추천시스템이란 다양한 아이템 중 사용자가 선호할 아이쳄을 제공하는 시스템으로 사용자의 만족도가 증가함으로써 저절로 서비스 제공자의 수익상승에 기여할 수 있다.
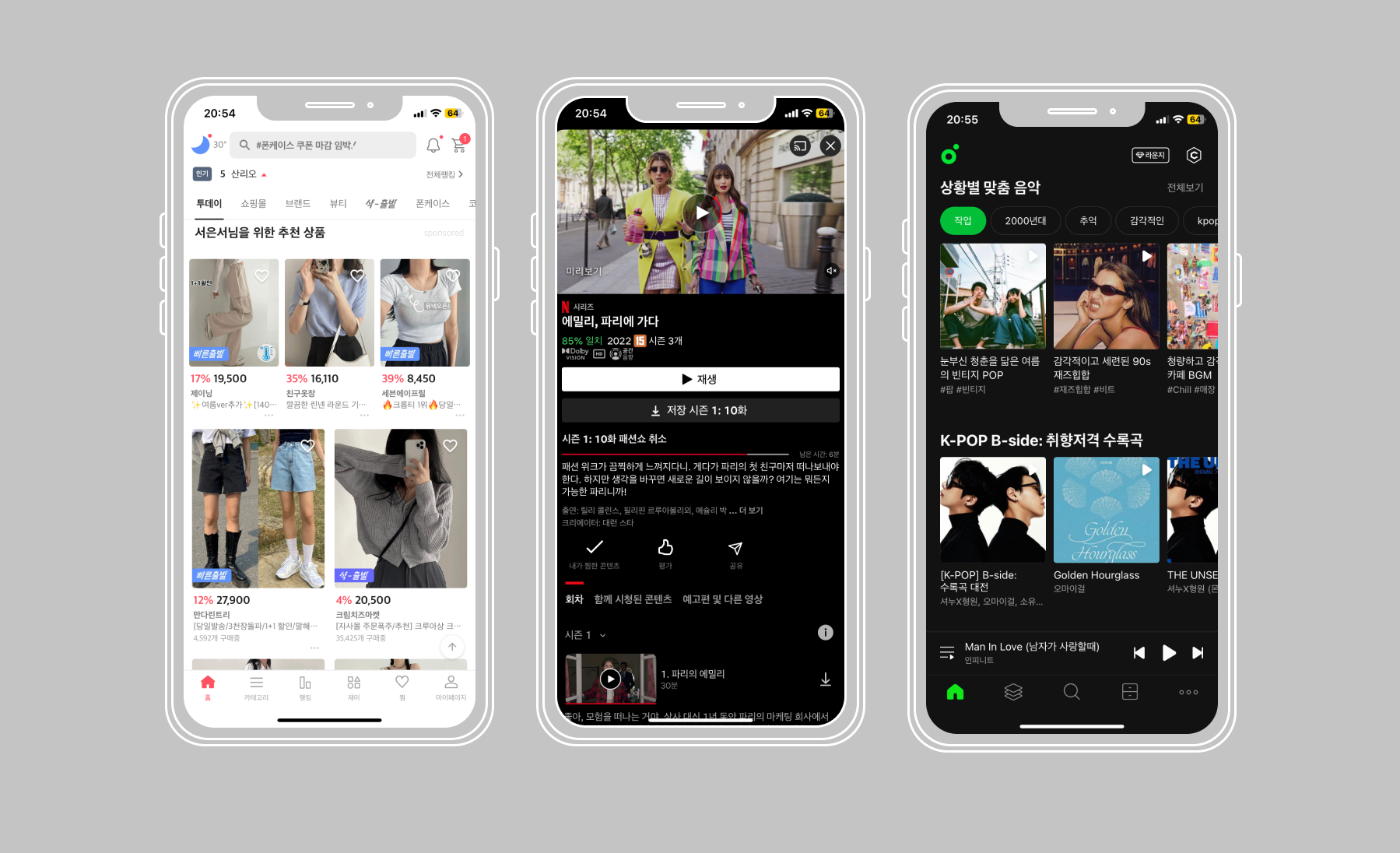
어떤 사용자에게 어떤 아이템을 추천할 것? 과 어떤 데이터를 활용할 것인지를 고려해야한다!
