관련논문 - all you need is attention
구현코드 - 해당코드는 Sin함수 등의 데이터를 생성하여 학습하였습니다.
- Dot-Product(내적)
- MultiHead
Nadaraya-Watson Kernel Regression (1964)
- Estimator
- Use given a kernel to get weights of labels according to location x
- Define
- query : (예측하고 싶은 값)
- keys : ( data_input )
- values : ( data_output )
- Kernel
- 가우시안 커널
- 가우시안 데이터 포인트는 0에 수렴
- 트라이앵글 커널을 사용하면 데이터 포인트를 0으로 만들 수는 있지만 이 방법으론 에서 분모가 0이 되어 계산이 되지 않는다.
- 즉 가우시안은 어떻게든 계산해서 답을 주긴 한다.
- 가우시안 커널
- Attention
- 공식
- 음수값인 베타를 곱해주는 이유는 지수함수는 양수에서 급격히 값이 변하기 때문에 차이를 줄여주기 위해서
- softmax를 사용
- 가우시안 방식에 비해 노이즈에 조금 더 민감
- 공식
- Self-Attention
- q,v,k가 같거나 q,k가 같은 것
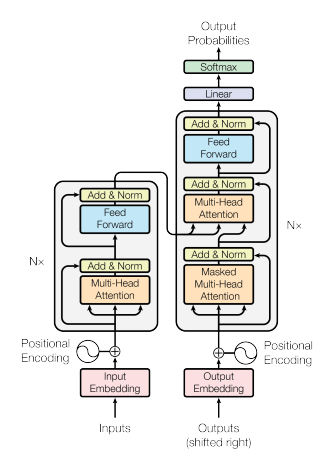
- Attention 메커니즘은 RNN계열 모델의 성능을 향상 시켰는데, 이것을 착안하여 만들어진 모델이 "Transformer"모델 이며, 기존 RNN의 단점인 반복 업데이트를 통해 연산 효율이 떨어지는 것을 해결한 모델입니다. 그리고 Self Attention이란 Attention을 자기 자신에게 취하는 것입니다. 이유를 알기 위해서 계산과정을 설명하겠습니다.
- Self Attention은 변수로 Query, Key, Value를 가지고 있으며, 이 세가지 변수는 시작 값이 동일합니다. 그렇기 때문에 self라고 불립니다. 최종적으로 학습을 통해 weight W값에 의해 세 변수는 값이 달라지게 됩니다. 즉, Self Attention의 세 변수는 처음에는 같지만 학습을 통해 최종 값이 달라진다라고 생각하시면 됩니다.
- 이해하기 편하시게 세가지가 다 같다고 했지만 Q와 K만 같은 경우도 있습니다.
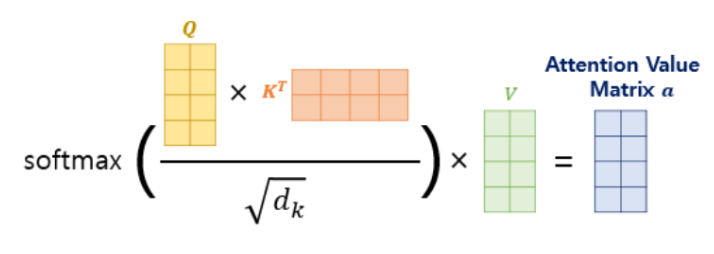
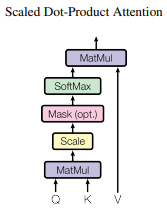
- Q와 K의 연관성을 계산하기 위해 내적을 해주고 이것을 Attetion score라고 부릅니다.
- Attetion scroe가 너무 커지게 되면 학습이 어려워 지기 때문에 나누어 스케일링을 해줍니다. 이것이 논문에서 설명하는 Scaled dot-product Attetion입니다.
- Scaled dot-product Attetion 후 softmax로 정규화를 진행합니다
- 마지막으로 계산된 score 행렬과 Value 행렬을 내적하면 Attention의 역할을 마무리 하게됩니다.

예시로 "I am a boy"가 있을 때 임베딩을 통해 위 행렬처럼 바뀌었다고 가정하고,
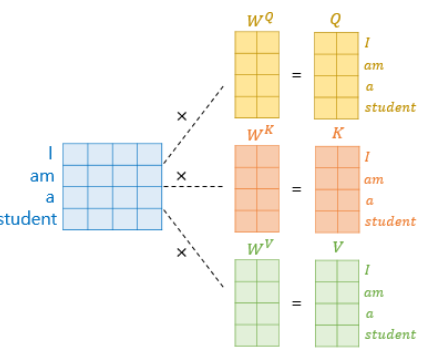
"I"의 임베딩이 [1,1,1,1]이라고 했을때 첫 Q,K,V는 각 각 Q_I,original,K_I,original,V_I,original라고 합니다. [1,1,1,1]이 된 이유는 Q,K,V가 같아야 Self Attention이기 때문에 이런식으로 가정하였습니다.
이때 학습된 weight를 WQ,WK,WV라고 할때 계산을 하면가 됩니다.
여기서 인 이유는 4차원(행렬)이라고 가정하였기 때문입니다.
이것을 반복해서 Self Attention을 하게 된다면
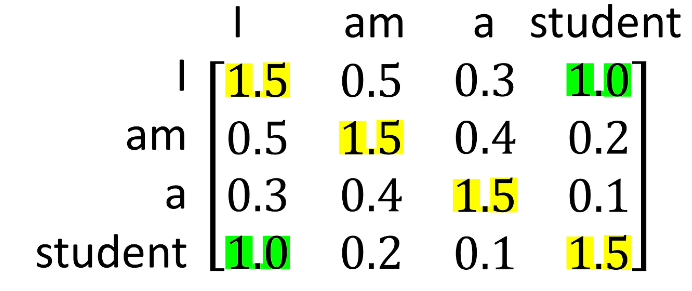
와 같은 결과가 나오고 I와 studet의 상관관계를 알 수 있습니다.
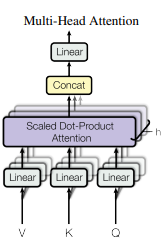
마지막으로 Multi Head Attention을 설명하자면, 이것을 병렬로 처리해서 계산하여 연산속도를 올리는 방법입니다.

AI (ML/DL) 학습