3주차부터는 파이썬과 웹 기초를 마무리하고 데이터 수집을 위한 웹 크롤링에 대해 학습했다.
1. 사전 학습
가. 용어 정리
들어가기에 앞서,
아직 익숙하지 않은 용어들에 대해 먼저 살펴보면
웹 크롤러 (Web crawler)
" A Web crawler, sometimes called a spider or spiderbot and often shortened to crawler, is an Internet bot that systematically browses the World Wide Web and that is typically operated by search engines for the purpose of Web indexing (web spidering)." (출처: 위키피디아 Wikipedia)
크롤러는 웹 인덱싱(웹상의 데이터를 찾아보기 쉽게 일정한 순서에 따라 목록으로 나열하는 것)을 위해 WWW를 체계적으로 탐색하는 Internet Bot(특정 작업을 반복 수행하는 프로그램)이며 크롤링은 바로 그 크롤러가 하는 행위를 나타낸다.
파싱(Parsing):
" Parsing, syntax analysis, or syntactic analysis is the process of analyzing a string of symbols, either in natural language, computer languages or data structures, conforming to the rules of a formal grammar. The term parsing comes from Latin pars (orationis), meaning part (of speech)." (출처: 위키피디아 Wikipedia)
언어학에서는 '구문 분석'이라고도 하는 파싱은 (Computer Science에서) 웹 상의 자연어, 컴퓨터 언어 등의 일련의 문자열을 의미있는 토큰token(어휘 분석의 단위)으로 분해하고 그것들로 이루어진 Parse tree를 만드는 과정이다.
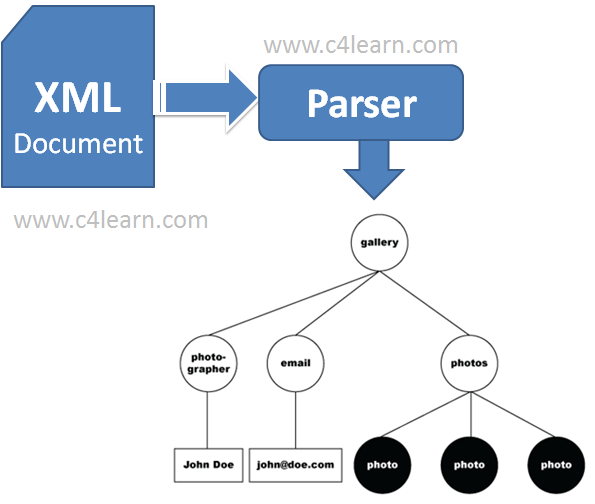
웹 스크래핑(Web scraping):
" Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites." (출처: 위키피디아 Wikipedia)
웹 스크래핑은 다양한 웹사이트들로부터 데이터를 추출하는 기술을 의미한다.
다시 말해 이들은 가공되지 않은 데이터(ex. html, xml, json, etc..)에서 원하는 정보를 추출하는 작업이며,
이를 통해 우리는 데이터 분석에 필요한 자료들을 확보할 수 있다.
파이썬에서 데이터를 파싱하는데 활용 가능한 모듈에는 BeautifulSoup, Selenium 등이 있다.
나. BeautifulSoup

" 이걸 다 외워서 무슨 소용이야! " 가짜 거북이가 또 끼어들며 말했어요. " 추가 설명 없인 대체 무슨 소린지 하나도 모르겠구나. 내 생전 이렇게 헷갈리는 시는 또 처음이야. " . 가짜 거북이는 깊은 한 숨을 몰아쉬더니 이따금씩 흐느낌을 삼키는 목소리로 다음과 같은 노래를 부르기 시작했어요." 아름다운 수프, 풍만한 녹색,
그릇에서 기다리거라!
누가 이 맛있는 것에 숙이지 않으리?
저녁 수프, 아름다운 수프!
아--르음다운 수---프!
저어녀---엌 수---프!
아름다운, 아름다운 수프
BeautifulSoup이란 방정맞은 이름의 유래는 루이스 캐럴의 소설 『이상한 나라의 앨리스』에 등장하는 모조 거북이가 부른 동명의 시에서 착안한 것이라고 한다.
tag soup이란 문법, 구조적으로 잘못된 HTML 웹 문서를 일컫는 용어인데
HTML 문서는 오류에 유연하게 대응하도록 설계되어 있기에 HTML과 텍스트가 마구잡이로 뒤섞이고 닫는 태그도 제대로 지켜지지 않는 등 웹 개발자들의 엄격하게 규칙을 따르지 않는 경우가 많았다고 한다.
