
Data Journey & Data Storage
- 데이터가 pipeline의 흐름에 따라 어떻게 변하는지 알아야 모델의 결과를 제대로 이해할 수 있음
- ML metadata는 ML 모델에 대한 디버깅(변경 사항 추적)과 모델의 재현성(reproducibility)에 도움을 줌
Data Journey
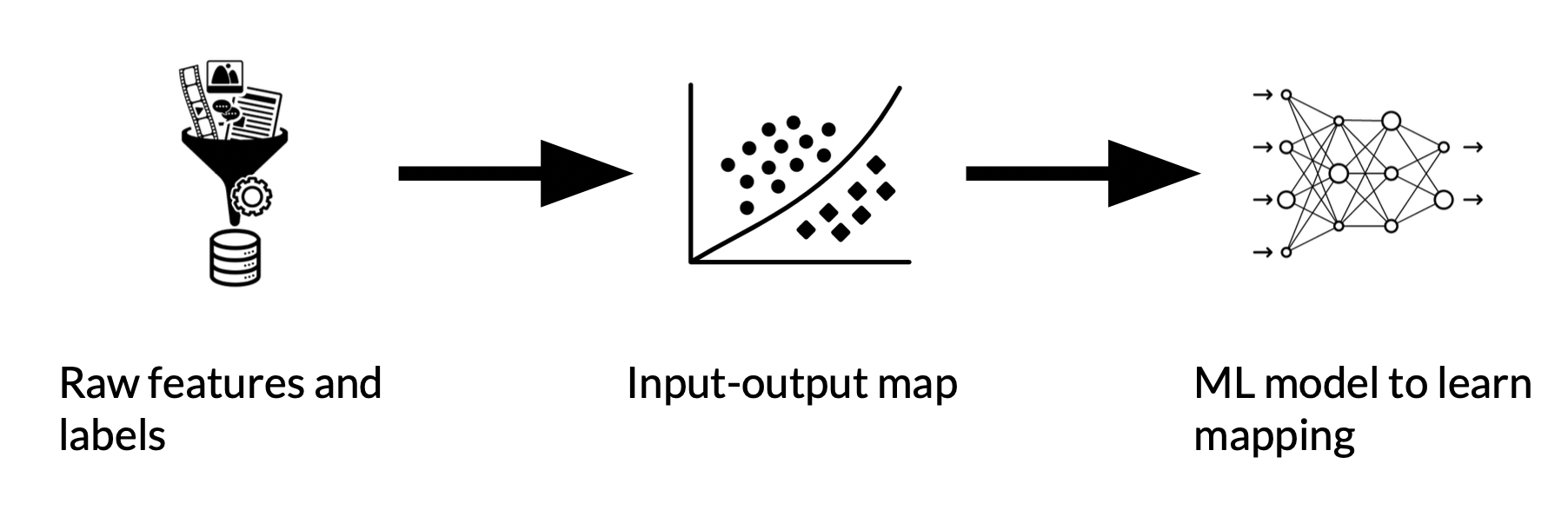
- 우리가 가지고 있는 raw data에서 시작해서
- train set의 input과 우리가 예측하려는 label간의 mapping 기능을 수행하고
- 모델 훈련을 통해 예측하려는 label과 점점 더 가까워짐
- 이 과정을 거치면서 data transformation이 일어남
ex. data format, feature engineering, training - 그러므로 모델의 결과를 제대로 해석하려면 data transformation을 제대로 이해해야 함.
Data Artifacts
pipe line 단계마다 발생하는 모든 결과물. Transformation 단계마다 생성되는 data들, schema, metrics 등을 모두 의미함.
