배치 프로그램 튜닝 개요
배치(Batch) 프로그램
배치 프로그램이란, 일련의 작업들을 하나의 작업 단위로 묶어 연속적으로 일괄 처리하는 것을 말한다. 온라인 프로그램에서도 여러 작업을 묶어 처리하는 경우가 있으므로 이와 구분하려면 한 가지 특징을 더 추가해야 하는데, 사용자와의 상호작용 여부다. 배치 프로그램의 특징을 요약하면 다음과 같다.
배치 프로그램의 특징
- 사용자와의 상호작용 없이
- 대량의 데이터를 처리하는
- 일련의 작업들을 묶어
- 정기적으로 반복 수행하거나
- 정해진 규칙에 따라 자동으로 수행
배치 프로그램 구분
- 정기 배치 : 정해진 시점(주로 야간)에 실행. 가장 일반적인 형태.
- 이벤트성 배치 : 사전에 정의해 둔 조건이 충족되면 자동으로 실행
- On-Demand 배치 : 사용자의 명시적 요구가 있을 때마다 실행 (실시간. 보통 비동기 방식으로 수행)
배치 환경의 변화
과거에는 일(Daily)이나 월(Monthly) 배치 작업 위주였으며 야간에 생성된 데이터를 주간 업무시간에 활용했다. 또한, 온라인과 배치 프로그램의 구분이 비교적 명확했다. 하지만 현재는 시간(Hourly) 배치 작업의 비중이 증가하였으며 분(Minutely) 배치 작업이 일부 존재하고 On-Demand 배치를 제한적이나마 허용한다.
실시간에 가까운 정보 서비스를 제공하기 위해 온라인 시스템에서 곧바로 대용량 데이터를 가공하는 예도 있지만, 대개는 DW 시스템에 근실시간으로 전송해 준 데이터를 가공해서 서비스하는 형태이다. 배치 작업을 위한 전용 서버를 두기도 하며, RAC 환경에서는 여러 인스턴스 중 하나를 배치 전용 인스턴스로 지정하기도 한다,
DW 시스템 : 사용자의 의사결정을 지원하기 위해 기업이 축적한 많은 데이터를 사용자 관점에서 주제별로 통합하여 별도의 장소에 저장.
성능 개선 목표 설정
온라인 프로그램은 경우에 따라 전체 처리속도 최적화나 최초 응답속도 최적화를 목표로 선택하지만, 배치 프로그램은 항상 전체 처리속도 최적화를 목표로 설정해야 한다. 개별 서비스 또는 프로그램을 가장 빠른 속도로 최적화하더라도 전체 배치 프로그램 수행 시간을 단축시키지 못하면 무의미하다.
(병렬도(DOP, degree of parallelism)를 32로 지정해서 5분이 소요되는 프로그램을 병렬 처리 없이 10분이 소요되도록 하는 것이 오히려 나을 수 있다. 시스템 자원을 독점적으로 사용하도록 설정된 프로그램을 찾아 병렬도를 제한하고, 동시에 수행되는 프로그램 개수도 적절히 유지해야 한다.)
실제 개발 프로젝트에 가보면, 시스템 자원에 대한 사용 권한을 적절히 배분하지 않고 각 서브 개발 파트에서 개발한 배치 프로그램을 12시 정각에 동시에 수행하는 경우를 종종 볼 수 있다. 그럴 때 배치 윈도우를 적절히 조절하는 것만으로 배치 프로그램 수십 개를 튜닝한 것과 같은 효과를 내기도 한다.
같은 시간대에 수많은 프로그램이 집중적으로 수행되면 자원(CPU, Memory, Disk 등)과 Lock(Latch와 같은 내부 Lock까지 포함)에 대한 경합이 발생하기 때문이다. 그러면 프로세스가 실제 일한 시간보다 대기하는 시간이 더 많아지므로 총 수행시간이 늘어나는 것이다.
배치 프로그램 구현 패턴과 튜닝 방안
절차형으로 작성된 프로그램 : 애플리케이션 커서를 열고, 루프 내에서 또 다른 SQL이나 서브 프로시저를 호출하면서 같은 처리를 반복하는 형태
One SQL 위주 프로그램 : One SQL로 구성하거나, 집합적으로 정의된 여러 SQL을 단계적으로 실행
성능 측면에서는 One SQL 위주의 프로그램이 월등하다. 절차형으로 작성된 프로그램은 이러한 비효율 때문에 느릴 수밖에 없다.
- 반복적인 데이터베이스 Call 발생
- Random I/O 위주
- 동일 데이터를 중복 액세스
또한, 개별 SQL을 최적화하더라도 그것을 담고있는 프로그램 전체를 최적화하는데 한계를 보인다.
하지만 절차형으로 작성된 프로그램을 One SQL 위주의 프로그램으로 구현하기가 쉽지만은 않다. 개발자의 기술력이 부족한 이유도 있지만, 업무의 복잡성 때문에 불가능한 경우도 많다. 무엇보다, 섣불리 One SQL로 통합했다가 결과가 틀려지는 위험성을 간과하기 어렵다.
