노션 정리본 : https://mint-truck-226.notion.site/KMP-6f2b91cc1f1144fba8834cdf1299addd
1. KMP란?
- 문자열 검색을 매우 빠르게 해 주는 알고리즘
- made by 3명의 개발자 : Knuth-Morris-Pratt
- James H. Morris가 먼저 생각했고
- 몇 주 후, (면식이 없는) Donald Knuth가 “오토마타 이론”에서 이와 비슷한 알고리즘을 발견하고
- Morris와 Vaughan Pratt가 1970년에 기술 보고서를 발표했고
- 세 사람은 1977년 이 알고리즘을 공동으로 발표했다.
⇒ 즉, 특정 패턴이 주어졌을 때 전체 문자열을 빠르게 검색하여 그 패턴이 어디에 등장하는지 찾아주는 알고리즘
시간복잡도 : O(n+m) > 완전 탐색은 O(nm)이다..
2. KMP의 원리
1) 주어진 패턴에 대해
skip배열을 만든다.
skip은 패턴의 각 인덱스마다 접두사와 접미사가 동일한 갯수2) skip 배열을 활용하여 패턴의 등장 위치를 찾는다. (빠르게)
※ 먼저 알아야 하는 것!
- 접두사(prefix) / 접미사(suffix)

- pi 배열 (퀴즈 코드는 skip으로 사용)
: 주어진 문자열의 부분 문자열 중, prefix == suffix가 되는 부분 문자열 중 가장 긴 것!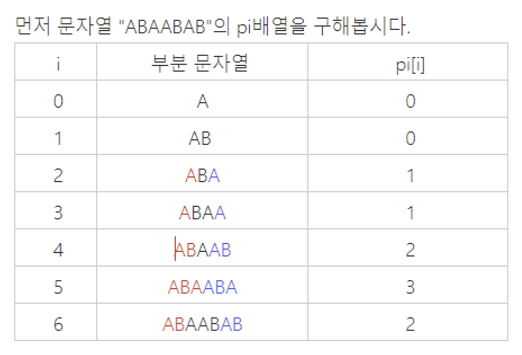
자, 드가자-!
주어진 퀴즈는 다음과 같았다.
kmp_match.py 코드를 실행할 때,
s1 = "abcabgabcaabcabcabgabcaef"
s2 = "abcabgabcae"
가 입력으로 주어지면
skip 배열과 count 값이 어떻게 될 지 맞춰 보시면 됩니다.
kmp_match.py는 책에 있는 걸 그대로 옮겨 오되, print 문만 추가했습니다.1) 패턴 분석 : 주어진 패턴에 대해 skip 배열을 만든다. → O(n)
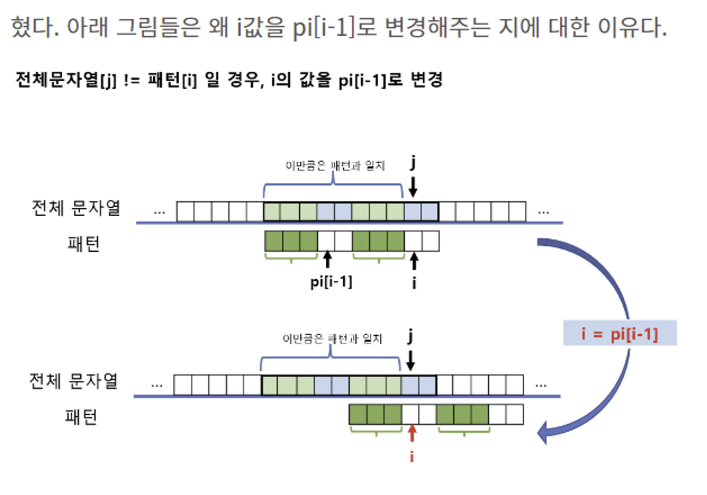
※ 잠깐! 왜 접두사 접미사가 같은지를 굳이..알아야 할까?
: 동일성이 보장되는 구간을 찾음으로써 불필요한 반복을 줄일 수 있다!
