
0. Abstract
주요 sequence transduction 모델은 인코더와 디코더를 포함하고 있는 복잡한 RNN 또는 CNN을 기반으로 한다. 본 논문에서는 오직 attention mechanism에만 기반한 transfomer를 제안한다. 이는 병력적으로 시퀀스 데이터를 처리하기 때문에 더 빠른 처리가 가능하다. 또한 transformer 는 다른 task에 일반화 할 수 있음을 보인다.
1. Introduction
Recurrent model은 input과 output 시퀀스의 symbol position을 통해 계산을 수행한다. 이는 이전 hidden states 과 위치 의 함수인 hidden states 를 생성한다. 이렇게 진행 시 긴 sequence 길이를 가지는 데이터를 처리할 때, memory와 computation에서 제약이 생긴다.
Attention mechanisms은 input 또는 output 시퀀스의 distance에 관계없이 dependency를 모델링할 수 있지만 대부분의 경우 recurrent network와 함께 사용된시에 효율적인 병렬화가 불가능하다.
본 논문에서는 recurrence를 회피하면서 input과 output사이의 global dependencies을 모델링 할 수 있는 Attention mechanism만을 사용한 모델 Transformer을 제안한다.
2. Background
"Extended Neural GPU," "ByteNet," "ConvS2S"과 같은 모델은 sequential한 계산을 줄이기위해 CNN을 사용하며 input과 outputdml position에 대한 숨겨진 표현을 병렬로 계산한다. 그러나 이러한 모델에서 임의의 입력 또는 출력 위치 간의 관계를 학습하기가 어려워진다.
transformer는 이 문제를 상수 개의 연산으로 줄이지만, 평균화된 어텐션 가중치 위치로 인해 효과적인 해상도가 감소하는 부작용이 있다. 이 부작용을 "Multi-Head Attention"을 통해 극복하고자 한다.
- Self-attention(intra-attention)
