

딥러닝의 모델 학습 및 학습과정 그래프에 대한 설명
목차
- fit()
- parameter 종류 소개(batch_size, epochs, verbose, callback, validation)
- loss, accuracy / val_loss, val_accuracy 그래프
- fit()
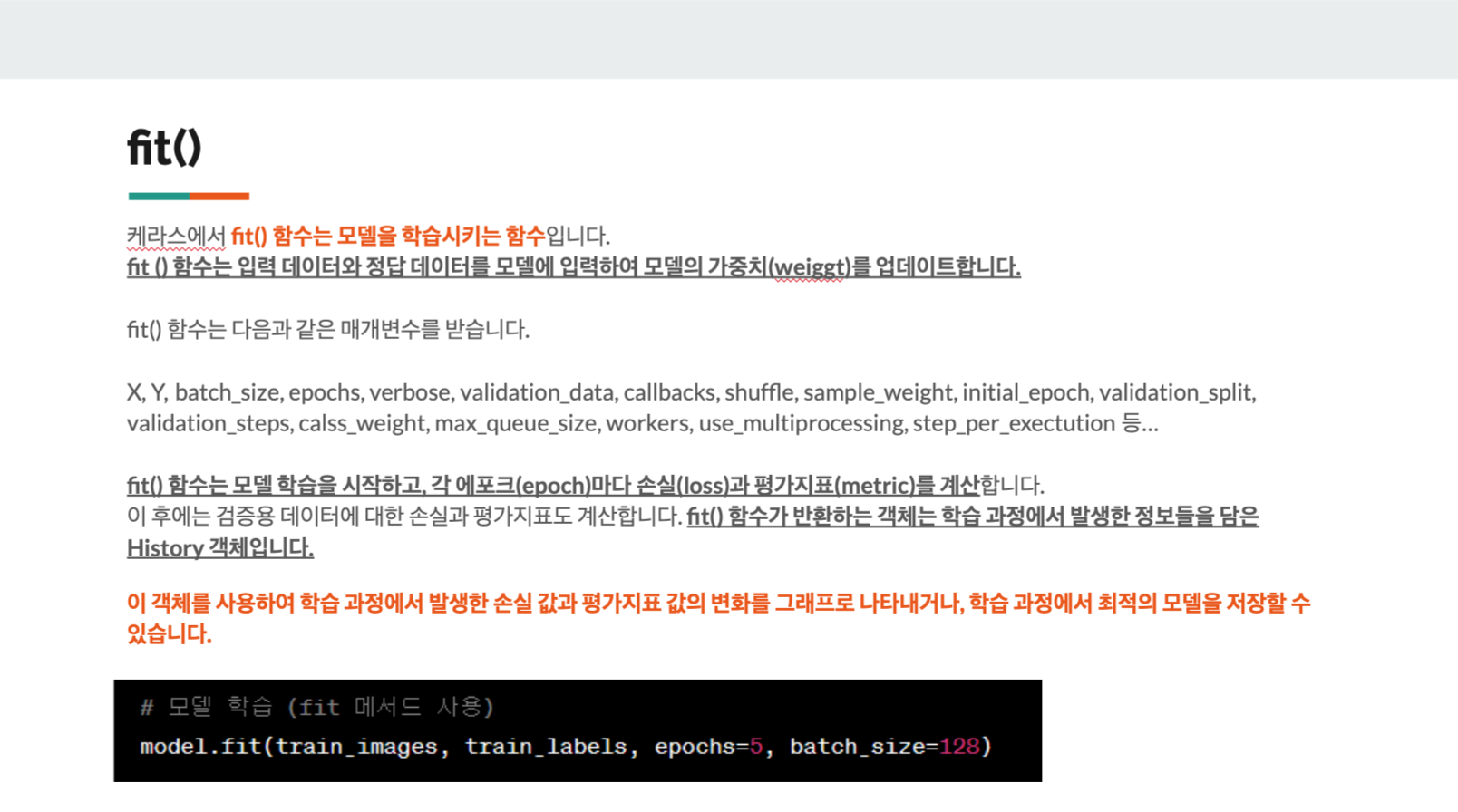
fit()은
model이라는 변수에 저장한 모델을 학습시키는 함수이다.
- model을 정의
- model의 input, hidden, output layer를 설정
- model 컴파일(compile)
- model 학습(fit)
아래는 신경망을 만드는 코드 예이다.