- 사용자의 취향, 흥미, 의도, 상황에 맞는 아이템 -> 유저의 특징을 고려
- 데이터 종류
- 유저 데이터 : 나이, 성별, 직업
- 행동 데이터 : 클릭, 구매, 평가
- 아이템 데이터 : 가격, 색상, 이름
💻 추천시스템
1️⃣ 추천 목적
■ Best Recommendation
Best를 어떻게 정하지?에 대한 고민 필요!- 신규 이용자들에게도 추천해줄 수 있음

■ Related Recommendation
연관된 다른 아이템을 추천해줌- 아이템간의 유사도를 측정함
- 대체재 : 대신 사용가능 한 아이템 - 보완재 : 같이 소비했을 때 효율이 더 올라가는 아이템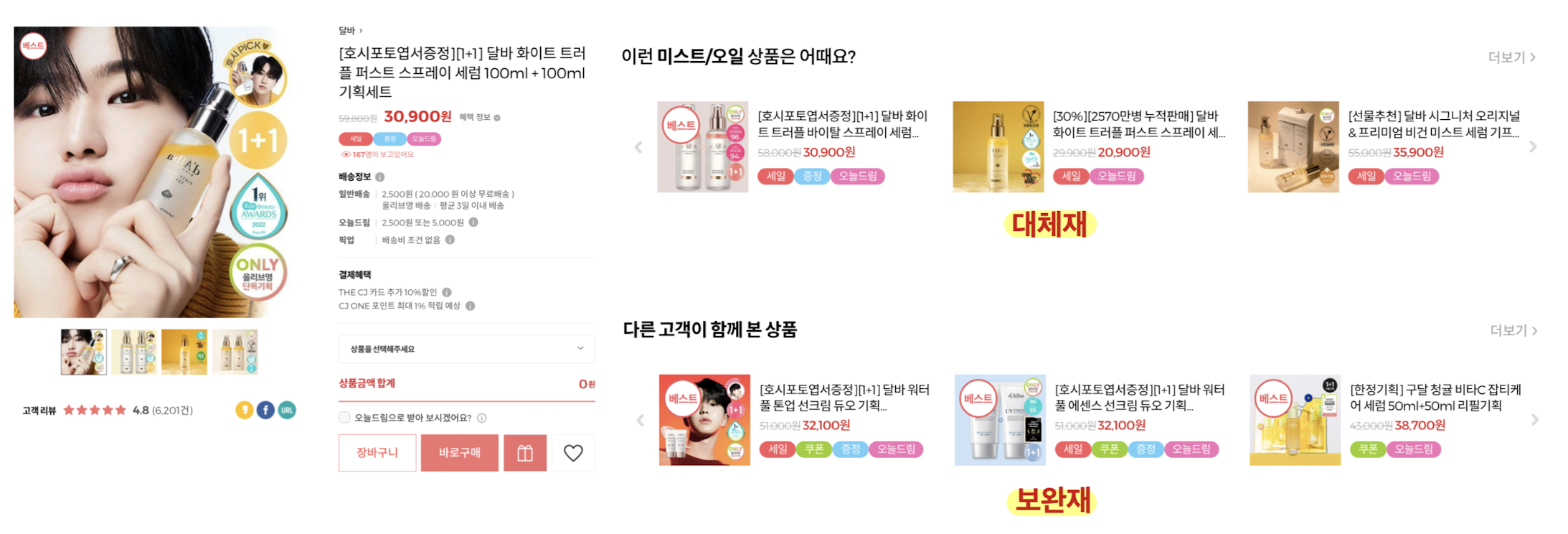
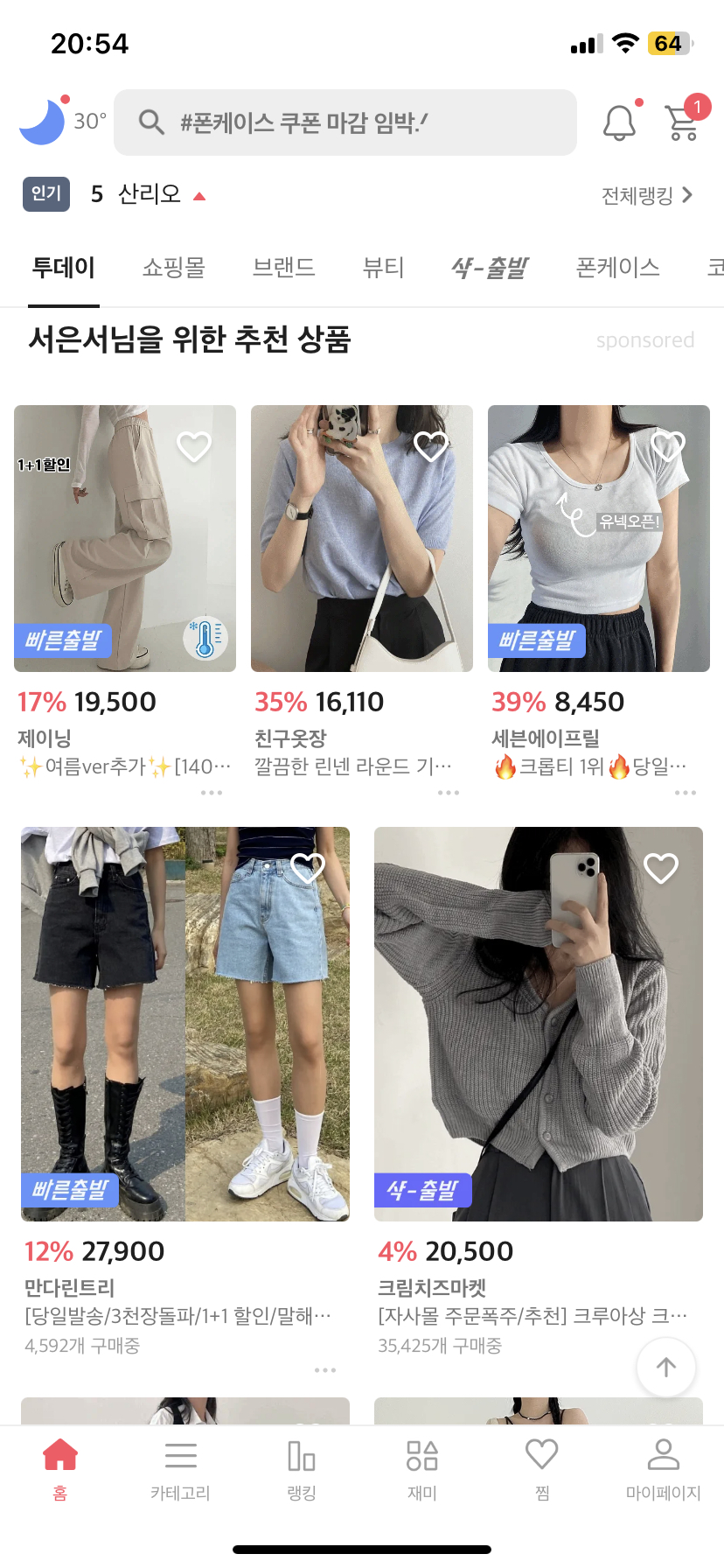
■ Personalized Recommendation
