1. Preview
Multi Cloud Management Platform python plugin 개발을 하면서 Azure가 제공해주는 Virtual Machine Scale Sets API (python sdk)를 이용해 resources를 inquire / control (Power off / on.. etc) 하는 업무를 맡았다.
Virtual Machine Scale Sets(이하 VMSS) A to Z, sdk 사용 방법과 함께 AWS Autoscaling과 닮은 듯 다른 점들을 비교해봤다.
2. Virtual Machine Scale Sets?
load balanced 될 VM 집합을 만드는 것. 미리 정의된 schedule에 따라서 자동적으로 VM수가 증가, 감소 된다. AWS의 Autoscaling과 동일한 개념의 서비스이다.
관리해야할 vm이 많을 때 중앙에서 관리가 쉽게끔 해줘서 대규모 서비스에 유용하다.
2-1. 특징
VM Scaleset 을 사용하면 기본 OS 이미지, 구성을 따서 Virtual Machiens 쌍둥이 인스턴스들이 만들어진다. 디스크 붙이고 떼고, 네트워크 관리 하나하나 이런거 안해줘도 되며, 한번에 통일해서 설정을 관리한다.
기본 4계층 트래픽 분산은 Load Balancer를 사용, 7계층 트래픽 분산은 AG를 사용하도록 지원한다.
Azure는 scale-in, scale-out 을 리소스 수요 변화에 따라서 자동으로 조정하는데, Scaling 정책에 관해서는 기존에 AWS로 알던 기준과 차이가 좀 있어서 아래에 조금 자세히 적겠음..
최대 1000개까지 vm instance scaling을 지원한다. 하나의 VmScaleSet에 같은 spec의 VM 생성을 지원한다. 이미지를 고유하게 내가 구성하는 경우(Snapshot을 이용한 VMSS생성)에는 600개까지만 가능하다.
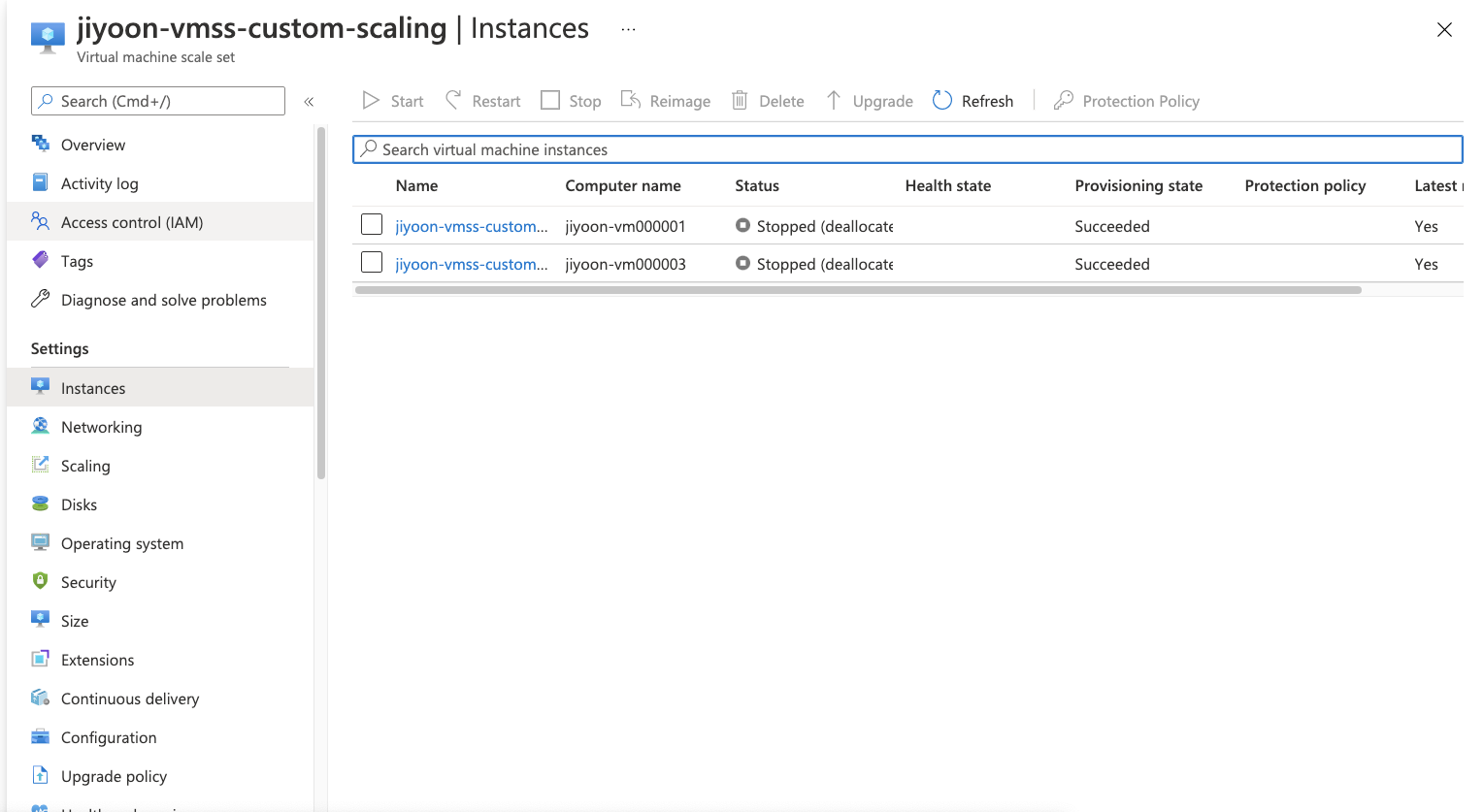
- Difference with AWS?
