1. NL(Nested Loops) 조인
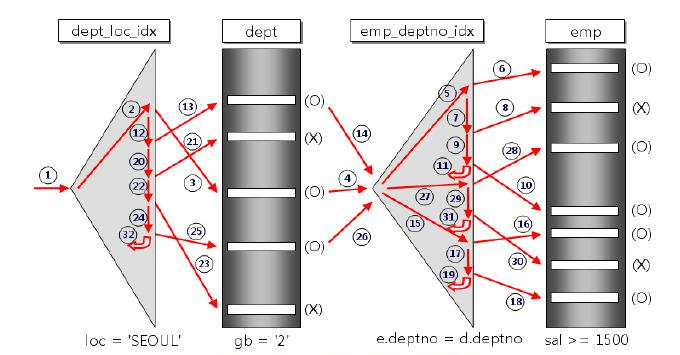
조인 수행 절차
하나의 테이블을 기준으로 Full-Scan 하면서 각 row를 추출할 때마다 순차적으로 상대 테이블의 연관된 모든 row들을 조인에 의해 추출한다.
- 튜닝 포인트
- 조인 횟수의 최소화를 위한 조인 순서의 최적화
- 조인 조건에 대한 인덱스 구성 및 사용
특징
- 인덱스에 의한 Random Access에 기반을 두기 때문에 대량의 데이터 처리 시 불리함.
- Driving Table로는 row 수가 적거나, where 절의 조건으로 적절하게 row를 제한할 수 있는 것이어야 함.
Driving Table: 우선적으로 데이터를 scan할 테이블(기준 테이블)
- Driven 테이블에는 조인 시 사용할 연결 고리 칼럼에 적절한 Index가 있어야 함.
- 만약 인덱스가 없으면 항상 Full-Scan해야하기 때문
문제점
인덱스 사용에 따른 Random Access로 인한 오버헤드
SM(Sort Merge) 조인
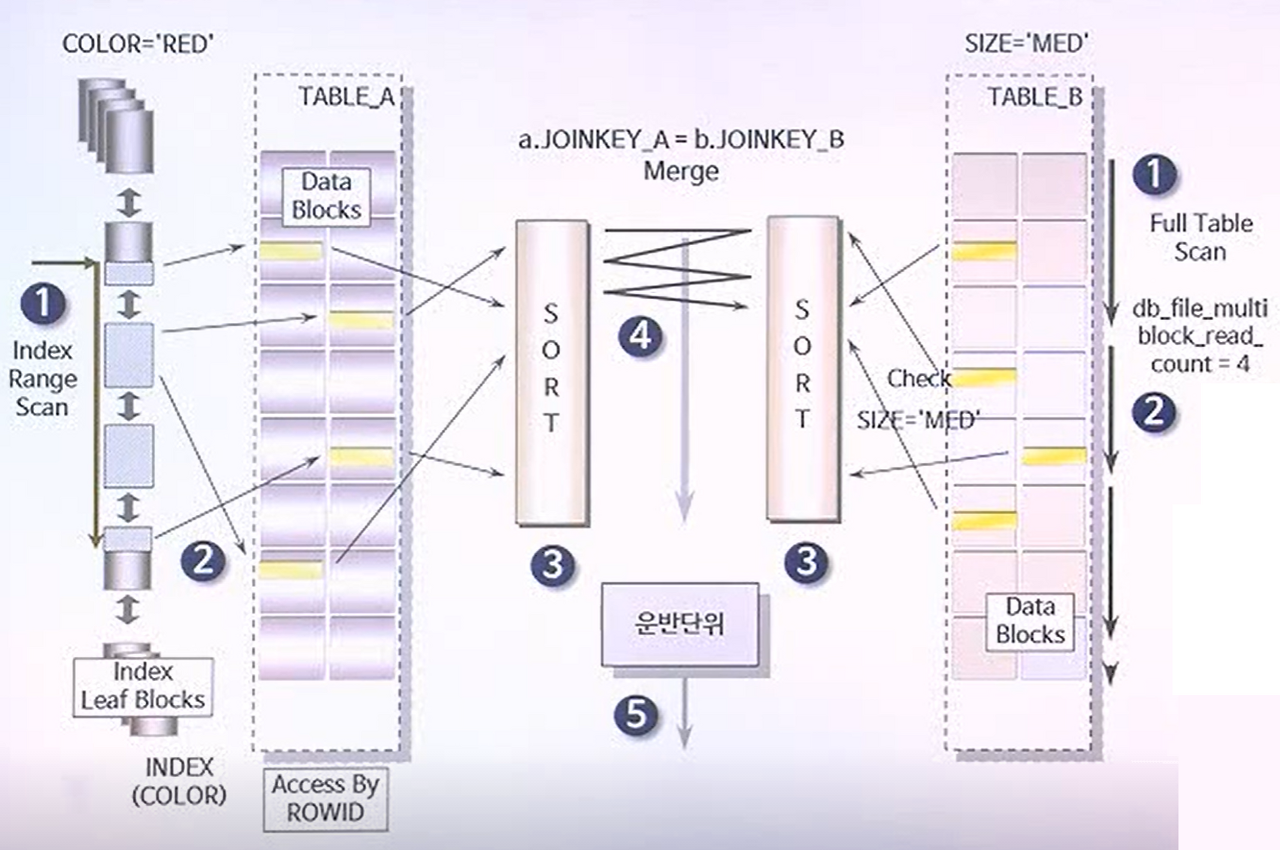
조인 수행 절차
각 테이블로부터 동시에 독립적으로 데이터를 읽어 들인 후, 연결고리 칼럼을 대상으로 정렬 작업을 수행한다. 이후, 정렬이 모두 끝나면 조인을 한다.
