Scikit-learn: 교차 검증(Cross validation) KFold, Stratified KFold, cross_val_score()
Machine-Learning
지난 공부에서는 Scikit-learn의 전반적인 내용을 통해 머신러닝을 한번 돌리는 것에 초점을 맞춰서 글을 썼습니다.
오늘은 그 속에서도 모델의 성능을 높일 수 있는 방법 중 하나인 교차 검증에 대해 정리를 해보고자 합니당.
왜냐면 내가 이걸 다 까먹었기 때문 🍊reference: 파이썬 머신러닝 완벽 가이드
Cross-validation : 교차 검증
교차 검증이란 Overfitting을 방지하고 모델의 성능을 높이기 위해 행하는 방법의 하나입니다.
하나의 data를 train dataset과 test dataset으로 분할한 다음, train dataset을 다시 train dataset과 valid dataset으로 분할하여 본고사를 치르기 전에 모의고사를 여러번 볼 수 있게 하는 방식이라고 할 수 있습니다.
K-Fold 교차 검증
K-Fold라고 해야할 지 KFold라고 해야할지,,,;ㅅ;KFold 교차 검증이 무엇일까
| 시도횟수 | 데이터 세트1 | 데이터 세트2 | 데이터 세트3 | 데이터 세트4 | 데이터 세트5 | 검증 평가 |
|---|---|---|---|---|---|---|
| 1회 | 학습 | 학습 | 학습 | 학습 | 검증 | 검증 평가1 |
| 2회 | 학습 | 학습 | 학습 | 검증 | 학습 | 검증 평가2 |
| 3회 | 학습 | 학습 | 검증 | 학습 | 학습 | 검증 평가3 |
| 4회 | 학습 | 검증 | 학습 | 학습 | 학습 | 검증 평가4 |
| 5회 | 검증 | 학습 | 학습 | 학습 | 학습 | 검증 평가5 |
앞서 정리했던 바와 같이 KFold Cross Validation이란 K만큼 접어서 검증한다는 뜻입니다
위의 표에서 학습 데이터 세트를 5개만큼 나누고 이를 하나씩 검증 데이터셋으로 바꿔가면서 총 5번의 검증 평가를 냅니다.
이 5번의 검증 평가는 평균을 내서 최종 평가 점수를 내게 됩니다.
이렇게 되면 fold를 한 다음에 가장 결과가 좋은 검증 평가를 낸 시도에다가 가중치를 부여하는 방법도..
가능할 것 같네여,, 아마 있을법한데 구글링 왜 안나와 ㅠ_ㅠK-Fold 기본 예제 코드
파이썬 기본기를 배움과 동시에 머신러닝 공부를 시작했는데, 파이썬 언어에 대한 숙련도가 워낙 부족하다보니 아무리 좋은 KFold 예제 코드를 봐도 이해하기가 쉽지 않았습니다,,,
사실 아직도 그닥 숙련된 수준은 아니지만.. 어쨌든, 간단하게 KFold를 적용한 예제 코드를 작성해보려고 한다.
from xgboost import XGBClassifier
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings(action = 'ignore')
from sklearn.datasets import load_wine
# 데이터 가져오기
np_data = load_wine()
wine_data = np_data.data
wine_label = np_data.target
data = pd.DataFrame(data = wine_data, columns = np_data.feature_names,)
data['label'] = np_data.target
# 모델 선언
model = XGBClassifier()
# Kfold
SPLITS = 5
kf = KFold(n_splits = SPLITS)
n_iter = 0
features = data.iloc[:,:-1]
label = pd.DataFrame(data['label'])
score_list = []
for train_idx, test_idx in kf.split(features, label):
n_iter += 1
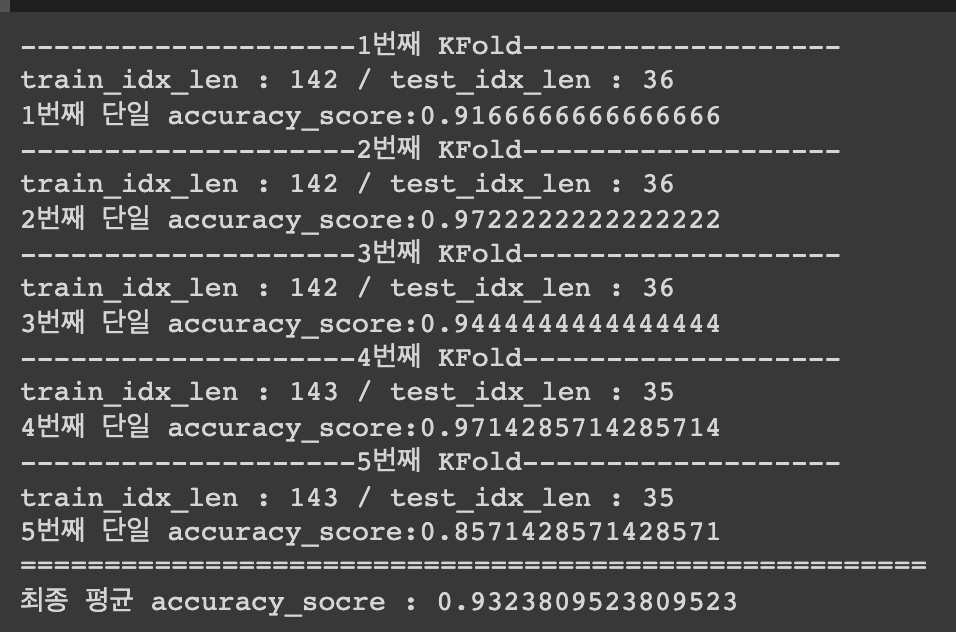
print(f'--------------------{n_iter}번째 KFold-------------------')
print(f'train_idx_len : {len(train_idx)} / test_idx_len : {len(test_idx)}')
label_train = label.iloc[train_idx]
label_test = label.iloc[test_idx]
X_train, X_test = features.iloc[train_idx, :], features.iloc[test_idx, :]
y_train, y_test = label.iloc[train_idx,:], label.iloc[test_idx,:]
model.fit(X_train, y_train)
preds = model.predict(X_test)
score = accuracy_score(y_test, preds)
print(f'{n_iter}번째 단일 accuracy_score:{score}')
score_list.append(score)
print('======================================================')
print(f'최종 평균 accuracy_socre : {sum(score_list)/len(score_list)}')엄청 간단하게 적어 보았는데,
아무튼 결과는 이러하다
Stratified K-Fold 교차 검증
앞선 게시글에서 설명한 바와 같이, skewed 되어 있는 데이터의 경우에는 치우쳐진 데이터만 잔뜩 뽑아서 KFold 를 만들 가능성이 높기 때문에 그것을 방지하기 위해 Stratified KFold를 사용할 수 있다.
from xgboost import XGBClassifier
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings(action = 'ignore')
from sklearn.datasets import load_wine
# 데이터 가져오기
np_data = load_wine()
wine_data = np_data.data
wine_label = np_data.target
data = pd.DataFrame(data = wine_data, columns = np_data.feature_names,)
data['label'] = np_data.target
#모델 선언
model = XGBClassifier()
# Stratified KFold
SPLITS = 5
skf = StratifiedKFold(n_splits = SPLITS)
n_iter = 0
features = data.iloc[:,:-1]
label = pd.DataFrame(data['label'])
score_list = []
for train_idx, test_idx in skf.split(features, label):
n_iter += 1
print(f'--------------------{n_iter}번째 KFold-------------------')
print(f'train_idx_len : {len(train_idx)} / test_idx_len : {len(test_idx)}')
label_train = label.iloc[train_idx]
label_test = label.iloc[test_idx]
X_train, X_test = features.iloc[train_idx, :], features.iloc[test_idx, :]
y_train, y_test = label.iloc[train_idx,:], label.iloc[test_idx,:]
model.fit(X_train, y_train)
preds = model.predict(X_test)
score = accuracy_score(y_test, preds)
print(f'{n_iter}번째 단일 accuracy_score:{score}')
score_list.append(score)
print('======================================================')
print(f'최종 평균 accuracy_socre : {sum(score_list)/len(score_list)}')동일한데, StratifiedKFold로만 바꿔주었다.
많이 skewed된 칼럼도 없었는데도 성능의 차이가 있었다. 데이터의 양이 작아서 그런가?

