PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model
Abstract
semantic segmentation이 많은 성능 향상을 이뤄냈지만 아직 real world에 실제로 적용하기엔 부족하다. 그래서 PP-LiteSeg라는 가볍고 real time으로 적용할 수 있는 모델을 제안한다. 특별한 점은 Flexible and Lightweight Decoder(FLD)로 이전 디코더의 overhead 연산량을 줄여준다. feature 표현을 강화하기 위해서 Unified Attention Fusion Module(UAFM)을 제안한다. 이 모듈은 input weight feature를 섞은 weight를 만들어 주는 spatial, channel attention의 이점을 활용한다. 그리고 Simple Pyramid Pooling Module(SPPM)을 사용해 global feature는 잘 파악하면서 계산량을 줄인다. PPlite-seg 모델은 계산량, 정확도 모두 우수하다.
Proposed Method
Flexible and Lightweight Decoder(FLD), Unified Attention Fusion Module(UAFM), Simple Pyramid Pooling Module(SPPM)을 통해서 PP-LiteSeg라는 모델 제안
3.1 Flexible and Lightweight Decoder
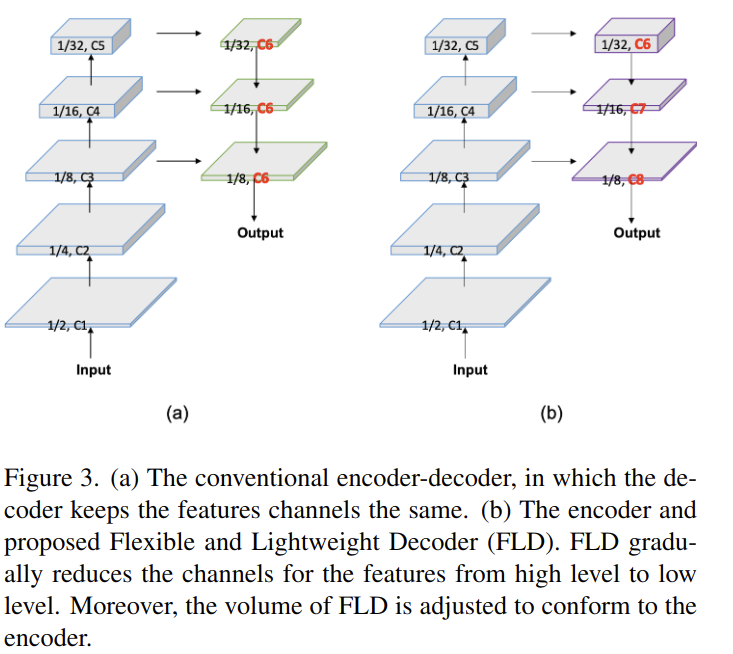
Encoder decoder구조는 semantic segmentation에서 효과적인게 증명되었다. 일반적으로 인코더는 몇단계로 묶인 layer들을 활용해서 hierarchical feature를 추출한다. low level에서 high level로 갈수록 feature의 channel은 점차 증가하고 feature의 spatial size는 점차 감소한다. 이러한 설계는 인코더의 효율성을 강화하면서 연산량의 밸런스를 맞춰나간다. 디코더도 몇 단계에 거쳐서 feature를 섞고 upsampling한다. 비록 high level에서 low level로 갈수록 feature의 spatial size는 증가하지만 경량화 모델들의 디코더는 채널을 모든 level에서 같도록 유지한다. 따라서 얕은 단계보다 깊은 단계에서 연산량은 당연히 증가하게 된다. 디코더의 효율성을 향상시키기위해서 Flexible and Lightweight Decoder(FLD)라는 위의 그림 같은 디코더를 제안한다. FLD는 high level에서 low level로 갈수록 점차 feature의 channel을 줄여나간다. FLD는 인코더와 디코더간의 밸러스를 맞추기 위해서 쉽게 연산량을 조절할 수 있다. FLD에 있는 feature의 channel이 감소하더라도 PP-LiteSeg는 좋은 성능을 보인다.
3.2 Unified Attention Fusion Module
여러 단계의 feature를 섞는 것은 segmentation 성능 향상을 위해서 필수적이다. 그리고 elementwise summation, concatenation이 효과적인게 이미 증명됐다. Unified Attention Fusion Module(UAFM)이라는 channel, spatial attention으로 구성된 모듈을 통해서 혼합된 feature map을 만들어낸다.
