BigQuery 시계열 분석 - Z-Chart Analysis
시작하기 전에
규모있는 쿼리를 작성하기 위해서는 일관된 코드 구조와 스타일의 유지가 중요하다. 이 글의 예시는 다음 BigQuery 스타일 가이드를 참고하고 있다.
BI 분석 핸즈온
기업의 매출과 같이 시간의 경과에 따라 변화하는 데이터로부터 과거 실적이나 추이 등을 파악하고 미래의 실적을 예측하기 위한 목적으로 시계열 분석이 활용된다.
이번 핸즈온은 시계열 분석 기법 중의 하나인 Z-Chart 분석을 BigQuery 언어로 진행하며 SQL 활용 능력을 키우는 것을 목표로 한다.
아래의 단계별로 Z-Chart 분석에 요구되는 지표들을 산출하고 시각화하는 과정을 따라가 보자.
raw data --> data mart --> visualization
데이터 준비
핸즈온에 사용할 매출 데이터는 아래 참고도서에서 공개한 부록/예제소스를 참고하여 BigQuery 환경에서 실습 가능하도록 정리하였다.
[참고도서] 데이터 분석을 위한 SQL 레시피 - 4장
매출 데이터 분석
1. 예시 테이블 생성
우선 예제 소스 중 9-1-data.sql 을 최소한의 변경으로 BigQuery 테이블로 생성해 보도록 하자.
CREATE OR REPLACE TABLE learning_club.purchase_log (
dt STRING,
order_id INT64,
user_id STRING,
purchase_amount INT64,
);
INSERT INTO learning_club.purchase_log VALUES
('2014-01-01', 1, 'rhwpvvitou', 13900),
('2014-01-01', 2, 'hqnwoamzic', 10616),
('2014-01-02', 3, 'tzlmqryunr', 21156),
('2014-01-10', 26, 'cyxfgumkst', 11339)
-- ...무료로 사용중인 GCP Project free tier 에서 위의 쿼리는 INSERT 문을 사용하지 못한다는 에러를 돌려준다.
배움의 길은 멀고도 험하다. 어쩔 수 없다. 약간의 고급진 기능을 사용하여 INSERT같은 DML 문을 사용하지 않고 예시 테이블을 만들어 보자.
BigQuery Scripting은 범용 프로그래밍 언어처럼 문장내에서 변수를 선언하고 사용할 수 있도록 해준다.
이 가운데 DECLARE는 변수를 선언하는 구문인데 이런게 있구나 정도로 넘어가자. BigQuery Scripting은 별도의 문법 강의에서 다룰 예정이다.
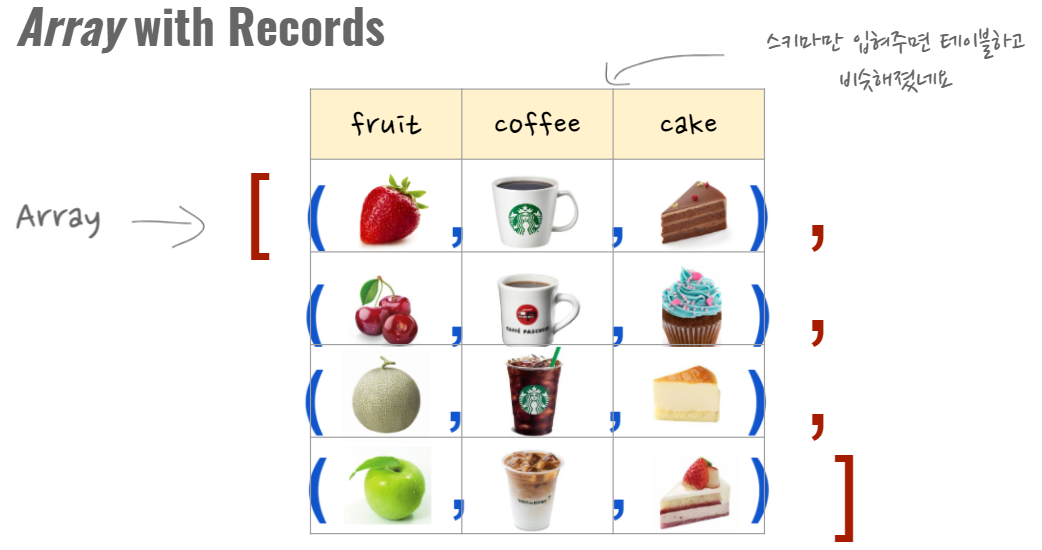
다만, 데이터 형식이 구조체의 배열(Array of Struct)인 변수는 BigQuery내에서 테이블과 거의 동등하게 다루어진다는 것만 기억해 두면 좋겠다.