즉, 25번째 문자까지 같았는데, 26번째에..! 하나 틀렸다고 다시 1번째로 돌아가지 않고 → 25번째 문자까지 접두==접미 같았던 부분이 몇 개였는지 파악해서, 접두+1 위치부터 탐색하는 게 더 빠르고 낭비도 덜하다!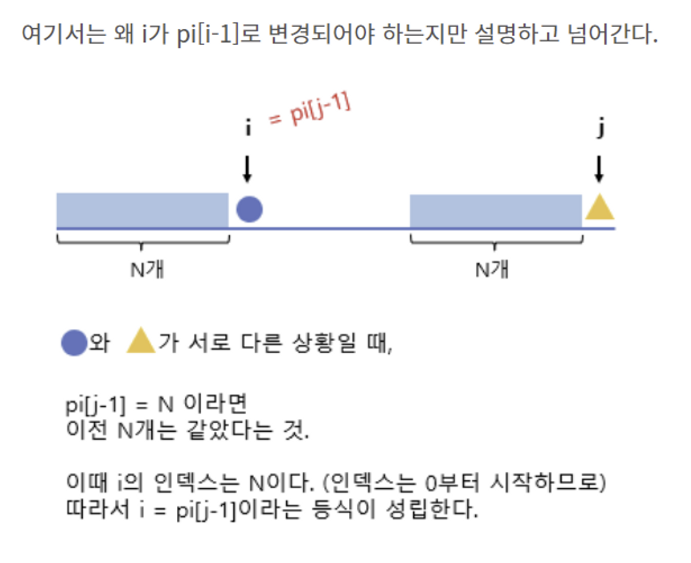
def kmp_match(txt: str, pat: str) -> int:
pt = 1
pp = 0
skip = [0] * (len(pat) + 1)
skip[pt] = 0
while pt != len(pat):
if pat[pt] == pat[pp]:
pt += 1
pp += 1
skip[pt] = pp
elif pp == 0:
pt += 1
skip[pt] = pp
else:
pp = skip[pp]
... (이하 생략)< 필요한 것 >
skip배열의 1번째 값은 무조건 0이다. (한 글자짜리는 접두/접미사 X)- 두 개의 포인터
pt와pp가 사용된다.- pt : 현재 어디를 보고 있는지 (탐색 위치) → (접미의 마지막이 될 수 있는) 몇 번째 글자
- pp : 현재 어디까지 일치하는지 (접두==접미 동일한 부분)에서
접두 마ㅈㅣ노선
⇒ ?? pp - 1: 접두 마ㅈㅣ노선 / pt + 1 : (pp가 0이 아니라면 아직) 접미 마ㅈㅣ노선?
< 동작 >
주어진 패턴 pat에 대해, [pt]와 [pp]를 비교한다. (패턴 끝까지)
▶ “패턴 pat에서 n번째 위치까지는 접두사와 접미사가 동일한 부분이 몇 개이다”를 파악해서, 다음 파트에서 활용할 거다!
- 같으면 → pt +1 / pp + 1 ▶ 즉, pt 부분까지는 pp 개의 접두사와 접미사가 동일하다!
- 다르면
- pp = 0 → pt + 1 / skip[pt] = pp ▶ (pre와 suf 동일한 부분이 없으므로) pp는 0으로 냅두고, 탐색 위치 pt만 한 칸 옆으로 옮긴다. ▶ skip[pt]는 “패턴의 pt번째 문자에서 접두와 접미가 같은 게 몇개가 되는가!”를 의미하는데, 아직 없으므로 0인 pp를 할당한다.