Data provenance & lineage
비슷한 의미로 사용되는 경우가 많음, Sequence of artifacts
모델의 결과를 해석해주는 하나의 key. 모델은 training set에 있는 데이터의 표현 = 모델은 데이터의 변화로 볼 수 있음 = provenance를 통해 데이터가 학습&최적화하면서 어떻게 변했는지 알 수 있음
-
Provenance : 파이프라인을 이해하고 디버깅을 수행하는데 중요함
- 어떻게 train 했고, 결과가 어떤 의미를 갖는지
- 어느 지점이든, trace back 가능
- 서로 다른 결과를 갖는 training runs 비교하면서 왜 이런 결과를 냈는지 이해할 수 있음
-
Lineage : 기업이 개인 데이터의 출처, 변경사항을 tracking 할 수 있게 하여 규정 준수에 중요한 역할을 함
- 데이터가 어떻게 쓰이고, pipeline에 따라 이동하면서 어떤 transformation이 일어났는지 빠르게 determine할 수 있게 함
Data versioning
- 많은 training runs를 거치면서 많이 변화하기 때문에 Data pipline 관리는 중요한 문제
- ML이 제대로 되었으면, 결과가 꽤 일관되어야(variance는 있어도 최대한 비슷해야) 함
- code versioning(github) & environment versioning(Docker, Terraform)
- Data versioning
- data provenance&lineage 추적하기 위해서 매우 필요함- code file보다는 엄청 커서 DVC나 Git LFS(Large File Storage) 사용
Introduction to ML Metadata (MLMD)
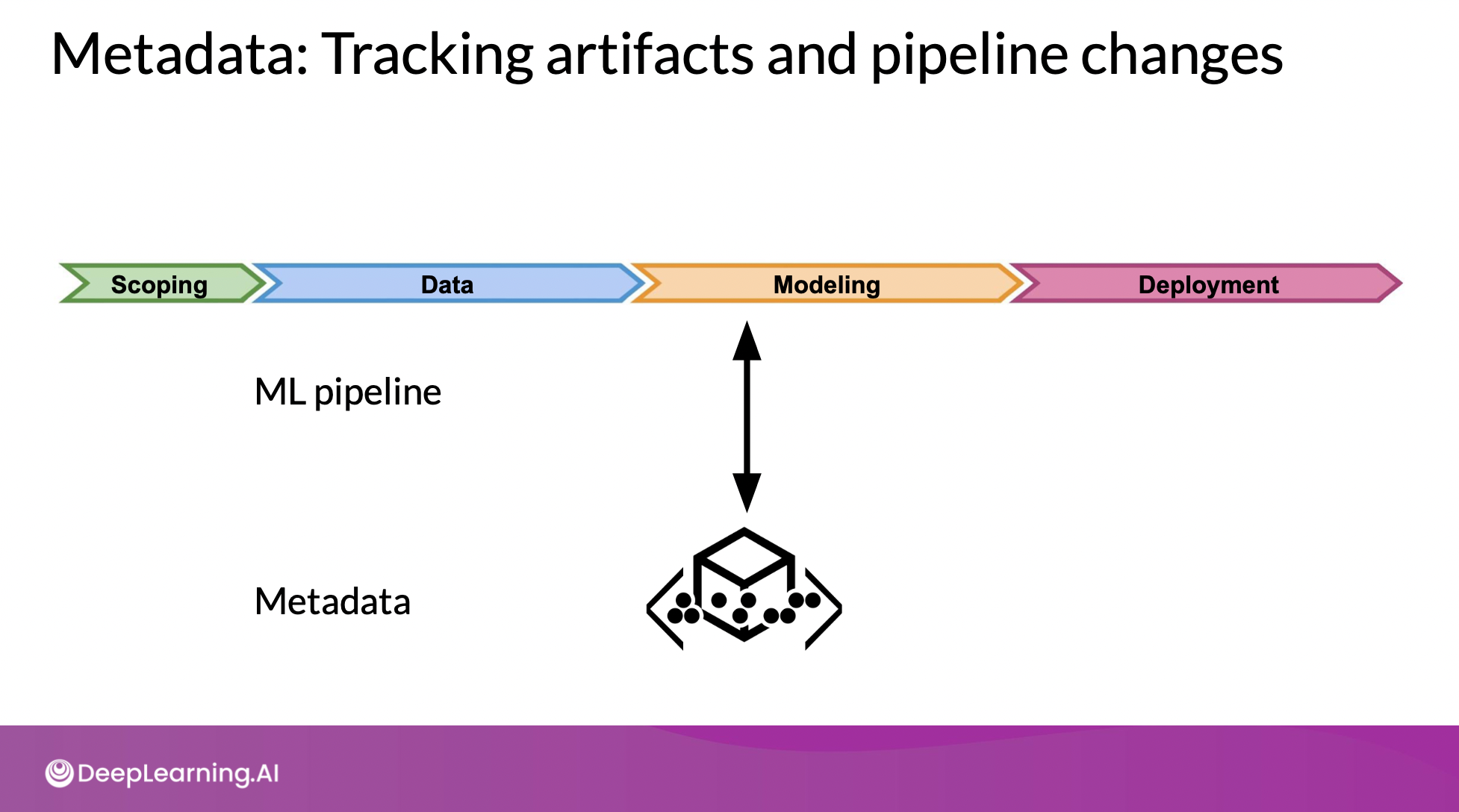
- 파이프라인 구성요소들, execution, training run, trained models 등의 정보를 metadata가 갖고 있음. 이걸 사용해서 lineage 분석하거나 디버깅 가능.
