MoCo
- 2020년 논문
: Momentum Contrast for Unsupervised Visual Representation Learning
: 비지도 학습 기반의 representation learning 알고리즘
매우 많은 key가 존재하는 dictionary에서 query로 들어온 데이터에 대해 positive key에 대해서는 유사도가 높아야 되고 negative key에 대해서는 유사도가 낮아야 한다.
문제 제기
현재 contrastive loss들을 사용하는 방법들은 1)large, 2)consistent 둘 중에 하나에 제한되어 있다.
unsupervised learning의 주요 목적
features와 같은 표시들은 fine-tuning을 통해서 학습된다. MoCo는 detection(탐지)나 segmentation(분할)관련된 7개의 작업들을 진행한다.
MoCo의 unsupervised pre-training은 ImageNet supervised보다 능가할 수 있다.
MoCo는 unsupervised와 supervised 방식에서 차이를 줄이고 Imagenet supervised pre-trainig에 대안을 제공할 수 있다.
학습 방법
Contrastive learning as Dictionary look-up
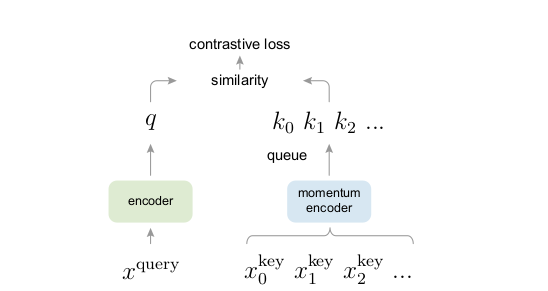
x에 대한 representation q와 dictionary에 존재하는 representation k0, k1,...에 대하여 같은 데이터로부터 파생된 키에 대하여 유사도를 높이고 다른 데이터로부터 파생된 키에 대하여 유사도를 낮추는 방향으로 학습을 진행함. dictionary에는 {k1, k2, ..}가 있고 q에 맞는 dictionary에 single key(k+)가 있다.
원할한 학습을 위해 1)키가 매우 많아 다양한 negative pair를 확보할 수 있는 large dictionary와 2) 일관된 표현을 위해 느리게 업데이트 되는 key encoder가 필요하다.
mini-batch의 encode된 representation들은 enqueued(먼저 들어가고), 가장 오래된 representation들은 dequeued(먼저 나간다).
queue는 mini-batch 크기로부터 dictionary 크기를 분리시켜 크게 만들 수 있다. 따라서 queue구조를 통해 query 인코더의 momentum 기반 움직이는 평균은 일관성을 유지시킬 수 있다.
contrastive loss는 q가 positive key인 k+와 같을 때 값은 작고
다른 key들과는 비슷하지 않다.(negative keys for q)
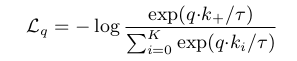
InfoNCE
Momentum Contrast
MoCo에서 중요한 점은 query에 대해 representation을 추출하는 query encoder와 dictionary에 있는 key에 대해 representation을 추출하는 key encoder로 정의함.
좋은 특징들은 negative sample들을 가지는 대량의 사전들로부터 학습되고, 그 사전 keys들의 encoder는 "consistent"하게 유지된다.
Dictionary as a queue
Dictionary size는 mini-batch size보다 더 크고 hyper parameter로서 독립적으로 있다.
current mini-batch는 dictionary에 추가되고 oldest mini-batch는 제거된다.
The dictionary always represents a sampled subset of all data, while the extra computation of maintaining this dictionary is manageble. Moreover, removing the oldest mini-batch can be beneficial, because its encoded keys are the most outdated and thus the least consistent with the newest ones.
Momentum update
gradient를 포함해 query encoder인 fq로부터 key encoder인 fk를 복사하는 방법은 좋지 않은 결과를 가져왔다.(논문 4.1)
즉 encoder를 바꾸는 것은 key representations' consistency를 줄이는 것이라고 가정해서 momentum update를 만들었다.

Relations to previous mechanisms
1) end-to-end update by back-propagation
: mini-batch를 dictionary로 삼아 fq와 fk를 공유한다. dictionary크기가 mini-batch 사이즈에 연관되어 GPU메모리 사이즈에 제약이 생긴다. SimCLR과 같은 모델은 mini-batch가 커져서 GPU 메모리 크기때문에 사용이 어렵다.
2) memory bank
: memory bank는 데이터셋에서 모든 sample들의 representation을 만든다. 모든 데이터의 representation은 back-propagation없이 memory-bank를 랜덤 샘플링을 진행한다. 그래서 큰 dictionary를 만들 수 있다. 그러나, 이전의 업데이트된 encoder로부터 추출된 것이므로 일관성이 떨어진다. 또한, 메모리 측면상 비효울적이다.

MoCo는 모든 sample들을 따르지 않는다. MoCo는 더 메모리를 효율적으로 사용하고 백만개의 규모 데이터도 잘 훈련시킬 수 있다. memory bank와는 별개로 사용한다.
Pretext Task
- Technical details
: Encoder로 ResNet을 사용했다. ResNet의 global average pooling이후에 128차원 출력을 L2로 normalize한 것이 representation이 된다.
출력 벡터는 L2-norm에 의해 계산된다. temperature는 0.07로 고정한다.
데이터 증강할 때 이미지 사이즈는 224*224로 한 후, random color jittering, random horizontal flip, random grayscale conversion을 사용했다.
- Shuffling BN
: encoders인 fq와 fk는 모두 Batch Normalization(BN)을 한다. 이 실험에서 BN을 사용하면 good representatons 학습하는 것을 막는다는 것을 깨달았다. 그 모델은 이전 작업을 "cheat"하고 low-loss solution을 발견했다. 또한, BN이 만든 intra-batch communication이 정보를 손실시킨다.
이 문제를 해결하기 위해 shuffling BN을 사용했다. 다양한 GPU를 사용해서 독립적인 샘플들에 BN을 실행했다.