아래 그림에서 배열의 각 요소(element)는 테이블에서 하나의 행(row)으로, 각 요소에 해당하는 구조체는 4개의 멤버을 가지는데 테이블의 컬럼(column)으로 생각할 수 있다.
[그림 1.] ARRAY<STRUCT<fruit, coffee, cake>> 구조체 배열
Nested Table 생성 쿼리
DECLARE 구문을 통해서 purchase_log라는 구조체 배열 변수를 하나 선언하자.
구조체는 구매날짜, 주문번호, 사용자식별자, 구매금액을 포함하는 레코드이다.
DECLARE purchase_log ARRAY<STRUCT<
dt STRING,
order_id INT64,
user_id STRING,
purchase_amount INT64
>>
DEFAULT [
('2014-01-01', 1, 'rhwpvvitou', 13900),
('2014-01-01', 2, 'hqnwoamzic', 10616),
('2014-01-02', 3, 'tzlmqryunr', 21156),
('2014-01-02', 4, 'wkmqqwbyai', 14893),
('2014-01-03', 5, 'ciecbedwbq', 13054),
('2014-01-03', 6, 'svgnbqsagx', 24384),
('2014-01-03', 7, 'dfgqftdocu', 15591),
('2014-01-04', 8, 'sbgqlzkvyn', 3025),
('2014-01-04', 9, 'lbedmngbol', 24215),
('2014-01-04', 10, 'itlvssbsgx', 2059),
('2014-01-05', 11, 'jqcmmguhik', 4235),
('2014-01-05', 12, 'jgotcrfeyn', 28013),
('2014-01-05', 13, 'pgeojzoshx', 16008),
('2014-01-06', 14, 'msjberhxnx', 1980),
('2014-01-06', 15, 'tlhbolohte', 23494),
('2014-01-06', 16, 'gbchhkcotf', 3966),
('2014-01-07', 17, 'zfmbpvpzvu', 28159),
('2014-01-07', 18, 'yauwzpaxtx', 8715),
('2014-01-07', 19, 'uyqboqfgex', 10805),
('2014-01-08', 20, 'hiqdkrzcpq', 3462),
('2014-01-08', 21, 'zosbvlylpv', 13999),
('2014-01-08', 22, 'bwfbchzgnl', 2299),
('2014-01-09', 23, 'zzgauelgrt', 16475),
('2014-01-09', 24, 'qrzfcwecge', 6469),
('2014-01-10', 25, 'njbpsrvvcq', 16584),
('2014-01-10', 26, 'cyxfgumkst', 11339)
];
-- 테이블 생성 쿼리
CREATE OR REPLACE TABLE learning_club.purchase_log AS
SELECT log.* FROM UNNEST(purchase_log) log;UNNEST() 함수로 구조체 배열(Array of Struct)의 요소인 구조체를 각각의 행(row)으로 풀어내고, 이어 구조체 안의 필드들을 dot operator 또는 member field access operator(멤버 접근 연산자) 라고 불리우는 표기법를 통해서 열(column)로 분리시키면 일반 테이블을 SELECT 하는 것과 동일한 결과가 만들어진다.