#model이라는 변수에 Sequntial()을 저장한다.
model = Sequential()
#model에 input, hidden, output layer 설정
model.add(Dense(units=5, activation='relu', input_shape=(39,)))
model.add(Dense(units=5, activation='relu'))
model.add(Dense(units=2, activation='softmax'))
#model compile
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
#model fit
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test), shuffle=True)
- 파라미터
1) batch_size
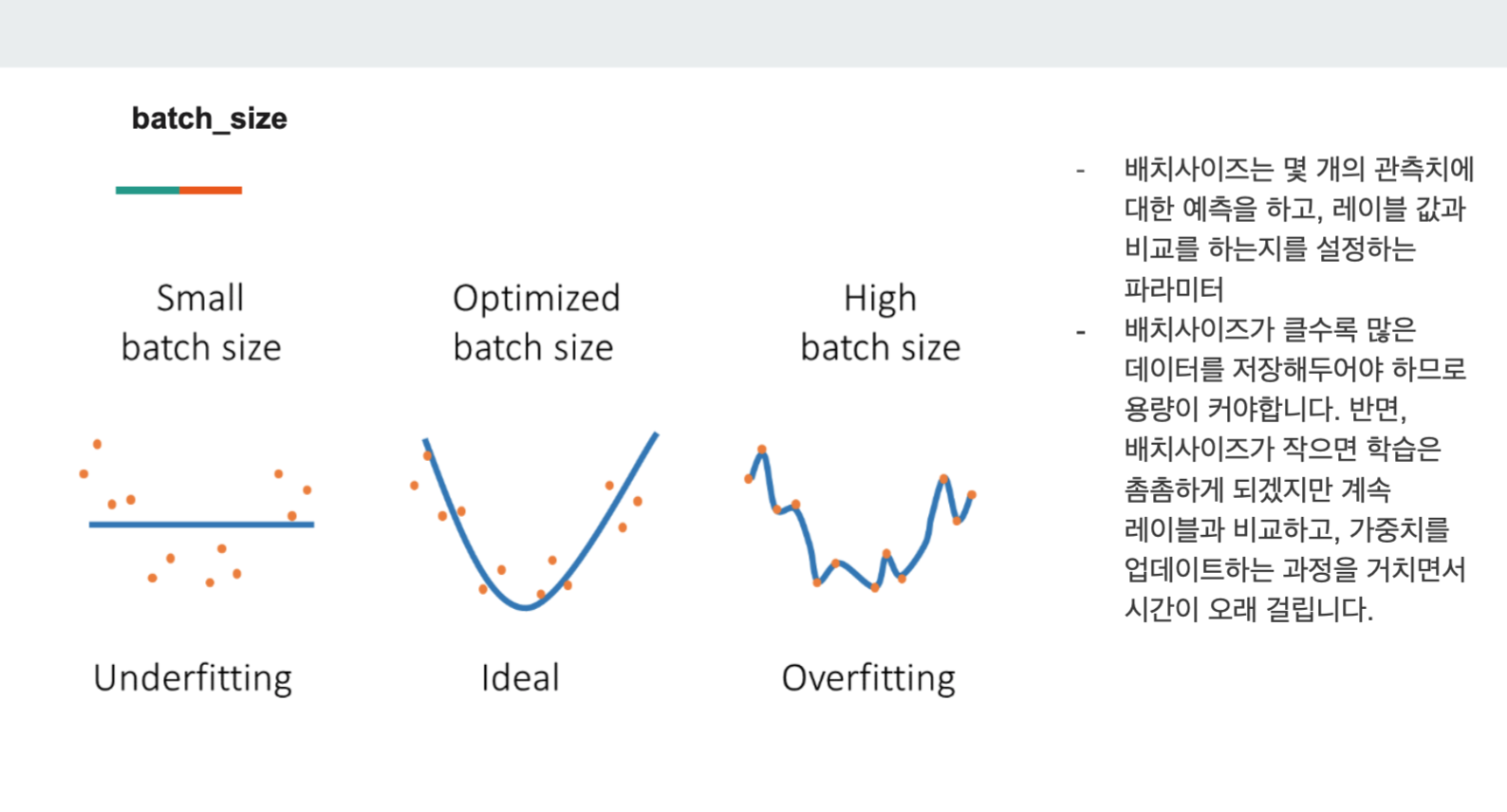
batch_size는 모델에 한번에 입력되는 데이터 개수의 크기를 말한다.
batch_size가 클수록 많은 데이터를 한번에 학습하여 학습속도가 빨라진다는 장점이 있지만 컴퓨터 메모리 요구사항도 높아진다.
batch_size가 작으면 학습은 촘촘하게 진행되고, 메모리 요구사항도 낮다는 장점이 있지만 학습이 느리다.
