UTF-8 ?
Unicode Transformation Format - 8bit
아스키(ASCII) ?
American Standard Code for Information Interchange
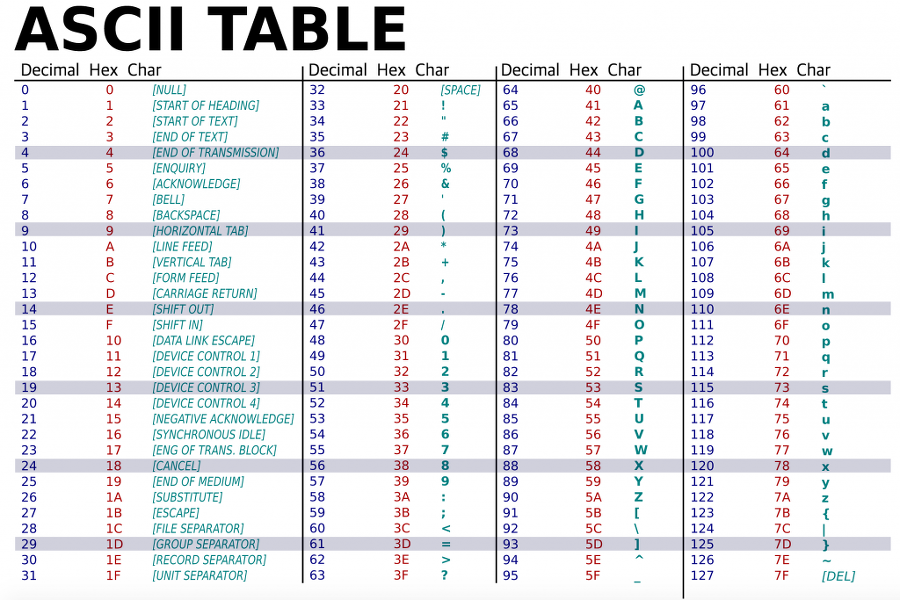
ANSI ?
8비트로 확장한 아스키코드
유니코드 ?
전 세계의 모든 문자를 컴퓨터에 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준
유니코드 확인하기 (파이썬)
print(ord("A"))
# 65 (1바이트)
print(ord("z"))
# 122 (1바이트)print(ord("ㄱ"))
# 12593 (3바이트)
print(ord("힣"))
# 55203 (3바이트)UTF-8에서 한글이 3바이트 인 이유
'A'부터 'z'까지는 65~122이므로 1바이트(0~255)로 처리가 가능하다.
그런데 'ㄱ'부터 '힣'까지의 한글은 2바이트(0~65535) 내에서 처리가 가능할 것 같은데 왜 3바이트 일까?
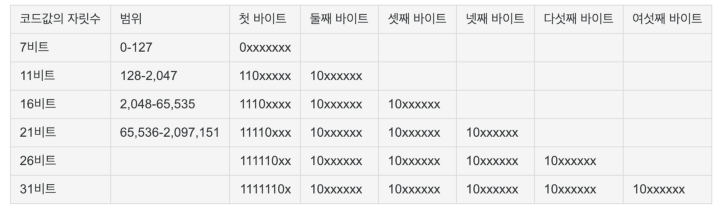
정답은,
가변인코딩 방식이기 때문이다.
위 표처럼, 첫바이트는 코드값의 자릿수와 데이터를 같이 표현한다.
UTF-8 인코딩인 것을 명시하기 위해서 비트 칸을 차지하기 때문에 2바이트가 아닌 3바이트를 이용해야 한다.
2048~65535의 유니코드는 바이트를 3개 차지하는 것을 확인 할 수 있다.
참고자료
위키백과
https://ko.wikipedia.org/wiki/%EC%9C%A0%EB%8B%88%EC%BD%94%EB%93%9C

티스토리 블로그 https://ondolroom.tistory.com/