배치 프로그램 튜닝 요약
절차형으로 작성된 프로그램
- 병목을 일으키는 SQL을 찾아 I/O 튜닝 : 인덱스를 재구성하고 액세스 경로 최적화
- 프로그램 Parallel 활용 : 메인 SQL이 읽는 데이터 범위를 달리하여 프로그램을 동시에 여러 개 수행
- Array Processing 활용 : 한 번의 SQL 수행으로 다량의 로우를 동시에 insert/update/delete 가능
- One SQL 위주 프로그램으로 다시 구현
One SQL 위주 프로그램
- 병목을 일으키는 오퍼레이션을 찾아 I/O 튜닝
(Index Scan보다 Full Table Scan 방식으로, NL Join보다 Hash Join 방식으로 처리) - 임시 테이블 활용
- 파티션 활용
- 병렬처리 활용
병렬 처리 활용
병렬 처리란, SQL문이 수행해야 할 작업 범위를 여러 개의 작은 단위로 나누어 여러 프로세스(또는 쓰레드)가 동시에 처리하는 것을 말한다. 여러 프로세스가 동시에 작업하므로 대용량 데이터를 처리할 때 수행 속도를 극적으로 단축시킬 수 있다.
select /*+ full(o) parallel(o, 4) */ count(*) 주문건수, sum(주문수량), sum(주문금액) 주문금액
from 주문 o
where 주문일자 between '20100101' and '20101231';parallel 힌트를 사용할 때는 반드시 Full 힌트도 함께 사용하는 습관이 필요하다. 옵티마이저에 의해 인덱스 스캔이 선택되면 parallel 힌트가 무시되기 때문이다.
parallel(테이블, 병렬프로세스 개수) <- 병렬프로세스 개수를 지정해주지 않으면 시스템 디폴트 개수만큼 기동한다.)
select /*+ index_ffs(o, 주문_idx)) parallel_index(o, 주문_idx, 4) */ count(*) 주문건수, sum(주문수량), sum(주문금액) 주문금액
from 주문 o
where 주문일자 between '20100101' and '20101231';parallel_index 힌트를 사용할 때, 반드시 index 또는 index_ffs 힌트를 함께 사용하는 습관도 필요하다. 옵티마이저에 의해 Full Table Scan이 선택되면 parallel_index 힌트가 무시되기 때문이다.
Query Coordinator와 병렬 서버 프로세스
Query Coordinator(QC)는 병렬 SQL문을 발행한 세션을 말하며, 병렬 서버 프로세스는 실제 작업을 수행하는 개별 세션들을 말한다.
Query Coordinator의 역할
- 병렬 SQL이 시작되면 QC는 사용자가 지정한 병렬도(DOP, degree of parallelism)와 오퍼레이션 종류에 따라 하나 또는 두 개의 병렬 서버 집합을 할당한다. 우선 서버 풀(Parallel Execution Server Pool)로부터 필요한 만큼 서버 프로세스를 확보하고, 부족분은 새로 생성한다.
- QC는 각 병렬 서버에서 작업을 할당한다. 작업을 지시하고 일이 잘 진행되는지 관리감독하는 작업반장 역할이다. 병렬로 처리하도록 사용자가 지시하지 않은 테이블은 QC가 직접 처리한다.
- QC는 각 병렬 서버로부터의 산출물을 통합하는 작업을 수행한다.
- QC는 쿼리의 최종 결과집합을 사용자에게 전송하며, DML일 때는 갱신 건수를 집계해서 전송해준다.
병렬 처리에서 실제 QC 역할을 담당하는 프로세스는 SQL문을 발행한 사용자 세션 자신이다.
Intra-Operation Parallelism과 Inter-Operation Parallelism
select /*+ full(고객) parallel(고객 4) */
* from 고객
order by 고객명;이 병렬 쿼리를 수행할 때 2개 조로 나누고 역할을 분담해 서로 다른 작업을 동시에 진행한다. 이 때 QC는 관리를 담당하고 4명은 분배, 4명은 분배된 내용을 정렬하는 역할을 수행한다. (병렬도가 4이므로)
Intra-Operation Parallelism
서로 배타적인 범위를 독립적으로 동시에 처리하는 것이다. 첫 번째 서버 집합에 속한 4개의 프로세스가 범위를 나눠 고객 데이터를 읽는 작업과 두 번째 서버 집합 고객 데이터를 정렬하는 작업이 모두 여기에 속한다. 즉, 같은 조끼리는 서로 Data를 주고받을 일이 없다.
Inter-Operation Parallelism
같은 서버 집합끼리는 서로 데이터를 반대편 서버 집합에 분배하거나 정렬된 결과를 QC에게 전송하는 작업을 병렬로 동시에 진행하는 것이며 항상 프로세스 간 통신이 발생한다.
테이블 큐
Intra-Operation Parallelism은 한 병렬 서버 집합에 속한 여러 프로세스가 처리 범위를 달리하면서 병렬로 작업을 진행하는 것이므로 집합 내에서는 절대 프로세스 간 통신이 발생하지 않는다. 반면, Inter-Operation Paralelism은 프로세스 간 통신이 발생하고, 메시지 또는 데이터를 전송하기 위한 통신 채널이 필요하다.
쿼리 서버 집합간 또는 QC와 쿼리 서버 집합 간 데이터 전송을 위해 연결된 파이프 라인을 테이블 큐라고 한다.