*batchsize는 보통 2의 제곱수를 사용함
2) epochs
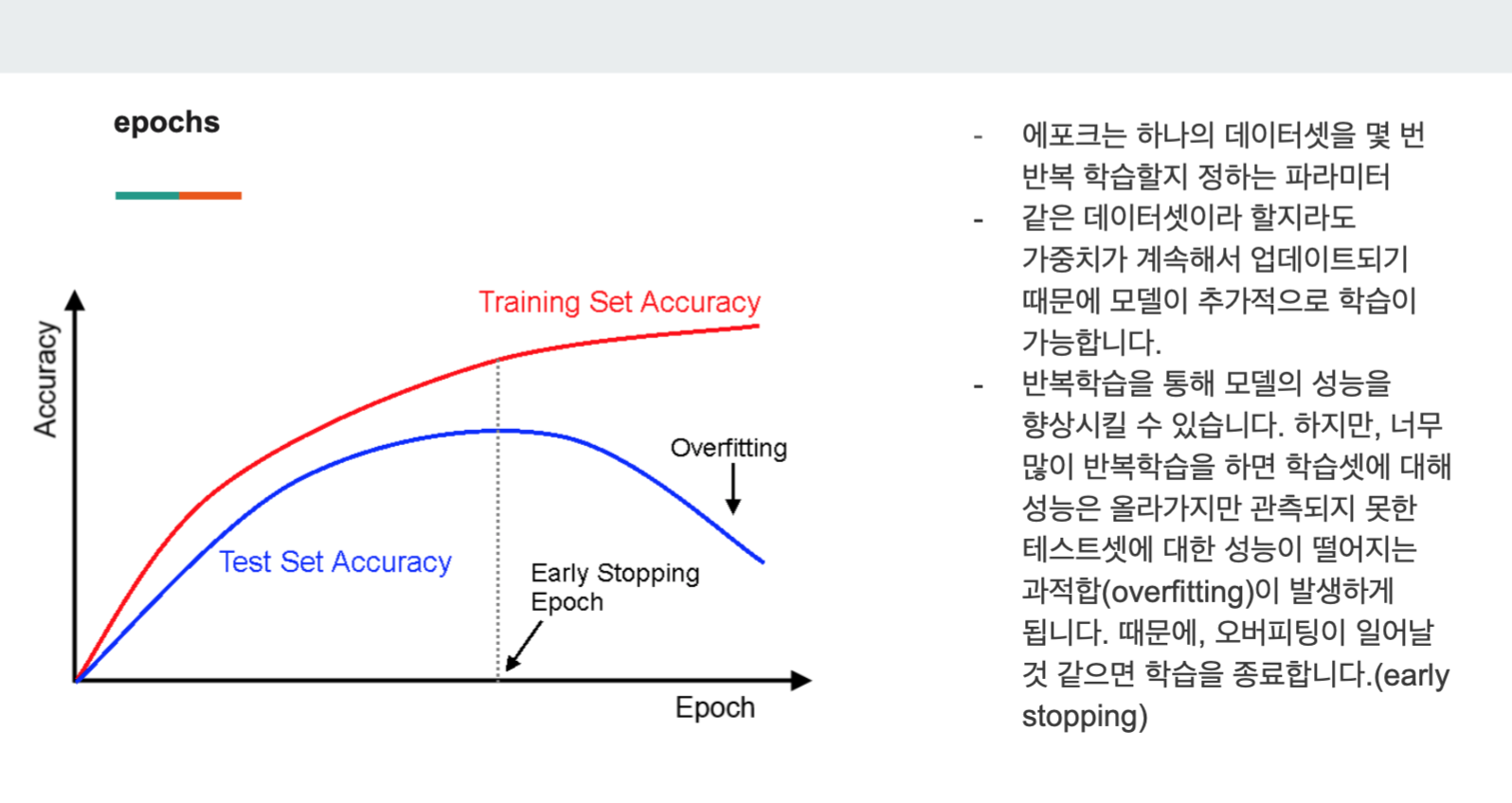
epochs(에포크)는 하나의 데이터셋을 몇 번 반복해서 학습할지 정하는 파라미터이다.
10, 20, 200등 원하는만큼 학습이 가능하다.
다만, 그래프에서 보다싶이 에포크와 성능이 비례하지 않는다. 과도하게 학습할경우, 과적합이 발생하게 되므로 Early Stopping을 이용해서 학습을 종료한다.
Early Stopping은 바로 아래에서 다룰 예정이다.