Beautifulsoup는 이런 더러운 구조를 가진 tag soup를 아름답게 변환시켜준다는 의미에서 지은 이름이라고 함.
이상한 나라에서 왔으니 BeautifulSoup도 이상한 걸 이해할 수 있다고 . .
2. BeautifulSoup
뷰티풀수프 BeautifulSoup는 HTML이나 XML 문서들의 구문을 분석하기 위한,
즉 마크업 Markup 언어로 작성된 문서를 정돈된 파스트리 ParseTree 로 변환하여 반환해주는 파이썬 라이브러리이다.
가. 패키지 설치
BeautifulSoup 모듈은 파이썬을 설치할때 함께 설치되는 표준 라이브러리가 아니므로 pip 등을 사용하여 설치해야한다.
다만 Anaconda Jupyter Notebook이나 Google Corab 등의 Tool을 사용하는 경우에는
이미 설치가 되어있을 확률이 높으므로 별도의 설치과정없이 import해서 그냥 사용하면 된다.
전체적인 과정은 URL 요청 - 페이지 파싱 - ㄷ - 순으로 진행된다.
나. URL 요청
우선 HTML 문서를 핸들링하기 위해선 어떤 페이지를 탐색할 것인지를 설정하는 URL 요청이 필요하다.
1) urllib
urllib는 파이썬에서 웹과 관련된 데이터를 쉽게 다룰 수 있도록,
URL 처리에 관련된 모듈을 모아놓은 패키지이며 파이썬을 설치할 때 함께 설치되는 표준 라이브러리다.
가)
패키지는 request, error, parse, robotparser 모듈로 구성되어 있다.
urllib.request는 url을 열고 읽기 위한,
urllib.error는 request에 의해 발생하는 예외를 포함하는,
urllib.parse는 url의 구문 분석을 위한,
urllib.robotparser는 robots.txt 파일을 구문 분석하기 위한 모듈이다.
나)
urllib.request의 urlopen() 함수에 url를 매개변수로 입력하면 해당 웹페이지를 추출할 수 있다.
urlopen() 함수는 HTTPResponse 자료형의 파일 객체를 반환한다.
import urllib.request
url = 'https://velog.io/@jd0419'
res = urllib.request.urlopen(url)
res, type(res)
# Output: (<http.client.HTTPResponse at 0x1cba7c94b20>, http.client.HTTPResponse)다)
해당 객체에 read() 메서드를 실행시키면 결과를 stdout으로 확인할 수 있다.
하지만 urllib.request는 데이터를 바이너리 형태로 인코딩해서 전송하기 때문에
decode()를 해주지않으면 인코딩된 페이지의 결과가 보이기 때문에 읽기가 어렵다.
decode()없이 출력
import urllib.request
url = 'https://velog.io/@jd0419'
res = urllib.request.urlopen(url)
res.read()
# Output:
# b'<!doctype html>\n<html><head><title data-rh="true">jd0419 (Kim JeongDo) - velog...
# ...<meta data-rh="true" name="description" content="\xec\xb0\x90\xeb\x94\xb0"/>...
# ...</head><body>...</body></html>'
type(res.read())
# Output: bytesdecode()와 함께 출력
import urllib.request
url = 'https://velog.io/@jd0419'
res = urllib.request.urlopen(url)
res.read().decode('UTF-8')
# Output:
# '<!doctype html>\n<html><head><title data-rh="true">jd0419 (Kim JeongDo) - velog...
# ...<meta data-rh="true" name="description" content="찐따"/>...
# ...</head><body>...</body></html>'
type(res.read().decode('UTF-8'))
# Output: str라)
Request() 함수에 url을 입력해 Request 객체를 생성해서,
이를 urlopen() 함수에 매개변수로 넘겨주어도 동일한 결과를 얻을 수 있다.
Request에 header값을 추가하는 등에 활용될 수 있다.
import urllib.request
url = 'https://velog.io/@jd0419'
req = urllib.request.Request(url)
# req.add_header("User-Agent", client_user_agent)
# req.add_header("X-Naver-Client-Id", client_id)
# req.add_header("X-Naver-Client-Secret", client_secret)
req, type(req)
# Output: (<urllib.request.Request at 0x241011d02e0>, urllib.request.Request)
res = urllib.request.urlopen(req)
res
# Output: <http.client.HTTPResponse at 0x2417f394550>마)
getheader()는 해당 HTTP 요청의 헤더값을 추출하여 표시해주는 메서드이다.
import urllib.request
res = urllib.request.urlopen('https://velog.io/@jd0419')
res.getheader('Content-Type')
# Output: 'text/html; charset=utf-8'바)
status는 해당 response의 상태 코드를 지니고 있는 속성이다.
