경사 하강법
키워드
- 배치 경사 하강법
- 확률적 경사 하강법
- 미니배치 경사 하강법
- 점진적 학습 + 온라인 학습
- 에포크
- 손실 함수
- 로지스틱 손실 함수
- 이진 크로스엔트로피 손실 함수
- 크로스엔트로피 손실 함수
- 에포크와 과대/과소적합
- 조기 종료
- 타당성 검사
- 힌지 손실
- 서포트 벡터 머신
- 미분
에포크
Epoch
사전적인 뜻은 (중요한 사건·변화들이 일어난) 시대
훈련 데이터셋에 포함된 모든 데이터들이 한 번씩 모델을 통과한 횟수를 뜻한다.
에포크가 10회라면 학습 데이터 셋 전체를 10회 모델에 학습 시켰다는 뜻이다.
한 번의 학습에 모든 학습 데이터 셋을 사용하면 발생하는 문제들
- 메모리가 과도하게 필요해진다
- 학습 한 번에 계산돼야 할 파라미터(가중치) 수가 지나치게 많아져서 계산 시간이 과도하게 오래 걸린다.
(만년필잉크의 데이터 분석 참고)
에포크와 과대/과소적합
적은 에포크 횟수를 훈련한 모델은 훈련 세트와 테스트 세트에 잘 맞지 않는 과소적합된 모델일 가능성이 높다.
많은 에포크 횟수를 훈련한 모델은 훈련 세트에 너무 잘 맞아 테스트 세트에는 오히려 점수가 나쁜 과대적합된 모델일 가능성이 높다.
과대적합이 시작하기 전에 훈련을 멈추는 것을 조기 종료(early stopping)라고한다.
타당성 검사(sanity check)
대량의 데이터를 분석 및 학습시키기 이전에 데이터의 일부를 이용하여 타당성 검사를 할 필요가 있다.
대량의 데이터를 모두 작업하기 위한 개발은 많은 노력과 시간이 들어가기 때문에 타당성 검사를 고려해야 한다.
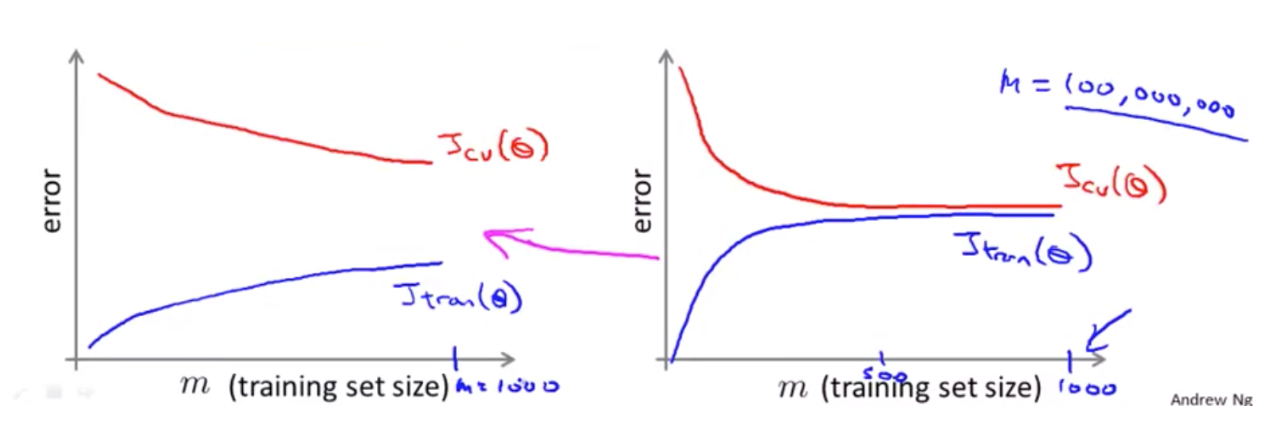
예를들어 위 이미지는 1억 건의 데이터 중 1000건의 데이터로 타당성 검사를 한 결과라고 가정해보자.
왼쪽의 그래프처럼 1000건을 학습했을 때 아직 좁혀질 가능성이 보인다면, 좀 더 학습 세트를 추가하여 정확도를 높일 수 있을 것이다.
반대로 오른쪽의 그래프처럼 500건과 1000건의 학습 결과가 비슷하다면 1억건을 해도 크게 달라질 것이 없을 것이다.
타당성 검사를 하지 않았다면 굳이 학습시키지 않아도 될 99999000개의 샘플을 학습하는 비용과 시간이 소요된다.
점진적 학습 / 온라인 학습
앞서 훈련한 모델을 유지하면서 새로운 데이터가 들어올 때마다 학습하는 방식.
훈련에 사용한 데이터를 모두 유지할 필요가 없다.
대표적인 점진적 학습 알고리즘이 확률적 경사 하강법이다.
