Transformer정리중
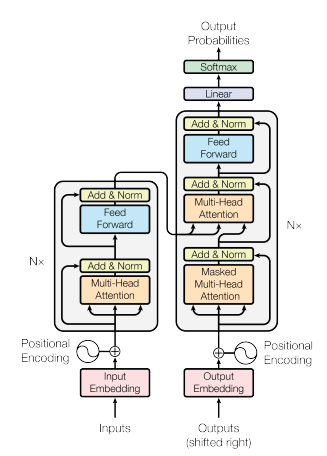
관련논문 - all you need is attention
구현코드 - 해당코드는 시계열 데이터(sunspot)을 이용하여 연습하였습니다.
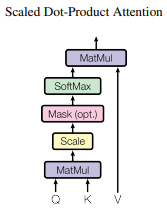
- Dot-Product(내적)
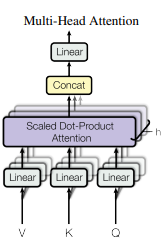
- MultiHead
Nadaraya-Watson Kernel Regression (1964)
- Estimator
- y=∑i=1mα(x,xi)yi
- Use given a kernel K to get weights of labels according to location x
- Define
- α(x,xi)=∑j=1mK(x−xj)K(x−xi)
- query : x (예측하고 싶은 값)
- keys : xi(1≤i≤m) ( data_input )
- values : yi(1≤i≤m) ( data_output )
- Kernel
- 가우시안 커널
- 가우시안 데이터 포인트는 0에 수렴
- 트라이앵글 커널을 사용하면 데이터 포인트를 0으로 만들 수는 있지만 이 방법으론 α(x,xi)=∑j=1mK(x−xj)K(x−xi)에서 분모가 0이 되어 계산이 되지 않는다.
- 즉 가우시안은 어떻게든 계산해서 답을 주긴 한다.
- Attention
- 공식
- ∑j=1mexp(β∣x−xj∣)exp(β∣x−xi∣)=softmax(β∣x−x1∣,β∣x−x2∣,…,β∣x−xm∣)i
- 음수값인 베타를 곱해주는 이유는 지수함수는 양수에서 급격히 값이 변하기 때문에 차이를 줄여주기 위해서
- softmax를 사용
- 가우시안 방식에 비해 노이즈에 조금 더 민감
- Self-Attention