상태 코드는 HTTP 요청이 성공했는지 실패했는지를 서버에서 알려주는 코드로
대표적으로 200은 OK(성공), 404는 Not Found(찾을 수 없는 페이지)를 의미한다.
추가적으로 각 코드들은
1xx: Informational - Request received, continuing process
2xx: Success - The action was successfully received, understood, and accepted
3xx: Redirection - Further action must be taken in order to complete the request
4xx: Client Error - The request contains bad syntax or cannot be fulfilled
5xx: Server Error - The server failed to fulfill an apparently valid request
(출처: http://www.iana.org/assignments/http-status-codes/http-status-codes.xhtml)로 분류되니 참고하시길
사)
urllib에서는 없는 페이지를 요청하면 HTTPError를 발생시켜 프로그램 실행이 중단된다는 점이 이후에 다룰 requests 라이브러리와 가장 큰 차이점이다.
import urllib.request
print("실행 완료 (1/3)")
print("실행 완료 (2/3)")
res = urllib.request.urlopen('https://velog.io/@jd04199')
print("실행 완료 (3/3)")
# Output:
# 실행 완료 (1/3)
# 실행 완료 (2/3)
# ---------------------------------------------------------------------------
# HTTPError Traceback (most recent call last)
# Input In [20], in <cell line: 5>()
# 3 print("실행 완료 (1/3)")
# 4 print("실행 완료 (2/3)")
# ----> 5 res = urllib.request.urlopen('https://velog.io/@jd04199')
# 6 print("실행 완료 (3/3)")
# ...
#
# HTTP Error 404: Not Found2) requests
requests는 파이썬으로 HTTP 통신이 필요한 프로그램을 작성할 때 가장 많이 사용되는 라이브러리다.
가)
requests는 케네스 레이츠(Kenneth Reitz)가 만든 모듈로 urllib보다 인기있는 모듈이지만 파이썬 표준 라이브러리는 아니므로 따로 설치를 해야한다.
$ pip install requests나)
urllib와 기능상 큰 차이는 없지만
요청하는 방식이 명시되어 있고, 요청하는 데이터도 정리되어 있는 등
사용자 친화적인 문법을 사용하여 다루기 쉽고 안정성이 뛰어난 것이 특징이다.
다)
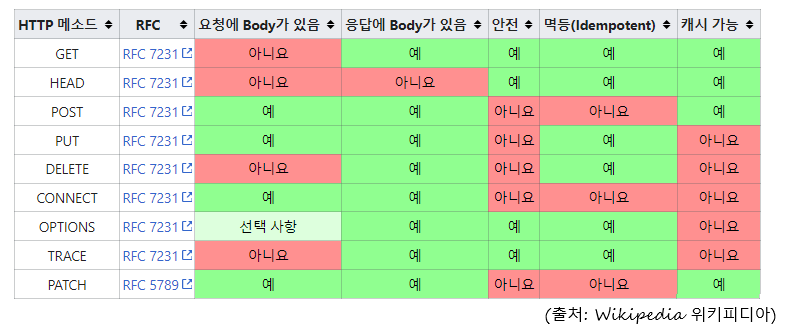
클라이언트가 웹 서버에게 사용자 요청의 목적/종류를 알리는 수단인
HTTP 요청 방식(HTTP Request Method)에는 여러 가지가 있는데
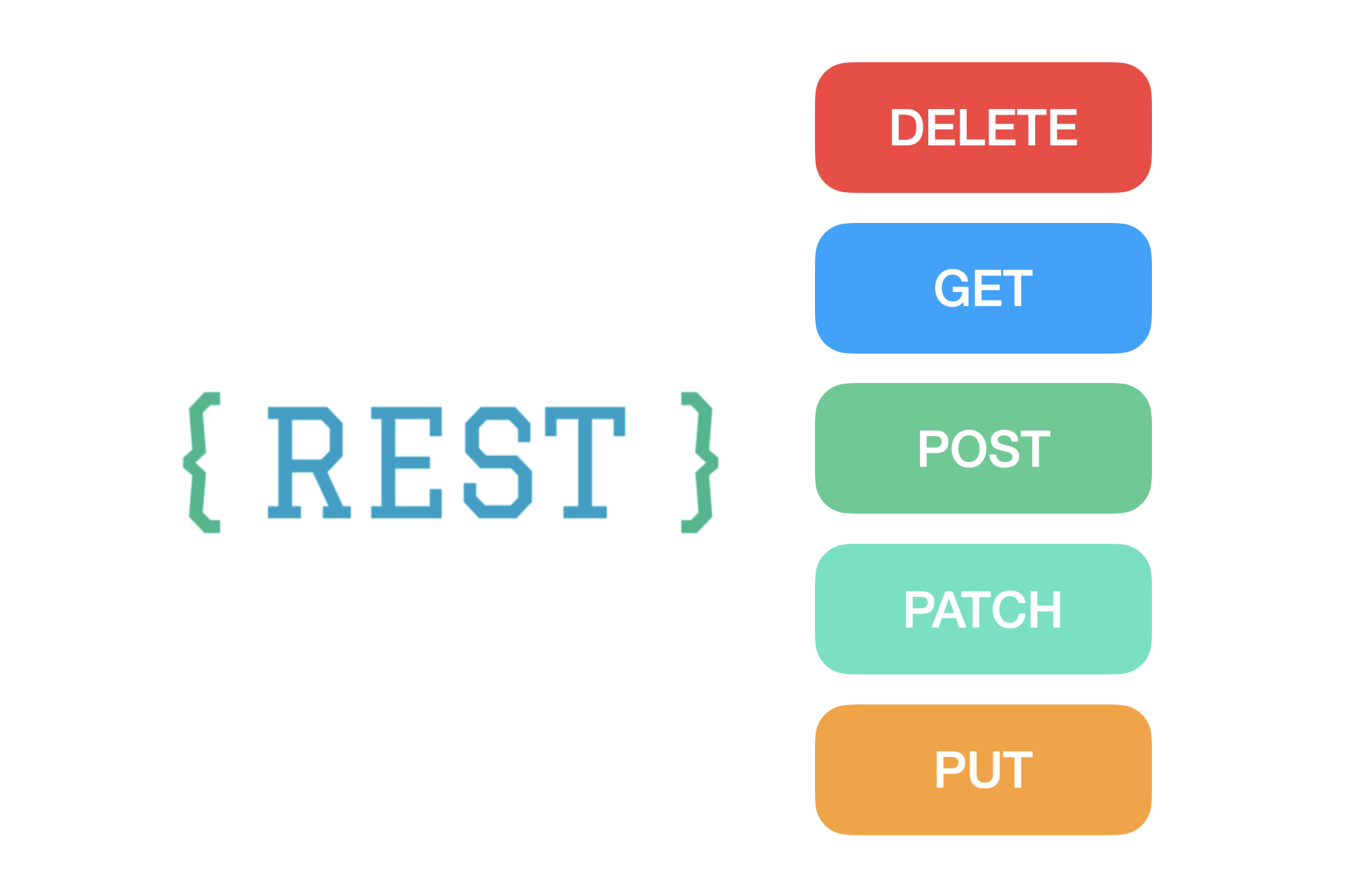
그 중에서 자주 사용되는 방식은 GET과 POST 방식이 대표적이다.
REST API에 적용되는 CRUD Operation에는 GET, POST, PUT, PATCH, DELETE가 있다.
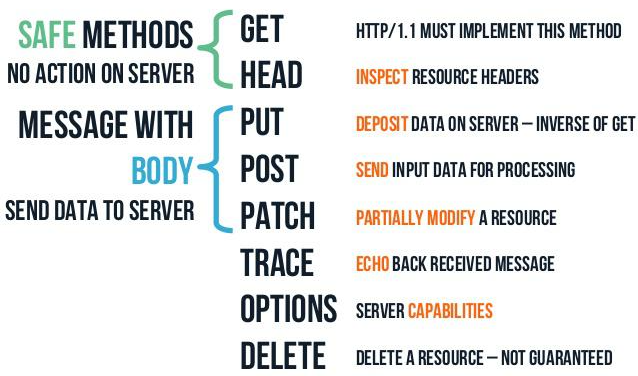
라)
requests 라이브러리는 HTTP 요청 방식에 대응하는 이름의 함수를 사용하는 식의 매우 직관적인 API를 제공한다.