손실 함수
loss function
머신러닝 알고리즘이 얼마나 엉터리인지를 측정하는 기준이다.
비용함수(cost function)이라고도 한다.
손실 함수를 개발자가 직접 만드는 일은 거의 없다.
이미 문제에 잘 맞는 손실 함수가 개발되어 있다.
- 이진 분류 -> 이진 크로스엔트로피 손실 함수
- 다중 분류 -> 크로스엔트로피 손실 함수
손실 함수를 직접 계산하는 일도 드물다.
머신러닝 라이브러리가 처리해준다.
로지스틱 손실 함수
다중 분류를 위한 손실 함수인 크로스엔트로피 손실 함수를 이진 분류 버전으로 만든 것이다.
크로스엔트로피 손실 함수
크로스 엔트로피 손실(Cross Entropy Loss)은 머신 러닝의 분류 모델이 얼마나 잘 수행되는지 측정하기 위해 사용되는 지표입니다.
Loss(또는 Error) 0은 완벽한 모델로 0과 1 사이의 숫자로 측정됩니다. 일반적인 목표는 모델을 가능한 0에 가깝게 만드는 것입니다.
(Weights&Biases 사이트 참고)
미분 / 편미분
깨봉 수학 유튜브
https://www.youtube.com/watch?v=EoUCOihCFG0&list=PLhOmNDKbGFE4ed4fa44lFx0lHCDYfUDGK
경사하강법 미분
https://youtu.be/GEdLNvPIbiM
신경망 알고리즘과의 관계
신경망은 일반적으로 많은 데이터를 사용하기 때문에 한 번에 모든 데이터를 사용하기 어렵다.
또한 모델이 매우 복잡하기 때문에 수학적인 방법으로 해답을 얻기 어렵다.
그래서 신경망 모델은 확률적 경사하강법이나 미니배치 경사 하강법을 사용한다.
배치 경사 하강법
Batch의 개념은 Total Trainning Dataset
즉 모든 학습데이터를 의미한다.전체 데이터 셋에 대해 에러를 구한 뒤 기울기를 한번만 계산하여 모델의 파라미터를 업데이트 하는 방식이다.
전체 데이터에 대해서 업데이트가 한번에 이루어지므로 업데이트 횟수 자체는 적다.
그러나 한번의 업데이트에 모든 Trainning Data Set을 사용하므로 계산 자체는 오래 걸린다.
GPU를 활용한 병렬처리에 유리하다.
하지만 전체 학습데이터에 대해 한번에 처리를 해야하므로 많은 메모리가 필요하다.
(aoc55 참고)
방대한 데이터셋을 처리하기 위해서는 연산 문제가 항상 따라다닌다.
학습 세트 크기가 m = 3억이라고 가정해보자.
이것은 오늘날 매우 현실적인 데이터셋의 크기다.
선형 회귀 모델 또는 로지스틱 회귀 모델이 데이터를 학습한다고 가정하고 경사 하강법을 활용한다면, 경사를 계산하기 위한 미분항의 m이 3억이라면 3억 번 합산한 후 하나의 스텝(에포크?)만 움직인다. 경사 하강법의 한 스텝을 계산하기 위해 3억 개가 넘는 항목을 합산하는 계산 비용이 엄청나다.
연산비용이 급격하게 증가하고 매우 비싸다.알고리즘은 미분항을 계산하기 위해 3억 개의 기록을 모두 컴퓨터 메모리로 불러들여야 한다.
하지만, 모든 데이터 셋을 메모리에 저장할 수 없기 때문에 메모리에서 기록을 넣고 삭제하는 과정을 반복해야한다.
알고리즘이 최적화 목표인 전역 최소값에 수렴하기 위해 너무 오랜 시간이 걸린다.
(데이터 사이언티스트가 되자 참고)
즉, 데이터 셋이 많아지면,
1. 미분항을 계산하기 위한 연산비용이 크게 증가한다.
2. 추가로 3억개의 미분항을 동시에 합산해야하니 메모리에 올려야하는데, 다 올라가지 않아서 올리고 합산하고 빼고 올리고 합산하고 빼고 하는 과정 때문에 더 느려진다.
확률적 경사 하강법
확률적 경사 하강법은 훈련 세트에서 랜덤하게 하나의 샘플(또는 한 묶음의 샘플)을 선택하여 가파른 경사를 조금 내려간다.
그다음 훈련 세트에서 랜덤하게 또 다른 샘플 하나를 선택하여 경사를 조금 내려간다.
이런 식으로 전체 샘플을 모두 사용할 때까지 계속한다.(혼공머신 201 참고)
확률적 경사 하강법의 첫 단계는 데이터 셋을 무작위로 섞는것.
즉,학습 예제를 재정렬 하는 것이다.두번째 단계가 확률적 경사 하강법의 핵심이다.