시퀀스 내의 다른 위치 간의 관계를 계산해 시퀀스의 표현을 생성하는 Attention mechanisms이다. 메커니즘 독해, 추상적 요약, 텍스트 포함, 학습 과제, 독립적인 문장 표현을 포함한 다양한 task에서 성공적으로 사용된다. - End-to-end memory network
sequence-aligned recurrence보다 recurrent attention mechanism 기반을 둔다.
본 논문에서는 transformer가 sequence-aligned RNNs 혹은 컨볼루션을 사용하지 않고 입력 및 출력의 표현을 계산하기 위해 완전히 'self-attention'에 의존하는 모델임을 보인다.
3. Model Architecture
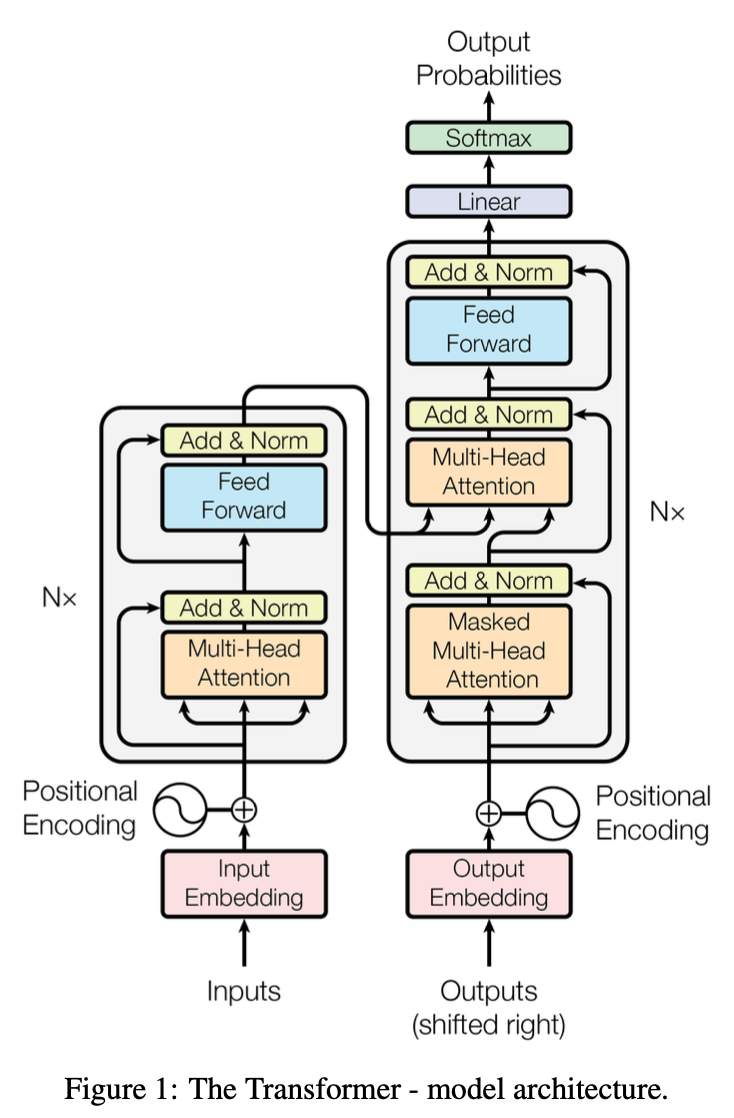
3.1 Encoder and Decoder Stacks
encoder와 decoder에서 stacked self-attention과 poinwise를 사용한 완전연결층을 구조로한다.
-
Encoder : 6개의 동일한 layer로 이루어져 있다.
▶︎ 각각의 layer는 두개의 sub-layer를 가지고 있다.
- 1. multi-head self-attention mechanism
- 2. positionwise fully connected feed-forward network -
Decoder : 6개의 동일한 layer로 이루어져 있다.
▶︎ 각각의 layer는 세개의 sub-layer를 가지고 있다.
- 1. multi-head self-attention mechanism
- 2. positionwise fully connected feed-forward network
- 3. encoder stack의 output에 대해 multi-head attention을 수행
3.2 Attention
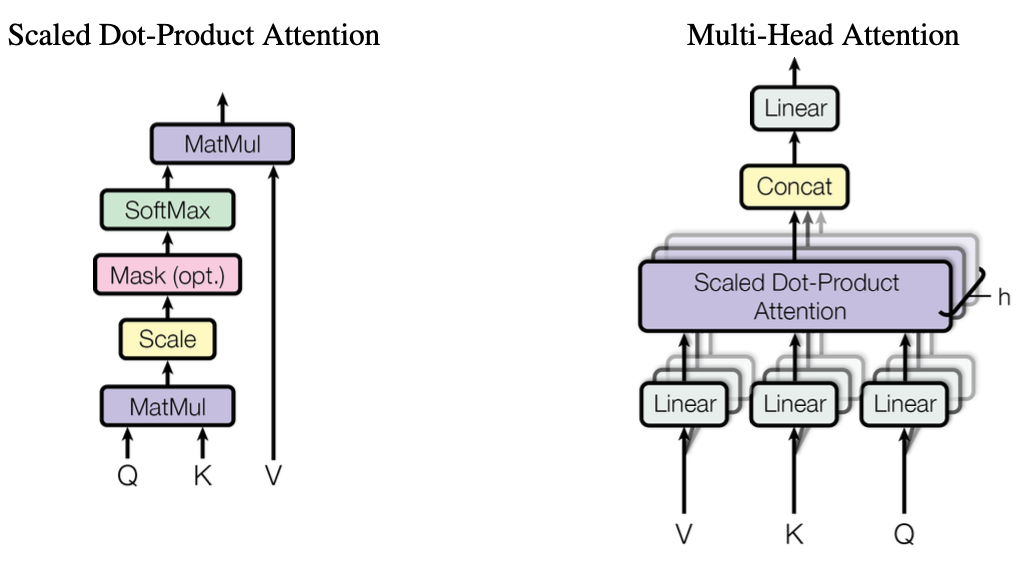
3.2.1 Scaled Dot-Product Attention
query, key, value?