GET 방식: requests.get()
POST 방식: requests.post()
PUT 방식: requests.put()
DELETE 방식: requests.delete()
매개변수에는 요청할 페이지의 URL을 입력하며,
요청이 정상적으로 처리된 경우 응답 전문(response body/payload)에 요청한 데이터가 담겨오게 된다.
import requests
url = 'https://velog.io/@jd0419'
res = requests.get(url)마)
응답 객체의 status_code 속성을 통해 요청이 잘 처리되었는지 문제가 있는지 알 수 있다.
import requests
url = 'https://velog.io/@jd0419'
res = requests.get(url)
res.status_code
# Output: 200바)
응답 전문을 읽어오는 방법은 크게 세 가지가 있다.
content 속성을 통해서는 바이너리 원문을 얻을 수 있다.
res.content
# Output: 200text 속성을 통해 UTF-8로 인코딩된 문자열을 얻을 수 있습니다.
res.text
# Output: 200마지막으로, 응답 데이터가 JSON 포멧이라면 json() 메서드를 통해 딕셔너리 객체를 얻을 수 있습니다.
res.json()
# Output: 200사)
응답에 대한 메타 데이터를 담고 있는 응답 헤더는 headers 속성을 통해 딕셔너리의 형태로 얻을 수 있습니다.
>>> response.headers
>>> response.headers['Content-Type']
'application/json; charset=utf-8'아)
요청 쿼리
GET 방식으로 HTTP 요청을 할 때는 쿼리 스트링(query string)을 통해 응답받을 데이터를 필터링하는 경우가 많습니다.
params 옵션을 사용하면 쿼리 스크링을 사전의 형태로 넘길 수 있습니다.
# https://jsonplaceholder.typicode.com/posts?userId=1
>>> response = requests.get("https://jsonplaceholder.typicode.com/posts", params={"userId": "1"})
>>> [post["id"] for post in response.json()]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]자)
요청 전문
POST나 PUT 방식으로 HTTP 요청을 할 때는 보통 요청 전문(request body/payload)에 데이터를 담아서 보내는데요.
data 옵션을 사용하면, HTML 양식(form) 포멧의 데이터를 전송할 수 있으며, 이 때 Content-Type 요청 헤더는 application/x-www-form-urlencoded로 자동 설정됩니다.
>>> requests.post("https://jsonplaceholder.typicode.com/users", data={'name': 'Test User'})
<Response [201]>json 옵션을 사용하면, REST API로 JSON 포멧의 데이터를 전송할 수 있으며, 이 때 Content-Type 요청 헤더는 application/json로 자동 설정됩니다.
>>> requests.post("https://jsonplaceholder.typicode.com/users", json={'name': 'Test User'})
<Response [201]>차)
요청 헤더
headers 옵션을 사용하면 요청 헤더도 직접 설정할 수 있는데요. 인증 토큰을 보낼 때 유용하게 사용할 수 있습니다.
>>> requests.post("https://jsonplaceholder.typicode.com/users", headers={'Authorization': 'Bearer 12345'})
<Response [201]>다. 파싱
우선 HTML 문서를 핸들링하기 위해선 어떤 페이지를 탐색할 것인지를 설정하는 URL 요청이 필요하다.
Find:
find 메소드
" What is the use of repeating all that stuff ! " the Mock Turtle interrupted, " if you don't explain it as you go on? It's by far the most confusing thing I ever heard ! " . The Mock Turtle sighed deeply, and began, in a voice sometimes choked with sobs, to sing this:" Beautiful Soup, so rich and green,
Waiting in a hot tureen!
Who for such dainties would not stoop?
Soup of the evening, beautiful Soup!
Soup of the evening, beautiful Soup!
Beau—ootiful Soo—oop!
Beau—ootiful Soo—oop!
Soo—oop of the e—e—evening,
Beautiful, beautiful Soup!
( 참고자료 :
crawl
https://library.gabia.com/contents/9239/
parse tree
bs
https://nocopyright.tistory.com/entry/이상한-나라의-앨리스원문소설
https://desarraigado.tistory.com/14
https://www.hanbit.co.kr/channel/series/series_view.html?cms_code=CMS4344562296&hcs_idx=14
urllib, request
https://han-py.tistory.com/320
https://moondol-ai.tistory.com/238
https://bentist.tistory.com/44
https://www.daleseo.com/python-requests/
https://hongku.tistory.com/292
https://infsafe.tistory.com/m/24
HTTP
https://zorba91.tistory.com/136
https://velog.io/@ellyheetov/REST-API
)