위 FROM 절의 UNNEST() 구문과 SELECT 절의 log.* 표기에 주목하자.
이후에 CTAS(Create Table As Select) 구문으로 Nested Table이 BigQuery의 Permanant Table이 되도록 만든다.
이제 데이터가 준비되었으니 분석을 위한 다음 단계로 넘어가자.
2. 날짜별 매출 집계
다음으로 앞서 만들어진 구매이력 데이터를 탐색하고 집계함수(aggregate function)와 분석함수(analytic function)을 사용하여 몇가지 지표들을 산출해 보자.
GROUP BY와 집계함수을 사용하여 날짜별 매출 지표를 산출하는 쿼리는 다음과 같다.
dt는 날짜를 나타내는 하나의 차원(dimension)이 되고, COUNT(), SUM(), AVG() 집계함수의 결과들은 각각 해당 차원에서 관측된 값인 메트릭(metric)이 된다.
SELECT dt,
COUNT(1) AS purchase_count,
SUM(purchase_amount) AS total_amount, -- 일별 매출
AVG(purchase_amount) AS avg_amount, -- 평균 구매액
FROM learning_club.purchase_log
GROUP BY 1
ORDER BY dt;쿼리 수행의 결과를 Explore Data (데이터 탐색) 를 통해 Data Studio에서 간단하게 시각화를 하면 다음과 같다.
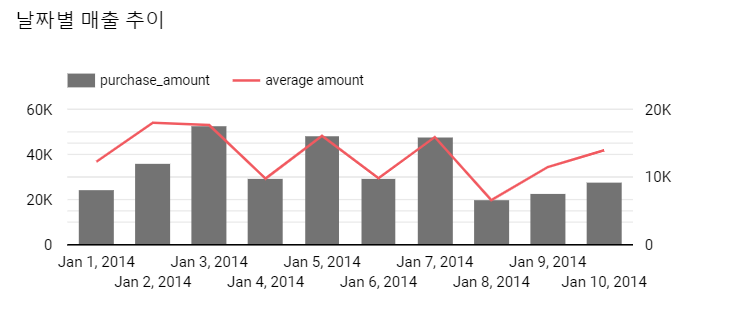
3. 이동평균을 사용한 날짜별 추이
앞선 시각화를 통해서 주중과 주말의 매출 차이를 확인할 수 있다.
이제 시계열 데이터의 계절성(seasonality)을 완화시키고 추세를 확인할 수 있도록 7일 이동평균 으로 표현해 보자.
SELECT dt,
COUNT(1) AS purchase_count,
SUM(purchase_amount) AS purchase_amount,
AVG(SUM(purchase_amount)) OVER (ORDER BY dt ROWS 6 PRECEDING) AS avg_seven_day,
FROM learning_club.purchase_log
GROUP BY 1
ORDER BY dt;이동 평균을 구하기 위해서는 분석함수(또는 윈도우함수)를 필요로 하는데 아래 구문은 뭔가 복잡하다.
AVG(SUM(purchase_amount)) OVER (ORDER BY dt ROWS 6 PRECEDING)
purchase_amount는purchase_log테이블의 컬럼일까 아니면 직전의AS purchase_amount에 의해서 새로 이름지어진 별칭(alias)일까? 정답: 테이블의 컬럼AVG(SUM(....))에서 SUM()은 집계함수일까? 분석함수일까? 정답: 집계함수AVG()는 그럼 무슨 함수일까? 정답: 분석함수
SELECT 문(statment)을 이루는 각 절(clause)의 해석순서와 컬럼 이름의 통용범위(scope) 때문인데 복잡하니 일단 넘어가자. BigQuery 문법 강의에서 이것도 다뤄보도록 하겠다.
위 구문은 테이블 전체를 날짜별로 오름 차순으로 정렬시킨 후에 각 행의 여섯 번째 전에 위치한 행부터 현재 행까지 7일간의 SUM(purchase_amount) 값의 평균을 구하는 구문이다. 여기서 SUM(purchase_amount)는 GROUP BY에 의해서 먼저 계산되어지는 날짜별 구매액에 해당한다.
