오늘 정리
관계지향형 데이터베이스(RDBMS)란? 데이터 간 관계에 초점을 두는 관계형 모델을 기반으로 많은 데이터를 다양한 처리를 할 수 있으며, 데이터 간의 관계를 강조한다.
복습
- 시작하기
- cmd로 시작하기 sqlplus id/pw@ip:1521:orcl11
- 프로젝트 서버로 로그인하여 사용
- cmd로 시작하기 sqlplus id/pw@ip:1521:orcl11
강의 내용
- sql 한글 깨짐 해결(https://dorothy-yang.tistory.com/128)
- 디비버 다운로드(https://dbeaver.io/download/)
- Toad 명령문 대문자 변경(https://surpassing.tistory.com/463)
[오라클 11g]
- PL/SQL 표준
- 관계지향형 DB : RDBMS 제품
- 고정된 2차원 테이블의 영속성 보장을 위해 사용
- 관계(1:1, 1:n, n:m → 양방향의 관계)
- 복잡한 산술식의 처리 가능
- 객체 모델(Object Model) vs 관계형 모델(Relational Model) ⇒ 데이터를 사용하는 ct의 환경이 계속 바뀜(상황에 따라 맞는 모델로 사용)
객체 모델 관계형 모델 타입 String/int… varchar2/number… 특징 객체 관계를 테이블로 변환하기 쉽지 않음. 변경할 때 마다 새로 반영해야 한다. → myBatis(DB중심 개발, 튜닝가능) → Hibernate(앱 중심 개발, 자동) 등장/NoSQL 등장(하이브리드앱) 양방향 서비스 장점 구조적 나누기 쉬움, 상속 지원, 값도 비교 가능, 동등 비교 가능 많은 데이터, 복잡한 처리 가능, 조인 처리 가능 단점 참조 통해 연결(but 단방향*2로 양방향 처리하는 방) 상속 지원 x, 구조적으로 나누기 어려움
추후 Spring프레임워크 활용 개발 진행 시 - JPA API 구현하게 된다.
관계형 모델에 대한 이해가 있어야 객체모델 설계가 가능하다.
[오라클 활용]
- 데이터 스키마 확인
-
Describe 확인법 → 해당 테이블 드래그 → f4클릭
-
또는 드래그 → ctrl 누른 채 클릭 ‘
⇒ 키, 데이터 타입, 인덱스, 제약조건, 물리적위치 확인
-
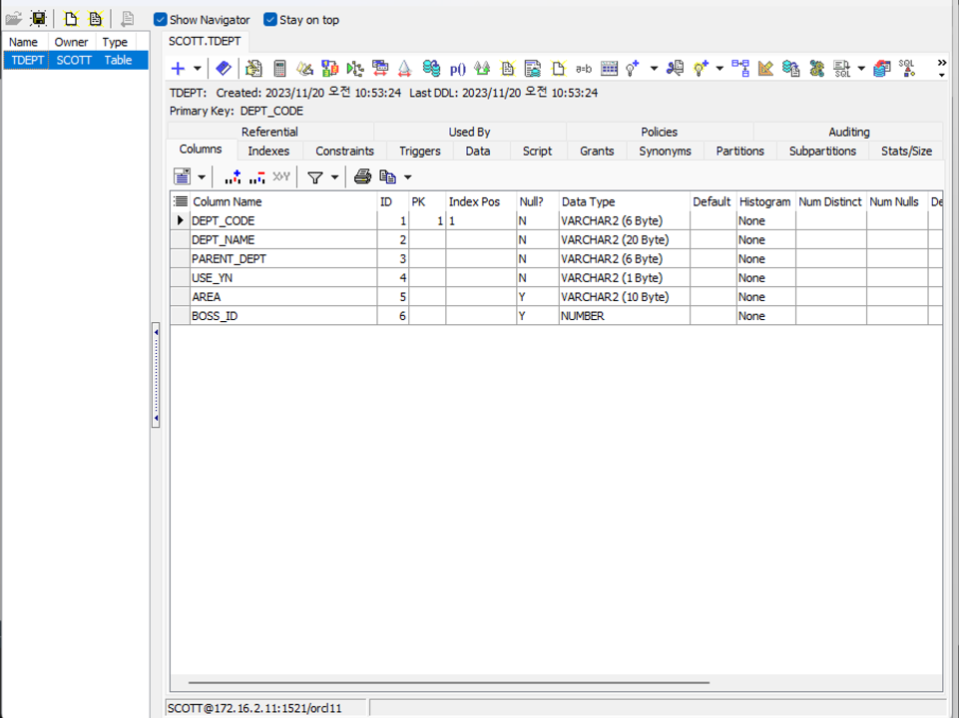
- Decribe 설명
- script : 테이블에 대한 스키마 확인 가능, 테이블 구조 볼 수 있음.