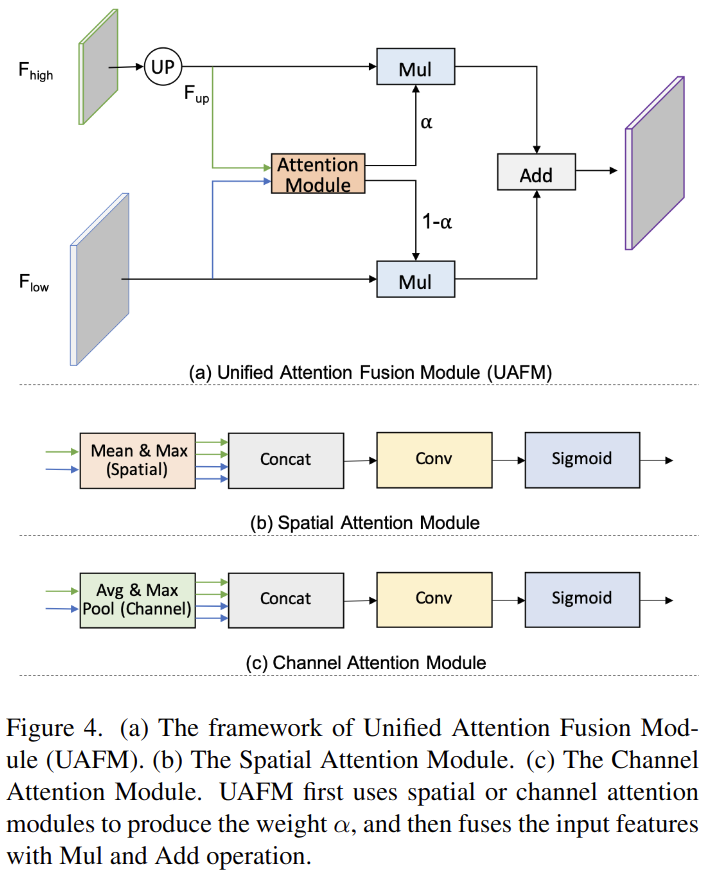
UAFM Framework
위의 그림처럼 UAFM은 weight 를 만들기 위해서 attention 모듈을 사용한다. 그리고 input feature를 Mul, Add 연산을 통해서 섞어준다.
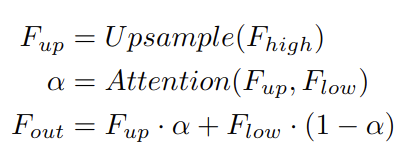
더 자세하게 설명하면 input feature는 다. 는 깊은 모듈의 output이고 는 encoder 짝이다. UAFM은 먼저 에 bilinear interpolation을 사용해서 와 같은 사이즈의 을 만든다. attention 모듈의 input으로 를 사용해서 weight 를 만든다. attention weight feature를 얻고나서 elementwise Mul을 에 각각 해준다. 마지막으로 UAFM은 attention weight를 elementwise를 해줘서 feature를 섞어준다.
Spatial Attention Module
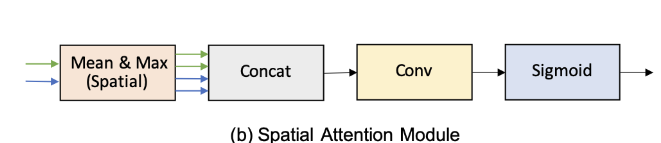
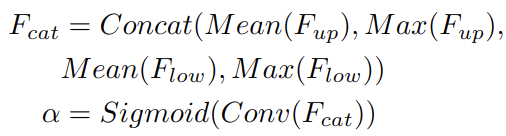
spatial attention module은 inter-spatial 관계를 사용해서 weight를 만들어 input feature의 각 픽셀의 중요도를 표현한다. 위의 그림에서 (b)처럼 (CxHxW)와 (CxHxW)를 이용해서 채널축으로 mean, max 연산을 통해 4개의 feature(1xHxW)를 생성한다. 그 다음으로 4개의 feature를 concat해서 4xHxW인 feature를 만든다. concat된 feature에 convolution과 sigmoid 연산을 통해서 output (1xHxW)를 만들어 낸다. 게다가 spatial attention 모듈은 유연해서 max 연산을 제거해 연산량을 줄일 수도 있다.