select /*+ ordered use_hash(e) full(d) noparallel(d) full(e) parallel(e 2) pq_distribute(e broadcast none) */ *
from dept d, emp e
where d.deptno = e.deptno
order by e.ename;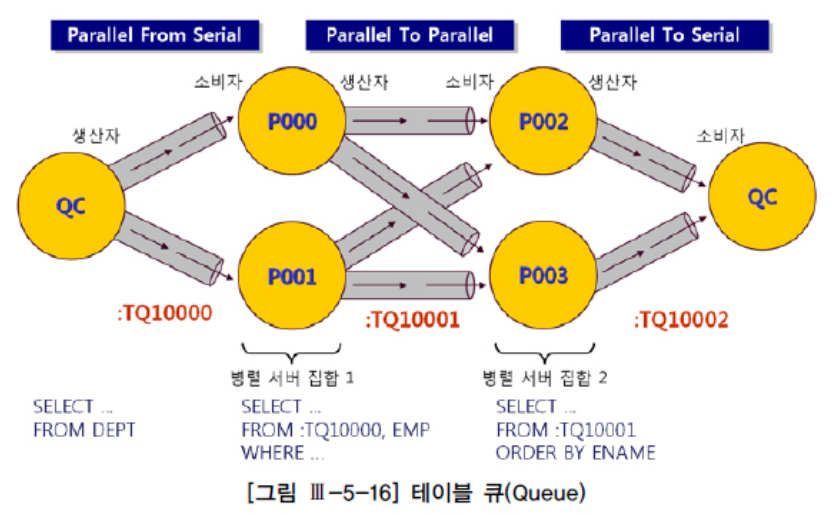
쿼리 서버 집합 간 Inter-Operation Parallelism이 발생할 때는 사용자가 지정한 병렬도의 배수만큼 서버 프로세스가 필요하다.
(P000, P001, P002, P003)
테이블 큐(:TQ10001)에는 병렬도의 제곱(2^2 = 4) 만큼 파이프 라인이 필요하다.
생산자 / 소비자 모델
테이블 큐에는 항상 생산자(Producer)와 소비자(Consumer)가 존재한다.
:TQ10000
QC가 생산자가 되고 서버 집합 1이 소비자가 된다.
:TQ10001
서버 집합 1이 생산자가 되고 서버 집합 2가 소비자가 된다.
:TQ10002
서버 집합 2가 생산자가 되고 QC가 소비자가 된다.
select 문장에서의 최종 소비자는 항상 QC일 것이며, Inter-Operation Parallelism이 나타날 때, 소비자 서버 집합은 from절에 테이블 큐를 참조하는 서브(Sub) SQL을 가지고 작업을 수행한다.
병렬 실행계획에서 생산자와 소비자 식별
Oracle 10g 이후부터는 생산자에 'PX SEND', 소비자에 'PX RECEIVE'가 표시되므로 테이블 큐를 통한 데이터 분배 과정을 좀 더 쉽게 확인할 수 있다.
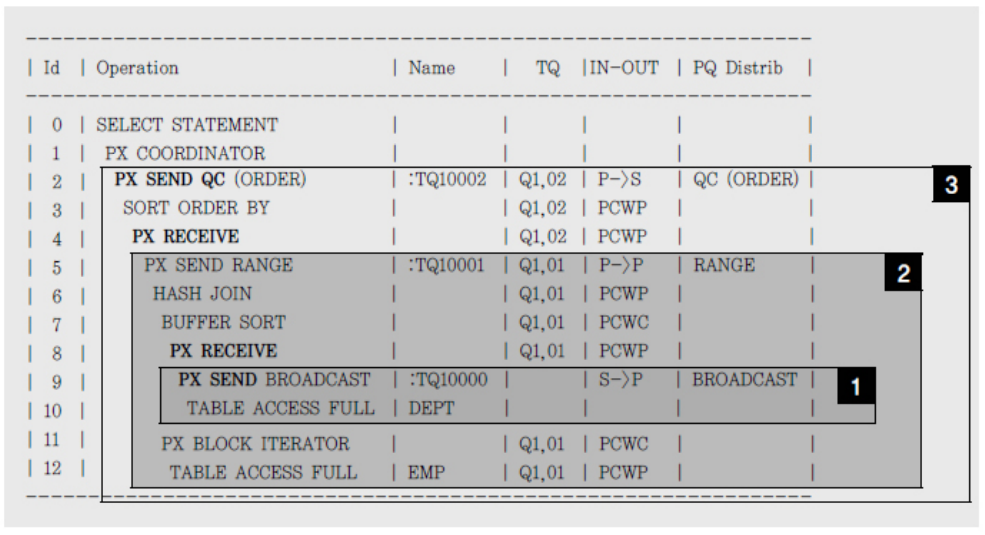
- QC가 dept 테이블을 읽어 첫 번째 서버 집합(Q1, 01)에게 전송한다.
- 첫 번째 서버 집합(Q1, 01)은 emp 테이블을 병렬로 읽으면서 앞서 QC에게서 받아 둔 dept 테이블과 조인한다. 조인에 성공한 레코드는 바로바로 두 번째 서버 집합(Q1, 02)에게 전송한다.
- 두 번째 서버 집합(Q1, 02)은 전송받은 레코드를 정렬하고 나서 QC에게 전송한다.
생산자로부터 소비자로 데이터 재분배가 일어날 때마다 'Name' 컬럼에 테이블 큐가 표시된다.
IN-OUT 오퍼레이션
-
SERIAL(blank)
Serial하게 실행 -
S -> P : PARALLEL_FROM_SERIAL
QC가 처리한 결과를 병렬 서버 프로세스에게 전달
병렬 오퍼레이션이 아니므로 Inter-Operation Parallelism에 속하지 않는다. -
P -> S : PARALLEL_TO_SERIAL
병렬 서버 프로세스가 처리한 결과를 QC에게 전달
QC에게 결과 데이터를 전송할 때 첫 번째 병렬 프로세스부터 마지막 병렬 프로세스까지 순서대로 진행할 때는 PQ Distrib 컬럼에 'QC(ORDER)가 표시된다. (그렇지 않은 경우 QC(RANDOM)이라고 표시된다.) -
P -> P : PARALLEL_TO_PARALLEL
두 개의 병렬 서버 프로세스 집합이 처리. 지정한 병렬도의 2배 만큼의 병렬 프로세스 생성한다. 데이터를 정렬(ORDER BY) 또는 그룹핑(GROUP BY)하거나 조인을 위해 동적으로 파티셔닝할 때 사용되며, 병렬 프로세스 간 통신이 발생하므로 Inter-Operation Parallelism에 속한다. -
PCWP : PARALLEL_COMBINED_WITH_PARENT
병렬 서버 프로세스 집합이 현재 스텝과 그 부모 스텝을 모두 처리하며 자식 스텝의 처리 결과를 부모 스텝에서 사용한다.