Data Studio에서 위의 결과를 시각화하면 다음과 같다.

4. 당월 누계 매출
Z Chart 분석에서 요구하는 지표들을 구하는 방법들을 하나씩 살펴보자.
다음은 일별 매출 데이터가 주어졌을 때 해당 월의 누계 매출을 구하는 쿼리이다.
윈도우 함수 구문에서 PARTITION BY SUBSTR(dt, 1, 7)은 윈도우 함수가 적용될 파티션을 월 단위로 나눈다는 의미이고, ROWS UNBOUNDED PRECEDING은 월 단위로 나뉘어진 파티션의 첫번째 행 (매월 1일에 해당)부터 현재 행 (매월 현재일)까지 윈도우를 설정한다. 설정된 윈도우에 포함된 행들을 SUM() 분석함수를 호출하게 되는데 여기서는 일별 매출(SUM(purchase_amount))을 다시 SUM() 분석함수로 누계시키고 있다.
-- total_amount는 일별 매출액, agg_amount는 해당 월의 해당 일까지의 매출 누계
SELECT dt,
SUBSTR(dt, 1, 7) AS year_month,
SUM(purchase_amount) AS total_amount,
SUM(SUM(purchase_amount)) OVER (
PARTITION BY SUBSTR(dt, 1, 7) ORDER BY dt ROWS UNBOUNDED PRECEDING
) AS agg_amount
FROM learning_club.purchase_log
GROUP BY dt
ORDER BY dt
;
-- 위와 동등한 결과의 쿼리, daily_purchase 서브쿼리에서 일별 매출액을 먼저 구하고,
-- 메인 쿼리에서 윈도우 함수를 사용하여 해당일까지의 매출 누계 산출
WITH daily_purchase AS (
SELECT dt,
SUBSTR(dt, 1, 4) AS year,
SUBSTR(dt, 6, 2) AS month,
SUBSTR(dt, 9, 2) AS day,
SUM(purchase_amount) AS purchase_amount,
COUNT(order_id) AS orders
FROM learning_club.purchase_log
GROUP BY 1
)
SELECT dt,
year || month AS year_month,
purchase_amount,
SUM(purchase_amount) OVER (
PARTITION BY year, month ORDER BY dt ROWS UNBOUNDED PRECEDING
) AS agg_amount
FROM daily_purchase
;5. 월별 매출의 작대비(작년대비비율)
지금까지 사용한 데이터는 열흘간의 매출 실적 데이터로 월별 매출 추이를 분석하기에는 부족하다.
다음은 2014년 1월부터 2015년 12월까지 매출 데이터로 이를 사용하여 월별 매출의 작대비를 구해보도록 하자.
예시 데이터는 도입부에서 언급한 도서의 공개 데이터를 사용하였다.