3) verbos
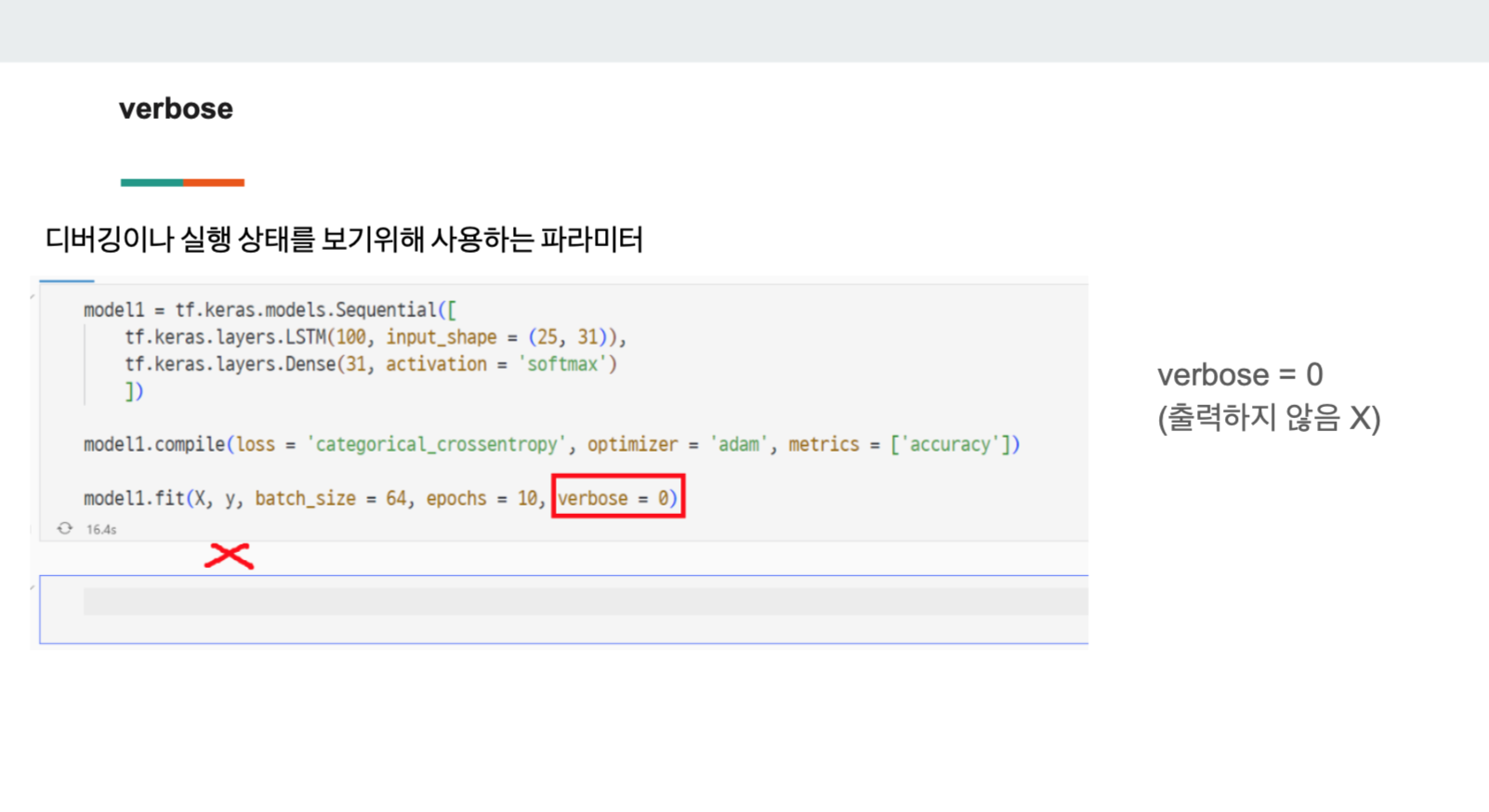
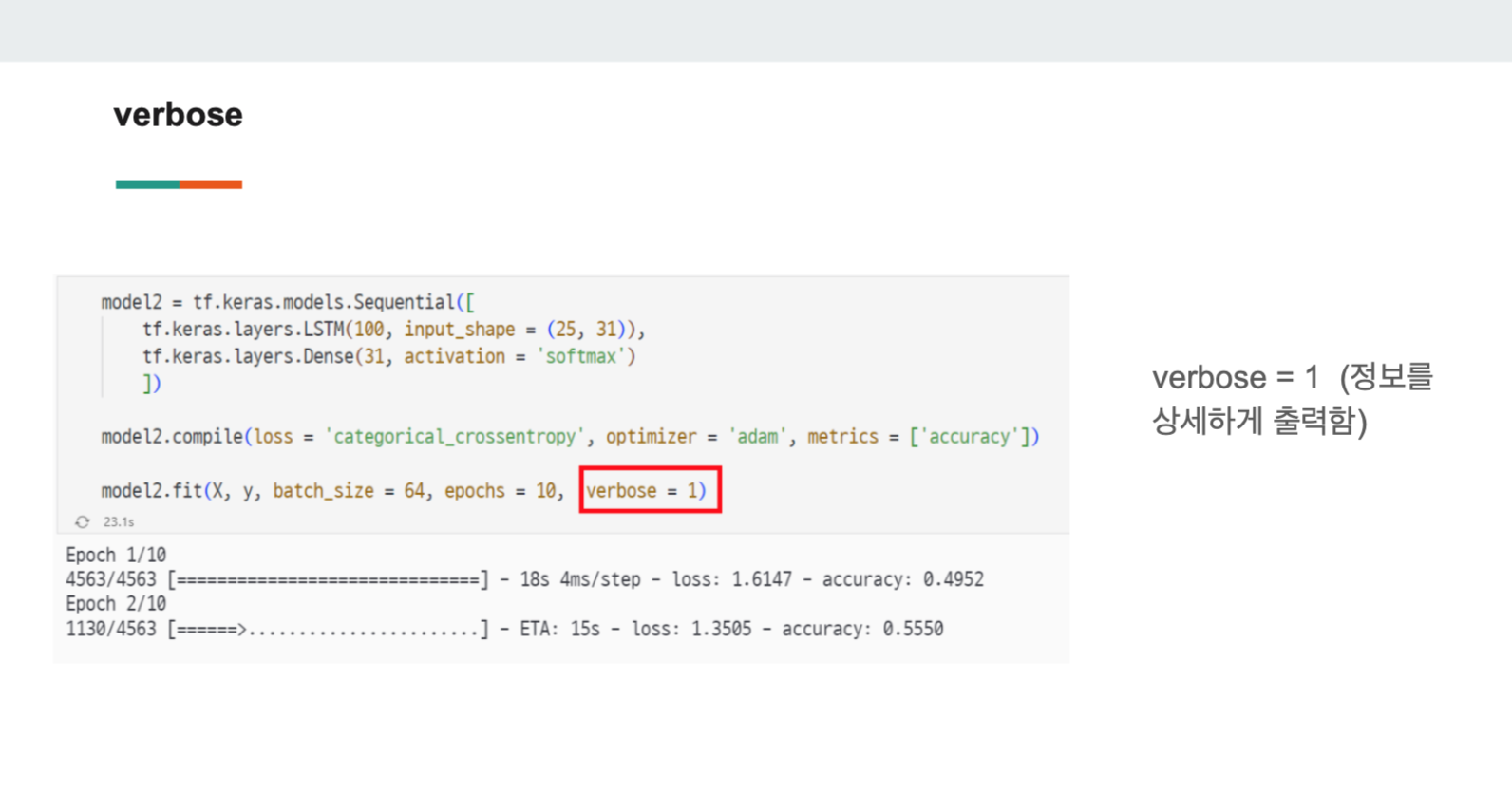
