df[df.columns[1]] :열 선택
- df.loc['울산'][0]
- df.loc['울산','최고기온']
- df.iloc[1][0]
- df.iloc[1,0]
- df['최고기온'][1]
DataFrame 데이터 수정(추가/삭제)
- df['새로운 열 이름'] = 데이터 값
- df.drop(행 이름, axis = 0)
- df.drop(열 이름, axis = 1)
DataFrame 데이터 수정(정렬)
ascending = True/False
- df.sort_index()
- df.sort_values('최고기온')
DataFrame 데이터 연산
.apply() : 괄호 안 함수를 모든 데이터에 적용
f = lambda x : x.max() - x.min()
df.apply(f,axis=0) 열 방향
df.apply(f,axis=1) 행 방향
내일의 나는 오늘보다 더 나아지기를 :D