Query(Q)는 물어보는 주체, Key(K)는 반대로 Query에 의해 물어봄을 당하는 주체, Value(V)는 데이터의 값들을 의미한다.
계산식은 다음과 같다.
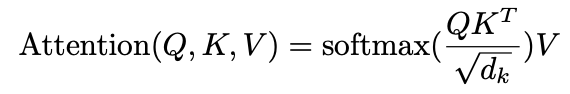
Query(Q) : 어떤 단어를 나타내는 vector
Key(K) : 문장의 모든 단어들에 대한 vector들을 쌓아놓은 행렬👉🏻 이 때 Q와 K의 차원은 , V의 차원은 이다.
- 를 통해 Q와 K의 내적을 해줌으로써 relation vector(Q와 K의 관련 정보가 들어있음)를 만든다.
👉🏻 마지막 softmax함수를 이용헤 Query 단어가 모든 단어들과 어느정도의 관련이 있는지 확률분포형태로 만든다. - 로 나누는 이유는 softmax가 0 근방에서 gradient가 높고 0에서 멀어질수록 gradient가 낮아지기 때문에 학습이 잘 되지 않는다. 떄문에 이를 0와 가까이 스케일링 함으로써 학습이 잘되도록 한다.
3.2.2 Multi-Head Attention
모델이 다양한 관점에서 문장을 해석할 수 있도록 하는 역할이다.

queries와 keys, values를 linear projection을 통해 중간에 매핑해 여러개의 attention function들을 만드는 것이 single attention function보다 효율적이다. 각각의 attention의 출력값은 전부 합쳐지고 linear function을 이용해 매핑된다.
computational cost측면에서 바라봤을 때 이기 때문에 single-head attention과 비교했을 때 비슷하다.
3.2.3 Applications of Attention in our Model
transformer에서는 multi-head attention을 다음의 방식으로 사용한다.
- encoder-decoder layer
query는 이전 decoder layer에서 나오며, key와 value는 인코더의 출력에서 나온다.
▶︎ 이를 통해 decoder의 각 위치가 입력 시퀀스의 모든 위치에 대해 attention을 수행할 수 있다. - encoder
encoder에는 self-attention layer가 포함되어있다. key,query,value는 동일한 곳에서 나오며 이 경우 이전 encoder layer의 출력에서 도출된다.
▶︎ 이를 통해 encoder의 각 위치가 이전 encoder 레어의 모든 위치에 대해 attention을 수행 할 수 있다. - decoder
decoder의 self-attention layer에서 각 위치는 해당 위치를 포함하여 decoder 내의 모든 위치에 attention을 수행 할 수 있다.
3.4 Embeddings and Softmax
input과 output은 tokenizing을 진행하며 embedding layer를 거쳐 나온 embedding vector를 사용한다. embedding vector는 문맥을 잘 나타내고 있으며 input embedding과 output embedding에서 가중치 matrix는 서로 공유한다.
3.5 Positional Encoding
transformer는 attention mechanism만을 사용하기 때문에 sequence한 정보를 담아낼 수 없다. 따라서 별도의 'positinal encoding'을 통해 sequence한 정보를 추가한다.
positinal encoding은 sine과 cosine function을 이용해 도출할 수 있다.
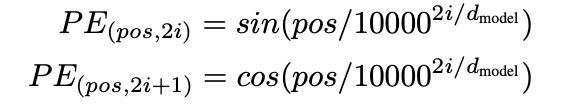
pos : position
i : dimension
⭐️ 고정된 offset k에 대해 가 $$PE_{pos}##의 선형함수로 표현될 수 있기에 모델이 쉽게 상대적인 위치를 참조할 수 있을 것이라 가정했기 때문에 위의 함수를 사용했다.
출처