- 연결된 관계로서 파이프라인을 전체적으로 이해할 수 있게 함
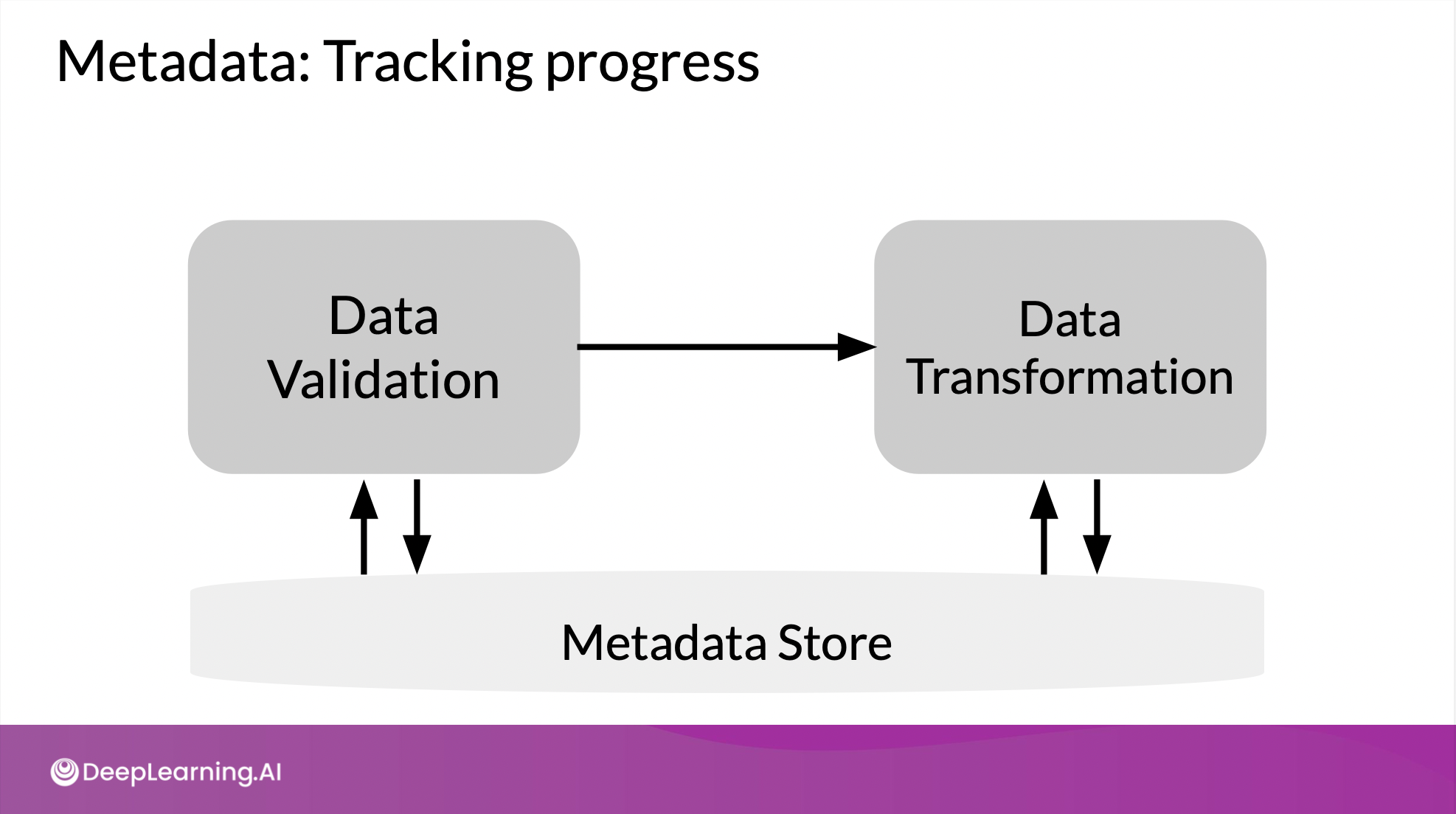
-
progress lost를 걱정할 필요 없음.
-
과거 결과들과 비교, 수정, 발전 시킬 수 있음
-
TFX component

- 코드 실행기 앞에 driver가 붙어서 필요한 metadata 제공
- 뒤에 publisher가 붙어서 결과를 metadata에 저장
MLMD library
pipeline과 연결되서 사용할수도, 따로 사용할 수도 있음
만약 함께 사용된다면, MLMD에 저장되는 결과물은 artifacts에 기반을 두고 있고 특성정보를 관계형 db에 저장하거나, 데이터 셋과 같은 큰 파일을 저장하기 때문에, explicitly interaction은 어려움.ML Metadata terminology