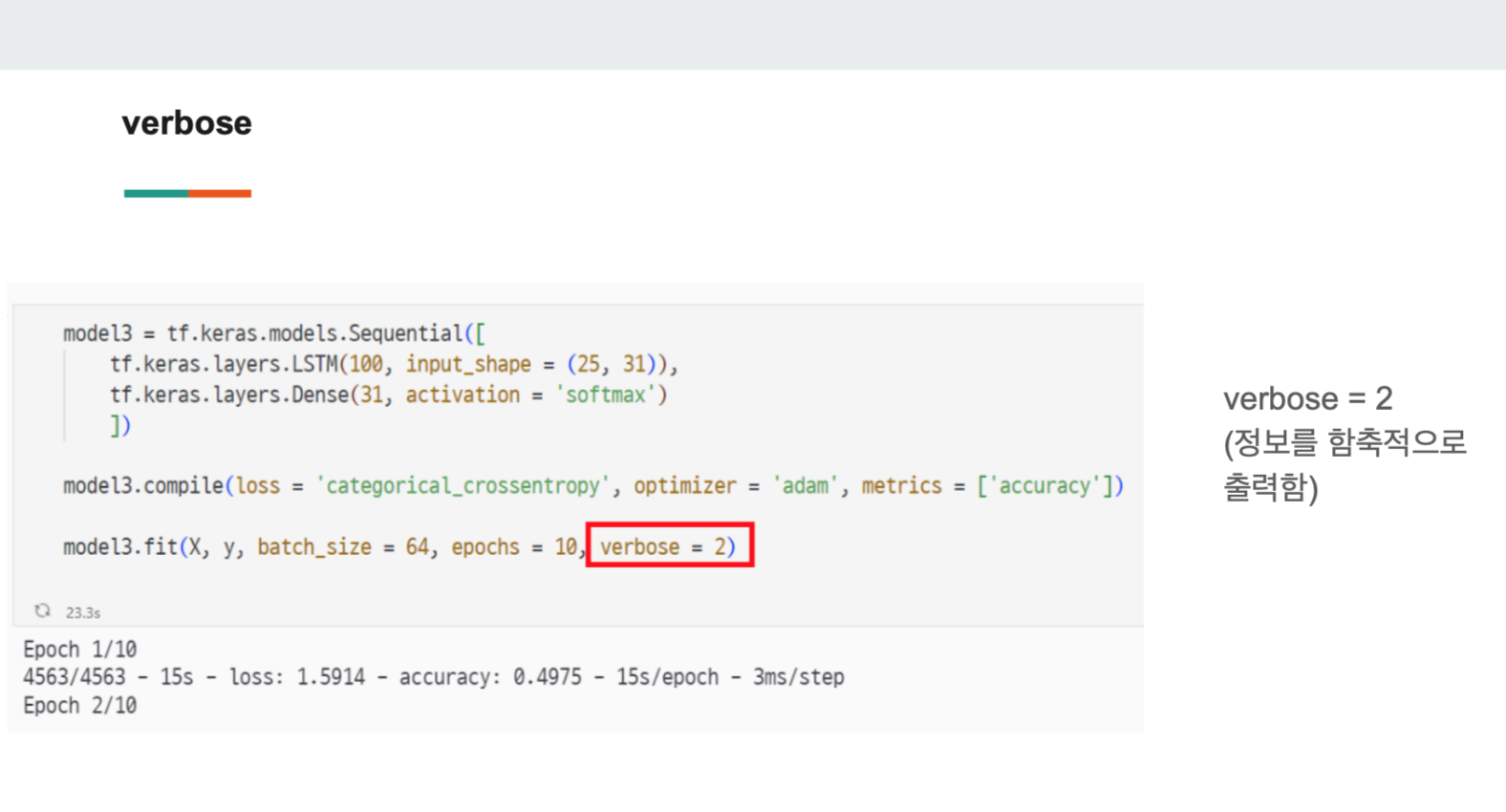
verbose는 코드의 수행 또는 디버깅을 모니터링할 때 사용되는 파라미터이다.