DECLARE purchase_log_yr ARRAY<STRUCT<
dt STRING,
order_id INT64,
user_id STRING,
purchase_amount INT64
>> DEFAULT [
('2014-01-01', 1, 'rhwpvvitou', 13900),
('2014-02-08', 95, 'chtanrqtzj', 28469),
('2014-03-09', 168, 'bcqgtwxdgq', 18899),
('2014-04-11', 250, 'kdjyplrxtk', 12394),
('2014-05-11', 325, 'pgnjnnapsc', 2282),
('2014-06-12', 400, 'iztgctnnlh', 10180),
('2014-07-11', 475, 'eucjmxvjkj', 4027),
('2014-08-10', 550, 'fqwvlvndef', 6243),
('2014-09-10', 625, 'mhwhxfxrxq', 3832),
('2014-10-11', 700, 'wyrgiyvaia', 6716),
('2014-11-10', 775, 'cwpdvmhhwh', 16444),
('2014-12-10', 850, 'eqeaqvixkf', 29199),
('2015-01-09', 925, 'efmclayfnr', 22111),
('2015-02-10', 1000, 'qnebafrkco', 11965),
('2015-03-12', 1075, 'gsvqniykgx', 20215),
('2015-04-12', 1150, 'ayzvjvnocm', 11792),
('2015-05-13', 1225, 'knhevkibbp', 18087),
('2015-06-10', 1291, 'wxhxmzqxuw', 18859),
('2015-07-10', 1366, 'krrcpumtzb', 14919),
('2015-08-08', 1441, 'lpglkecvsl', 12906),
('2015-09-07', 1516, 'mgtlsfgfbj', 5696),
('2015-10-07', 1591, 'trgjscaajt', 13398),
('2015-11-06', 1666, 'ccfbjyeqrb', 6213),
('2015-12-05', 1741, 'onooskbtzp', 26024)
];
CREATE OR REPLACE TABLE learning_club.purchase_log_yr AS
SELECT l.* FROM UNNEST(purchase_log_yr) l;위와 같이 UNNEST함수와 멤버접근연산자를 사용하여 on-the-fly하게 정의된 nested table을 BigQuery 영구테이블로 먼저 만든다.
LAG(col, n) 네비게이션 함수는 파티션의 현재 행을 기준으로 n만큼 앞선 행의 col값을 가져온다. 따라서 LAG(purchase_amount, 12)는 날짜순으로 정렬된 월별 매출액 테이블에서 일년 전의 매출액을 돌려주게 된다. 이 값으로 현재 월매출액을 나누게 되면 작대비(purchase_amount_rate)가 산출된다.
CREATE OR REPLACE TABLE learning_club.purchase_log_dm AS
WITH daily_purchase AS (
SELECT dt,
SUBSTR(dt, 1, 4) AS year,
SUBSTR(dt, 6, 2) AS month,
SUBSTR(dt, 9, 2) AS day,
SUM(purchase_amount) AS purchase_amount,
COUNT(order_id) AS orders
FROM learning_club.purchase_log_yr
GROUP BY 1
),
year_month_purchase AS (
SELECT year,
month,
SUM(purchase_amount) AS purchase_amount,
SUM(orders) AS orders
FROM daily_purchase
GROUP BY 1, 2
)
SELECT year, month, purchase_amount,
LAG(purchase_amount, 12) OVER (ORDER BY year, month) AS purchase_amount_prev,
ROUND(purchase_amount / LAG(purchase_amount, 12) OVER (ORDER BY year, month), 2) AS purchase_amount_rate,
FROM year_month_purchase
ORDER BY year, month;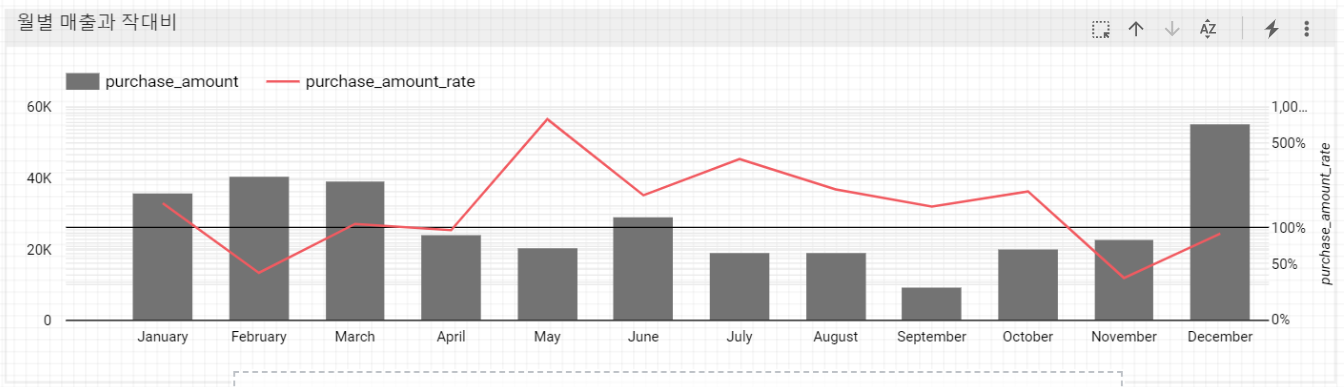
몸풀기를 마쳤으니 이제 본격적으로 Z-Chart 분석에 들어가 보도록 하자.
