[selenium] 크롤링 오류 AttributeError
🚫 문제 발생
Traceback (most recent call last):
File "crawler.py", line 134, in <module>
quiz_data = crawled_quiz()
File "crawler.py", line 113, in crawled_quiz
"explain": explain.text.replace("\xa0", " "),
AttributeError: 'NoneType' object has no attribute 'text'20개 단위로 크롤링을 진행하면서 DB 저장을 테스트 했을 땐 발생하지 않는 문제였었는데,
전체 데이터를 크롤링해오는 과정에서 이런 오류가 발생했다.
🔎 해결 시도
정확히 어떤 문제에서 코드가 멈추는지 잡기 위해서
for문 마지막에 print문을 넣어 점검해보았다.
# crawler.py
for i in range(1, 1747):
...
for handle in driver.window_handles:
if handle != current_tab_handle:
...
print(f"{i}번째 데이터!")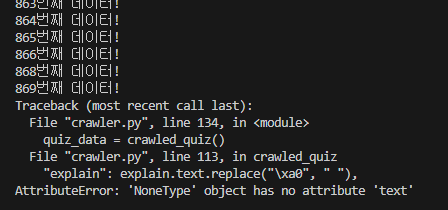
869번째 데이터를 수집하는 도중에 오류가 생겼으니
넓게 잡아 868번부터 872번까지 번호를 수집해보자!
코드가 충돌나지 않게 임의의 python 파일을 만들어주었다.
# test.py
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# chromedriver 실행 파일의 경로
chromedriver_path = "F/nbc/chromedriver_win32/chromedriver"
# Service 객체 생성
service = Service(chromedriver_path)
# Chrome 드라이버 생성 및 서비스 설정
driver = webdriver.Chrome(service=service)
driver.implicitly_wait(3)
driver.get(
"https://wquiz.dict.naver.com/list.dict?service=krdic&dictType=koko&sort_type=3&group_id=1"
)
# 기다리는 객체 생성
wait = WebDriverWait(driver, 10)
while True:
open_btn = driver.find_element(By.ID, "btn_quiz_more")
# 얼만큼 더보기를 눌러줄지는 퀴즈 더보기 옆의 숫자를 수정해주면 됨.
# 예시 : 30만큼 더보기를 보고싶다면 퀴즈 더보기 30 / 1,746
if open_btn.text == "퀴즈 더보기 880 / 1,746":
break
open_btn.click()
current_tab_handle = driver.current_window_handle
for i in range(868, 872):
my_problem = driver.find_element(
By.CSS_SELECTOR, f"#content > ul.quiz_list > li:nth-child({i}) > a"
)
new_link = my_problem.get_attribute("href")
print(new_link)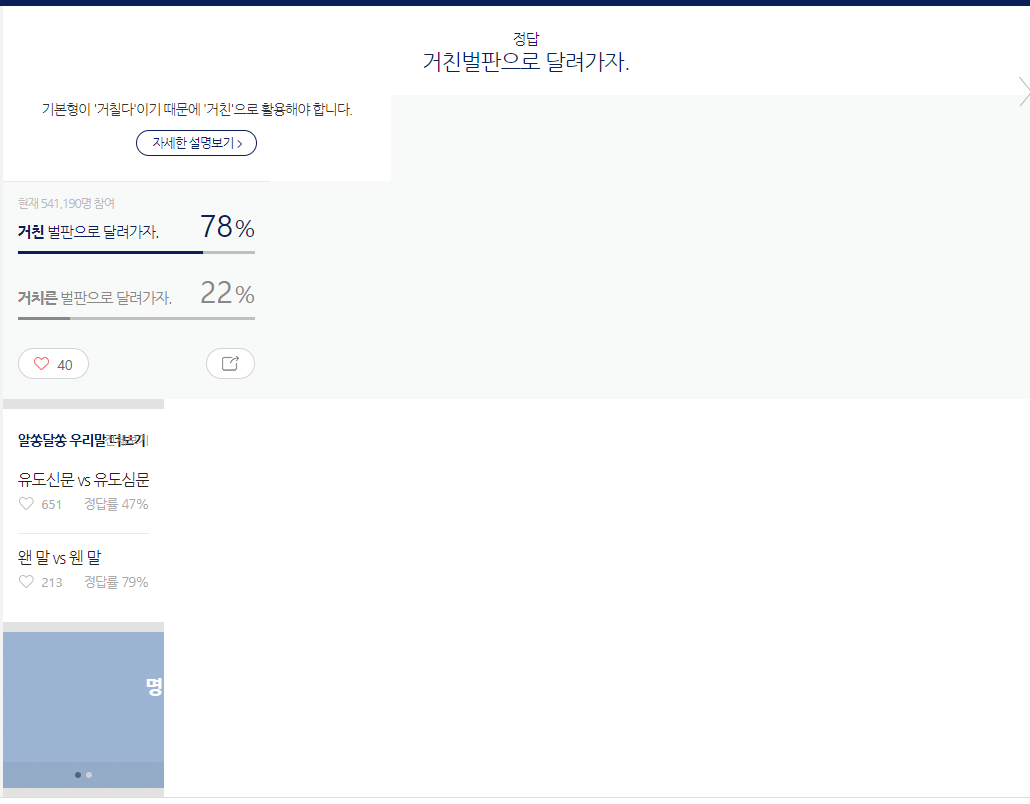
확인해보니 이 녀석이 문제였다.
html 구조가 다른 녀석들이랑 달라서,
selector 복사를 했을 때 형태가 달랐다!
✅ 문제 해결
이럴 경우에는 try except를 써서 오류부분을 지정해주면 되지 않을까?
# crawler.py
for i in range(1, 1747):
my_problem = driver.find_element(
By.CSS_SELECTOR, f"#content > ul.quiz_list > li:nth-child({i}) > a"
)
title = my_problem.find_element(By.TAG_NAME, "p").text
new_link = my_problem.get_attribute("href")
driver.execute_script("window.open(arguments[0]);", new_link)
for handle in driver.window_handles:
if handle != current_tab_handle:
...
try:
# 딕셔너리에 순서대로 저장
quiz = {
"title": title,
"explain": explain.text.replace("\xa0", " "),
"rate": rate.text.replace("%", ""),
"option": [
{"content": correct_option.text, "is_answer": True},
],
}
# 오답이 여러개일 경우, option에 순서대로 append
for wrong in wrong_options:
quiz["option"].append(
{"content": wrong.text, "is_answer": False}
)
except:
quiz = {
"title": "오류가 발생했습니다",
"explain": f"링크 확인 : {new_link}",
"rate": 0,
"option": [{"content": "", "is_answer": True}],
}
print(f"{i}번째 문제에서 오류 발생!")
data.append(quiz)이렇게 해주니까 오류가 몇번째 문제에서 발생하는지,
그리고 그 문제의 데이터도 건너뛰지 않고 무사히 저장되었다!
이렇게하면, 데이터베이스에서 찾아서 수정만 해주면 된다!

개발 공부 하는 비전공자 새내기. 꾸준히 합시다!