
MySQL을 주로 사용해왔던 사람이라면, 혹은 DB에 대해서 깊지 않게 생각한 사람이라면 PostgreSQL과 MySQL이 이름만 다르지 크게 다르지 않을거라고 생각할 수 있다.
과거의 나도 그러했는데 막상 사용하다보니 각각의 특징과 매력이 있다는 것을 알게 되었다.
그중에 두 DB의 차이의 핵심이라고 생각되는 Vacuum이라는 개념을 알아보려고 한다.
Vacuum에 대해 알기 전에 PostgreSQL이 어떻게 이루어져있는지 알아보자.
Tuple
MySQL에서 사용하는 row와 같은 역할을 하는 친구라고 생각하면 편한데 PostgreSQL은 데이터가 Tuple로 저장된다.
Tuple은 Live Tuple, Dead Tuple 총 2종류의 Tuple이 존재한다.
간단하게 번역해보면 살아있는 튜플, 죽은 튜플로 번역 그대로의 역할을 한다.
Live Tuple은 테이블 조회 시 보이는 데이터이고, Dead Tuple은 일련의 과정으로 인해 물리적 공간에 남아있는 불필요 데이터를 의미한다.
아래 쿼리를 실행시켜보면 현재 테이블별 live tuple과 dead tuple을 확인할 수 있다.
SELECT c.relname AS table_name,
pg_stat_get_live_tuples(c.oid) AS live_tuple,
pg_stat_get_dead_tuples(c.oid) AS dead_tupple
FROM pg_class AS c
JOIN pg_catalog.pg_namespace AS n
ON n.oid = c.relnamespace
WHERE pg_stat_get_live_tuples(c.oid) > 0
AND c.relname NOT LIKE 'pg_%'
ORDER BY dead_tupple DESC;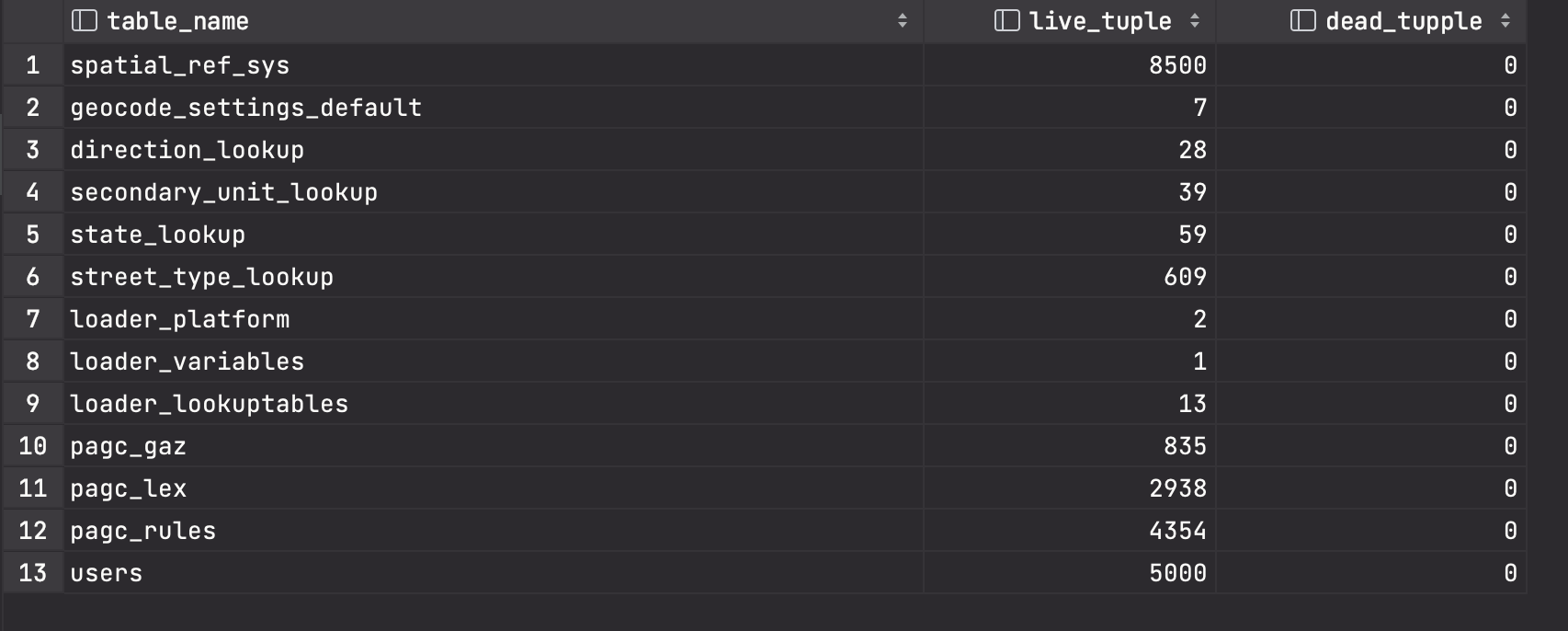
무슨 기준으로 Live, Dead Tuple으로 나뉘고 왜 이렇게 작동할까?