Channel Attention Module

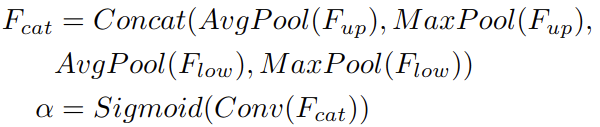
channel attention의 중요한 컨셉은 input feature안에 있는 각 채널의 중요도를 나타내는 weight를 생성하기 위해서 중간 채널들의 관계를 조정하는 것이다. channel attention은 average pooling과 max pooling을 사용해서 input feature의 spatial 차원을 줄인다(squeeze). 이 과정을 통해서 차원이 Cx1x1인 4개의 feature를 만든다. 그리고나서 생성된 4개의 feature를 channel축으로 concat을 한다음에 convolution과 sigmoid연산을 이용해 weight (Cx1x1)을 만든다.
3.3 Simple Pyramid Pooling Module
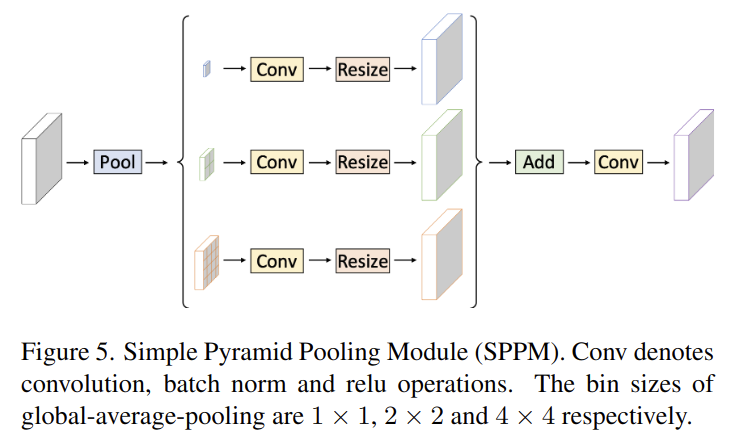
SPPM은 먼저 input feature를 섞기 위해서 pyramid pooling을 조절한다. pyramid pooling은 3개의 global average pooling연산(1x1, 2x2, 4x4)을 가진다. 그다음 output feature는 convolution과 upsampling과정을 통과한다. convolution 연산은 kernel size가 1x1이고 output channel은 input channel보다 작다. 마지막으로 upsample된 feature들을 더하고 convolution연산을 해 새로운 feature를 생성한다. 원래 PPM과 비교해서 SPPM은 중간 단계와 output channel을 줄인다. 그리고 concat 연산을 add로 바꾼다. 그래서 SPPM은 real time task에 더 잘 맞는 모듈이다.