- 언어 설명
- DDL : 시퀀스, 함수 등 구조 정의 (Create, Alter, Rename, Drop)
- 칼럼추가 → 데이터 타입, 크기 결정(물리적 모델링 단계에서 결정)
- 제약조건 → Not null, unique 등
- 인덱스 추가 → 검색속도에 영향 미침(※ PK의 경우, 인덱스 제공, unique)
- DML : 데이터 조작어(Select-3초 이내 조회, Insert, Delete, Update)
- Select(조회) → 속도차이 발생(실력차이 확인 가능), only read(물리적 변화x)
SELECT 컬럼명(여러개 가능, 연산식도 가능, 함수 중첩 사용 가능) FROM 집합(SELECT문도 가능한 자리-서브쿼리:인라인/여러개의 집합 가능-Join의 대상) WHERE 조건검색(예 : deptno = 10;) ---------------------------------------------------------------------------------------- SELECT max(sal), min(sal), avg(sal) FROM emp; --전체 조회 후 사용가능한 함수 -> 검색속도 느림
- Select(조회) → 속도차이 발생(실력차이 확인 가능), only read(물리적 변화x)
- DDL : 시퀀스, 함수 등 구조 정의 (Create, Alter, Rename, Drop)

- PK(고유키) : 인덱스를 기본 제공(인덱스부터 조회한다)→빠르게 조회 가능
- 옵티마이저 : 조건 만족되는 정보를 직접 찾아 오는 일꾼이다🛒 병렬처리 지원, 클러스터 지원
- 조인(객체모델설계), 순서에 따라 조회 속도에 차이가 나타남.
- rowid로 조회 가능
> rowid는? DBMS가 가진 모든 데이터의 각각의 고유한 식별자이다(18자리). index테이블은 index key와 rowid로 구성되어있다. rowid는 index 테이블 내에 있는 해당 데이터를 찾기 위한 논리적 정보일 뿐이다.
>
```jsx
**AAARE8AAEAAAACTAAA
//**6자리 : 데이터 오브젝트번호
//3자리 : 상대적 파일번호
//6자리 : 블록번호
//3자리 : 블록 내 행 번호
```
- DCL : 권한 부여 및 삭제 (Grant, Revoke), 트랜잭션 관리(commit, rollback)- 서버
- 이전에는 호이스팅 방식
- 요즘은 AWS라는 플랫폼을 통해 합리적으로 진행
- Join
-
cross join (카타시안의 곱 → A join B, A row * B row), 쓰레기값들이 많이 출력됨.