배치 경사 하강법은 i=1부터 m(3억개)까지 반복 연산한 다음 파라미터를 업데이트 한다. 그 이후 다음 업데이트를 수행한다.-> 에포크와 파라미터 업데이트의 주기가 같다.
하지만 확률적 경사하강법은, 학습 예제를 스캔하고, 첫번째 학습 예제에 적합한 비용 함수(cost func)를 계산하고 경사 하강법 스텝을 약간 움직인다.
즉, 첫번째 학습 예제의 비용 함수를 최소화한 후 파라미터를 업데이트한다.
그 다음 두번째 학습 예제의 비용 함수를 최소화한 후 파라미터를 업데이트한다.
그 다음 세번째 학습 예제로 이동한다.
마지막 예제까지 이 작업을 반복한다.-> 배치 경사 하강법과 마찬가지로 전체 데이터를 학습하지만, 1회의 에포크동안 여러번의 파라미터 업데이트를 한다.
경사 하강법은 모득 학습 예제 m에 대해 미분항을 계산하지만, 확률적 경사 하강법은 단일 학습 예제에 대한 미분항을 계산한다.
즉, 전역 최소값에 다다르기 위해 모든 학습 예제를 합산할 필요 없이 단일 학습 예제를 이용하여 약간 수정하는 것이다.
배치 경사 하강법은 전역 최소값에 도달하기 위해 합리적으로 직선 궤도를 따라 움직이는 경향이 있다.
확률적 경사 하강법은 무작위로 초기화한 지점에서 시작한다. 각 스텝마다 파라미터 값을 초기화 한다.
옳은 방향으로 가기도 다른 방향으로 가기도 하면서 결과적으로 전역 최소값 부근으로 이동힌다.
확률 경사 하강법은 배치 경사 하강법과 달리 한 점에 수렴하지 않고 전역 최소값에 가까운 영역에서 배회한다.
즉, 전역 최소값에 도달해도 머무르지 않는다. 그러나 일반적으로 전역 최소값에 가까운 파라미터를 얻기 때문에 기본 목적을 충분히 수행한다고 보여진다.
확률적 경사 하강 알고리즘은 훨씬 더 큰 데이터 셋을 빠르게 처리할 수 있다.
-> 이 말 뜻은 데이터를 모두 처리한다는 뜻이다.
배치 경사 하강 알고리즘과의 차이는 합산이 없고, 오직 하나의 학습 예제에 대해서 수행한다.
(데이터 사이언티스트가 되자 참고)
미니배치 경사 하강법
확률적 경사 하강법이 스텝마다 하나의 샘플을 사용하는 반면, 미니배치 경사 하강법은 2~100개 정도의 작은 배치를 이용한다.
예를들어 10개의 샘플을 가진 미니배치를 순차적으로 학습한다면, 10개씩 학습 예제를 사용하므로 평균 오차의 제곱을 구하기 위해 1/10로 나눈다.
확률적 경사 하강법과 마찬가지로 미니배치를 학습하면 파라미터를 업데이트하고 다음 미니배치를 학습한다.
(데이터 사이언티스트가 되자 참고)
미니배치 경사 하강법이 확률적 경사 하강법보다 빠를 수 있는 상황
미니배치 경사 하강법은 벡터화 구현이 좋은 경우에는 확률적 경사 하강법보다 성능이 우수하다.
10 개 이상의 예제를 합산하는 것 대신 벡터화 구현으로 수행한다면 10 개 예제에 대한 계산을 부분적으로 병렬화하여 계산할 수 있다.
즉, 적절한 벡터화를 사용하여 나머지 항을 계산하면 좋은 선형 대수 라이브러리를 부분적으로 사용하면서 b 예제에 대한 기울기 계산을 병렬화할 수 있다.
반면에 단일 예제만 계산하는 확률적 경사 하강법은 한 번에 하나의 예제만 보기 때문에 병렬화를 할 수 없다.
미니배치 경사 하강법의 한 가지 단점은 파라미터 b를 추가하는 것이다.
미니배치의 크기는 결정하기 위해 데이터를 조작해야 할 시간이 필요할 수 있다.
-> 사람이 건들여야할 부분이 있다는 뜻인 듯
그러나 벡터화 구현이 좋다면 확률적 경사 하강법보다 더 빠르게 실행할 수 있다.
(데이터 사이언티스트가 되자 참고)
참고 사이트
https://angeloyeo.github.io/2020/08/16/gradient_descent.html
데이터 사이언티스트가 되자
https://brunch.co.kr/@linecard/559
aoc55님 블로그
https://aoc55.tistory.com/48
만년필 잉크의 데이터분석 블로그
https://gooopy.tistory.com/68
욱이명님 블로그
https://ukb1og.tistory.com/22
Weights&Biases
https://wandb.ai/wandb_fc/korean/reports/---VmlldzoxNDI4NDUx