AWS auto scaling instances의 경우, Autoscaling의 서비스 카테고리가 EC2 소속으로, Autoscaled 된 instances가 EC2 main instances 조회 화면에서 보인다.
Azure의 경우, VMSS는 VM과는 완전히 다른 서비스 카테고리 소속으로 (Service code:Microsoft.Compute/VirtualMachines↔️Microsoft.Compute/VirtualMachineScaleSets) Virtual Machines의 콘솔 화면에서 한번에 관리가 불가능하며, API도 나눠져 있다.
2-2. Network
Virtual Machine Scale Sets의 NIC 설정을 한번만 구성해서 vm들에 대한 네트워크 연결을 정의한다. 보안 그룹 규칙을 사용하거나, 기존 Load Balancer의 back-pool에 VMSS를 배치해 Scaleablity 를 조정한다.

2-3. Scaling
VM인스턴스를 자동으로 늘리거나 줄일 때 정책을 설정한다. Scaling 정책은 Scale-in (축소정책) 과 Scale-out (확장 정책) 2가지가 있다.
2-3-1. Azure의 Scaling 정책

특이하게도, Virtual Machine Scale Sets의 Autoscaling 부분은 Azure / Azure Monitor 서비스 소속으로, API 호출부터 관리가 Azure Monitor 카테고리의 하위에서 이루어진다.
(참고로 Virtual Machine Scale Set 자체는 Azure / Virtual Machine Scale Set 서비스 - <Microsoft.Compute/VirtualMachineScaleSets 소속)
서비스 카테고리를 언급하는 이유는, Azure의 API가 서비스 카테고리 별로 산재해 있기 때문이다. 만약 보여주고 싶은 정보가 현재 Virtual Machine Scale Sets의 목록이라면, Virtual Machine Scale Sets API 1 call로 가능하지만, Auto scaling 정책도 함께 보여주고 싶다면, VMSS N개 당 Monitoring 소속의 Autoscaling API도 추가로 M번 call 해야 하고, 결과적으로
(N*M)번 API 를 call하기 때문에 성능과 속도 저하로 이슈가 이어질 수 있다.
2-3-2. Auto scale rules with condition mode
Scaling 정책에는 custom mode 와 Manual Mode가 있다.