- 유저 정보에 기반, 사용이력이 많을수록 정확도가 올라감
▶︎ 에이블리(ABLY)
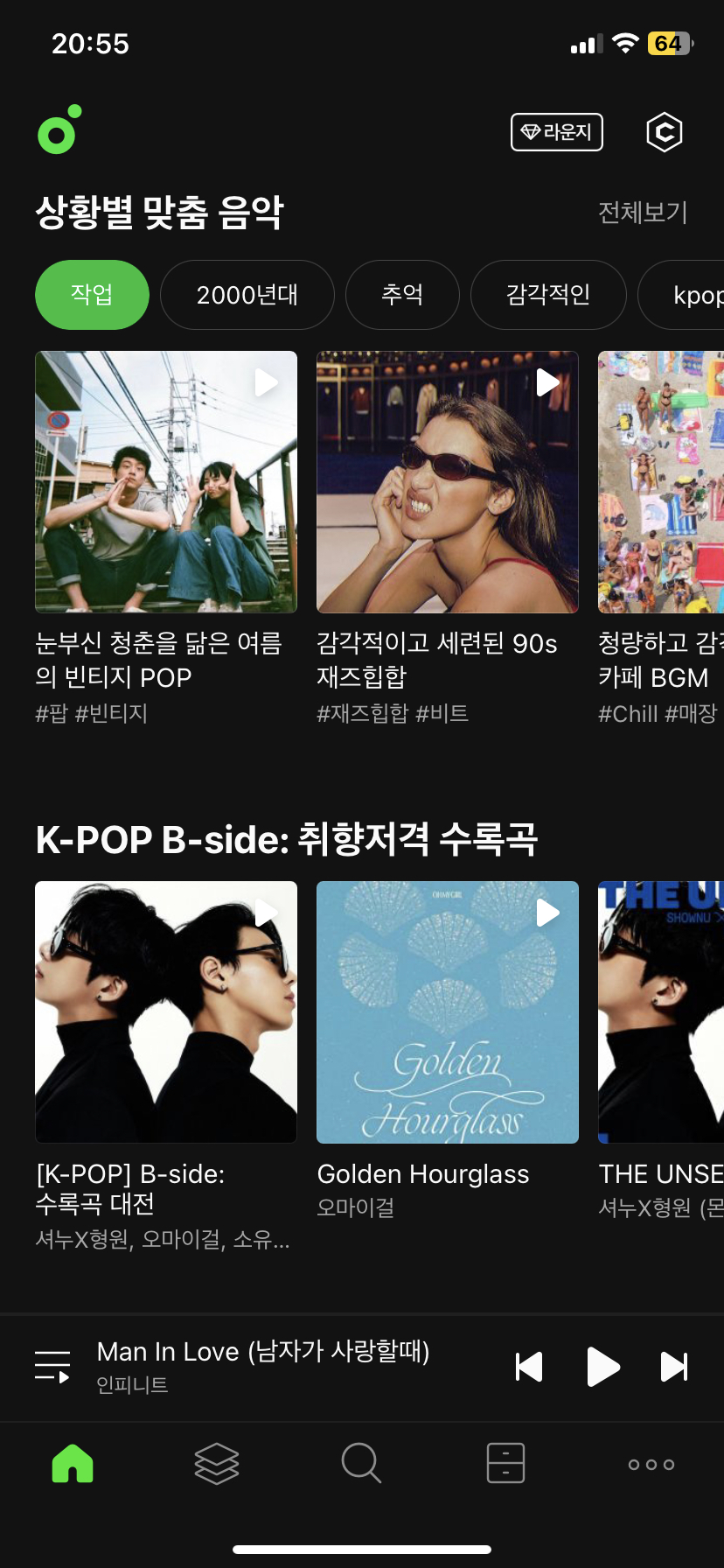
■ Context-aware Recommendation
- 맥락적 정보도 함께 고려(시간, 장소 등..)
▶︎ 멜론뮤직(Melon)
2️⃣ 추천 알고리즘
추천 알고리즘에는 크게 콘텐츠 기반 필터링(Content-based Filtering)과 협업 필터링(Collaborative Filtering)으로 나눌 수 있다.
■ Content-based Filtering(CBF)
사용자가 선호하는 아이템의 특성을 파악해 유사한 아이템을 추천하는 방식
ex)
- 유저 : '인터스텔라'를 좋아함 -> 우주🪐관련 영화를 추천
❗️ 그러나 우주영화라고 다 좋아하는 것은 아님 TF-IDF를 이용할 수 있음
■ Collaborative Filtering(CF)
아이템과 사용자의 관계를 이용하여 사용자의 흥미에 맞는 아이템을 추천하는 방식
- User-based
- ex) 유저와 비슷한 평점을 부여한 유저의 평점을 이용하여 추천함
- ❗️ 유저마다 평점을 부여한 기준이 다를 수 있음
- Item-based
- ex) 유사한 영화에 부여한 평점을 기준으로 평점을 부여함
- 💡 많은 기업들에서
Item-based를 더 선호함- 아이템에 대한 정보가 유저의 정보보다 구하기 쉽기 때문
- 아이템의 업데이트 주기가 유저의 업데이트 주기보다 더 길기 때문에 효율적이다.
- 아이템의 수가 유저의 수보다 적기 때문에 아이템간의 관계를 파악하는 것이 더 쉽다.
- ❗️ 데이터가 충분하지 않다면 적절한 추천을 하기 어렵다.
- ❗️ 평가가 적은 데이터는 추천에서 배제될 수가 있다.
