Abstract
최근 Transformer 및 CNN 기반 모델이 ASR(Automatic Speech Recognition)에서 RNN을 능가하는 유망한 결과를 보여줬다.
-
Transformer : 콘텐츠 기반의 global interactions을 잘 포착
-
CNN : 지역적인 특징을 효과적으로 활용
본 연구에서는 Transformer와 CNN의 장점을 모두 달성한 Conformer를 제안하고 있다.
Introduction
ASR 시스템은 최근 몇 년 동안 크게 개선되었다.
-
RNN : 오디오 sequence의 시간적 종속성을 효과적으로 모델링 할 수 있다.
-
Transformer : self-attention에 기반하여 장거리 interactions을 포착하는 능력과 높은 훈련 효율을 가지고 있다.
-
CNN : local 정보를 활용하고 vision에서는 계산 블록으로 사용된다. 번역 등가성을 유지하고, 가장자리 및 모양과 같은 feature를 캠쳐할 수 있는 local indow를 통해 공유된 위치 기반의 kernel을 학습한다.
그러나 위의 모델들은 한계가 있다.
-
Transformer : 세분화된 local feature patterns을 추출하는 능력이 떨어진다.
-
CNN : global 정보를 캡쳐하기 위해서는 더 많은 layer 혹은 매개변수가 필요하다.
이러한 한계점을 보완하기 위해 본 논문에서는 convolution과 self-attention을 결합하였다. 이는 local feature를 학습하고 global interactions을 사용할 수 있다.
본 논문에서는 ASR 모델에서 convolution을 self-attention과 결합하는 방법을 연구한다. global과 local 상호작용이 매개 변수 효율화를 위해 중요하다는 점에 초점을 두어 global의 상호작용을 학습하는 *self-attention과 상대적 offset기반 local 상관관계를 효율적으로 포착하는 convolution의 새로운 조합*을 제안했다.
본 논문에서 제안된 Conformer 모델은 LibriSpeech에서 SOTA 결과를 달성하며 Transformer Transducer의 성능을 능가한다.
Conformer Encoder

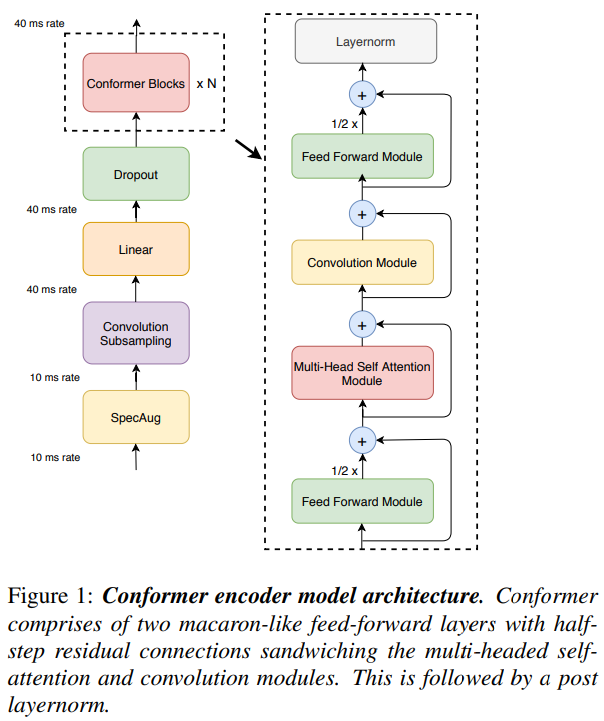
Conformer 모델에서의 오디오 인코더는 convolution subsampling layer로 input을 처리한 후 다수의 conformer block으로 입력을 처리한다.
- convolution subsampling layer? Subsampling layer가 하는 기능적인 역할은 입력 데이터의 크기를 줄이는 것이다. 이는 위치 이동, 회전 및 부분적인 변화와 왜곡에 강인한 인식 능력을 키우는데 있어 중요한 역할을 한다. Subsampling layer를 통해 입력 데이터의 크기를 줄이면 비교적 강한 특징만 남고, 자잘한 변화들은 사라지는 효과를 얻을 수 있다.
주목할 점은 transformer block 대신 conformer block을 사용한다는 점이다.
⬜️ conformer block : 네 개의 모듈로 구성된다.
- 첫번째 feed-forward 모듈
- self-attention 모듈
- convolution 모듈
- 두번째 feed-forward 모듈
Multi-Headed Self-Attention Module

Transformer-XL(extra long)의 테크닉을 참고하여 relative positional encoding을 사용했다.