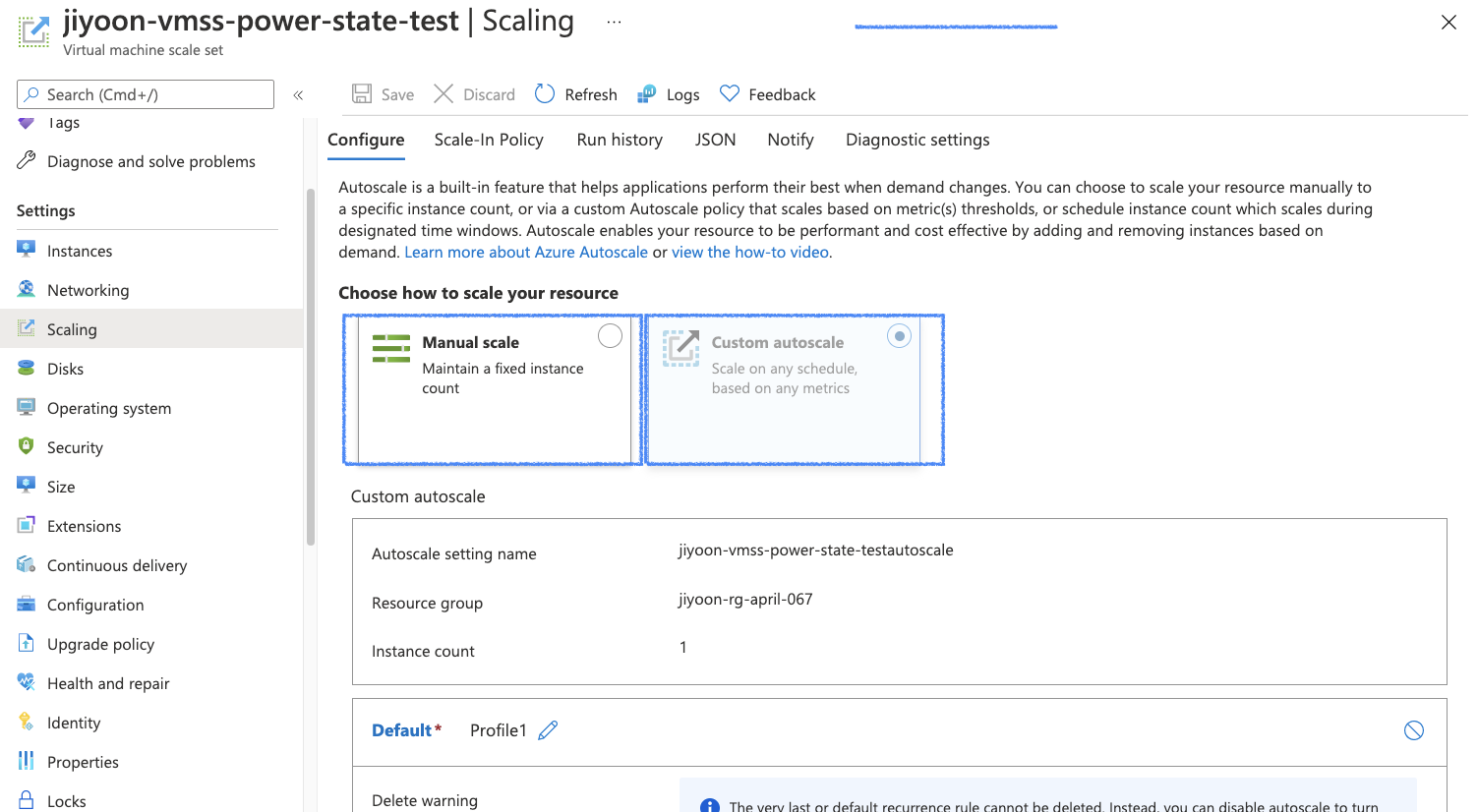
Virtual Machine Scale Sets > Scaling 탭에서 컨트롤 가능하다.
두가지 Mode에 대한 description은 아래와 같다.
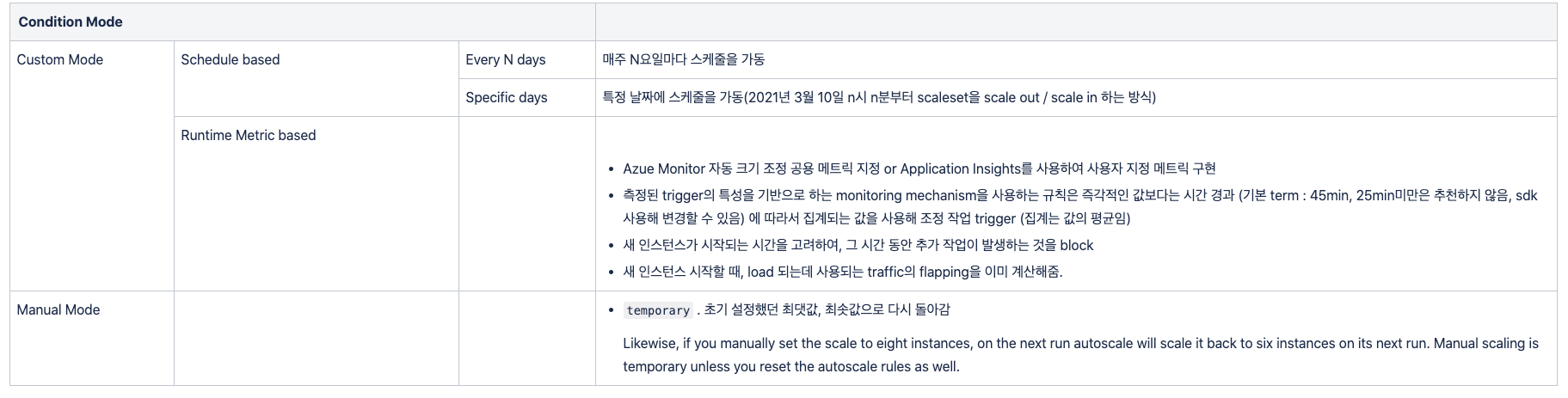
이 rules를 감싸고 있는 Azure의 논리적인 단위가 Profile이다.
