Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Github
프로젝트 페이지
참고문헌
25년 5월에 Data 없이 AI에게 자기 합습 시키는 방법이 나와 다루어 보려고합니다.
Absolute Zero 패러다임은 외부 데이터 없이 모델이 스스로 학습할 작업을 생성하고 해결하는 자기 주도 학습 방식입니다.
즉, 사람이 설계한 데이터셋 없이도 모델이 문제를 만들고 풀면서 추론 능력을 향상시키는 새로운 접근입니다.
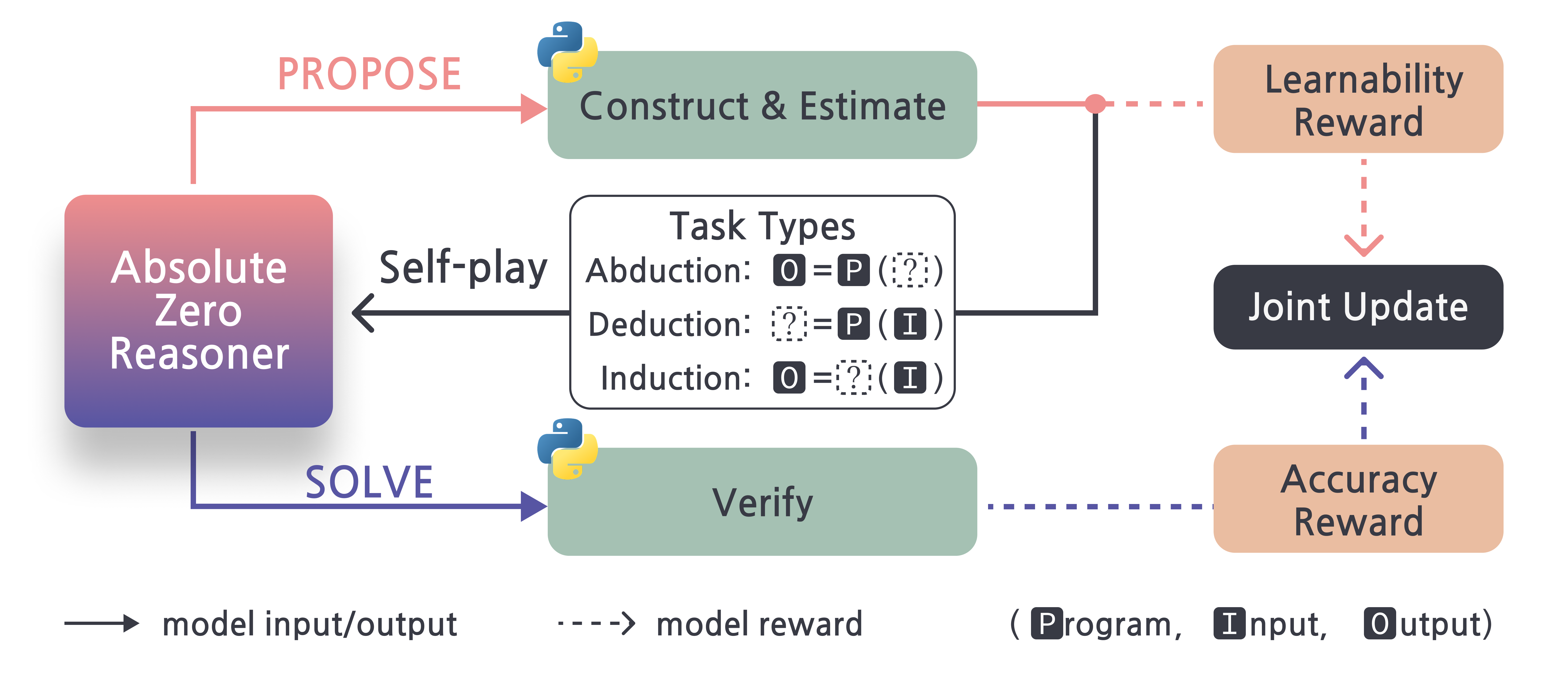
핵심 개념: Absolute Zero 패러다임
Absolute Zero는 모델이 학습 가능한 작업을 스스로 생성하고 해결하는 자기 주도 학습 방식입니다.
- 외부의 라벨링된 데이터가 없어도 성능이 향상됩니다.
- 모델이 직접 문제를 만들고 풀면서 추론 능력을 키웁니다.
AZR의 구조: Proposer, Solver, Verifier
| 구성 요소 | 역할 |
|---|---|
| Proposer | 학습 가능한 문제를 생성 |
| Solver | 문제를 해결 |
| Verifier | 문제와 해답의 유효성을 검증 |
학습되는 작업 유형
- Deduction (연역)
: 프로그램 + 입력 → 출력을 추론 - Abduction (가추)
: 프로그램 + 출력 → 가능한 입력을 추론 - Induction (귀납)
: 여러 입력-출력 쌍 → 프로그램을 합성
학습 전략: 강화 학습 기반 보상
AZR은 다중 작업 학습을 위해 TRR++ (Task-Relative REINFORCE++)라는 보상 추정기를 사용합니다.
- r: 해당 step 또는 episode에서 받은 실제 보상값
- : 특정 작업(task)과 역할(role)에 대한 보상의 평균값
- : 해당 task-role 조합의 보상 표준편차
- : 정규화된 advantage (보상 이득)
Proposer 보상 설계
너무 쉽거나 너무 어려운 문제는 보상이 없습니다.
Solver가 적당히 성공하는 문제를 만들면 보상을 많이 받습니다.
- : Proposer가 받는 보상
- : 해당 문제가 Solver에 의해 해결된 평균 비율
(즉, 여러 시도 중 Solver가 얼마나 자주 성공했는지를 나타냄)
동작 원리:
- Solver가 항상 틀리면 :
- Solver가 항상 맞히면 :
- Solver가 약 50% 확률로 맞히면 :
작업 유효성 검증
- 무결성: 코드 실행 여부
- 안전성: 무한 루프/치명적 오류 여부
- 결정론적 실행: 동일한 입력 → 항상 동일한 출력
비결정론적 프로그램은 실행 결과가 매번 달라질 수 있으므로 배제
- 𝑝 : 생성된 프로그램
- : 결정론적 프로그램의 집합
- 𝑖∈𝐼: 입력 집합
- : 동일 입력 𝑖에 대해 프로그램 𝑝를 𝑗번째 실행한 결과
실험 결과 및 특징
- 외부 데이터 없이도 성능 향상이 가능함을 입증
- 기존 제로샷 모델보다 추론 능력 우위
- 다양한 LLM 구조와 호환 가능 (예: Mistral)
- 모델 크기 증가 시 선형 성능 향상
- 제안자가 난이도 조절을 자동으로 학습
요약
- 인간의 레이블이 없어도 AI가 스스로 문제를 만들고 풀며 학습
- 추론 능력 향상 중심의 새로운 학습 프레임워크
- 향후 코드 생성, 수학 추론 등 고난이도 작업에 확장성 기대

AI (ML/DL) 학습