- Transformer_XL transformer에서의 고정된 길이의 문맥의 한계점을 극복하기 위하여 제안되었다. 이 모델은 각 새로운 segment의 hidden state를 처음부터 계산하는 것이 아닌, 이전 segment에서 학습된 hidden state를 재사용하여 segment간의 recurrent connection을 형성했다. 이 recurrent connection을 따라서 정보가 전달되어 long-term dependency를 학습할 수 있게 되며, 이전 segment로부터온 정보를 전달함으로써 context fragmentation 문제도 해결할 수 있게 되었다. 또한 relative positional encoding을 사용하여, 시점의 혼란(temporal confusion)이 없이 state를 재사용할 수 있게 하였다.
⬜️ relative positional encoding
transformer 아키텍쳐는 input sequence 사이의 attention을 통해 input 사이의 관계를 모델링하는데 sequence의 순서를 모델링하는데에는 한계가 있다. 이를 위해 제안된것이 positional encoding이다.
ex) "철수 / 가 / 영희 / 를 / 좋아해"라는 시퀀스와 "영희 / 가 / 철수 / 를 / 좋아해"라는 시퀀스에서 "철수"에 해당하는 attention layer의 아웃풋은 두 문장에서 완벽하게 동일하다.
- positional encoding
- sinusoidal 함수를 사용한 인코딩
- 인코더나 디코더의 첫 번째 레이어 이전의 input에 sinusoidal 함수를 사용한 frequency를 더해준다.
- 학습된 absolute representation
- 위치 정보 input에 대해 projection layer를 학습하여 사용한다.
sinusoidal 함수를 사용한 인코딩기반의 relative positional encoding은 self-attention 모듈이 다른 입력 길이에 더 잘 일반화 할 수 있게 하였고, 인코딩 결과가 발화 길이의 분산에 더 robust하게 했다. 더 깊은 모델을 훈련하고 정규화하는데 도움이 되는 dropout과 함께 prenorm residual units을 사용한다.
- pre-norm(pre-layer normalization) transformer 모델에서 사용되는 레이어 정규화의 한 현태로 각 sub layer의 입력에 적용된다. 즉, 각 sub layer의 연산 전에 레이어 정규화가 수행된다. pre-norm은 학습 중 발생할 수 있는 수치적 불안정성을 줄이고, 더 깊은 네트워크의 효율적인 학습을 가능하게 한다.
Convolution Module
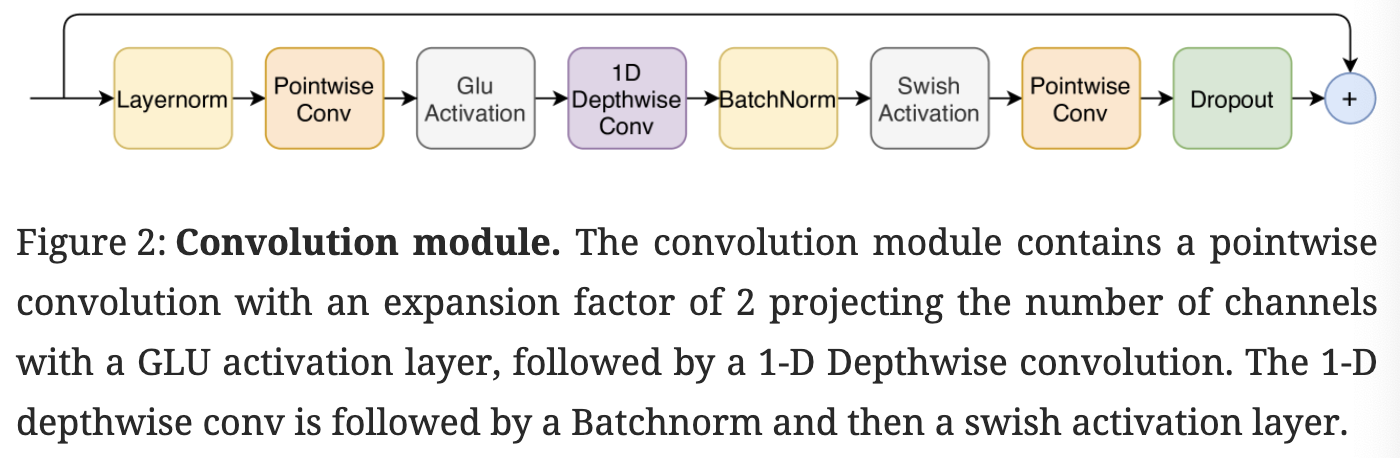
Convolution module은 pointwise convolution과 gated linear unit(GLU)인 gating machanism에서 시작한다. 다름으로 1D depthwise convolution layer가 이어지며 batchnorm은 deep module 훈련을 지원하기 위해 convolution 직후에 전개된다.