그래서 간단하게 plot을 찍어봤는데,
아주 째끔? ㅋㅋ ㅠ_ㅠ
근데 도대체 이 colab에서 fig 크기 어떻게 키우는거야,, 댄쟝그럼 이 긴 코드를 줄여봅시다.
인간의 나태함은 세상을 발전시킨다...
Cross_val_score
방금 말했던 일련의 과정들을 한번에 계산해서 제공하는 API입니다.
1. Fold set 설정
2. for문 반복을 통해 학습 데이터셋의 인덱스, 테스트 데이터셋의 인덱스를 추출하고
3. 학습하고 예측해서 성능을 냄
을 한번에 해냅니다.
from xgboost import XGBClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import cross_val_score
import numpy as np
import pandas as pd
# 데이터 불러오기
np_data = load_wine()
wine_data = np_data.data
wine_label = np_data.target
data = pd.DataFrame(data = wine_data, columns = np_data.feature_names,)
data['label'] = np_data.target
features = data.iloc[:,:-1]
label = pd.DataFrame(data['label'])
# 모델 선언
model = XGBClassifier()
score = cross_val_score(model, features, label, scoring = 'accuracy', cv=5)
print(f"단일 accuracy : {score}")
print(f"5번의 fold 후 평균 accuracy: {np.mean(score)}")오 코드가 짧아지니 너무 기분이 좋다,,
cross_val_score() 은 모델, 피쳐, 타겟, 평가지표, 폴드횟수를 입력 파라미터로 받습니다.
기본적으로 StratifiedKFold를 기준으로 리턴해주며, 회귀의 경우 StratifiedKFold를 쓸 수 없으므로 KFold로 계산해서 리턴해준다고 합니다.

accuracy를 이렇게 리스트로 리턴해주는 것도 처음 알았다. 오호랑..
데이터도 작고 해서 1.0을 뱉나보다 처음 보는 숫자 ;ㅅ;

안녕하세요!
글 잘 읽었습니다.
궁금한게 있는데요.
k-fold를 했을 시, 평균 검증값만 산출되어 이를 하이퍼파라미터 튜닝에만 이용하는 것인가요?
아니면 k-fold를 통해 평균값으로 구한 새로운 모델이 구축되는 것인가요?
새롭게 구축이 된다면 이것을 다시 train dataset에 적용하여 학습을 다시 시키고
마지막으로 test dataset으로 평가를 하는 것인가요?