
오늘은 최근접이웃에 대해 배워 보도록 하겠습니다.
K-최근접 이웃
K-최근접 이웃(K-NN, K-Nearest Neighbor) 알고리즘은 가장 간단한 머신러닝 알고리즘입니다. 분류(Classification) 알고리즘으로써, 비슷한 특성을 가진 데이터는 비슷한 범주에 속하는 경향이 있다는 가정하에 사용합니다.
예를 들어
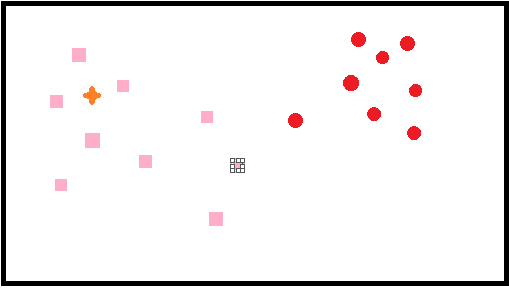
다음과 같이 데이터가 있을 때, 주황 별데이터의 주변 데이터는 분홍 사각형 데이터이기 때문에
분홍 사각데이터에 속한다고 추측할 수 있습니다.
이와 같이 주변에 가장 가까운 K개의 데이터를 보고 데이터가 속할 그룹을 판단하는 알고리즘입니다.
특징
K-NN은 훈련 데이터셋을 저장하는 것이 모델 학습의 전부입니다. 이때 거리를 측정하는 방법을 유클리드거리(Euclidean distance)를 사용합니다.
K-NN은 K 값에 따라 분류가 달라진 다는 것이 특징입니다.
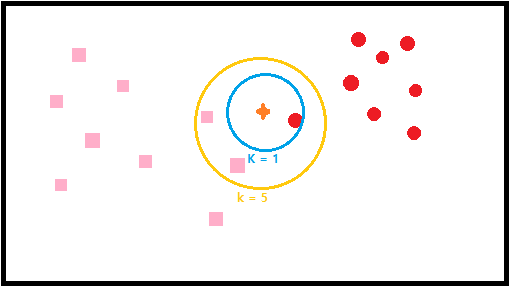
다음과 같이 데이터가 있을 때 k의 값에 따라 가까운 데이터를 확인하고 데이터의 총량의 따라 k=1은 빨간원 k=5는 분홍 사각형의 데이터라고 추측하게 됩니다.
K값은 홀수로 설정하는 것이 좋고, 최적의 K값을 구할 때는 데이터마다 다르게 접근해야 하기때문에 일반적으로는 총 데이터 수의 제곱근 값을 사용합니다.
K-NN은 간단한 알고리즘이지만 이미지 처리, 글자/얼굴 인식, 추천 알고리즘,의료 분야등으로 많이 사용됩니다.
장단점
장점
- 단순한 알고리즘 이기 때문에 구현이 쉬움
- 학습 데이터를 그대로 가지고 특별한 학습을 하지 않기 때문에 학습이 매우 빠름
단점
- 모델 생성하지 않기 때문에 특징과 클래스 간 관계를 이해하는데 제한적(모델 결과 해석이 아닌 변수와 클래스 간의 관계를 파악해야 원하는 결과를 얻을 수 있습니다)
- 적절한 K값이 필요하고 데이터가 많아지면 분류 단계가 느림
개요
input
X=[[0],[1],[2],[3]]
y=[0,0,1,1]
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier(n_neighbors=1) #가장 가까운 이웃의 수 1
knn.fit(X,y)
print(knn.predict([[1.1]]))
print(knn.predict_proba([[0.9]])) # 0일 확률, 1일 확률
print(knn.predict([[0.9]]))
print(knn.predict([[1.9]]))output
[0][1. 0.]]
[0][1]
다음과 같이 X와 Y의 데이터를 주어 졌을 때 4개의 데이터를 예측하여 1인지 0인지 구분 할 수 있습니다.
데이터셋 불러오기
input
import mglearn
import matplotlib.pyplot as plt
X,y=mglearn.datasets.make_forge()
mglearn.discrete_scatter(X[:,0],X[:,1],y)
plt.legend(['class 0','class 1'],loc=4)
plt.show()output
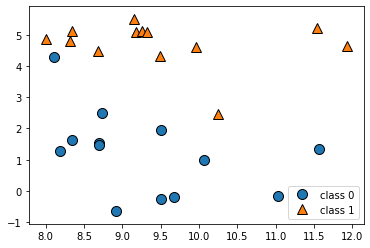
forge를 이용하여 데이터 셋을 만들어 줍니다.
K 설정하기
input
mglearn.plots.plot_knn_classification(n_neighbors=1)output
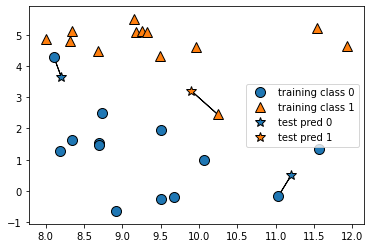
K 설정하기2
input
mglearn.plots.plot_knn_classification(n_neighbors=2)output
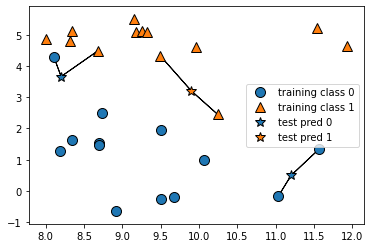
K 설정하기3
input
mglearn.plots.plot_knn_classification(n_neighbors=3)output

다음과 같이 K값에 따라 데이터분류가 달라지는 것을 확인 할 수 있습니다.
모델 학습
input
from sklearn.model_selection import train_test_split
X,y=mglearn.datasets.make_forge()
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=0)정확도 확인
input
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train,y_train)
print(knn.score(X_train,y_train))
print(knn.score(X_test,y_test))output
0.95
0.8333333333333334
K값을 3으로 정하고 데이터를 학습시켜줍니다.
K 값에 따른 데이터 분류
input
fig,axes=plt.subplots(1,3,figsize=(10,3))
for n,ax in zip([1,3,9],axes):
knn=KNeighborsClassifier(n_neighbors=n).fit(X,y)
mglearn.plots.plot_2d_classification(knn,X,fill=True,eps=0.5,ax=ax,alpha=0.4)
mglearn.discrete_scatter(X[:,0],X[:,1],y,ax=ax)
axes[0].legend(loc=3)output
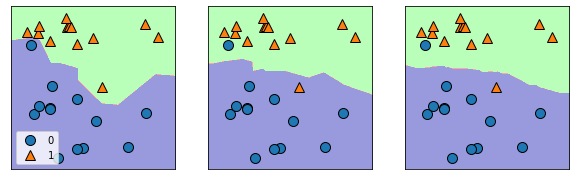
k값을 1, 3, 9를 주어서 각 데이터 분류가 어떤 식으로 되는지 확인 할 수 있습니다.
오늘은 최근접 이웃에 대해 알아 보았습니다. K-NN또한 파이프 라인을 이용하여 최적의 값을 구할 수 있으니 배운것을 복습할 겸 연습해 보는것도 좋은 방법이라고 생각합니다.
😁 power through to the end 😁