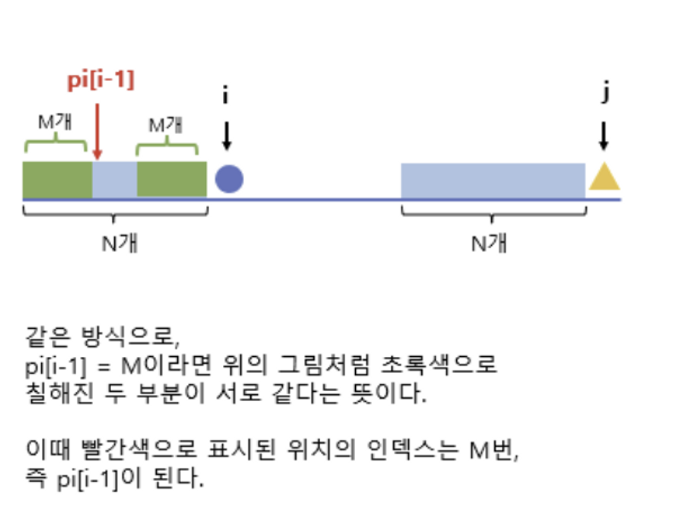
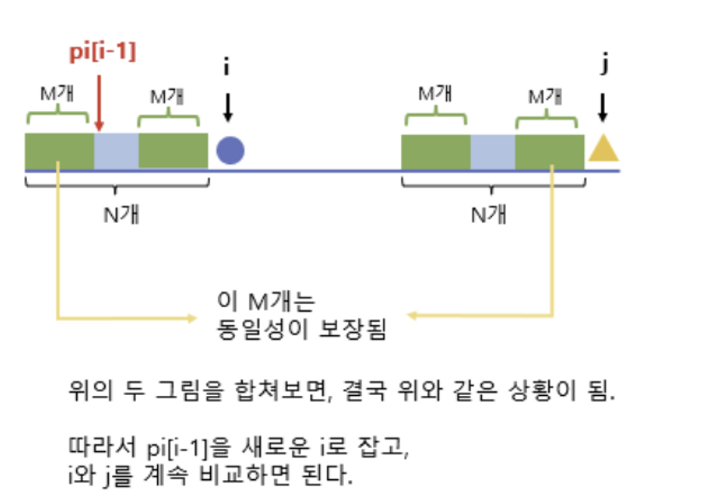
- pp ≠ 0 → pp = skip[pp] ★★★★★★★? ▶ 그 전까지 pre와 suf가 동일했던 부분이 있었다는 얘기이니까, 마ㅈㅣ노선이었던 접두 부분 바로 뒤로 이동시킨다. (앞에서 아무리 여러 번 동일했더라도, 지금 문자 하나 때문에 다 망가지므로..)
- pp = 0 → pt + 1 / skip[pt] = pp ▶ (pre와 suf 동일한 부분이 없으므로) pp는 0으로 냅두고, 탐색 위치 pt만 한 칸 옆으로 옮긴다. ▶ skip[pt]는 “패턴의 pt번째 문자에서 접두와 접미가 같은 게 몇개가 되는가!”를 의미하는데, 아직 없으므로 0인 pp를 할당한다.
2) 패턴 / 문자열 비교 : skip 배열을 활용하여 패턴의 등장 위치를 찾는다. (빠르게) → O(m)
- 앞서 만든 파이 배열이 여기서 어떻게 사용될까?
pt = pp = 0
count = 0
while pt != len(txt) and pp != len(pat):
if txt[pt] == pat[pp]:
pt += 1
pp += 1
elif pp == 0:
pt += 1
else:
pp = skip[pp]
count += 1
print("count: " + str(count))
return pt - pp if pp == len(pat) else -1< 필요한 것 >
- 두 개의 포인터
pt와pp→ 모두 0으로 초기화!- pt : 전체 문자열을 탐색하는 포인터
- pp : 패턴을 탐색하는 포인터
count: 아깝..? (앞 부분은 동일하다가, 뜬금 없이 틀린 것) → 점프!!! (필수적인 건 아니다.)
< 동작 >
주어진 문자열 txt 내에서, 패턴 pat을 찾는다. (비교한다)
- 같으면 → pt와 pp 모두 한 칸씩 옆으로 옮긴다. ▶ “같아!”
- 다르면
- pp = 0 → pt만 한 칸 옆으로 옮긴다. ▶ “달라!” “문자열 그 다음 거는?”
- pp ≠ 0 → pp를 이전 (인덱스) 접미와 같았던 접두 부분 (인덱스) 다음으로 옮긴다. ▶ “달라!” “패턴 다시 봐야겠지만..이미 한 번 같았던 부분은 볼 필요 없어!”
✍ 소회
KMP..이해하는 데에 하루 걸리고, pp = skip[pp] 이 부분 이해하는 데에 하루 더 걸린 것 같다. 왜 악명 높다고 하는지 알 것 같다.
그래도 이해해 가는 과정이 즐거웠으니 됐다-! (까먹지만 않기를..)