PostgreSQL은 Update 쿼리는 MySQL과 성질이 다르다.
user 테이블에 아래의 데이터가 저장되어 있다고 가정해보자.
{"id": 1, "name" : "홍길동", "email" : "hong@velog.io"}두 DB에서 아래 쿼리를 실행하면 다른 동작이 발생한다.
UPDATE name = '김철수'
FROM user
WHERE id = 1;MySQL은 우리가 흔히 알고 있듯이 id: 1 인 row의 값이 Replace 되는 것에 반해 PostgresSQL은 name:김철수라는 tuple을 새롭게 생성한다.
{"id": 1, "name" : "홍길동", "email" : "hong@velog.io"}
{"id": 1, "name" : "김철수", "email" : "hong@velog.io"}id가 겹치는 데 오류 나는 게 아니냐고? 아니다.
PostgreSQL은 기존홍길동의 Live Tuple을 Dead Tuple로 전환하고 새로운 Tuple을 INSERT한다.
Dead Tuple {"id": 1, "name" : "홍길동", "email" : "hong@velog.io"}
Live Tuple {"id": 1, "name" : "김철수", "email" : "hong@velog.io"}즉, 새로운 Tuple이 UPDATE가 아닌 INSERT 되는 방식이다.
DELETE도 마찬가지로 Dead Tuple로 전환시키는 행위이다.
여기까지 읽었으면 왜??라는 생각이 가장 우선적으로 들 것이다.
MVCC
RDBMS은 안전하게 데이터를 제공할 의무가 있는데 PostgreSQL은 MVCC 기법을 사용하여 최대한의 의무를 다하고 있는 것이다.
MVCC(Multi-Version Concurrency Control)는 쿼리 수행 시점의 데이터를 제공하는 기법이다.
MVCC에는 2가지 방법이 있다.
- MGA(Multi Generation Architecture)
- Rollback Segment
PostgreSQL는 이중 MGA 방식을 사용중이다.
MGA 특징은 아래와 같다.
- Tuple 별로 유효 XID를 저장해둔다.
- 어떤 데이터에 업데이트가 일어나면 기존 데이터는 그대로 두고 새로운 데이터가 추가된다.

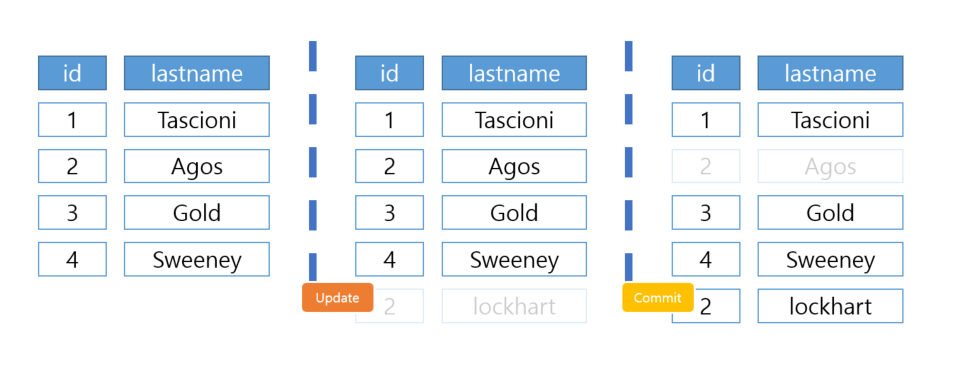
위 이미지 기준으로 설명해보자면
- New Tuple 2가 등록된 시점은
XID: 30이다.- Old Tuple 2은 Dead Tuple로 변경된다.
- XID(Transaction Id): 30
이후의 연결은 New Tuple 2을 제공한다.- XID: 30
이전의 연결은 Old Tuple 2을 제공한다.
다양한 버전에서 안전하게 데이터를 제공해주는 엄청난 기법이지만 기술엔 항상 장단점이 있는 법.
해당 기법을 사용하기 위해선 앞서 Dead Tuple 개념에 대해 설명했듯이 물리적으로 데이터가 저장되어 용량을 차지하고 있다는 것이다.
Dead Tuple의 단점을 아래와 같다.
1. SELECT 성능을 영향을 끼친다.
2. 물리적으로 저장되어 있어 불필요한 용량을 차지한다.
3. Tuple에 잡혀있는 XID가 반환되지 않아 가용 XID 수가 줄어든다.
PostgreSQL은 이 문제를 어떻게 극복했을까?
Vacuum
먼저 Vacuum이라고 검색해보면 검색하면 청소기 사진들이 뜰 것이다. 사전 정의는 아래와 같다.
- 진공
- 공백
- 진공청소기로 청소하다
이미지와 사전의 내용을 생각해보면 무엇인가 굉장히 깨끗(?)해질 것 같은 기분이 들지 않나?
그리고 한번 DB에서 아래 쿼리를 한번 실행시켜 보아라.