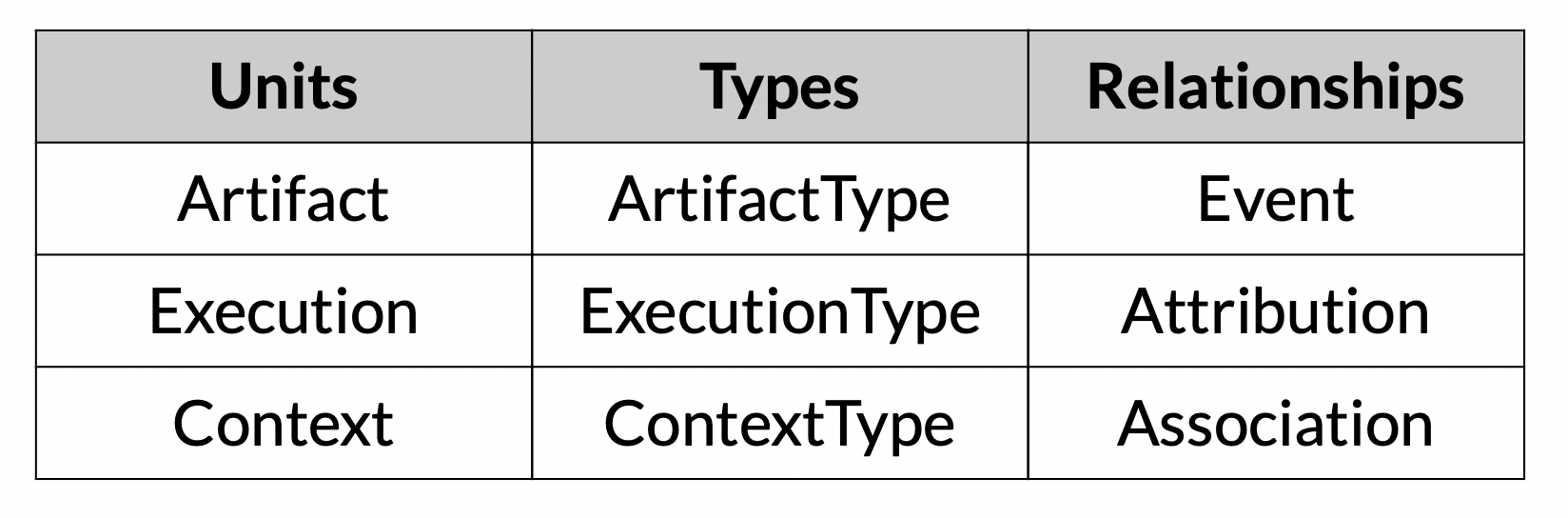
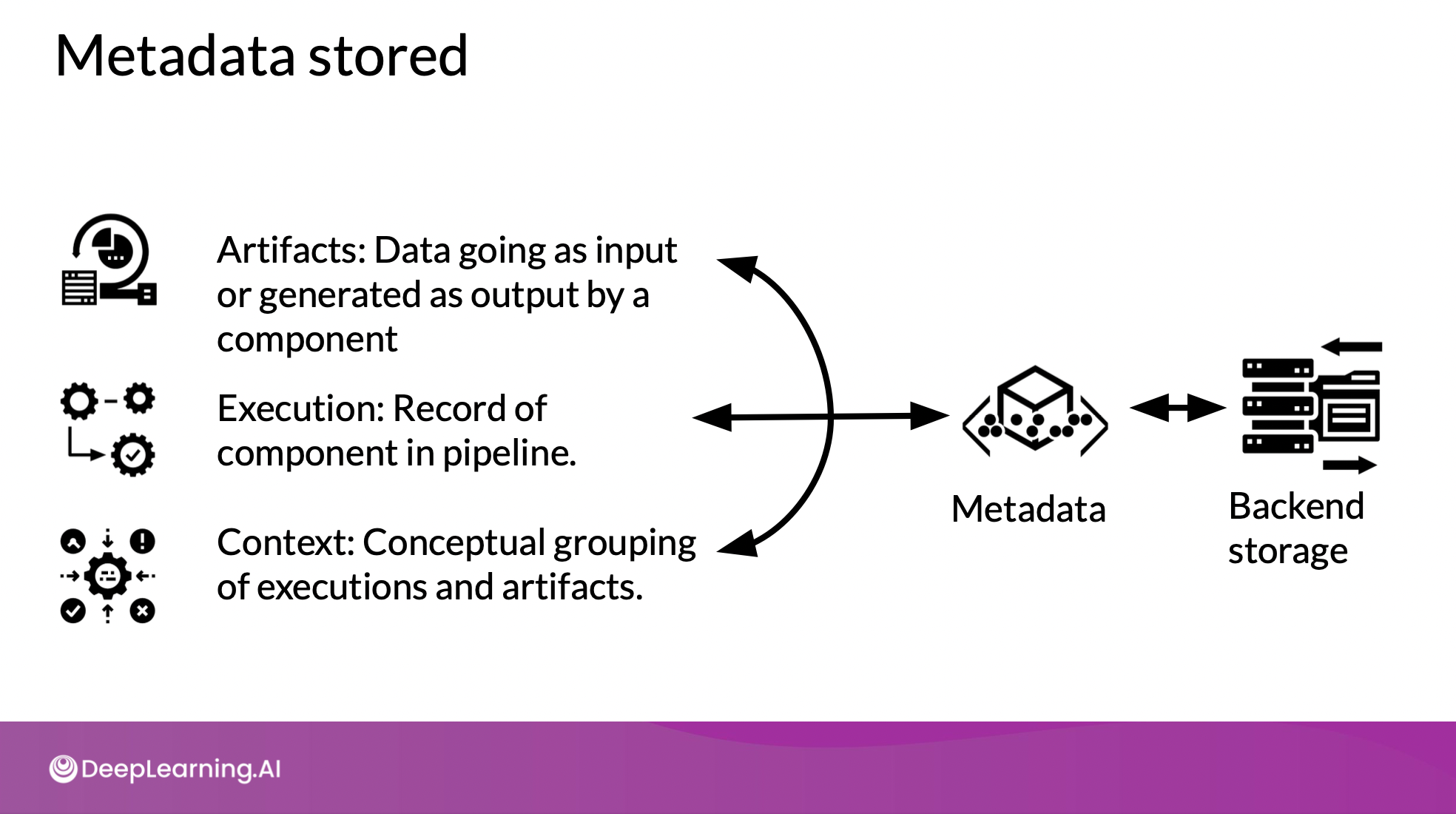
Artifact
- MLMD store에 저장되는 기본 단위
- 각 요소의 input & ouput 으로 사용됨
- Artifact <-> Execution : event
Execution
- component가 ML 파이프라인에서 run할 때의 record
Context
- Artifact&Execution 둘 다 한 타입의 component와 연결됨
- 함께 cluster될 수는 있지만, 각 type은 다름. = context
- metadata of the projects being run, experiments being conducted, details about pipelines, etc.