병렬 오퍼레이션이지만 한 서버 집합 내에는 프로세스 간 통신이 발생하지 않으므로 Intra_Operation parallelism에 속한다. -
PCWC : PARALLEL_COMBINED_WITH_CHILD
병렬 서버 프로세스 집합이 현재 스텝과 그 자식 스텝을 모두 처리하며 자식 스텝의 처리 결과를 받아 현재 스텝의 입력값으로 사용한다.
병렬 오퍼레이션이지만 한 서버 집합 내에는 프로세스 간 통신이 발생하지 않으므로 Intra_Operation parallelism에 속한다.
(참고로 표기할 때 PARALLEL을 기준으로 쓰는 듯)
S -> P, P -> S, P -> P는 프로세스 간 통신이 발생한다.
PCWP와 PCWC는 프로세스 간 통신이 발생하지 않으며, 각 병렬 서버가 독립적으로 여러 스텝을 처리할 때 나타난다. 하위 스텝의 출력 값이 상위 스텝의 입력 값으로 사용된다.
P -> P, P -> S, PCWP, PCWC는 병렬 오퍼레이션인 반면 S -> P는 직렬(Serial) 오퍼레이션이다.
데이터 재분배
병렬 서버 프로세스 간에 데이터를 재분배하는 방식. PX SEND 뒤에 나타난다.
RANGE
- order by 또는 sort group by를 병렬로 처리할 때 사용된다. 정렬 작업을 맡은 두 번째 서버 집합의 프로세스마다 처리 범위를 지정하고 나서, 데이터를 읽는 첫 번째 서버 집합이 두 번째 서버 집합의 정해진 프로세스에게 '정렬 키 값에 따라' 분배하는 방식이다.
QC는 각 서버 프로세스에게 작업 범위를 할당하고 정렬 작업에는 직접 참여하지 않으며, 정렬이 완료되고 나면 순서대로 결과를 받아서 사용자에게 전송하는 역할만 한다.
HASH
- 조인이나 hash group by를 병렬로 처리할 때 사용된다. 조인 키나 group by 키 값을 해시 함수에 적용하고 리턴된 값에 따라 데이터를 분배하는 방식이며, P->P 뿐만 아니라 S->P 방식으로 이루어질 수도 있다.
BROADCAST
- QC 또는 첫 번째 서버 집합에 속한 프로세스들이 각각 읽은 데이터를 두 번째 서버 집합에 속한 "모든" 병렬 프로세스에게 전송하는 방식이다. 병렬 조인에서 크기가 매우 작은 테이블이 있을 때 사용되며, P->P 뿐만 아니라 S->P 방식으로도 이루어진다.
(작은 테이블은 병렬로 읽지 않을 때가 많으므로 오히려 S->P가 일반적이라고 볼 수도 있다.)
KEY
- 특정 컬럼들을 기준으로 테이블 또는 인덱스를 파티셔닝할 때 사용하는 분배 방식이다. 실행 계획에는 'PARTITION (KEY), PART (KEY)로 표시된다.
1) Partial Partition-Wise 조인(이미 파티션된 테이블과 조인하기 위해 다른 한쪽 테이블을 동적으로 파티셔닝하고 나서 각 Partition-Pari에 대해 독립적으로 병렬조인을 수행하는 것)
2) CTAS 문장으로 파티션 테이블을 만들 때
3) 병렬로 글로벌 파티션 인덱스를 만들 때
ROUND-ROBIN
- 파티션 키, 정렬 키, 해시 함수 등에 의존하지 않고 반대편 병렬 서버에 무작위로 데이터를 분배할 때 사용된다. 무작위라고는 하지만 골고루 분배되도록 round-robin 방식을 사용한다.
Granule
데이터를 병렬로 처리할 때 일의 최소 단위를 'Granule'이라고 하며, 병렬 서버는 한 번에 하나의 Granule씩만 처리한다. Granule 개수와 크기는 병렬도와 관련 있으며, 이는 병렬 서버 사이에 일을 고르게 분배하는 데에 큰 영향을 미친다.
- 블록 기반 Granule(=블록 범위 Granule)
블록 기반 Granule은, 파티션 테이블인지 여부와 상관없이 대부분의 병렬 오퍼레이션에 적용되는 기본 작업 단위이다. 실행 계획상에 'PX BLOCK ITERATOR'라고 표시되며, 이 오퍼레이션이 나타날 때면, QC는 테이블로부터 읽어야 할 일정 범위의 블록을 Granule로서 각 병렬 서버에게 할당한다. 그리고 ITERATOR가 의미하는 바와 같이 병렬 서버가 한 Granule에 대한 일을 끝마치면 이어서 다른 Granule을 할당한다.
Granule 크기와 총 개수는 실행 시점에 오브젝트 사이즈와 병렬도에 따라 QC가 동적으로 결정한다. 모든 병렬 서버에게 일을 골고루 분배하는 것을 목표로 하며, 아주 작은 테이블이 아니라면 Granule 개수는 사용자가 지정한 병렬도보다 많을 것이다. 또한, Granule을 계산할 때는 각 병렬 서버에게 가능한 한 서로 다른 데이터 파일에 놓인 블록들을 할당함으로써 경합을 회피하려고 노력한다.