-
natural join
- cross join의 쓰레기값 제거--조인의 예시(cross join - 카타시안의 곱 - 총합, 소계 구할 때 사용) --emp 14row, dept 4row -> **56개**의 값이 나옴. --왜 복제하나?? 하나의 같은 값이 총계, 소계, 중계 등 여러번 사용되어야 하기 때문이다. . SELECT dept.dname, emp.deptno, dept.deptno FROM emp, dept; --쓰레기값도 포함되어 있다. 이걸 제거하려면?? natural join --where를 통해 1:n의 관계에서 deptno가 외래키로 들어가 있을 때 그 두개의 값이 같은 유의미한 값만 가져오도록 --유의미한 **14개**의 값이 나옴. SELECT dept.dname, emp.deptno, dept.deptno FROM emp, dept WHERE emp. deptno = dept.deptno;
-
- round(숫자, 나타낼 자리 수)
SELECT round(12345.6789,1), round(12345.6789,-1), round(12345.6789,0) FROM dual; -- 12345.7 12350 12346 - 날짜 sysdate
SELECT sysdate, To_char<(sysdate,'YYYY-MM-DD') ,to_char(sysdate, 'YYYY-MM-DD HH24:mi:ss am') ,to_char(sysdate, 'YYYY-MM-DD HH:mi:ss am') ,to_char(sysdate, 'day') FROM dual; --2023/11/20 오후 3:25:06 2023-11-20 2023-11-20 15:25:06 오후 2023-11-20 03:25:06 오후 월요일 - 집합함수
- union : 중복값 제외 → 정렬 → 속도 느림
- union all : 중복값 제외x → 속도 빠름
- minus : 차집합
- intersect : 교집합
- 작성법
- AS 뒤 “ “
- 문자열 ‘ ‘
- not in 연산자에 null이 포함되면 어떠한 결과 값도 조회하지 못 함.
- 치환하기
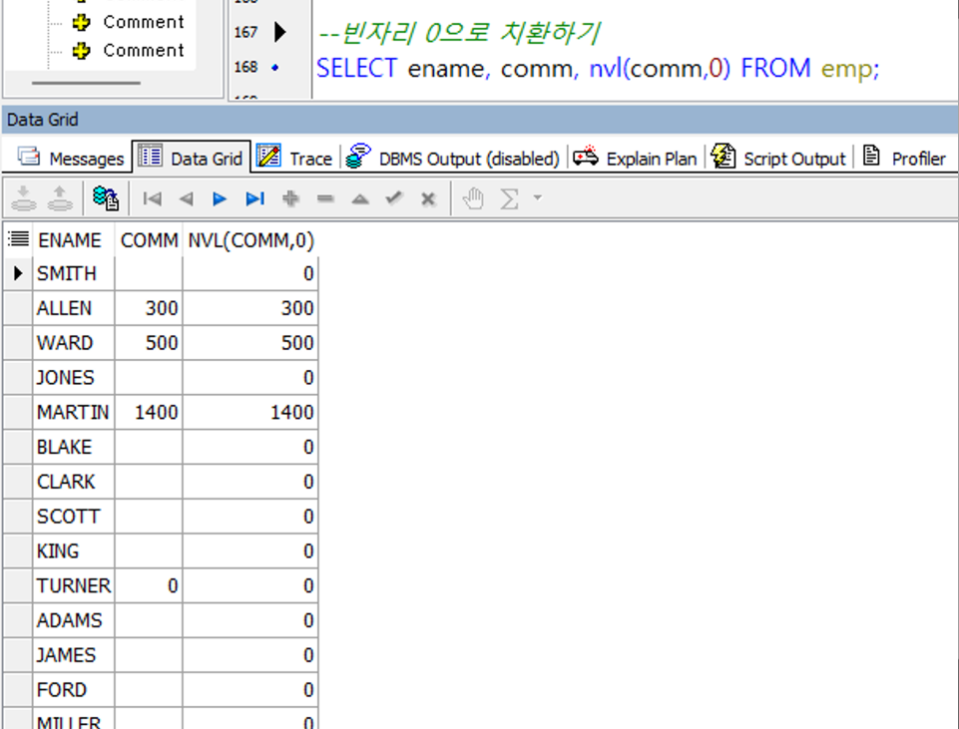
--5.TEMP의 자료 중 HOBBY의 값이 NULL인 사원을 ‘등산’으로 치환했을 때
--HOBBY가 ‘등산인 사람의 성명을 가져오는 문장을 작성하시오.
SELECT emp_name, 취미
FROM (SELECT emp_name, NVL(hobby,'등산') AS 취미 FROM temp)
WHERE 취미 = '등산';
SELECT emp_name, NVL(hobby,'등산') AS hobby FROM temp;
SELECT emp_name FROM temp
WHERE nvl(hobby,'등산') = '등산';강의 마무리
- 자바 복습 필수