#verbose = 0
#아무것도 보여주지 않음
modelfit(X_train, y_train, batch_size = 64, epochs = 10, verbose = 0)
# verbose = 1
#정보를 자세히 보여줌
modelfit(X_train, y_train, batch_size = 64, epochs = 10, verbose = 1)
#verbose = 2
#정보를 함축적으로 보여줌 (2 이상)
modelfit(X_train, y_train, batch_size = 64, epochs = 10, verbose = 2)
4) EarlyStopping

EarlyStopping은 과적합을 방지하기 위함이며 EarlyStopping을 통해 훈련을 종료시킬 수 있다.
callback = tf.kears.callbacks.EarlyStopping(monitor = 'loss', patience=3)epochs 학습 중 loss가 3번 동안 개선이 안되면 멈추게 하는 예시 코드이다.
5) Checkpoint

Checkpoint는 중간중간에 현재 학습하는 값을 저장하는 용도이다.
6) Learning rate (나는 이게 어렵다!!)

Learning rate(학습률)은 이차함수의 해를 미분을 통해 찾아가기 위함이다. 즉 최적화(Optimization)를 위해 학습률을 이용하는데,
y = wx + b
(x,y) 값이 정해져 있을 때, 가장 적합한 w(가중치),b(바이너리)를 학습률을 조절하여 찾아간다.
학습률이 너무 작으면 해를 찾아가는데 시간이 오래 걸린다.
학습률이 너무 크면 해를 찾기 전에 값이 요리조리 함수 안을 튀어 버린다.(= 발산한다)
7) validation

validation이란 검증하기 위해 사용되는 파라미터로 loss와 accuacy를 나타낸다.
- 그래프 그리기
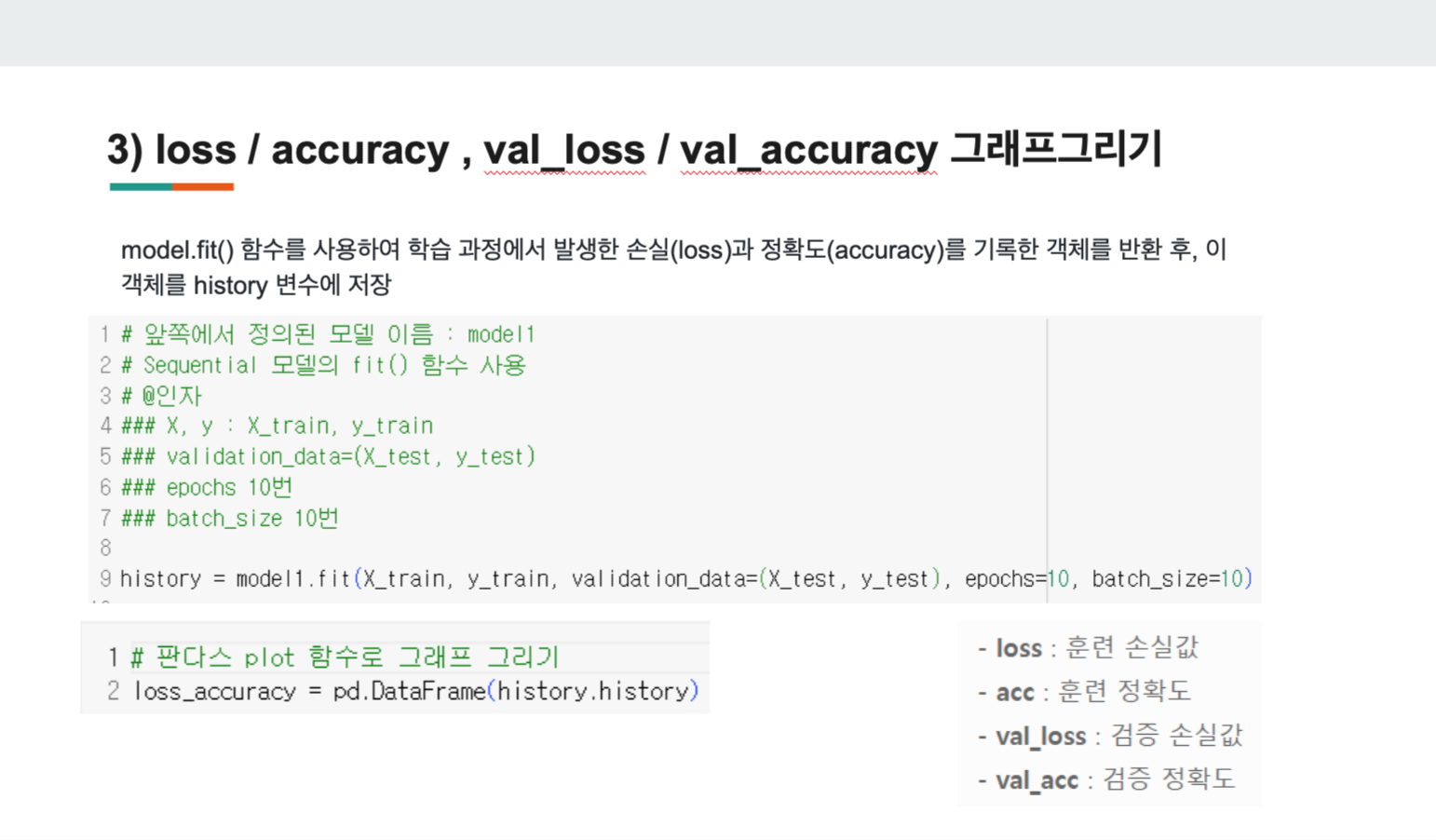
위와 같이 'history'변수에 저장해 그래프를 그린다.
1) loss
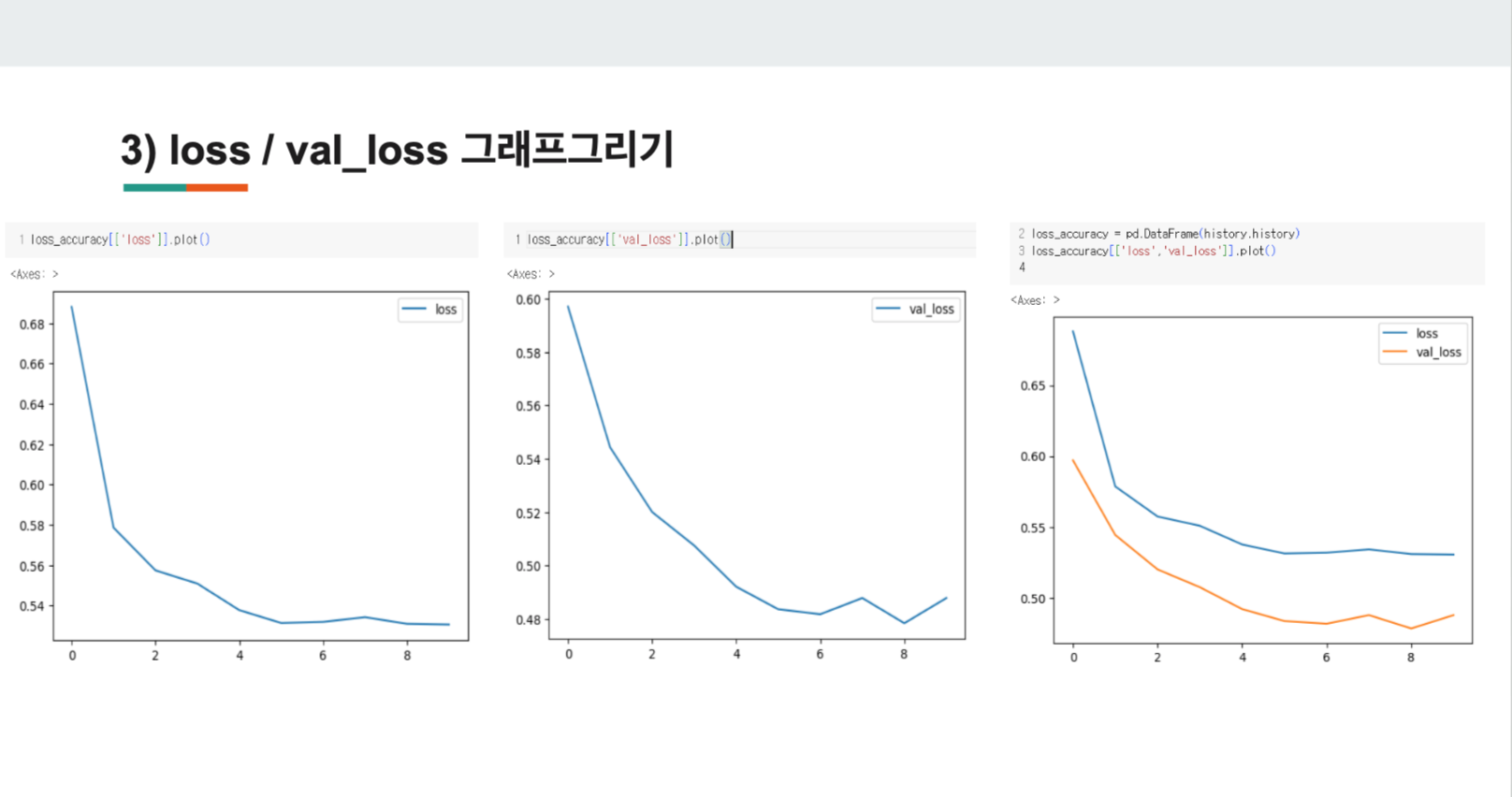
x축(epochs)가 증가할 수록, y축(loss)가 낮아지는걸 볼 수 있다.