각 타입은 그 타입의 특성도 갖고 있음(??)
MetadataStore
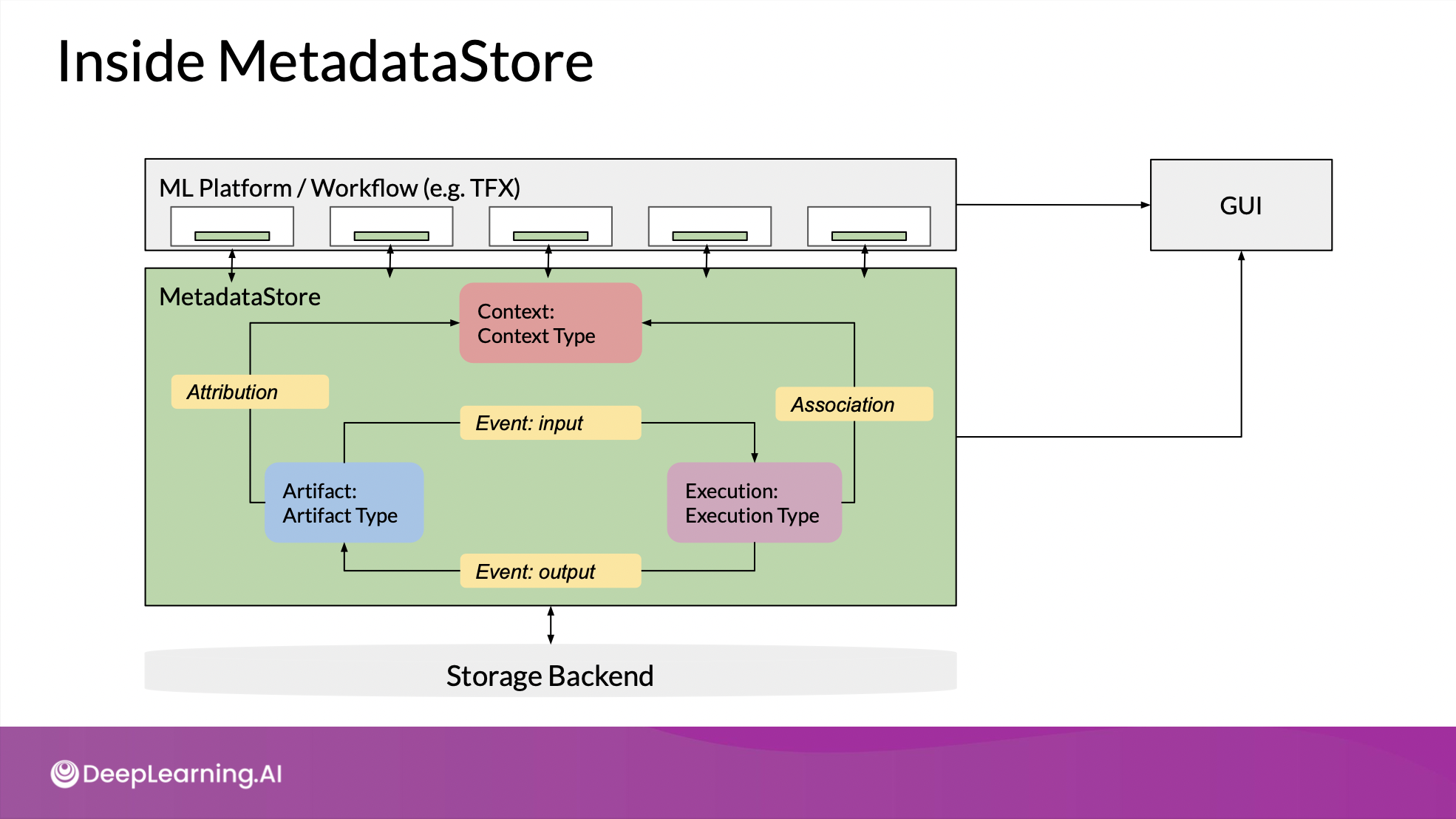
- 각 component별로 독립적으로 md store에 접근 가능
- 진행상황을 추적할 수 있는 GUI
- artifact : 핵심, 모든 파이프라인 구성 요소의 입력이 됨 & excecution에 기록됨
- 이런 관계가 attribution & association을 통해 context로 표현
- 생성된 모든 데이터는 백엔드 저장소에 저장.