■ Hybrid Collaborative Filtering
- Content-based와 Collaborative Filtering의 단점을 보완함
- 아이템의 속성, 사용자 행동 이력 데이터를 모두 사용한 추천시스템
3️⃣ Model
■ Rating Prediction
점수를 예측하고 가장 높은 점수를 기반으로 추천
■ Top-k Recommendation
점수를 이용해 순위를 매기고 이를 이용하여 추천
🔍 유사도
1️⃣ 자카드 유사도
2️⃣ 코사인 유사도

3️⃣ 유클리디안 유사도
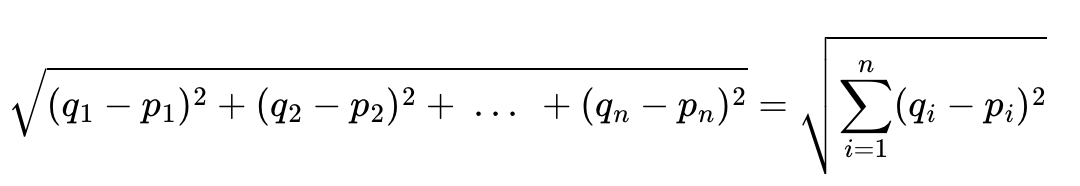

🧺 Bag of Word Embedding
- 단어의 순서를 고려하지 않고 빈도수로 텍스트를 임베딩하는 방법
- 많이 쓰인 단어가 주제와 관련이 있다고 생각!
▶︎ BoW 예시

- ❗️영어 text일 경우 'a'와 같은 단어 때문에 예측하기 어렵다는 문제가 있음
📝 TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF (Term Frequency-Inverse Document Frequency)
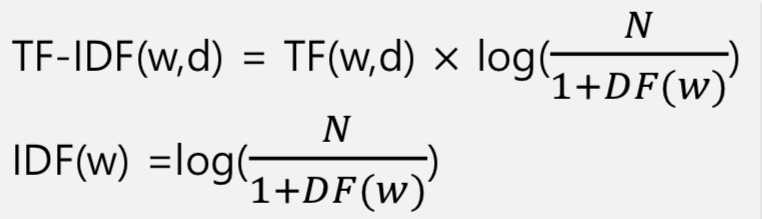
- Bag of Word의 문제점을 보완
TF(w): 특정 단어 w가 특정 문서 d에 나온 빈도DF(w): 특정 단어 w가 나타난 문서의 수
👉🏻 여러문장에 쓰이는 번용적인 단어IDF(w): 전체 문서 수 N을 해당 단어의 DF로 나눈 뒤 로그를 취한 값
👉🏻 모든 문서에 등장하는 단어(DF)의 중요도를 낮춤
(1을 더하는 이유는 분모가 0이 되는 것을 방지하기 위함)N: 전체 문서 수
🎥 예시) 영화 추천하기
📈 CBF(Content-based Filtering)를 이용한 영화 평점 예측

▶︎ 사용자 u가 영화 i에 남길 예상 평점
- 이때
sim(i,j)는 영화 i와 j의 유사도를 뜻함(영화 장르의 TF-IDF를 계산해서 나온 벡터를 이용하여 구함)
📈 CF(Collaborative Filtering)를 이용한 영화 평점 예측
Item-based
▶︎ 사용자 u가 영화 i에 남길 예상 평점
- 이때
sim(i,j)는 영화 i와 j의 유사도를 뜻함(영화 장르의 TF-IDF를 계산하지 않고 영화에 남겨진 평점으로 구함)
User-based
👉🏻 사용자 간의 유사도를 가중치처럼 적용하여 예상 평점을 구함!
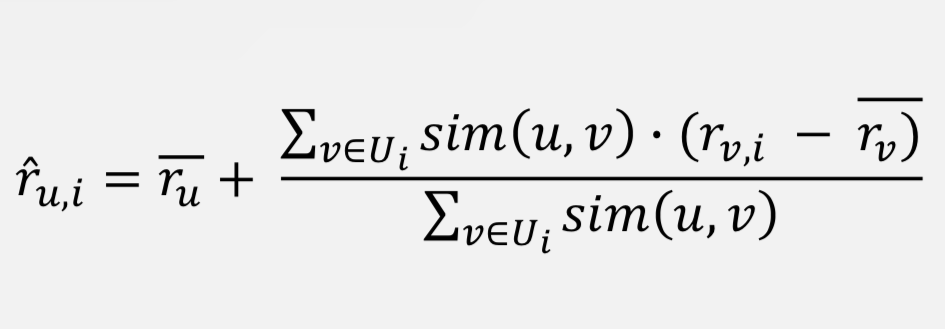
▶︎ 사용자 u가 영화 i에 남길 예상 평점
- 이때
sim(i,j)는 사용자 i와 j의 유사도를 뜻함
출처
- OUTTA

내일의 나는 오늘보다 더 나아지기를 :D