2) accuracy
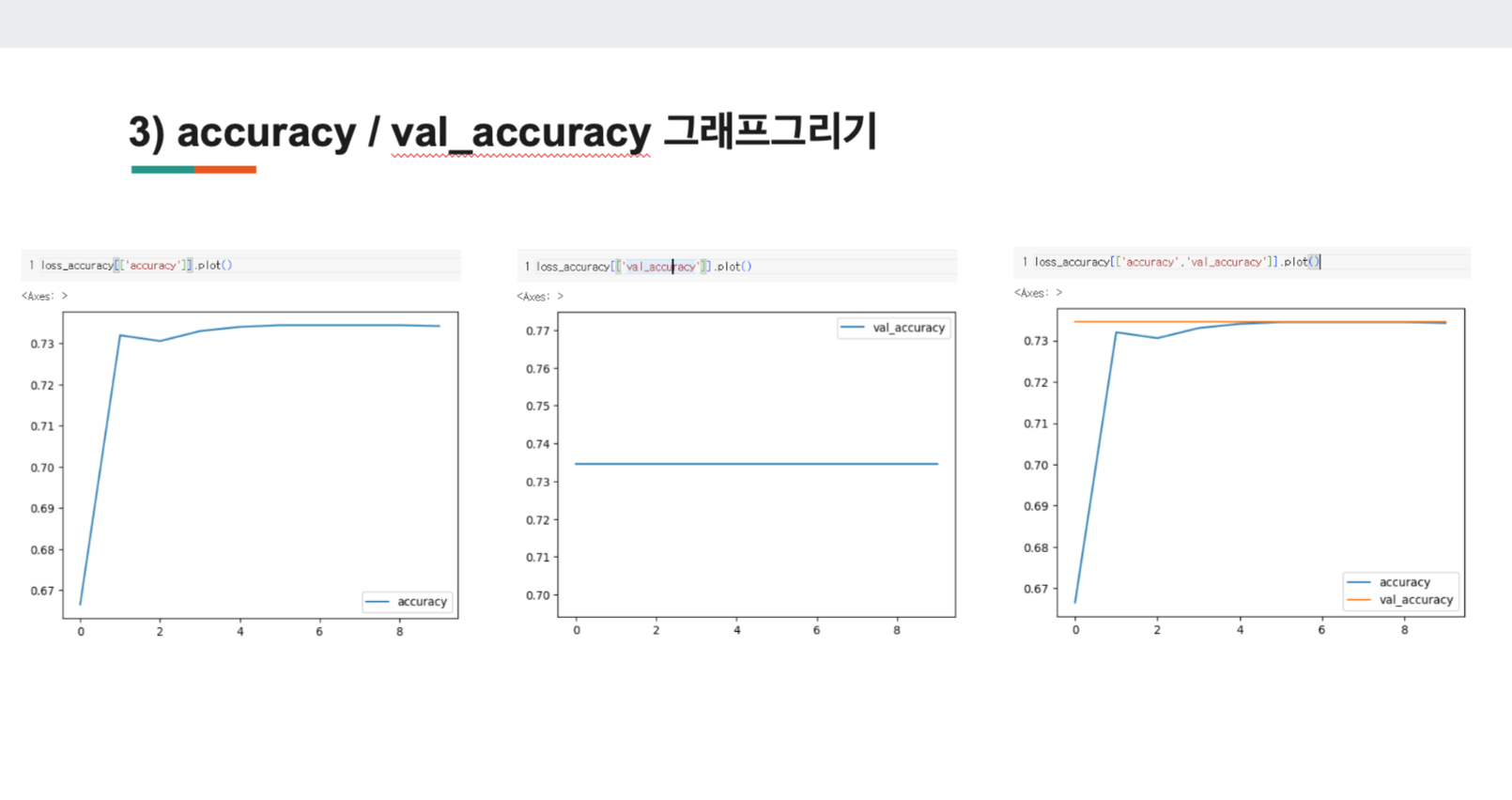
x축(epochs)가 증가할 수록, y축(accuracy)가 높아졌다가 수렴하는 것을 볼 수 있다.