- 파티션 기반 Granule(=파티션 Granule)
파티션 기반 Granule이 사용될 때, 각 병렬 서버 프로세스는 할당받은 테이블(또는 인덱스) 파티션 전체를 처리할 책임을 진다. 이 방식에서는 한 파티션을 두 개의 프로세스가 함께 처리할 수 없으므로 병렬도는 당연히 파티션 개수 이하로만 지정할 수 있다.
PX PARTITION RANGE ALL : 파티션 전체를 읽어야 할 때
PX PARTITION RANGE ITERATOR : 일부 파티션만 읽을 때
병렬도가 파티션 개수보다 적을 때 병렬 서버가 한 파티션 처리를 끝마치면 이어서 다른 파티션을 할당받는 식으로 진행한다.
1) Partition-Wise 조인 시
2) 파티션 인덱스를 병렬로 스캔할 때
3) 파티션 인덱스를 병렬로 갱신할 때
4) 9iR1 이전에서의 병렬 DML
5) 파티션 테이블 또는 파티션 인덱스를 병렬로 생성할 때
파티션 기반일 때는 Granule 개수가 테이블과 인덱스의 파티션 구조에 의해 정적으로 결정되므로 블록 기반 Granule처럼 유연하지 못하다. 또한, 시스템 리소스를 최대한 사용함으로써 병렬 효과를 극대화하려 할 때, 파티션 개수보다 많은 병렬도를 지정할 수 없다.
Granule은 병렬도보다 파티션 개수가 상당히 많을 때 유용하다.
병렬 처리 과정에서 발생하는 대기 이벤트
-
PX Deq: Execute Reply (클래스 : Idle)
QC가 각 병렬 서버에게 작업을 배분하고서 작업이 완료되기를 기다리는 상태 -
SQL*Net message from client
클라이언트로부터 추가 Fetch Call이 오기를 기다리는 상태. 가장 먼저 작업을 끝낸 병렬 서버로부터 데이터를 받아 클라이언트에게 전송하기 시작할 때 나타난다. -
PX Deq: Execute Msg (클래스 : Idle)
병렬 서버가 자신의 임무를 완수하고서 다른 병렬 서버가 일을 마치기를 기다리는 상태. QC 또는 소비자 병렬 서버에게 데이터 전송을 완료했을 때 나타난다. -
PX Deq: Table Q Normal (클래스 : Idle)
메시지 수신 대기. 메시지 큐에 데이터가 쌓이기를 기다리는 상태. -
PX Deq Credit: send blked (클래스 : Other)
메시지 송신 대기. QC 또는 소비자 병렬 서버에게 전송할 데이터가 있는데 블로킹이 된 상태. -
PX Deq Credit : need buffer (클래스 : Idle)
데이터를 전송하기 전에 상대편 병렬 서버 또는 QC로부터 credit 비트를 얻으려고 대기하는 상태.
(Oracle은 테이블 큐를 보호할 목적으로 credit 비트를 사용한다. 데이터를 전송하려면 먼저 상대편 서버 프로세스로부터 credit 비트를 받아야 한다.)
대기 이벤트 해소
병렬처리와 관련된 대기 이벤트가 대부분 Idle로 분류되어 있는데, 이벤트를 회피하기 위해 사용자가 할 수 있는 일들이 거의 없기 때문이다.
Idle 이벤트가 아닌 경우에는 종종 튜닝이 가능할 수 있다.
PX Deq Credit: send blked 이벤트가 많이 발생하는 이유?
- 클라이언트가 천천히 스크롤하면서 데이터를 관찰한다.
-> CPU 리소스를 낭비하는 것이므로 가급적 병렬 쿼리를 사용하지 않는 편이 낫다.- Fetch Call과 Fetch Call 사이에 많은 애플리케이션 로직을 수행한다.
-> 애플리케이션 로직을 튜닝할 수 있는지 검토한다.
병렬 Order By와 Group By
P -> P 데이터 재분배는 주로 병렬 order by, 병렬 group by, 병렬 조인을 포함한 SQL에서 나타난다.
병렬 Group By
쿼리에 Order By를 추가하느냐 그렇지 않느냐에 따라 실행 계획이 달라진다. Order By를 추가하면 Sort Group By가 적용되고 추가하지 않으면 Hash Group By가 추가된다.
이 둘의 차이점은 데이터 분배 방식에 있다. Group By 키 정렬 순서에 따라 분배하느냐 해시 함수 결과 값에 따라 분배하느냐의 차이다. Group By의 결과를 QC에 전송할 때도, Sort Group By는 값 순서대로 진행하지만 Hash Group By는 먼저 처리가 끝난 순서대로 진행한다.
병렬 Group By도 두 집합으로 나눠 한쪽은 명함을 읽어서 분배하고 다른 한쪽은 그것을 받아 집계하도록 해야 병렬 처리 효과를 극대화할 수 있다.
(기존 Sort Order By와 방식은 비슷하다. 두 번째 프로세스 집합이 정렬하는 일 대신 집계하는 는 일을 한다고 생각하면 편할 것 같다.)
## 병렬 조인 병렬 조인 메커니즘을 이해하는 핵심 원리는, 병렬 프로세스들이 서로 독립적으로 조인을 수행할 수 있도록 데이터를 분배하는 데에 있다. 분배작업이 완료되고 나면 프로세스 간에 서로 방해받지 않고 각자 할당받은 범위 내에서 조인을 완료한다.
파티션 방식
1. Partition-Pair끼리 조인 수행
1) 둘 다 같은 기준으로 파티셔닝된 경우 - Full Partition Wise 조인
조인에 참여하는 두 테이블이 조인 컬럼에 대해 같은 기준으로 파티셔닝 돼있다면 병렬 조인은 매우 간단하다.