Evolving Data
Schema Development
schema: feature name, type, required/optional, range, default values
- 데이터가 늘어남에 따라 이상치도 발생하고, 분포가 편향되기도 함
- 이런 걸 schema 개발할 때 고려해야 함
Requirements in production deployment
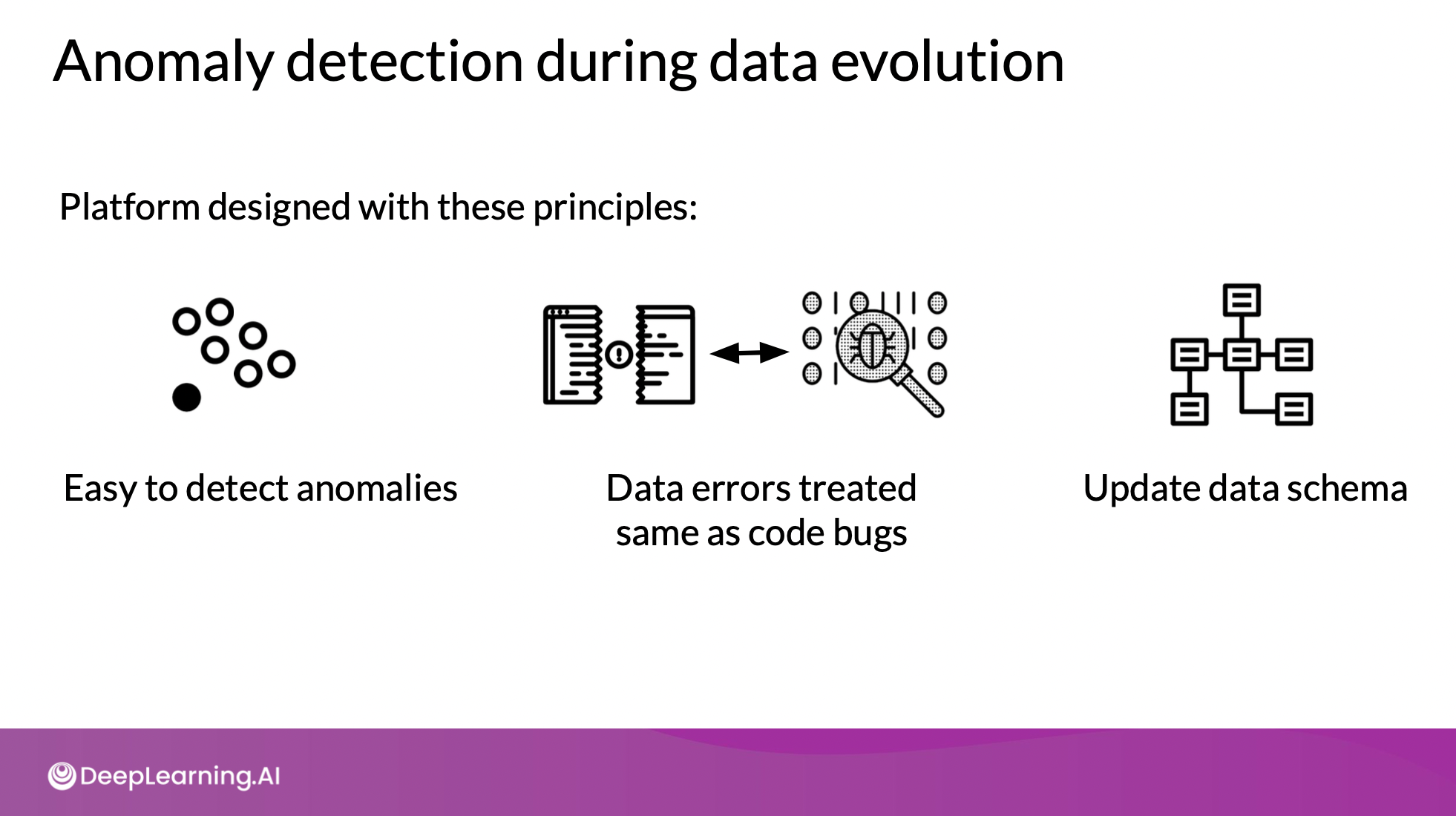
- 스키마를 발전시키면 데이터의 발전을 이해하고 추적하기 쉬움
- 자동 feature engineering과 함께 자동화의 중요한 input으로 작용할 수 있음
Schema Environments
- 코드 버전 관리처럼 schema도 버전 제어가 있으면, anomaly를 관리하기 쉬움
- 적용하고 싶은 상황에 따라 스키마를 사용자가 지정하도록 설정할 수 있음
ex. schema에 required로 표시되어 있는데 사실 prediction requests에 대한 데이터여서 레이블이 누락되어 있는 데이터 = anomaly로 보고
# anomaly 확인
stats_options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
eval_stats = tfdv.generate_statistics_from_csv(
data_location=SERVING_DATASET,
stats_options=stats_options
)
serving_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(serving_anomalies)