Z-Chart 분석
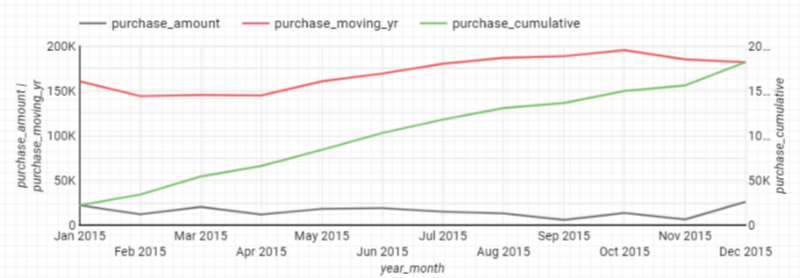
Z-Chart 분석은 월별매출, (년)매출누계, 이동(년간)합계 라는 3가지 지표를 꺾은선 그래프로 나타낸 것으로 Z 형태를 이룬다 하여 Z-Chart 로 불린다.
경영 분석이나 마케팅 분야에서 월 변동이나 계절 변동을 배제한 매출 경향을 분석하기 위해 자주 이용된다. Z-Chart 분석을 위해서는 아래 3가지 지표가 필요하다.
- 월별매출
- 매출누계
- 이동년계
매출 이력 데이터로부터 각각의 지표를 산출하는 과정은 다음과 같다.
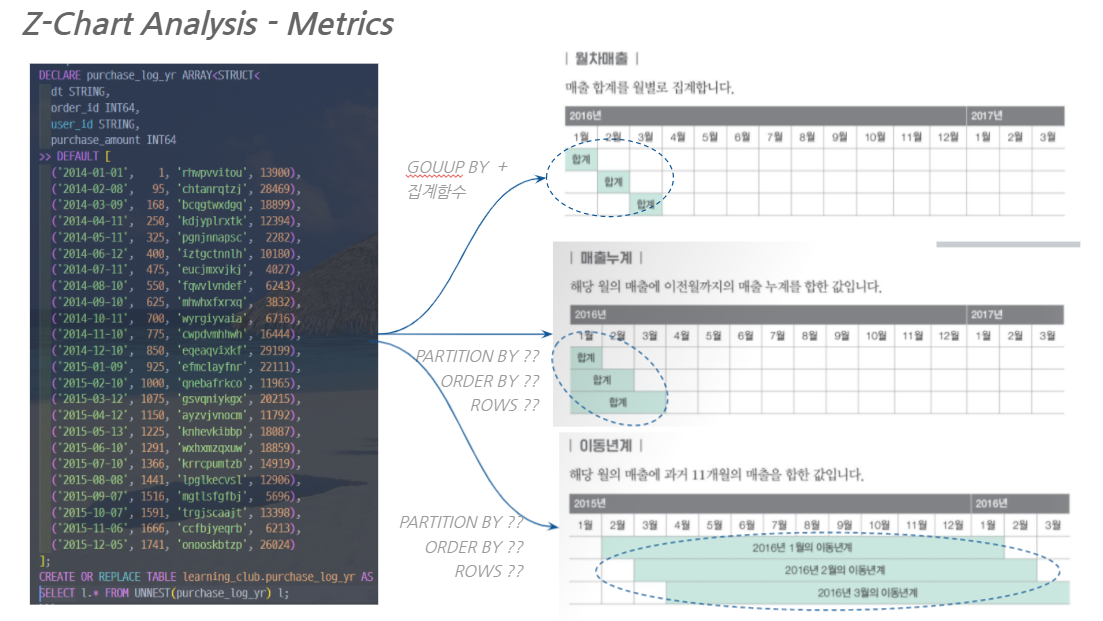
1. Z-Chart 분석 쿼리
CREATE OR REPLACE TABLE learning_club.zchart_dm AS
WITH daily_purchase AS (
SELECT dt,
SUBSTR(dt, 1, 4) AS year,
SUBSTR(dt, 6, 2) AS month,
SUBSTR(dt, 9, 2) AS day,
SUM(purchase_amount) AS purchase_amount,
COUNT(order_id) AS orders
FROM learning_club.purchase_log_yr
GROUP BY 1
ORDER BY 1
),
year_month_purchase AS (
SELECT year,
month,
SUM(purchase_amount) AS purchase_amount,