Feed Forward Module
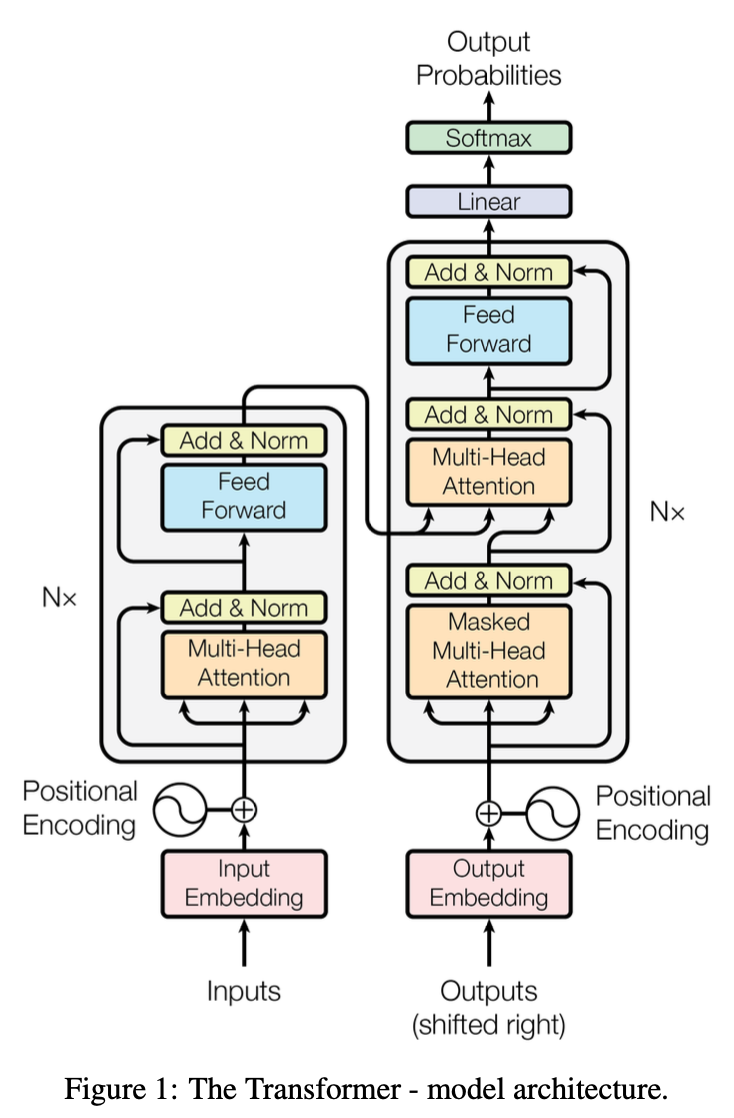
“Attention is all you need”에서의 transformer 구조이다.
“Attention is all you need” 논문에서는 Multi-Headed Self-Attention Module 이후에 feed forward module을 배치하여 두개의 linear transformations과 그 사이의 nonlinear activation으로 구성된다.
residual connection이 feed-forwrad layer위에 추가 된 후 레이어 정규화가 수행된다. 이는 transformer ASR 모델에도 채택되었다.
Conformer에서의 feed forward module은 pre-nrom residual units을 따른다.

Conformer Block

Conformer Block은 multi-headed Self-attention 모듈과 Convolution 모듈 그리고 두개의 feed-forward 모듈을 포함하고 있다.
Transformer의 feed-forward를 두 개의 half-step feed-forward로 나눠 attention 전과 후에 적용하는 Macaron-Net처럼, 논문에서도 feed-forward에서 half-step residual weight를 사용하였다.
실제로 half-step residual connection이 있는 두개의 Macaron-net style feed-forward layers가 conformer 구조에 단일 feed-forward 모듈을 갖는 것보다 크게 개선된다는 것을 발견했다.
feed-forwrad 모듈 이후 최종 layernorm layer가 적용되는데 수학적으로 conformer block 에 대한 입력 에 대한 블록의 출력 는 아래와 같은 수식으로 표현할 수 있다.