# 레이블이 optional인 스키마로 적용
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
tfdv.get_feature(schema, 'Cover_Type')
.not_in_environment.append('SERVING')
# No output!Enterprise Data Storage
Feature stores
- documented, curated, and access controlled features 저장
- 팀이 사용가능한 feature를 공유 & 검색해서 사용 가능
- 온, 오프라인 모두 사용 가능
- feature engineering과 model development 사이의 interface 역할
- 중복 작업을 줄이는 centralized 저장소
- 다른 각각의 파이프라인에서 프로세싱이 중복되는 것을 방지
- 접근 권한 제어
- 새로운 피쳐 생성을 위해 합쳐지거나, 사이즈 관리를 위해 지울 수 있음
offline
- 오프라인으로 데이터 수집 → feature engineering, 새로운 feature 생성 → 다시 store에 저장의 과정을 진행할 수 있음
- 모니터링 도구와 통합해서 오프라인에서 모니터링 가능, 처리된 feature는 오프라인용으로 저장. prediction도 가능
- 내가 찾는 데이터를 찾을 수 있게 해주는 meta data = 좋은 도구
online
대기 시간이 짧아야하기 때문에 pre-computed features를 사용
- batch 환경

- 하루에 한 번 or 몇시간에 한 번씩 업데이트될 때 적합.
- pre-computing & loading으로 쉽게 할 수 있음.
- 하지만 모델 훈련할 때는 request가 들어온 시점에 이용할 수 있는 데이터만 포함해야 함! (train&serving할 때는 동일한 데이터를 사용)