SUM(orders) AS orders
FROM daily_purchase
GROUP BY 1, 2
)
SELECT year, month,
purchase_amount,
SUM(purchase_amount) OVER (
PARTITION BY year ORDER BY month ROWS UNBOUNDED PRECEDING
) AS purchase_cumulative,
SUM(purchase_amount) OVER (
ORDER BY year, month ROWS 11 PRECEDING
) AS purchase_moving_yr,
FROM year_month_purchase
ORDER BY year, month; [그림] Z Chart Analysis Query
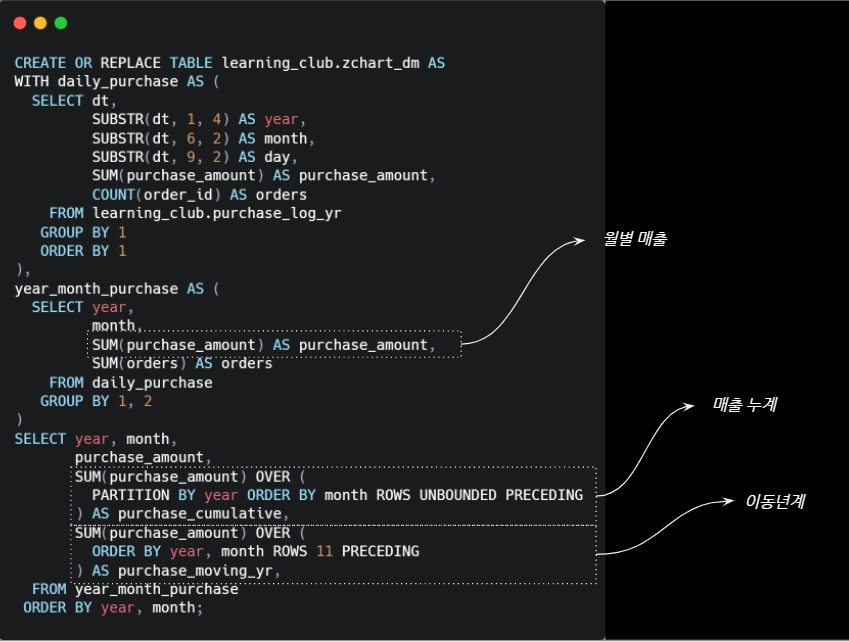
월별매출은 GROUP BY 집계를 통해 쉽게 계산된다. 매출누계와 이동년계는 앞서 몸풀기에서 살펴봤던 일별 매출 누계와 이동평균를 산출할 때 사용했던 분석함수(윈도우함수)를 사용하여 산출 가능하다.
윈도우 함수를 사용할 때는 항상 파티션을 어떻게 나눌지, 파티션 안에서 윈도우의 범위를 어떻게 잡을지를 고민해야 한다. 앞의 내용을 바탕으로 각자 생각해 보자.
2. Z-Chart 분석 시각화
위에서 산출한 3가지 지표들들을 마트화하여 BigQuery 테이블로 생성한 후 Data Studio에서 시각화를 하면 아래와 같이 Z 자 모양의 그래프가 만들어진다.