파티션 방식과 조인 방식은 어떤 것이든 상관 없으며 여기서는 하나의 서버집합만 필요하다.
Operation : PX PARTITION RANGE ALL, PQ PARTITION RANGE ITERATOR
2) 둘 중 하나만 파티셔닝된 경우 - Partial Partition Wise 조인
둘 중 한 테이블만 조인 컬럼에 대해 파티셔닝된 경우나 둘 다 파티셔닝 되었지만 파티션 기준이 서로 다른 경우, 다른 한쪽 테이블을 같은 기준으로 동적으로 파티셔닝 하고나서 각 Partition-Pair를 독립적으로 병렬 조인하는 것이다. 중요하 것은, 데이터를 동적으로 파티셔닝하기 위해서는 데이터 재분배가 선행되어야 한다는 사실이다. 즉, Inter-operation parallelism을 위해 두 개의 서버 집합이 필요해진다.
Operation : PX SEND PARTITION(KEY)
PQ Distrib: PART(KEY)
3) 둘 다 파티셔닝되지 않은 경우 - 동적 파티셔닝
-
양쪽 테이블을 동적으로 파티셔닝하고서 Full Partition Wise 조인
첫 번째 서버 집합이 두 테이블을 하나씩 읽고 두 번째 서버 집합에 전송한다.
두 번째 서버 집합은 받은 두 테이블 모두 파티셔닝한 후 각 Partition-Pair에 대해 독립적으로 병렬 조인을 수행한다.
(파티셔닝 시 가능하다면 메모리 내에서 파티셔닝하겠지만 공간이 부족할 때는 Temp 테이블 스페이스를 활용할 것이다.)
이 방식은 조인을 본격적으로 수행하기 전 사전 정지 작업 단계에서 메모리 자원과 Temp 테이블 스페이스 공간을 많이 사용해야 하며 양쪽 모두 파티셔닝 해야하므로 양쪽 테이블 모두에 대한 전체범위처리가 불가피하다. 또한, 조인 컬럼의 데이터 분포가 균일하지 않을 때는 프로세스 간 일량 차이 때문에 병렬 처리가 크게 반감될 수 있다. 따라서 이 방식은...
어느 한 쪽도 조인 컬럼 기준으로 파티셔닝되지 않은 상황에서 두 테이블 모두 대용량 테이블이고 조인 컬럼의 데이터 분포가 균일할 때 유리하다.PQ Distrib : HASH
-
한쪽 테이블을 Broadcast 하고 나서 조인
4) 둘 다 파티셔닝되지 않은 경우 - Broadcast 방식
두 테이블 중 작은 쪽을 반대편 서버 집함의 "모든" 프로세스에 Broadcast하고 나서 조인을 수행하는 방식이다. 이 방식은 동적 파티셔닝이 불필요하다.
PX SEND BROADCAST
BROADCAST양쪽 테이블 모두 파티션되지 않았을 때는 1차적으로 Broadcast방식이 고려되어야 한다. 양쪽 테이블을 동적으로 파티셔닝하는 방식은 메모리 자원과 Temp 테이블스페이스 공간을 많이 사용하는 반면 이 방식은 리소스 사용량이 매우 적기 때문이다.
하지만 Broadcast되는 테이블이 아주 작을 때만 적용된다. 만약 Broadcast되는 테이블이 중대형 이상일 때는 과도한 프로세스 간 통신 때문에 성능이 매우 느려질 수 있다. 뿐만 아니라 두 번째 서버 집합이 메모리 내에서 감당하기 어려울 정도로 큰 테이블을 Broadcast한다면 Temp 테이블스페이스 공간을 사용하게 되면서 그 성능은 심각하게 저하될 것이다.
- Broadcast는 작은 테이블임이 전제되어야 하므로 Serial 스캔으로 처리할 때도 많다. 따라서 오히려 S -> P 형태가 일반적이고, 이는 두 테이블 중 한쪽 테이블만 병렬로 처리함을 뜻한다.
- Broadcast가 이루어지고 나서의 조인 방식은 어떤 것이든 선택 가능하다.
- Broadcast되는 작은 쪽 테이블은 전체범위처리가 불가피하지만 큰 테이블은 부분범위처리가 가능하다.
pq_distribute 힌트 활용
조인되는 양쪽 테이블의 파티션 구성, 데이터 크기 등에 따라 병렬 조인을 수행하는 옵티마이저의 선택이 달라질 수 있다. 대개 옵티마이저의 선택이 최적이라고 할 수 있지만 가끔 그렇지 못한 경우가 있는데 그럴 때 pq_distribute 힌트를 사용함으로써 옵티마이저의 선택을 무시하고 사용자가 직접 조인을 위한 데이터 분배 방식을 결정할 수 있다.