요약

- 개인부터 회사까지 모두 포괄할 수 있는 데이터 관리 수단
- 훈련&테스트할 때 성능 좋고 같은 데이터를 사용할 수 있게
- 일관성 있고, 미래 데이터에 대해 point-in-time에 맞는 데이터 에 접근할 수 있게
- feature에 대해 검색 가능하고, 문서화하고, 인사이트를 제공할 수 있게
Data Warehouse
하나 이상의 소스에서 데이터를 합쳐 처리하고 분석할 수 있는 기술. long running batch jobs을 일반적으로 의미하며, 읽기에 최적화되어 있음. 일관된 schema를 따라야 하기 때문에 실시간 입력이 아닐 수도 있음
기능 및 장점
- subject oriented (ex. 고객, 공급업체 등)
- 관계형 db, 파일 등 여러 소스에서 수집
- timestamp가 있어서 생성되었을 때 context 파악
- 이전 데이터가 지워지지 않음 = 데이터 발전 확인 가능
- 일관된 schema를 따름 = 데이터 품질, 일관성 좋음
- read & query 효율성이 좋아 빠르게 데이터 접근 가능
warehouse vs database 비교 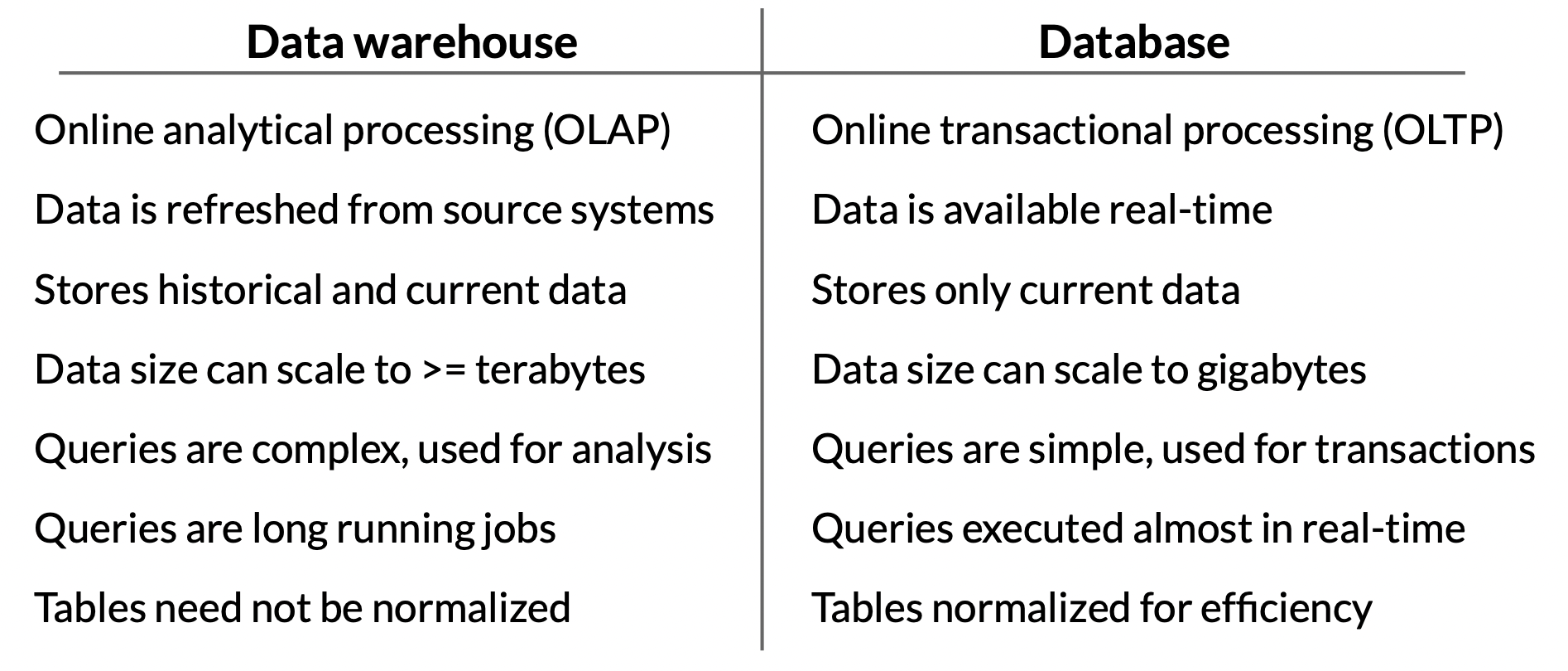
Data Lakes
nautral&raw 형태의 데이터. warehouse처럼 다양한 곳에서 데이터를 모으고, 정형/반정형/비정형 데이터가 모두 포함됨. processing을 하지 않고 대체로 schema를 따르지 않음.
warehouse vs lake 비교 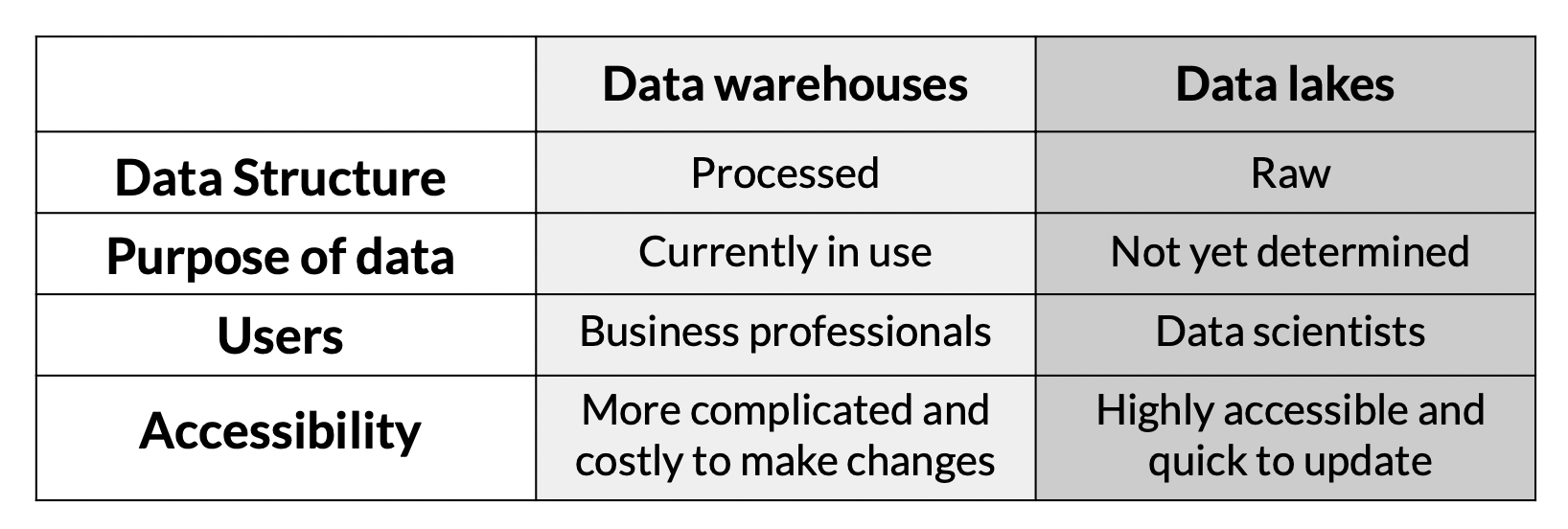
 엔지니어님들 감사합니다ㅎㅎ
엔지니어님들 감사합니다ㅎㅎ
