웹 스크래핑이란?
웹 스크래핑(web scraping)은 웹 페이지에서 우리가 원하는 부분의 데이터를 수집해오는 것으로 크롤링(crawling)이라는 용어로 혼용해서 사용합니다.
1. 파이썬 기초 문법
변수 & 기본 연산
a = 3
b = a
a = a + 1
num1 = a*b
num2 = 99
자료형
name = 'bob'
num = 12
is_number = True
- 리스트 형(JavaScript의 배열형과 동일)
a_list = []
a_list.append(1)
a_list.append([2,3])
people = [{'name':'bob','age':20},{'name':'carry','age':38}]
person = {'name':'john','age':7}
people.append(person)
조건문
if age > 20:
print('성인입니다')
else:
print('청소년이에요')
is_adult(30)
반복문
- 파이썬에서의 반복문은 리스트의 요소들을 하나씩 꺼내 쓰는 형태 -> 무조건
리스트와 함께 쓰임!
fruits = ['사과','배','배','감','수박','귤','딸기','사과','배','수박']
count = 0
for fruit in fruits:
if fruit == '사과':
count += 1
print(count)
people = [{'name': 'bob', 'age': 20},
{'name': 'carry', 'age': 38},
{'name': 'john', 'age': 7},
{'name': 'smith', 'age': 17},
{'name': 'ben', 'age': 27}]
for person in people:
print(person['name'], person['age'])
for person in people:
if person['age'] > 20:
print(person['name'], person['age'])
그 밖의 내장 함수
txt = 'sparta@gmail.com'
result = txt.split('@')[1].split('.')[0]
print(result)
txt = 'sparta@gmail.com'
result = txt.replace('gmail','naver')
print(result)
2. 파이썬 패키지
- 패키지: Python에서 모듈(일종의 기능들 묶음)을 모아 놓은 단위
- 라이브러리: 패키지의 묶음
- 가상환경(virtual environment): 프로젝트별로 패키지들을 담을 공구함
3. dload와 selenium을 이용한 이미지 저장
- dload 라이브러리: URL로 부터 파일 다운로드를 해주는 패키지
import dload
dload.save("https://spartacodingclub.kr/static/css/images/ogimage.png", 'sparta.png')
- selenium 패키지: 브라우저 제어 가능하게 해주는 패키지
from selenium import webdriver
driver = webdriver.Chrome('chromedriver')
driver.get("http://www.naver.com")
- bs4 라이브러리 (BeautifulSoup): HTML 및 XML 파일에서 원하는 데이터를 손쉽게 Parsing 할 수 있는 라이브러리
from bs4 import BeautifulSoup
from selenium import webdriver
import time
driver = webdriver.Chrome('chromedriver')
driver.get("https://search.daum.net/search?w=img&nil_search=btn&DA=NTB&enc=utf8&q=%EC%95%84%EC%9D%B4%EC%9C%A0")
time.sleep(5)
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
thumbnails = soup.select("#imgList > div > a > img")
for thumbnail in thumbnails:
src = thumbnail["src"]
print(src)
driver.quit()
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
soup.select('태그명[속성="값"]')
soup.select_one('위와 동일')
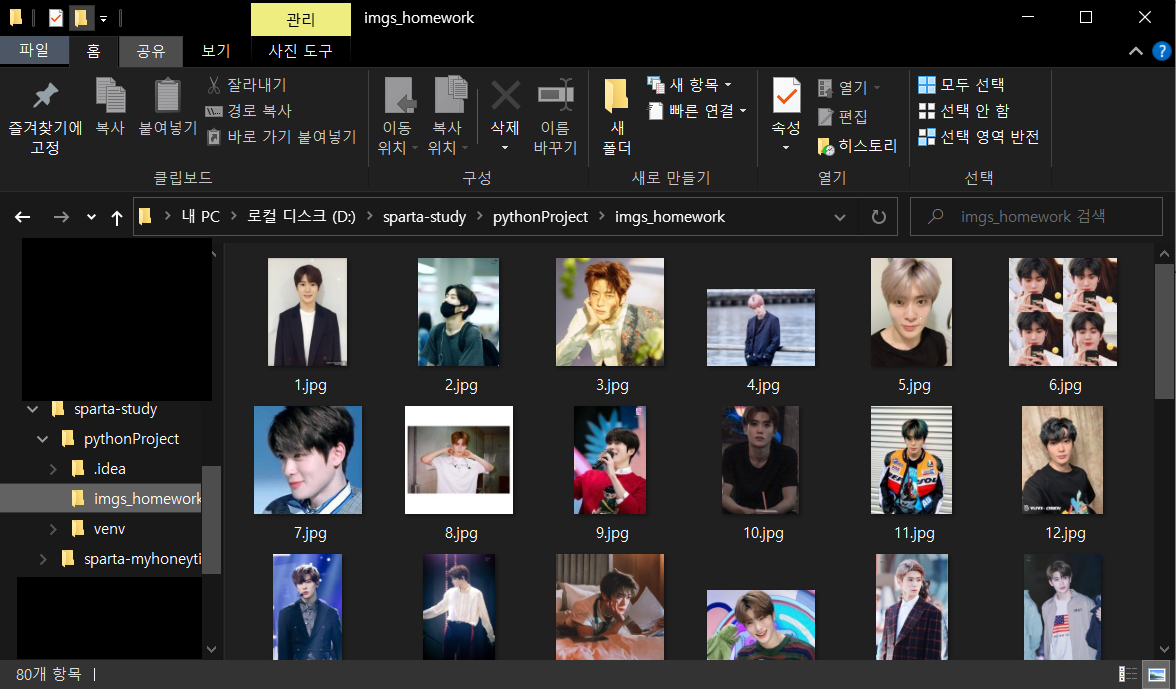
다음에서 연예인 이미지 검색해 저장해보기
import dload
from bs4 import BeautifulSoup
from selenium import webdriver
import time
driver = webdriver.Chrome('chromedriver')
driver.get("https://search.daum.net/search?nil_suggest=btn&w=img&DA=SBC&q=nct+%EC%9E%AC%ED%98%84")
time.sleep(5)
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
thumbnails = soup.select("#imgList > div > a > img")
i=1
for thumbnail in thumbnails:
src = thumbnail["src"]
dload.save(src, f'imgs_homework/{i}.jpg')
i+=1
driver.quit()
- 결과