-- 현재 실행중인 쿼리 확인용 쿼리
select *
from pg_stat_activity;
이미지를 보면 우리가 쳤던 select * from pg_stat_activity 가 보이고 우린 실행도 하지도 않은 다른 것들도 같이 보인다.
이들은 Wait Event Types이라고 불리며 PostgreSQL을 정상적으로 사용하도록 도와주는 액티비티들이다.
오늘은 이것들에 대해서 다루지는 않을 것이고 AutoVacuum 과 관련된 Event Acitity가 이미 실행되고 있다는 것만 확인시켜주려고 했다.
Vacuum은 앞서 설명했던 MVCC를 통해 생성된 Dead Tuple을 정리하여 FSM(Free Space Map)으로 반환하는 작업을 진행한다. 물론 Dead Tuple만 정리하는 것은 아니다.
FSM은 각 테이블 별 사용 가능한 공간으로 생각할 수 있다.
Vacuum은 Vacuum과 AutoVacuum로 크게 2가지로 나눌 수 있다.
Vacuum 명령어는 아래와 같다.
명령어에
full이 들어간 것은 table lock이 걸리니 운영 환경에선 사용하면 안된다.
-- DB 전체 풀 실행
vacuum full analyze;
-- DB 전체 간단하게 실행
vacuum verbose analyze;
-- 해당 테이블만 간단하게 실행
vacuum analyse [테이블 명];
-- 특정 테이블만 풀 실행
vacuum full [테이블명];vacuum verbose는 Dead Tuple 정리, XID 반환 작업을 진행하고 vacuum full은 테이블별 할당된 크기 회수까지 추가로 진행된다.
AutoVacuum의 경우 기준에 따라 vacuum verbose이 실행시키는 것이라고 생각하면 된다.
AutoVacuum이 실행되는 기준이 존재하며 PostgreSQL 에서는 이를 조정할 수 있는 여러 옵션들을 제공한다.
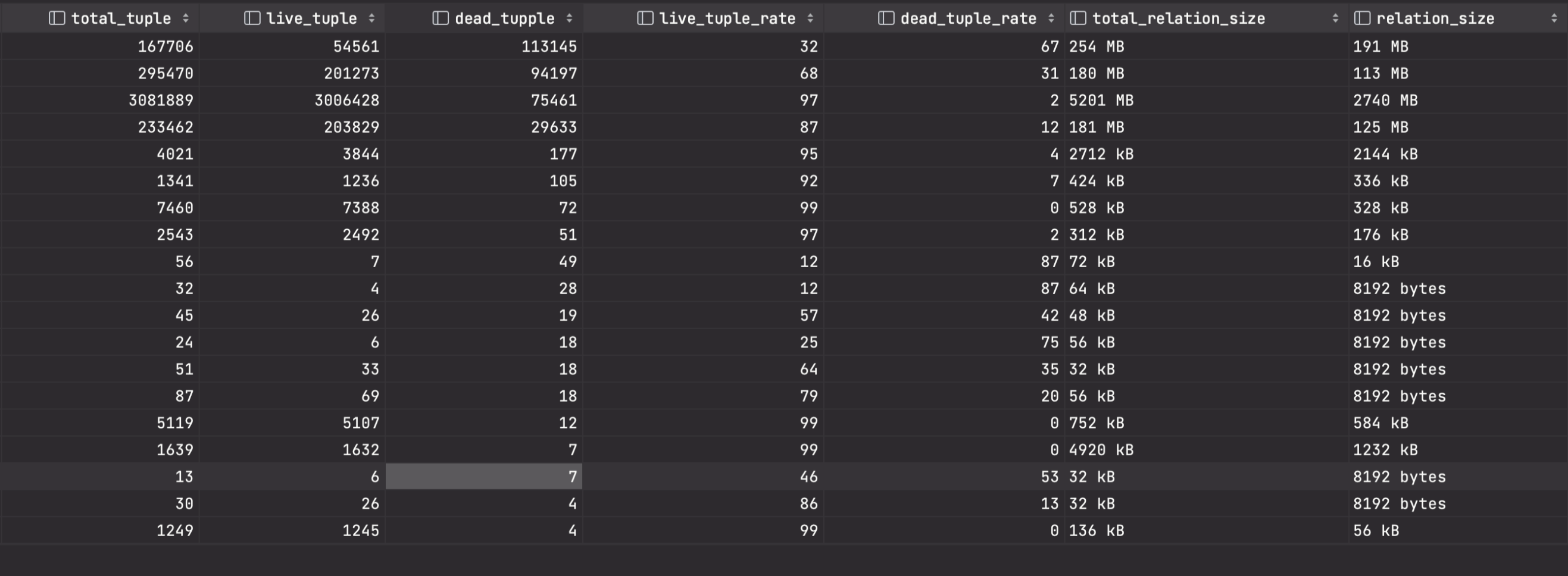
잘못된 튜닝은 아래처럼 tuple 역전 현상이 생기는 등 역효과가 날 수 있다. 검색해보면 튜닝에 관련한 좋은 자료들이 많으니 제대로 공부하고 적용시키자.
출처