-
: Feed Forward module
-
: Multi-Head Self-Attention module
-
: Convolution module
본 연구를 통해 self-attention 모듈 뒤에 쌓인 convolution 모듈이 음성 인식에 대해 가장 잘 작동한다는 것을 알아냈다.
Experiments
Data
LibriSpeech 데이터셋을 사용하여 모델을 평가한다. 본 연구에서는 10ms의 보폭으로 25ms window에서 계산된 80채널 필터 뱅크를 추출했다. SpecAugment와 time mask의 maximum-size를 발화 길이의 의 곱으로 설정된 최대 time mask ratio를 가진 10개의 time mask를 사용한다.
Conformer Transducer
network의 깊이, model의 차원, attention head의 수의 다양한 조합으로 실험한 후 파라미터 제약에서 가장 효율적인 10M, 30M, 118M 세 모델을 선정했다. 모든 모델에서의 디코더는 single LSTM layer를 사용했다.
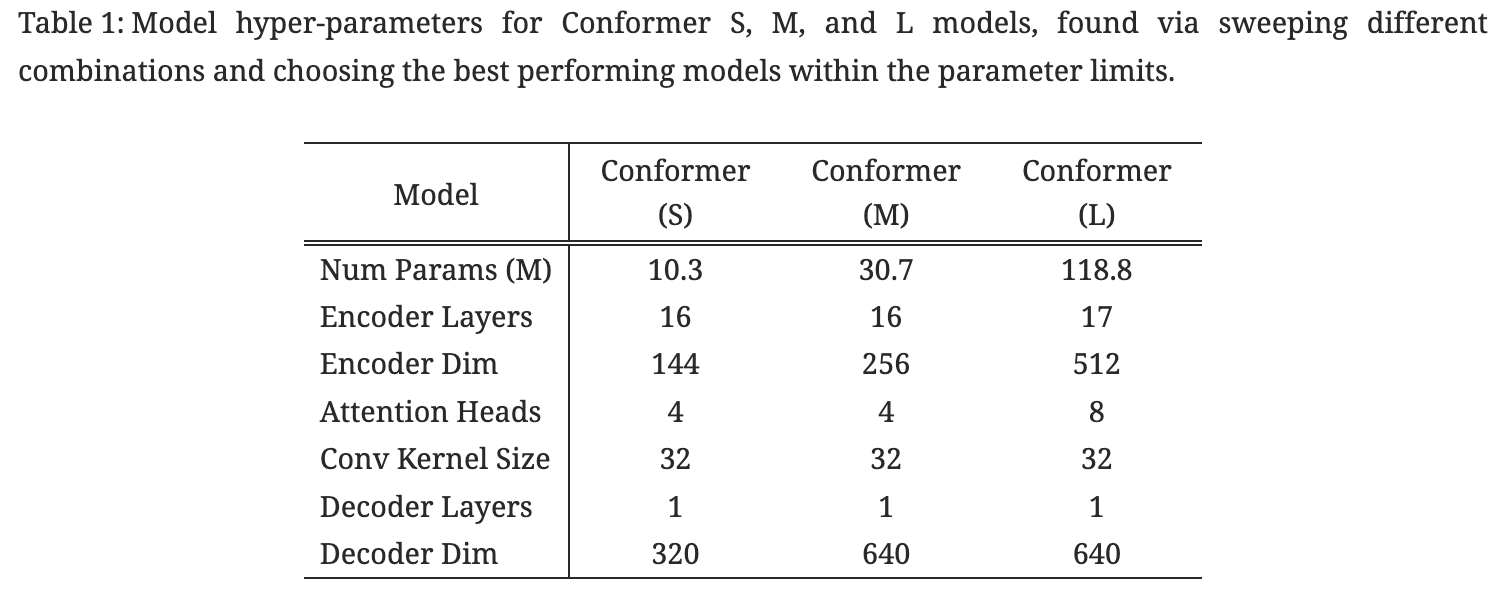
정규화를 위해 모듈 입력에 추가되기 전 conformer의 각 residual unit에 dropout을 적용한다. 뿐 만 아니라 variational noise가 정규화로 모델에 도입 되었고 l2 정규화는 네트워크의 모든 훈련 가능한 weight에 추가되었다.
-
Adam optimizer
-
peak learning rate : ( : 모델의 차원)
-
transformer learning rate schedule : 10k warm-up steps
LibriSpeech 언어 모델 corpus에서 훈련된 3-layer LSTM 언어 모델을 사용한다.