- 옵티마이저가 파티션된 테이블을 적절히 활용하지 못하고 동적 재분할을 시도할 때
- 기존 파티션 키를 무시하고 다른 키 값으로 동적 재분할을 시도할 때
- 통계정보가 부정확하거나 통계정보를 제공하기 어려운 상황(-> 옵티마이저가 잘못된 판단을 하기 쉬운 상황)에서 실행계획을 고정시키고자 할 때
- 기타 여러 가지 이유로 데이터 분배 방식을 변경하고자 할 때
병렬 방식으로 조인을 수행하기 위해서는 프로세스들이 서로 "독립적으로" 작업할 수 있도록 사전 준비작업이 필요하다. 먼저 데이터를 적절히 배분하는 작업이 선행되어야 하는 것이다. 그 중에서도 병렬 조인을 위해서는 '분배 & 조인(Distribute & Join) 원리'가 작동함을 이해하는 것이 매우 중요하다. 이때, pq_distribute 힌트는 조인에 앞서 데이터를 분배(distribute) 과정에만 관여하는 힌트임을 반드시 기억할 필요가 있다. 즉, 조인 방식과는 무관하다.
pq_distribute 사용법
/*+ PQ_DISTRIBUTE(table, outer_distribution, inner_distribution) */
table : inner 테이블명 또는 alias
outer_distribution : outer 테이블의 distribution 방식
inner_distribution : inner 테이블의 distribution 방식
첫 번째 인자인 table에는 ordered 또는 leading 힌트에 의해 먼저 처리되는 outer 테이블을 기준으로 그 집합과 조인되는 inner 테이블을 지정하면 된다. 조인 순서를 먼저 고정시키는 것이 중요하므로 ordered 또는 leading 힌트를 같이 사용하는 것이 올바른 사용법이다.
- pq_distribute(inner, none, none)
Full-Partition Wise Join으로 유도할 때 사용하며 양쪽 테이블 모두 조인 컬럼에 대해 같은 기준으로 파티셔닝 되어있을 때만 작동한다.
Partition Wise Join
Partition Wise Join은 조인에 참여하는 두 테이블을 조인 컬럼에 대해 같은 기준으로 파티셔닝 하고서 각 파티션 짝끼리 독립적으로 조인을 수행하는 것을 말한다. 파티션 짝을 구성하고 나면 병렬 프로세스끼리 서로 데이터를 주고 받으며 통신할 필요가 전혀 없으므로 병렬 조인 성능을 크게 향상시킬 수 있다.
Full Partition Wise Join : 양쪽 테이블이 사전에 미리 파티셔닝 되어있어 곧바로 Partition Wise Join 하는 경우
Partial Partition Wise Join : 한쪽만 파티셔닝 돼 있어 나머지 한쪽을 실행시점에 동적으로 파티셔닝하고서 Partition Wise Join 하는 경우
-
pq_distribute(inner, partition, none)
Partial-Partition Wise Join으로 유도할 때 사용하며, outer 테이블을 inner 테이블 파티션 기준에 따라 파티셔닝하라는 뜻이다. inner 테이블이 조인 키 컬럼에 대해 파티셔닝 되어있을 때만 작동한다. -
pq_distribute(inner, none, partition)
Partial-Partition Wise Join으로 유도할 때 사용하며, inner 테이블을 outer 테이블 파티션 기준에 따라 파티셔닝하라는 뜻이다. outer 테이블이 조인 키 컬럼에 대해 파티셔닝 되어있을 때만 작동한다. -
pq_distribute(inner, hash, hash)
조인 키 컬럼을 해시 함수에 적용하고 거기서 반환된 값을 기준으로 양쪽 테이블을 동적으로 파티셔닝하라는 뜻이다. 조인되는 테이블을 둘 다 파티셔닝해서 파티션 짝을 구성하고서 Partition Wise Join을 수행한다. -
pq_distribute(inner, broadcast, none)
outer 테이블을 Broadcast하라는 뜻이다. -
pq_distribute(inner, none, broadcast)
inner 테이블을 Broadcast하라는 뜻이다.
병렬 처리에 관한 기타 상식
Direct Path Read
Oracle은 병렬 방식으로 Full Scan 할 때는 버퍼 캐시를 거치지 않고 곧바로 PGA 영역으로 읽어들이는 Direct Path Read 방식을 사용한다. 버퍼 캐시 히트율이 낮은 대용량 데이터를 건건이 버퍼 캐시를 거쳐서 읽는다면 오히려 성능이 나빠지기 때문이다.
자주 사용되고 버퍼 캐시에 충분히 적재될 만큼의 중소형 테이블을 병렬 쿼리로 읽을 때는 오히려 성능이 나빠지는 경우가 있다. 버퍼 경합이 없는 한 디스크 I/O가 메모리 I/O보다 빠를 수 없기 때문이다. 게다가 Direct Path Read를 하려면 메모리와 디스크 간 동기화를 위한 체크포인트를 먼저 수행해야 한다. 따라서 병렬 쿼리의 Direct Path Read 효과를 극대화하려면 그만큼 테이블이 아주 커야한다.
병렬 DML
병렬 처리가 가능해지려면 쿼리, DML, DDL을 수행하기 전에 해당 명령을 먼저 수행해주어야 한다.
alter session enable parallel query;
alter session enable parallel dml;
alter session enable parallel ddl;parallel query와 parallel ddl은 기본적으로 활성화돼 있으므로 괜찮지만 parallel dml은 사용자가 명시적으로 활성화해주어야 한다. 활성화 여부에 따라 갱신 작업을 병렬 프로세스 서버가 할지 QC가 할지 달라진다.
병렬 DML을 수행할 때 Exclusive 모드 테이블 Lock이 걸리므로 주의해야 한다. 성능은 매우 빨라지겠지만 해당 테이블에 다른 트랜잭션이 DML을 수행하지 못하게 되므로 트랜잭션이 빈번한 주간에 이 옵션을 사용하는 것은 절대 금물이다.
병렬 인덱스 스캔
Index Fast Full Scan이 아닌 한 인덱스는 기본적으로 병렬로 스캔할 수 없다. 파티션된 인덱스일 때는 병렬 스캔이 가능하며, 파티션 기반 Granule이므로 당연히 병렬도는 파티션 개수 이하로만 지정할 수 있다.
(두 개 이상의 병렬 서버가 하나의 파티션을 맡을 수 없기 때문이다.)