2-3-3. Autoscale Unit
- Autoscale one profile at a time. Profile 단위로 실행한다.
- 만약에 profile이 조건에 안맞으면, checks for the next profile.
- 하나의 Profile은 여러개의 rules로 이뤄져 있음
2-3-4. Rule Priority
- Scale Out : 어떤 규칙이던 규칙이 충족되면 auto scale
- Scale In : 모든 규칙을 충족해야 auto scale
- Scale out 은 항상 Scale in 보다 우선됨
- Scale out 이 충돌하면 인스턴스를 가장 많이 늘리는 규칙이 우선함
- Scale in 이 충돌하면 인스턴스를 가장 적게 늘리는 규칙이 우선함
2-4. Monitoring 및 VM 관리
2-4-1. VM Upgrade policy
VM 인스턴스 수 조정 할 때의 업그레이드 정책 설정 옵션에 3가지가 있다.
Automatic, Manual, Rolling upgrade
| Upgrade mode | Desc |
|---|---|
| Automatic | 인스턴스들이 무작위 순서로 업그레이드를 시작함 |
| Manual | 인스턴스들을 수동으로 업그레이드 해줘야함 |
| Rolling | 선택적으로 몇 개 중지하고, 일괄적으로 롤아웃함 |
2-4-2. Monitoring
| Monitoring Type | Desc |
|---|---|
| Booting Diagnostics(부팅진단 모니터링) | - Booting시에 생기는 문제를 진단하도록 instance console 출력 혹은 스크린샷을 뜰껀지 여부를 지정한다. - storage account에 연결해서 이 계정 하나만 가지고도 다른 도구로도 모니터링 할 수 있는 기능을 지원한다. 오.. |
| Application Status Monitoring (애플리케이션 상태 모니터링) | App endpoint에서 상태 모니터링을 구성해서 인스턴스의 App 상태를 업데이트 할 수 있음. - Application health extension : health monitor를 하고 싶은 목적 인스턴스의 protocol, port, path 정의 - Load balancer probe: 기존에 LB만들 때 세운 정책 사용 |
2-4-3. Overprovisioning
실제로 요청한 vm수보다 더 많은 vm 돌린다음에 provisioning을 성공한 후에 추가 vm을 제하는 방식. 장점이 2개 있다.
- 배포 시간 줄여준다.
- 추가 vm에 대한 요금은 청구되지 않음.
Microsoft에서 클라우드를 만들 때 Advanced features에 대한 고민이 보이는 부분이었다.
2-4-4. 자동 OS 업그레이드
scale set내 모든 인스턴스 OS disk 안전하게 업그레이드 할 시에 자동으로 해줄지 설정하는 옵션이다.