3.4 Network Architecture
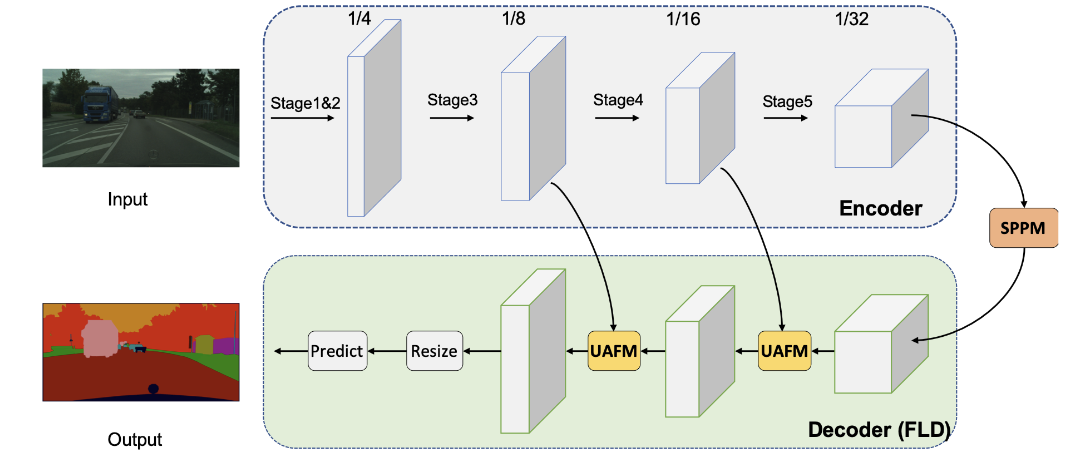
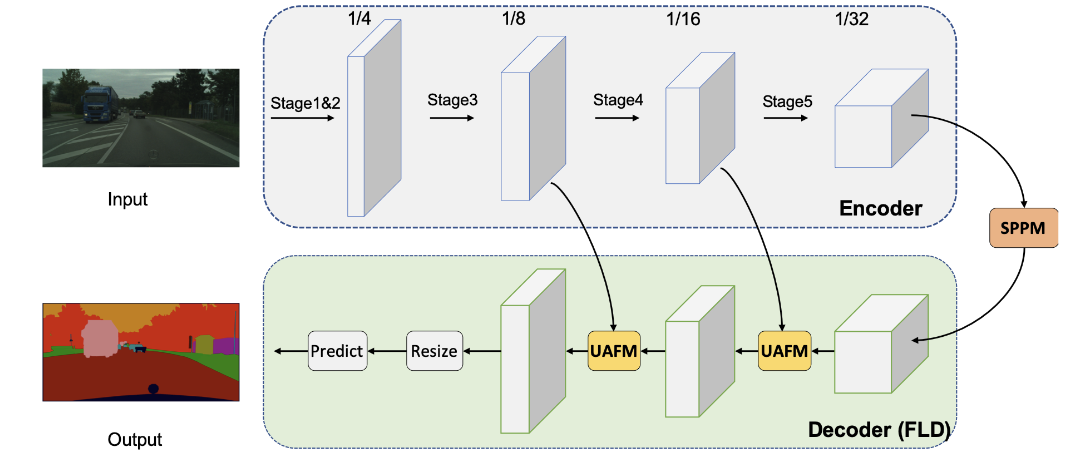
PP-LiteSeg는 크게 encoder, aggregation, decoder 3모듈로 구성되어있다. 먼저 input 이미지가 주어지면 PP-Lite는 STDCNet의 encoder를 사용한다. STDCNet은 5단계를 가지고 있는데 각 단계의 stride는 2이다. 그래서 마지막 feature size는 input size의 1/32이다.
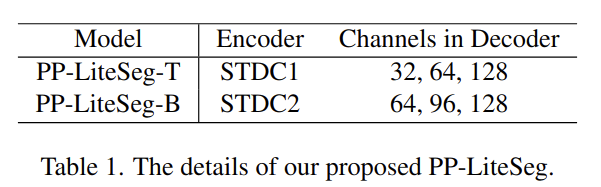
위의 표처럼 2가지 버전의 PP-Lite가 있다.(T, B) PP-LiteSeg-T는 STDC1을 사용했고 PP-LiteSeg-B는 STDC2를 사용했다. B는 정확도에 강점이 있고 T는 속도에 강점이있다. backbone으로 SSLD를 사용한다. 두번째로는 PP-LiteSeg는 SPPM을 long range dependency를 위해서 사용한다. encoder의 output feature를 input으로 사용하면서 SPPM은 global context 정보를 포함한 feature를 만들어낸다.
마지막으로 PP-LiteSeg는 FLD라는 디코더를 사용해서 multi level feature와 output을 점점 섞는다. FLD는 2개의 attention module과 segmentation head로 구성된다. low level feature는 인코더 단계에서 추출 되고 high level feature는 SPPM이나 더 깊은 fusion 모듈을 통해서 생성된다. UAFM 1/8로 down sampling된 섞인 feature를 생성한다. segmentation head에서 CBR 연산을 통해서 1/8로 down sampling된 feature의 channel을 class 숫자로 맞춰준다. upsampling연산은 feature size를 input image 사이즈로 확장시킨다. 그리고 argmax를 통해서 각 픽셀의 label을 결정한다. cross entropy loss와 online hard example mining이 모델의 최적화를 위해서 사용된다.
Reference