사용 용도
- Driven Table에 적절한 인덱스가 존재하지 않아 NL Join이 너무 비효율적일 때,
- Equal Join이 아닌 범위로 Join을 진행할 때,
튜닝 포인트
- 각 테이블로부터 데이터를 빠르게 처리할 수 있도록 한다.
- 정렬 작업을 위한 메모리(SORT_AREA_SIZE) 최적화
특징
- 연결고리 칼럼에 인덱스가 전혀 없어도 빠른 조인을 수행함
- Where 절의 조건으로 조인 범위를 줄이지 못하는 경우에 효율적임
- 조인이 되는 두 집합은 모두 정렬되어야 함
- Random Access가 일어나지 않고 Sorting 작업이 PGA 영역에서 수행되기 때문에 경합이 발생하지 않음
문제점
정렬 작업으로 인한 오버헤드
Hash 조인
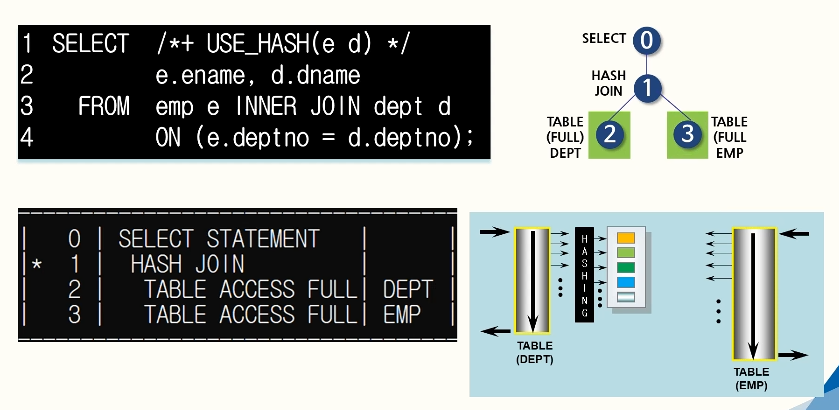
위의 두 조인 방법의 오버헤드를 줄여주는 join 방법
조인 수행 절차
Driving 테이블로 하나를 선택해서 데이터를 먼저 읽어 들인 후, Hashing을 통해 해시 값을 만들어 메모리에 올린다. 다음으로, 조인해야 할 테이블로부터 데이터를 읽어서 hashing을 통해 해시값을 만든다. 이렇게 만든 해시 값을 이용하여 조인을 한다.
사용 용도
- 배치작업, 대용량 테이블을 JOIN할 때 이점을 가진다.
튜닝 포인트
- Driving 테이블의 선택이 중요하다. (충분히 작아야한다.)
- Hash 영역의 사이즈를 초과하게 되면 디스크 영역을 사용하기 때문에 비효율적이다.
- 각 테이블로부터 데이터를 빨리 처리하도록 한다.
- 조인 작업을 위한 메모리(HASH_AREA_SIZE) 최적화
특징
- 조인을 위해 만든 해시 값을 저장하기 위해 Hash Bucket이 구성되는데, 이를 위해 많은 메모리와 CPU를 필요로 한다.
- 하드웨어 자원이 넉넉한 상황에서는 다른 조인보다 효율적일 수 있지만, 부족한 상황에서는 오히려 다른 조인보다 비효율적이다.
- Driven Table의 레코드들을 해싱하여 Driving Table의 레코드에 매칭시켜야 하기 때문에 Equal Join만이 가능하다.
참고자료

Data Engineer