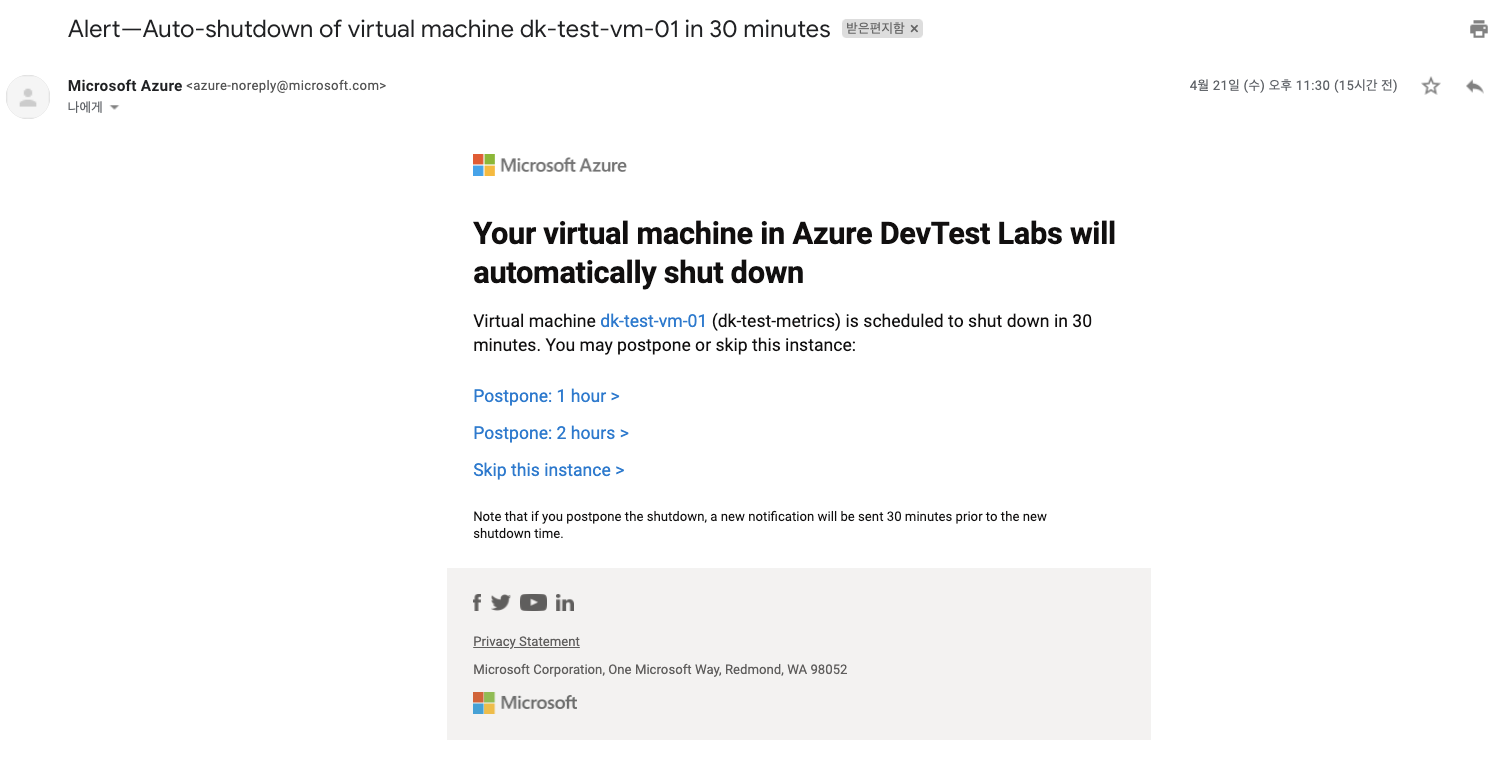
2-4-5. 인스턴스 종료 알림
Azure Metadata Service를 통해 인스턴스 종료 알림을 수신하도록 설정하고, 종료 작업을 지연시킬 시간 제한을 설정함. (단위 : min, 최대 15분)
종료 알림을 메일로 수신해봤는데, 이런 식으로 schedule에 따라 미리 알림 메일을 준다.
2-4-6. 자동 Repair 정책
자동으로 unhealthy한 인스턴스들은 지우고, 인스턴스 최신 모델 세팅으로 repair 해주는 옵션이다.
유예 기간(단위 : 분, 30분~90분 사이로) 설정할 수 있는데 vm이 죽었을 때 이 시간 동안 유예되어서 우발적으로 repair 되는 것을 방지한다.
2-4-7. 할당 정책
100개 이상 scaling out 되도록 허용하거나, 확산 알고리즘, 장애 도메인 수를 결정하고 배포 시 설치해줄 플러그인도 선택한다.
VM 확산 알고리즘
한 데이터 센터(zone)에서의 failure보다 더 작은 단위 내에서 (아마도 rack?) resource provisioning failure 의 가용성을 보장해주는 Azure의 개념인fault domain 사이에서 Virtual Machine Scale Sets가 균형을 이루는 방식 결정하는 옵션이 2가지 있다. Max spreading / Fixed spreading .
| Spreading Options | Desc |
|---|---|
| Max spreading | VM들이 각 영역에서 가능한 한 많은 Fault Domain에 분산된다. |
| Fixed spreading | 항상 5개 Fault domain내에 분산되는데, Fault domain이 5개 미만이면 "Fixed spreading" 옵션을 사용했던v vm scalesets는 배포에 실패한다. |
2-5. Vm scalesets 기타 사항
Preview features
앞으로 Uniform, Flexible(preview) mode 를 선택 지원할 예정이라고 한다. (multiple vm types) (2021년 3월 19일 기준) 하나의 Vm ScaleSets내에서 Window server / Linux 타입 이미지가 둘다 포함될 수 있다는 점.! 꽤나 좋은 옵션이 될 것 같다.
3. Azure에서 제공하는 VM ScaleSets API (python sdk)를 사용해 vm scale set list 불러오기
- Azure Compute Management Client Library for python 을 pypi를 이용해 python 환경에 설치한다.
2. API Request requirements 확인.
https://docs.microsoft.com/en-us/rest/api/compute/virtualmachinescalesets/listall