병렬 NL 조인
병렬 조인은 항상 Table Full Scan을 이용한 해시 조인 또는 소트 머지 조인으로 처리된다고 생각하기 쉽다. 하지만 인덱스 스캔을 기반으로 한 병렬 NL 조인도 가능하다.
병렬 NL 조인의 효용성
- Outer 테이블과 Inner 테이블이 둘 다 초대용량 테이블이다.
- Outer 테이블에 사용된 특정 조건의 선택도가 매우 낮은데 그 컬럼에 대한 인덱스가 없다.
- Inner쪽 조인 컬럼에는 인덱스가 있다.
- 수행 빈도가 낮다. (수행 빈도가 높다면 Outer쪽에도 인덱스를 만드는 편이 낫다.)
병렬 쿼리와 스칼라 서브쿼리
병렬 쿼리는 대부분 Full Table Scan으로 처리되는데, 도중에 인덱스를 경유한 Random 액세스 위주의 스칼라 서브쿼리까지 수행해야 한다면 수행 속도를 크게 저하시킨다. 따라서 병렬 쿼리에서는 스칼라 서브쿼리를 가급적 일반 조인문장으로 변환하고서 Full Scan + Parallel 방식으로 처리되도록 하는 것이 매우 중요하다.
병렬 쿼리와 ROWNUM
SQL에 rownum을 포함하면 쿼리문을 병렬로 실행하는 데에 제약을 받게 되므로 주의해야 한다.
select /\*+ parallel(t) */ no, no2, rownum
from t
order by no2;보통은 병렬 서버가 자신이 맡은 부분에 대해서 정렬 후 QC에게 전달하면 QC가 포개기만 하면 끝나는 식으로 작동한다. 하지만, rownum을 사용하게 된다면 rownum 결과치로 정렬하는 것이 아님에도 불구하고 sort order by를 QC가 담당하게 된다.
병렬 처리 시 주의사항
병렬 쿼리를 과도하게 사용하면 시스템을 마비시킬 수도 있으므로 적절한 사용 기준이 필요하다.
- 동시 사용자 수가 적은 애플리케이션 환경(야간 배치 프로그램, DW, OLAP 등)에서 직렬로 처리할 때보다 성능 개선 효과가 확실할 때
(-> 이 기준에 따르면 작은 테이블은 병렬 처리 대상에서 제외됨) - OLTP성 시스템 환경이더라도 작업을 빨리 완료함으로써 직렬로 처리할 때보다 오히려 전체적인 시스템 리소스(CPU, Memory) 사용률을 감소시킬 수 있을 때
(-> 수행 빈도가 높지 않음을 전제로)
야간 배치 프로그램에는 병렬 처리를 자주 사용하는데, 야간 배치 프로그램은 전체 목표 시간을 달성하는 것을 목표로 해야지 개별 프로그램의 수행 속도를 단축하려고 필요 이상의 병렬도를 지정해서는 안된다.
여러 팀에서 작성한 배치 프로그램이 동시에 수행되는 상황에서 특정 소수 배치 작업이 과도한 병렬 처리를 시도한다면 CPU, 메모리, 디스크 등 자원에 대한 경합 때문에 오히려 전체 배치 수행이 늘어날 수 있다.
결론적으로, 성능 개선 효과가 확실한 최소한의 병렬도를 지정하려는 노력이 필요하다.
하지만 데이터 이행(Migration)의 경우 성능개선 효과가 확실한 최소한의 병렬도를 지정하려는 노력이 필요한데, 이때는 모든 애플리케이션을 중지시키고 이행 프로그램이 시스템을 독점적으로 사용하기 때문에 모든 리소스를 활용해 이행 시간을 최대한 단축하는 것을 목표로 삼아야 한다.
병렬 DML 수행 시 Exclusive 모드 테이블 Lock이 걸리므로 트랜잭션이 활발한 주간에 사용해서는 안된다.
그 외에 주의할 점
- 병렬도를 지정하지 앟으면 cpu_count * parallel_threads_per_cpu만큼의 병렬 프로세스가 할당된다. adaptive multiuser 기능을 사용하려는 경우가 아니라면 반드시 병렬도를 지정하는 것이 좋다.
- 실행계획에 P -> P가 나타날 때면 지정한 병렬도의 2배수만큼 병렬 병렬 프로세스가 필요하다.
- 쿼리 블록마다 병렬도를 다르게 지정한 경우, 여러 가지 우선 순위와 규칙에 따라 최종 병렬도가 결정된다. 하지만 이런 규칙들을 외우려는 노력보다는 쿼리 작성 시 병렬도를 모두 같게 지정하는 것이 바람직하다.
- parallel 힌트를 사용할 때는 반드시 Full 힌트도 함께 사용하는 습관이 필요하다. 옵티마이저에 의해 인덱스 스캔이 선택될 경우 parallel 힌트가 무시되기 때문이다.
- parallel_index 힌트를 사용할 때는 반드시 index 또는 index_ffs 힌트를 함께 사용하는 습관이 필요하다. 옵티마이저에 의해 Full Table Scan이 선택될 경우 parallel_index 힌트가 무시되기 때문이다.
- 병렬 DML 수행 시 Exclusive 모드 테이블 Lock이 걸리므로 업무 트랜잭션이 발생하는 주간에는 삼가야 한다.
- 테이블이나 인덱스를 빠르게 생성하려고 parallel 옵션을 사용했다면 작업을 완료하자마자 noparallel로 돌려 놓아야 한다.
- 부분범위처리 방식으로 조회하면서 병렬 쿼리를 사용할 때는 필요한 만큼 데이터를 Fetch 하고나서 곧바로 커서를 닫아주어야 한다.
(select * from dual같은 문장 수행하기)