Results on LibriSpeech
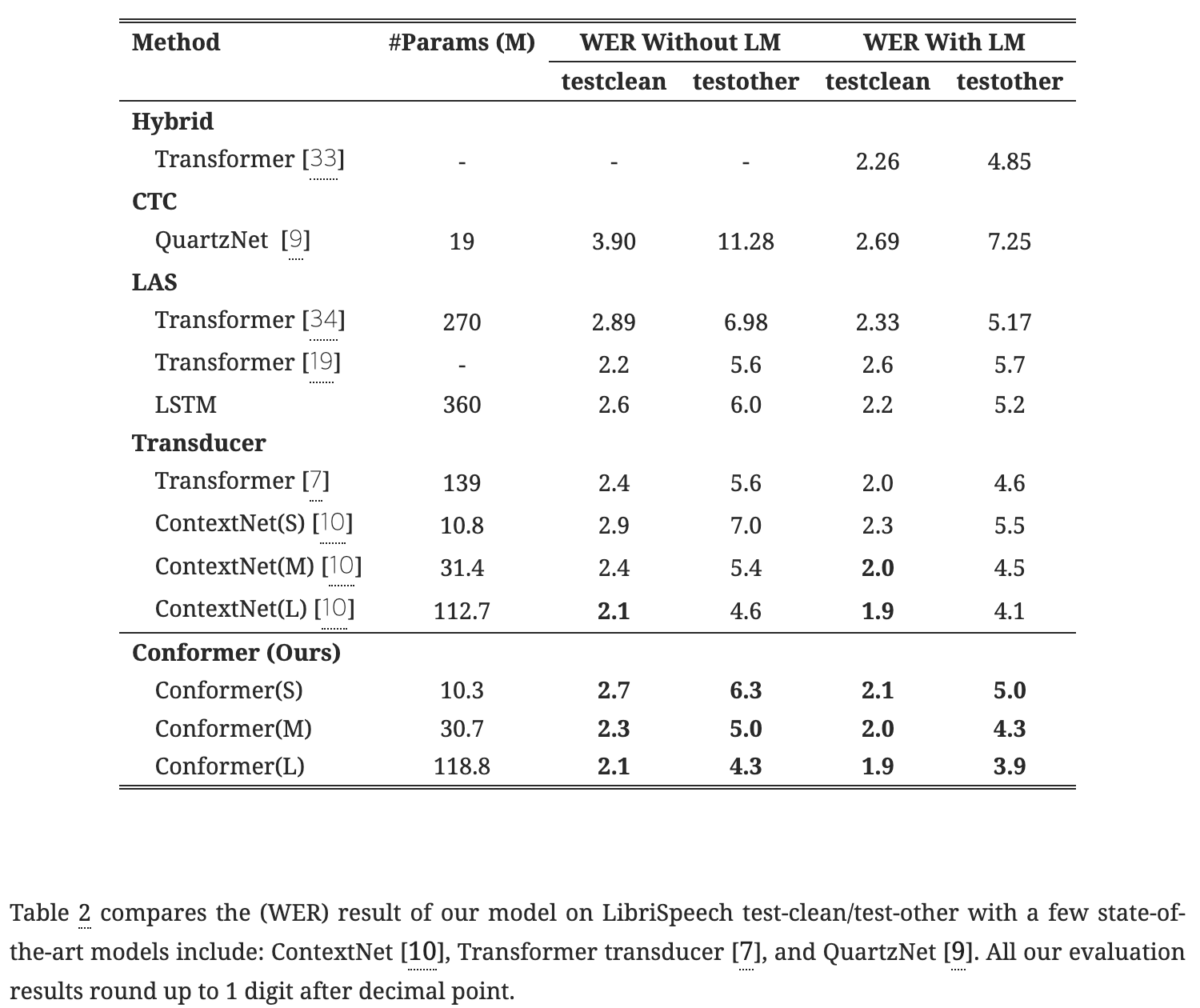
위의 표에서 확인할 수 있듯이 Conformer 모델은 다양한 모델 파라미터 크기 제약 조건에서 일관되게 개선된 성능을 보여주고 있다.
언어 모델을 사용하지 않고서도 본 모델의 성능은 Transformer, LSTM 기반 모델 또는 유사한 크기의 Convolution 모델을 능가한다.(2.3/5.0 on test/testorher) 언어 모델을 추가 되었을 때 Conformer 모델은 기존 모델 중 WER이 가장 낮음을 확인할 수 있다. 이는 단일 신경망에서 Transformer와 Convolution을 결합하는 효과가 명확함을 보인다.
